Inleiding
In databasekringen is het algemeen bekend dat indexen de prestaties van zoekopdrachten verbeteren, hetzij door volledig aan de vereiste resultatenset te voldoen (Indexen afdekken) of door te fungeren als zoekacties die de query-engine gemakkelijk naar de exacte locatie van de vereiste gegevensset leiden. Echter, zoals ervaren DBA's weten, moet men niet te enthousiast zijn over het maken van indexen in OLTP-omgevingen zonder de aard van de werklast te begrijpen. Met behulp van Query Store in SQL Server 2019-instantie (Query Store is geïntroduceerd in SQL Server 2016), is het vrij eenvoudig om het effect van een index op invoegingen te laten zien.
Invoegen zonder index
We beginnen met het herstellen van de WideWorldImporters Sample-database en maken vervolgens een kopie van de Sales. Facturentabel met het script in Listing 1. Houd er rekening mee dat Query Store al is ingeschakeld in de lees-schrijfmodus voor de voorbeelddatabase.
-- Listing 1 Make a Copy Of Invoices SELECT * INTO [SALES].[INVOICES1] FROM [SALES].[INVOICES] WHERE 1=2;
Merk op dat er helemaal geen indexen zijn in de tabel die we zojuist hebben gemaakt. We hebben alleen de tabelstructuur. Als we klaar zijn, voeren we invoegingen uit in de nieuwe tabel met behulp van de gegevens van de bovenliggende tabel, zoals weergegeven in Listing 2.
-- Listing 2 Populate Invoices1 -- TRUNCATE TABLE [SALES].[INVOICES1] INSERT INTO [SALES].[INVOICES1] SELECT * FROM [SALES].[INVOICES]; GO 100
