"Waitstats helpt ons prestatiegerelateerde tellers te identificeren. Maar wachtinformatie alleen is niet voldoende om prestatieproblemen nauwkeurig te diagnosticeren. De wachtrijcomponent van onze methodologie is afkomstig van Performance Monitor-tellers, die een beeld geven van de systeemprestaties vanuit het oogpunt van resources.”Tom Davidson, Microsoft's Performance Tuning Toolbox openen
SQL Server Pro Magazine, december 2003
Waits and Queues wordt gebruikt als methode voor het afstemmen van SQL Server-prestaties sinds Tom Davidson het bovenstaande artikel publiceerde, evenals de bekende SQL Server 2005 Waits and Queues-whitepaper in 2006. Indien toegepast in combinatie met resourcestatistieken, kunnen wachttijden waardevol zijn voor beoordeling van bepaalde prestatiekenmerken van de werklast en hulp bij het sturen van afstemmingsinspanningen. Waits-gegevens worden door veel SQL Server-oplossingen voor prestatiebewaking opgedoken en ik ben vanaf het begin een voorstander geweest van afstemming met behulp van deze methode. De aanpak was van invloed op het ontwerp van het prestatiedashboard van SQL Sentry, dat wachttijden presenteert geflankeerd door wachtrijen (belangrijkste bronstatistieken) om een uitgebreid overzicht van de serverprestaties te leveren.
Sommigen lijken echter het punt van Davidson over het belang van bronnen te hebben gemist en vertrouwen bijna volledig op wachttijden om een beeld te krijgen van de queryprestaties en de systeemgezondheid. Wachtstatistieken komen rechtstreeks van de SQL Server-engine en zijn gemakkelijk te gebruiken en te categoriseren. Wachten op vragen betekent wachten op applicaties en gebruikers, en niemand houdt van wachten! Het is gemakkelijker om afstemming te verkondigen met wachttijden als de enige oplossing om query's en applicaties sneller te maken dan om het volledige verhaal te vertellen, dat meer betrokken is.
Helaas kan een op wachten gerichte benadering, waarbij resource-analyse wordt uitgesloten, misleiden en in het ergste geval blind maken. SentryOne-teamleden Kevin Kline en Steve Wright hebben dit hier en hier eerder besproken. In dit bericht ga ik dieper in op recent onderzoek dat mogelijk is gemaakt door Query Store en dat nieuw licht heeft geworpen op hoe gebrekkig wachten-exclusieve afstemming echt kan zijn.
De belangrijkste zoekopdrachten die er niet waren
Onlangs nam een klant van SentryOne contact met me op over prestatieproblemen met hun SentryOne-database. Er is één SQL Server-database in het hart van elke SentryOne-bewakingsomgeving en deze klant bewaakte ongeveer 600 servers met onze software. Op die schaal is het niet ongebruikelijk om af en toe problemen met de prestatie van query's te zien en een beetje af te stemmen, en sommige zogenaamd nieuwe query's in de werklast waren de bron van hun zorg.
Ik nam deel aan een schermdeelsessie om een kijkje te nemen, en de klant presenteerde me eerst gegevens van een ander systeem dat ook de SentryOne-database bewaakte. Het systeem maakte gebruik van een wachtbenadering op queryniveau en toonde aan dat twee opgeslagen procedures verantwoordelijk waren voor ongeveer de helft van de wachttijden op de SQL Sentry-databaseserver. Dit was ongebruikelijk omdat deze twee procedures altijd erg snel verlopen en nooit een aanwijzing zijn geweest voor een echt prestatieprobleem in onze database. Verbaasd schakelde ik over naar SQL Sentry om te zien wat het ons zou laten zien, en was verrast om te zien dat over hetzelfde interval de #1 procedure in het andere systeem #6, #7 en #8 was in termen van totale duur, CPU en logische leest respectievelijk:
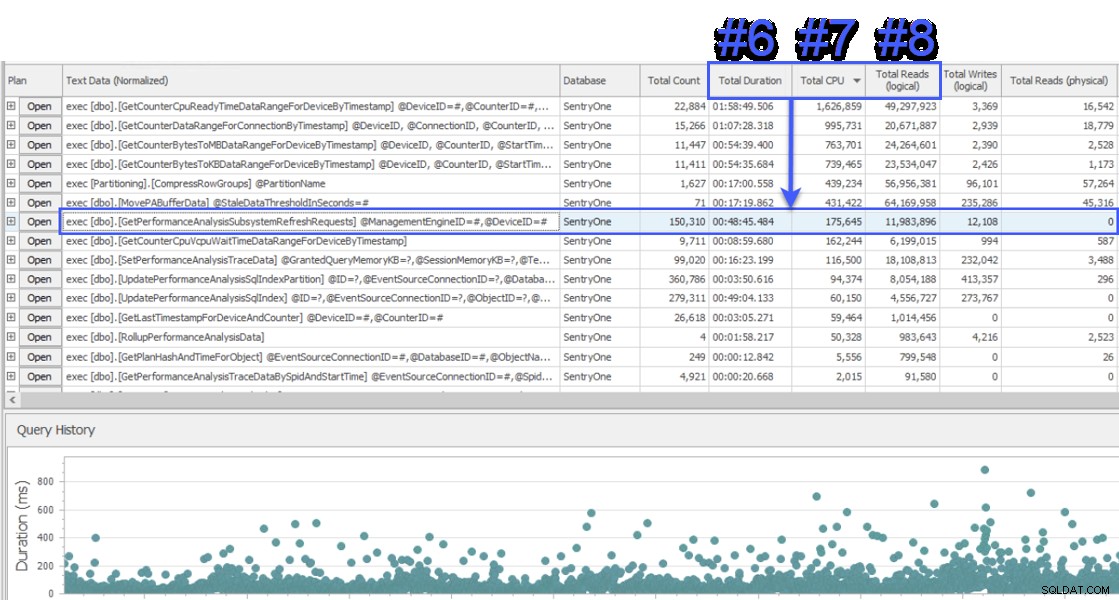 SQL Sentry's "Top SQL"-weergave
SQL Sentry's "Top SQL"-weergave
Vanuit het oogpunt van resourceverbruik betekende dit dat de query's erboven 75% van de totale duur, 87% van de totale CPU en 88% van de logische reads vertegenwoordigden. Bovendien stond de #2 procedure in het andere systeem niet eens in de top 30 in SQL Sentry, hoe dan ook! Deze twee zoekopdrachten waren verre van de top 2 en de zoekopdrachten die de meeste werkelijke voor hun rekening namen verbruik op het systeem werd ernstig ondervertegenwoordigd.
Ik was er altijd van uitgegaan dat er een sterkere correlatie was tussen de beste obers en de beste gebruikers van hulpbronnen, maar ik had nog nooit een directe vergelijking op vraagniveau als deze uitgevoerd, dus deze resultaten waren op zijn zachtst gezegd verrassend. Mijn interesse was gewekt en ik besloot te onderzoeken of deze situatie typisch of abnormaal was.
Query Store 2017 te hulp schieten
In SQL Server 2017 en hoger legt Query Store wachttijden op queryniveau vast naast het verbruik van queryresources. Erin Stellato heeft een geweldige post gedaan op Query Store wacht hier. Het is minder overhead en nauwkeuriger dan het elke seconde opvragen van wacht DMV's in de hoop tijdens de vlucht vragen op te vangen, de standaardbenadering die wordt gebruikt door andere tools, waaronder de bovengenoemde.
SQL Sentry heeft altijd wachttijden vastgelegd, maar op het niveau van de SQL Server-instantie, vanwege deze zorgen over overhead en nauwkeurigheid. Gedetailleerde querywachttijden zijn op aanvraag beschikbaar via geïntegreerde Plan Explorer, en we evalueren het vergroten van de wachttijden op instantieniveau met gegevens op queryniveau uit Query Store, indien beschikbaar.
Voor dit streven heb ik de hulp ingeroepen van de SentryOne Product Advisory Council, een groep SentryOne-klanten, partners en vrienden in de branche die deelnemen aan een privé Slack-kanaal. Ik deelde dit script om de afgelopen 8 uur aan gegevens uit Query Store te dumpen en ontving resultaten terug voor 11 productieservers in meerdere branches, waaronder financiële diensten, game-publicatie, fitness-tracking en verzekeringen.