Tijdens deze bewerking legt Query Store het uitvoeringsplan van de query vast. Figuur 1 laat in het kort zien wat er onder de motorkap gebeurt. Als we van links naar rechts lezen, zien we dat SQL Server de invoegingen uitvoert met Plan ID 563 – een indexscan op de primaire sleutel van de brontabel om de gegevens op te halen en vervolgens een tabelinvoeging op de doeltabel. (Lezen van links naar rechts). Merk op dat in dit geval het grootste deel van de kosten op het bijvoegsel van de tabel staat - 99% van de vraagkosten.
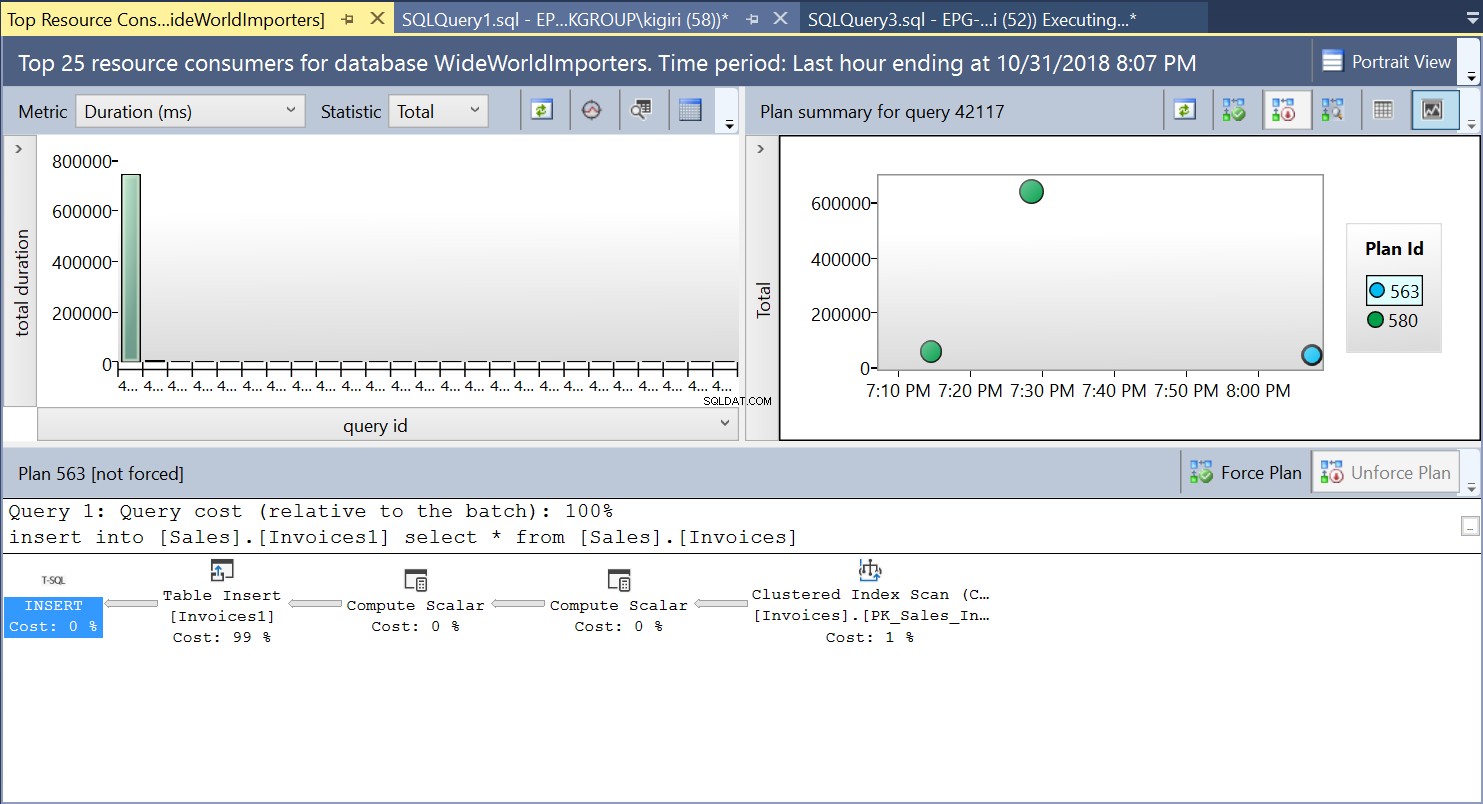
Afb. 1 Uitvoeringsplan 563
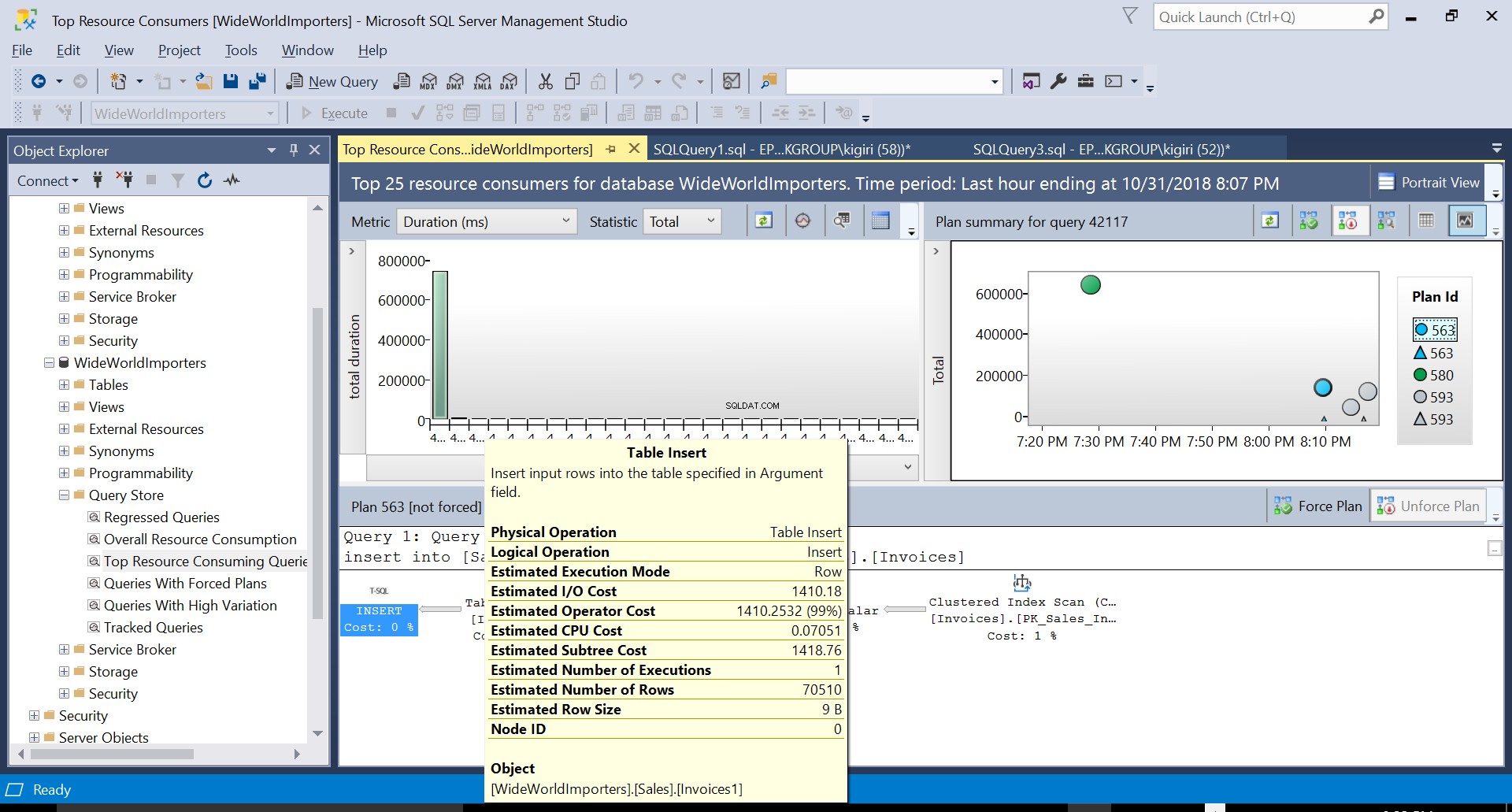
Fig. 2 Tabel invoegen op bestemming
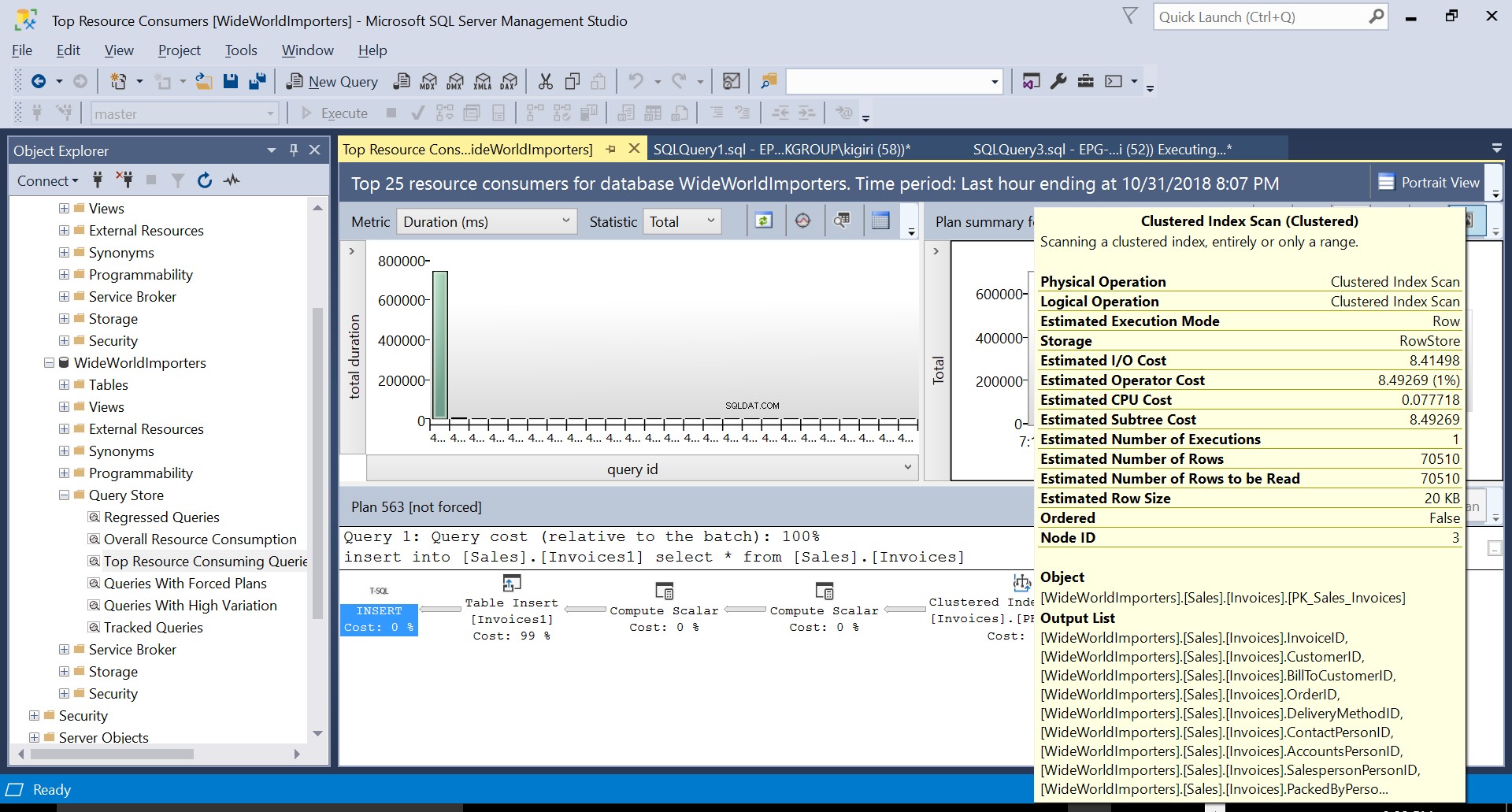
Fig. 3 Geclusterde indexscan op brontabel
Invoegen met index