Wachtcategorieën voor Query Store worden hier gedocumenteerd. Alle categorieën zijn in de analyse opgenomen, behalve deze, die om de genoemde redenen zijn verwijderd:
- Parallelisme - Het kan de wachttijd van een query enorm opblazen tot ver voorbij de werkelijke duur, omdat meerdere threads de bijbehorende wachttijden kunnen verstoren, waardoor de correlatie met de duur en andere statistieken wordt verstoord. Verder, hoewel de CXPACKET/CXCONSUMER-splitsing nuttig is, betekent CXPACKET nog steeds alleen dat je parallellisme hebt en niet per se problematisch of bruikbaar is.
- CPU – Signaalwachttijd kan handig zijn voor het vaststellen van CPU-knelpunten via correlatie met resourcewachten, maar Query Store bevat momenteel alleen SOS_SCHEDULER_YIELD in deze categorie, wat geen wachttijd is in de traditionele zin zoals hier beschreven. Het leent zich niet voor gemakkelijke vergelijking of correlatie, vooral niet wanneer SQL Server zich op een VM bevindt die op een host met te veel abonnementen staat. Op één server waren de CPU-wachttijden van Query Store bijvoorbeeld 227% van de totale CPU-tijd voor alle zoekopdrachten zonder enige parallelliteit, wat niet mogelijk zou moeten zijn.
- Gebruiker wachten enInactief – Deze categorieën bestaan uitsluitend uit timer- en wachtrijwachten en zijn uitgesloten om dezelfde reden dat men deze typen altijd moet uitsluiten - ze zijn onschadelijk en veroorzaken alleen ruis.
Even terzijde, ik heb onlangs met de vader van Query Store, Conor Cunningham, gesproken over de waarschijnlijkheid van toekomstige wijzigingen in de wachttypes en categorieën van Query Store en hij gaf aan dat het zeker mogelijk was ... dus we moeten het in de gaten houden het.
Analyseresultaten TL;DR
Na uitgebreide analyse heb ik bevestigd dat de resultaten die op het klantsysteem zijn waargenomen niet afwijkend zijn, maar eerder alledaags. Dit betekent dat als u afhankelijk bent van een op wachten gerichte tool voor het bewaken en afstemmen van uw workloads, de kans groot is dat u zich op de verkeerde vragen concentreert en degenen die verantwoordelijk zijn voor de meeste mist. van de queryduur en het resourceverbruik op een systeem. Aangezien het CPU- en IO-verbruik zich rechtstreeks vertaalt naar serverhardware en clouduitgaven, is dit aanzienlijk.
De meeste vragen wachten niet
Een interessante en belangrijke bevinding die ik eerst zal behandelen, is dat de meeste zoekopdrachten helemaal geen wachttijden genereren. Van de in totaal 56.438 zoekopdrachten op alle servers, hadden slechts 9.781 (17%) enige wachttijd en slechts 8.092 (14%) hadden wachttijd van significante typen. Als u alleen wachttijden gebruikt om te bepalen welke zoekopdrachten u wilt optimaliseren, mist u de meeste zoekopdrachten in de werklast.
Wachttijden en bronnen in verband brengen
Ik heb geanalyseerd hoe wachttijden zich verhouden tot het verbruik van hulpbronnen door alle zoekopdrachten op elk systeem te rangschikken op wachttijden en middelen en de rangen te gebruiken om de correlatie van een Spearman te berekenen. Wat we uiteindelijk proberen te bepalen, is of de beste obers de grootste consumenten zijn. Het blijkt dat ze dat niet doen.
Tabel 1 toont de kleurgeschaalde correlatiecoëfficiënten voor gemiddelde query-wachttijd tijd voor andere metingen – een waarde van 1,00 (donkerblauw) staat voor gegevens die perfect gecorreleerd zijn. Zoals je kunt zien, is de correlatie met wachttijden en andere metingen op de meeste servers niet sterk, en voor één server is er een negatieve correlatie met de meeste metingen.
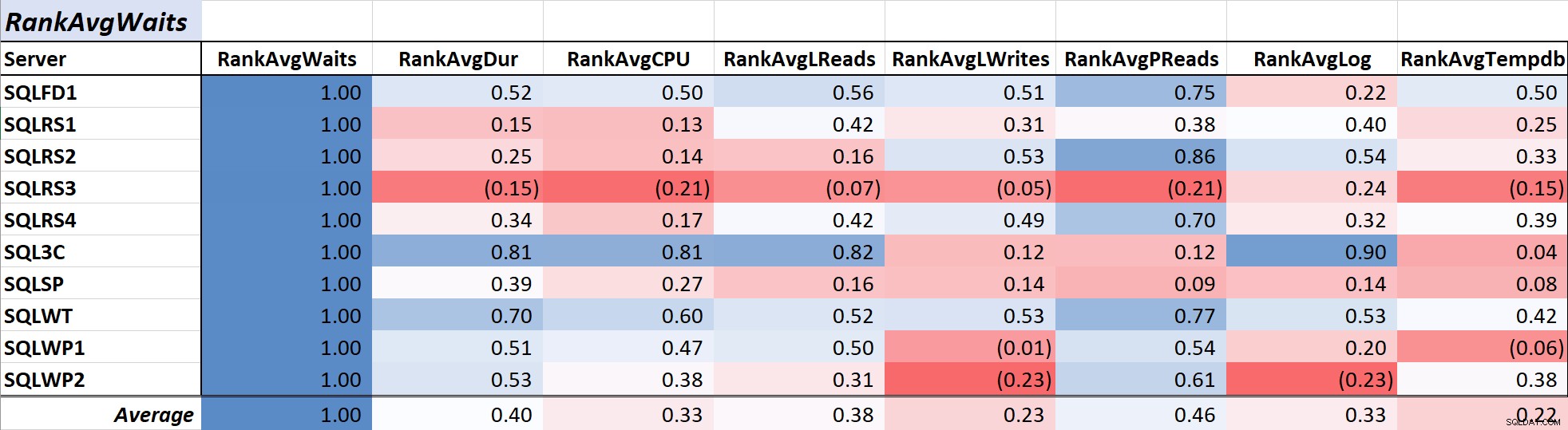 Tabel 1:Correlatie met gemiddelde wachttijd voor query's (ms)
Tabel 1:Correlatie met gemiddelde wachttijd voor query's (ms)
De duur van de zoekopdracht is vaak een primaire zorg voor DBA's en ontwikkelaars, omdat deze zich rechtstreeks vertaalt naar de gebruikerservaring, en Tabel 2 toont de correlatie tussen gemiddelde duur van zoekopdrachten en de andere maatregelen. De correlatie met duur en de twee primaire bronmetingen, CPU en logische uitlezingen, is vrij sterk op respectievelijk .97 en .75.
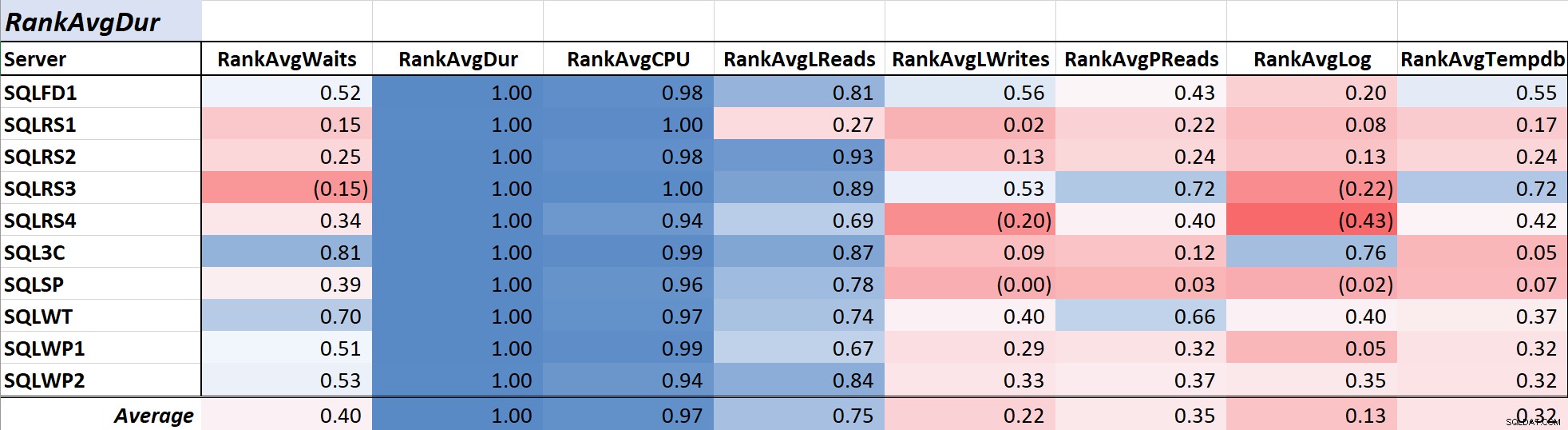 Tabel 2:Correlatie met gemiddelde duur van zoekopdrachten (ms)
Tabel 2:Correlatie met gemiddelde duur van zoekopdrachten (ms)
Aangezien logische uitlezingen altijd CPU gebruiken en, net als de duur, CPU wordt gemeten in milliseconden, is deze relatie niet verrassend. De resultaten komen overeen met het idee dat als u wilt dat uw databasetoepassingen zo snel mogelijk werken, u zich richt op het verminderen van de CPU voor query's en logische leesbewerkingen om de duur te verkorten dan alleen het gebruik van wachttijden. Gelukkig is dit via een beter ontwerp van query's, indexering, enz. meestal een eenvoudiger voorstel dan het rechtstreeks verkorten van de wachttijd voor query's. Collega Aaron Bertrand geeft hier effectief enkele kanttekeningen bij het afstemmen met wacht.
% van totale wachttijd