Vervolgens maken we een index op de bestemmingstabel met behulp van de DDL in Listing 3. Wanneer we de verklaring in Listing 2 herhalen na het afkappen van de bestemmingstabel, zien we een iets ander uitvoeringsplan (Plan-ID 593 getoond in Fig 4). We zien nog steeds de tabelinvoeging, maar deze draagt slechts 58% bij ten koste van de vraag. De uitvoeringsdynamiek is een beetje scheef met de introductie van een soort en een Index Insert. Wat er in wezen gebeurt, is dat SQL Server overeenkomstige rijen in de index moet introduceren wanneer nieuwe records in de tabel worden geïntroduceerd.
-- LISTING 3 Create Index on Destination Table CREATE NONCLUSTERED INDEX [IX_Sales_Invoices_ConfirmedDeliveryTime] ON [Sales].[Invoices1] ( [ConfirmedDeliveryTime] ASC ) INCLUDE ( [ConfirmedReceivedBy]) WITH (PAD_INDEX = OFF , STATISTICS_NORECOMPUTE = OFF , SORT_IN_TEMPDB = OFF , DROP_EXISTING = OFF , ONLINE = OFF , ALLOW_ROW_LOCKS = ON , ALLOW_PAGE_LOCKS = ON) ON [USERDATA] GO