Vervolgens heb ik gekeken of de query's met de hoogste wachttijd de meeste bronnen verbruiken. We willen bepalen of wat we op het klantsysteem zagen atypisch is, waarbij de top 2 wachtende zoekopdrachten een relatief klein percentage van het totale resourceverbruik vertegenwoordigden.
Grafiek 1 hieronder toont het % van de totale CPU en logische uitlezingen voor elke server die worden verantwoord door de query's die 75% van de totale wachttijd vertegenwoordigen. Slechts één server had een bron van meer dan 75% - leest op SQLRS3. Voor de rest verbruikten de queries die verantwoordelijk waren voor 75% van de wachttijd minder dan 75% van de resources – vaak veel minder. Dit weerspiegelt wat we in het klantensysteem hebben gezien en is consistent met de correlatieanalyse.
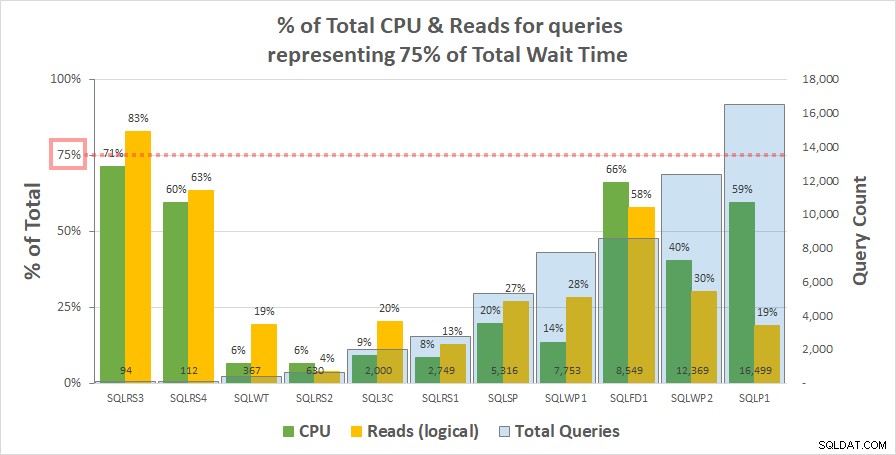 Grafiek 1
Grafiek 1
Merk op dat er een relatie lijkt te zijn met het totale aantal queries in de workload. Dit wordt weergegeven door de lichtblauwe kolomreeks op de secundaire y-as en de grafiek wordt oplopend gesorteerd volgens deze reeks. De twee servers met de hoogste resource-metingen bij 75% van de wachttijden hadden ook de minste query's (SQLRS3 en SQLRS4). Hoe kleiner de werkbelasting, hoe groter de potentiële invloed van een klein aantal query's, en inderdaad, op beide servers waren slechts twee query's verantwoordelijk voor de meeste wachttijden en bronnen. Een manier om hiernaar te kijken, is dat wachttijden het meest helpen bij het identificeren van uw zwaarste vragen wanneer u deze het minst nodig heeft.