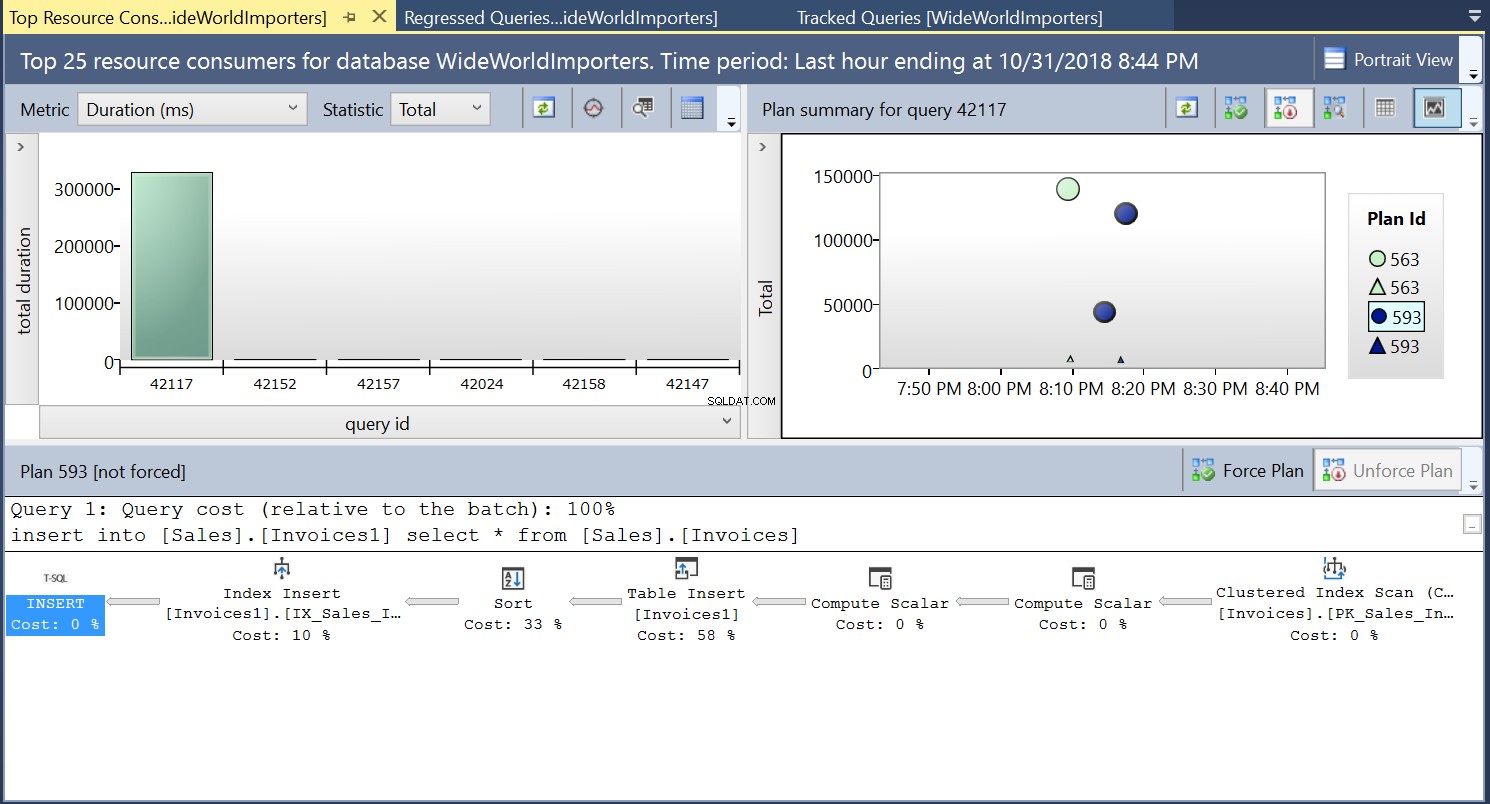
Afb. 4 Uitvoeringsplan 593
Dieper kijken
We kunnen de details van beide plannen onderzoeken en zien hoe deze nieuwe factoren de uitvoeringstijd van de verklaring escaleren. Plan 593 voegt ongeveer 300 ms extra toe aan de gemiddelde duur van de instructie. Bij zware werkdruk in een productieomgeving kan dit verschil aanzienlijk zijn.
Het inschakelen van STATISTICS IO bij het slechts één keer uitvoeren van de insert-instructie in beide gevallen - met Index op de bestemmingstabel en zonder een index op de bestemmingstabel - laat ook zien dat er meer wordt gewerkt in termen van logische IO bij het invoegen van rijen in een tabel met indexen.
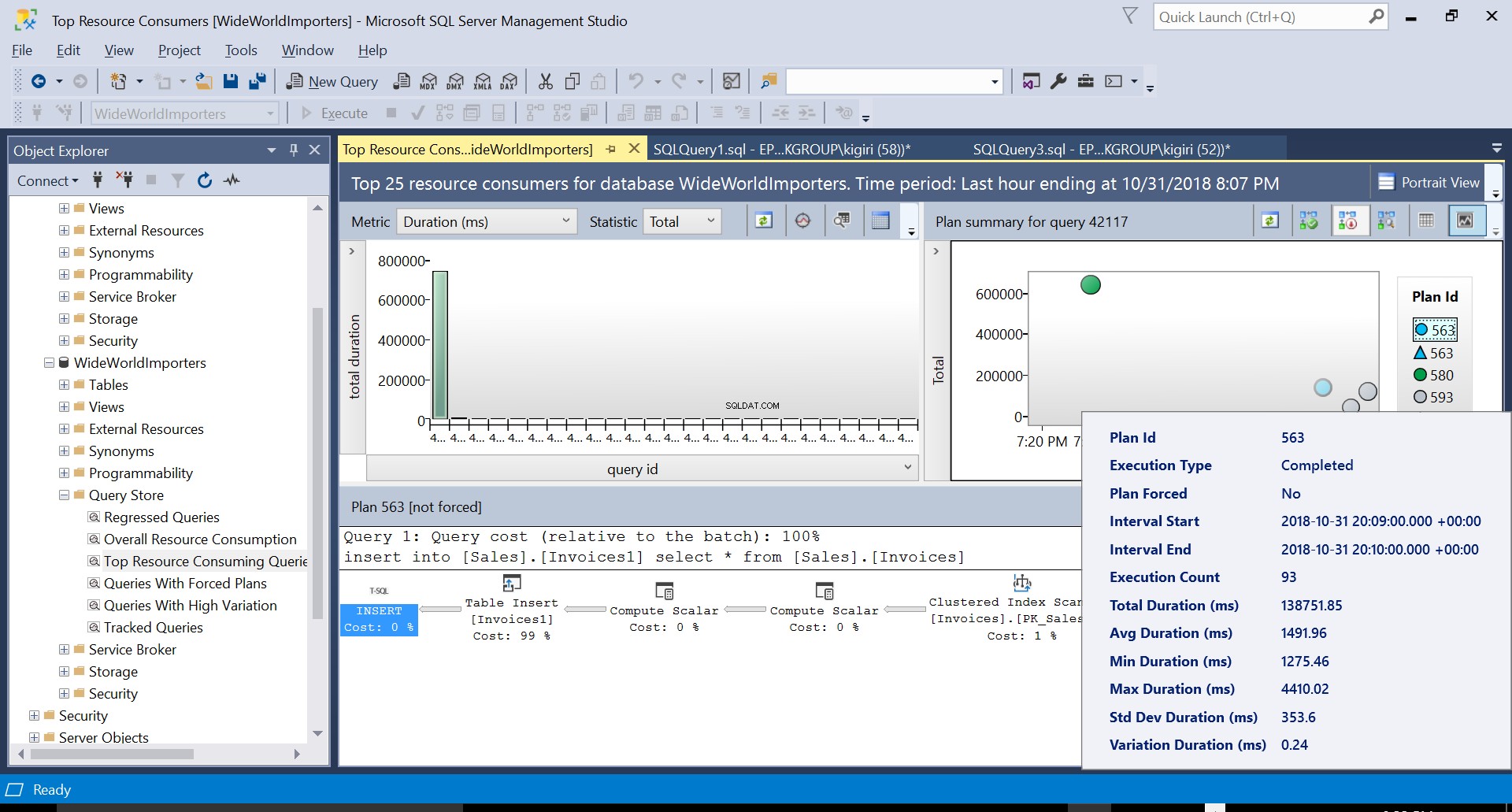
Fig. 5 Details van uitvoeringsplan 563
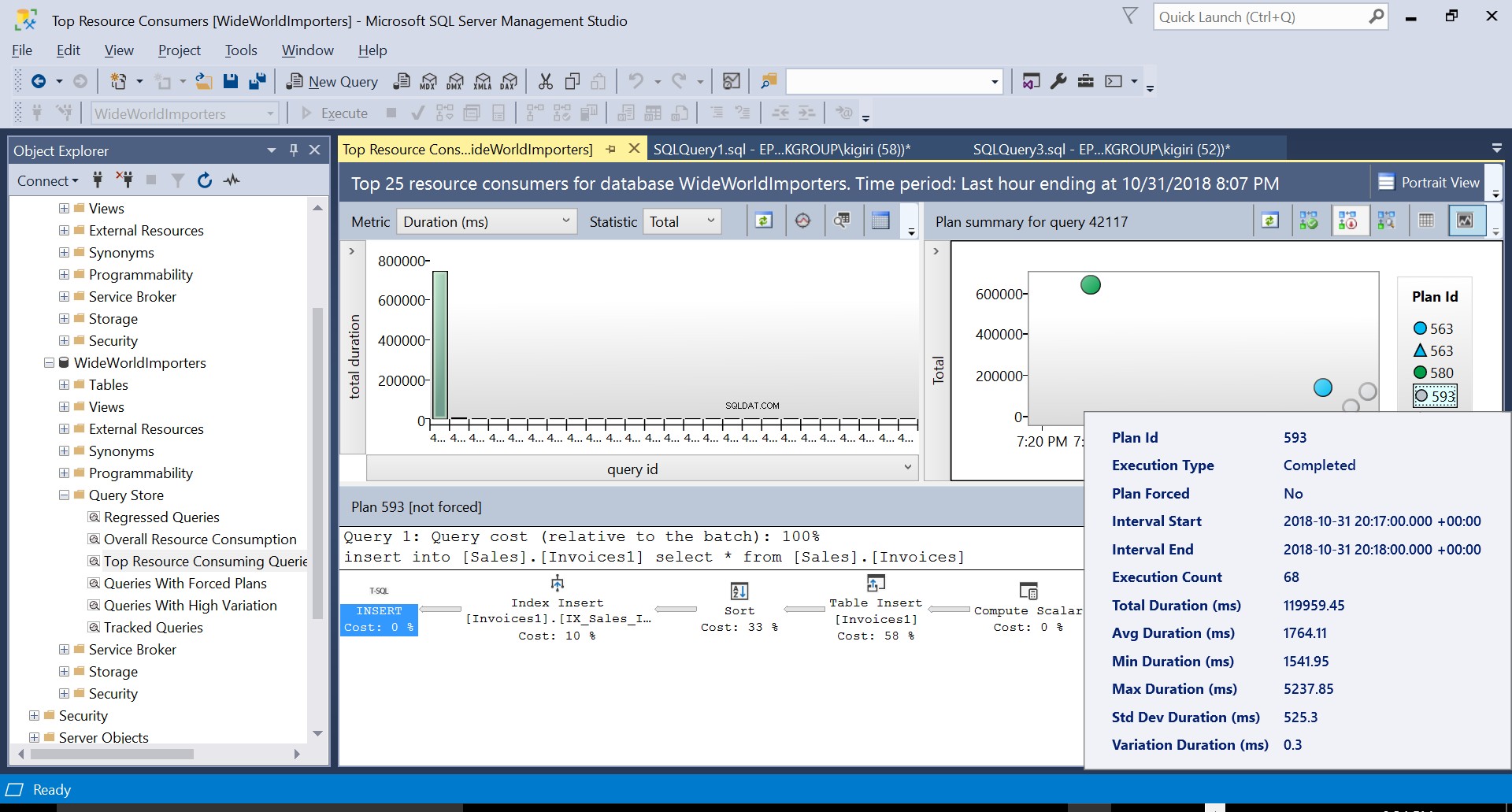
Fig. 4 Details van uitvoeringsplan 593
Geen index:uitvoer met STATISTICS IO ingeschakeld:
Tabel ‘Facturen1’. Scantelling 0, logische uitlezingen 78372 , fysiek leest 0, read-ahead leest 0, lob logische leest 0, lob fysiek leest 0, lob read-ahead leest 0.
Tabel ‘Facturen’. Scantelling 1, logische leest 11400, fysiek leest 0, read-ahead leest 0, lob logische leest 0, lob fysiek leest 0, lob read-ahead leest 0.
(70510 rijen aangetast)
Index:uitvoer met STATISTICS IO ingeschakeld:
Tabel ‘Facturen1’. Scantelling 0, logische uitlezingen 81119 , fysiek leest 0, read-ahead leest 0, lob logische leest 0, lob fysiek leest 0, lob read-ahead leest 0.
Tabel 'Werktafel'. Scantelling 0, logische leest 0, fysieke leest 0, read-ahead leest 0, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.
Tabel ‘Facturen’. Scantelling 1, logische uitlezingen 11400 , fysiek leest 0, read-ahead leest 0, lob logische leest 0, lob fysiek leest 0, lob read-ahead leest 0.
(70510 rijen aangetast)
Aanvullende informatie
Microsoft en andere bronnen leveren scripts om de productieomgeving van indexen te onderzoeken en situaties te identificeren zoals:
- Overtollige indexen – Indexen die gedupliceerd zijn
- Ontbrekende indexen – Indexen die de prestaties kunnen verbeteren op basis van werkdruk
- Heel veel – Tabellen zonder geclusterde indexen
- Overgeïndexeerde tabellen – Tabellen met meer indexen dan kolommen
- Indexgebruik – Aantal zoekopdrachten, scans en opzoekingen op indexen
Items 2, 3 en 5 hebben meer betrekking op prestatie-impact met betrekking tot lezen, terwijl items 1 en 4 betrekking hebben op prestatie-impact met betrekking tot schrijven. Lijsten 4 en 5 zijn twee voorbeelden van deze openbaar beschikbare zoekopdrachten.
-- LISTING 4 Check Redundant Indexes
;WITH INDEXCOLUMNS AS(
SELECT DISTINCT
SCHEMA_NAME (O.SCHEMA_ID) AS 'SCHEMANAME'
, OBJECT_NAME(O.OBJECT_ID) AS TABLENAME
,I.NAME AS INDEXNAME, O.OBJECT_ID,I.INDEX_ID,I.TYPE
,(SELECT CASE KEY_ORDINAL WHEN 0 THEN NULL ELSE '['+COL_NAME(K.OBJECT_ID,COLUMN_ID) +']' END AS [DATA()]
FROM SYS.INDEX_COLUMNS AS K WHERE K.OBJECT_ID = I.OBJECT_ID AND K.INDEX_ID = I.INDEX_ID
ORDER BY KEY_ORDINAL, COLUMN_ID FOR XML PATH('')) AS COLS
FROM SYS.INDEXES AS I INNER JOIN SYS.OBJECTS O ON I.OBJECT_ID =O.OBJECT_ID
INNER JOIN SYS.INDEX_COLUMNS IC ON IC.OBJECT_ID =I.OBJECT_ID AND IC.INDEX_ID =I.INDEX_ID
INNER JOIN SYS.COLUMNS C ON C.OBJECT_ID = IC.OBJECT_ID AND C.COLUMN_ID = IC.COLUMN_ID
WHERE I.OBJECT_ID IN (SELECT OBJECT_ID FROM SYS.OBJECTS WHERE TYPE ='U') AND I.INDEX_ID <>0 AND I.TYPE <>3 AND I.TYPE <>6
GROUP BY O.SCHEMA_ID,O.OBJECT_ID,I.OBJECT_ID,I.NAME,I.INDEX_ID,I.TYPE
)
SELECT
IC1.SCHEMANAME,IC1.TABLENAME,IC1.INDEXNAME,IC1.COLS AS INDEXCOLS,IC2.INDEXNAME AS REDUNDANTINDEXNAME, IC2.COLS AS REDUNDANTINDEXCOLS
FROM INDEXCOLUMNS IC1
JOIN INDEXCOLUMNS IC2 ON IC1.OBJECT_ID = IC2.OBJECT_ID
AND IC1.INDEX_ID <> IC2.INDEX_ID
AND IC1.COLS <> IC2.COLS
AND IC2.COLS LIKE REPLACE(IC1.COLS,'[','[[]') + ' %'
ORDER BY 1,2,3,5;
-- LISTING 5 Check Indexes Usage
SELECT O.NAME AS TABLE_NAME
, I.NAME AS INDEX_NAME
, S.USER_SEEKS
, S.USER_SCANS
, S.USER_LOOKUPS
, S.USER_UPDATES
FROM SYS.DM_DB_INDEX_USAGE_STATS S
INNER JOIN SYS.INDEXES I
ON I.INDEX_ID=S.INDEX_ID
AND S.OBJECT_ID = I.OBJECT_ID
INNER JOIN SYS.OBJECTS O
ON S.OBJECT_ID = O.OBJECT_ID
INNER JOIN SYS.SCHEMAS C
ON O.SCHEMA_ID = C.SCHEMA_ID;
Conclusie
We hebben met behulp van Query Store aangetoond dat extra werklast met een index kan leiden tot het uitvoeringsplan van een voorbeeldinsert-statement. In productie kunnen overmatige en redundante indexen een negatieve invloed hebben op de prestaties, met name in databases die bedoeld zijn voor OLTP-workloads. Het is belangrijk om beschikbare scripts en tools te gebruiken om indexen te onderzoeken en te bepalen of ze de prestaties daadwerkelijk helpen of schaden.
Handig hulpmiddel:
dbForge Index Manager – handige SSMS-invoegtoepassing voor het analyseren van de status van SQL-indexen en het oplossen van problemen met indexfragmentatie.