Wachttijd en duur van zoekopdracht
Ten slotte evalueerde ik het % van de totale wachttijd tot de totale duur van de query op elk systeem. Tabel 3 heeft kolommen voor:
- Totale duur van zoekopdracht in ms
- Totale wachttijd ms – onbewerkt
- Totale wachttijd ms – zonder parallellisme, inactief en gebruikerswachten (Rev1)
- Totale wachttijd ms – zonder parallellisme, inactief, gebruikerswachten en CPU (Rev2)
- Het % van de duur voor de 3 wachttijdkolommen, met gegevensbalken
- Totaal aantal unieke zoekopdrachten, met gegevensbalken
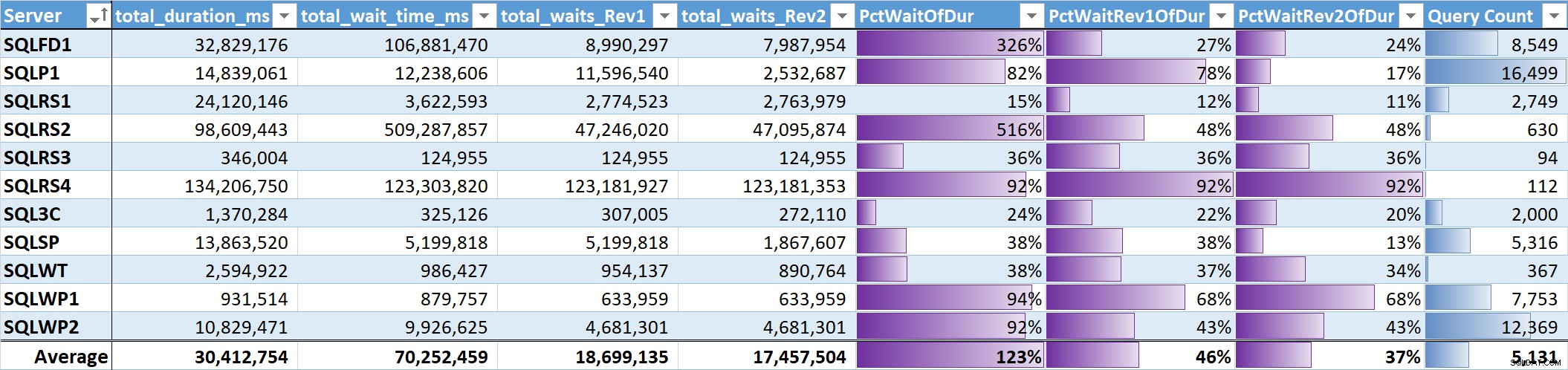 Tabel 3
Tabel 3
Het ongewogen gemiddelde voor de zinvolle wachttijden (Rev2) voor alle systemen is 37% van de totale duur van de zoekopdracht. Op vijf van de systemen was het minder dan 25% en op slechts twee systemen was het meer dan 50%. Op het systeem met 92% wachttijd (SQLRS4), een met de minste zoekopdrachten, waren twee zoekopdrachten goed voor 99% van de wachttijden, 97% van de duur, 84% van de CPU en 86% van de leesbewerkingen.
Hoewel de wachttijd op bepaalde systemen een aanzienlijk deel van de query-runtime kan vertegenwoordigen, en het intuïtief lijkt dat als u de wachttijd verkort, de queryduur ook afneemt, hebben we gezien dat wachttijd en duur zwak gecorreleerd zijn. Het is onwaarschijnlijk dat het zo eenvoudig is, en mijn eigen ervaring bevestigt dit. Hier is meer onderzoek nodig.
Uitgebreide afstemming met Plan Explorer en SQL Sentry
Zoals deze uitstekende whitepaper over SQLskills vaak suggereert, ligt de oorzaak van hoge wachttijden vaak in niet-geoptimaliseerde query's en indexen. De gratis SentryOne Plan Explorer is speciaal gebouwd om het verbruik van hulpbronnen te verminderen door middel van efficiënte afstemming van zoekopdrachten met behulp van de Index Analysis-module en vele andere innovatieve functies. SQL Sentry integreert Plan Explorer rechtstreeks in de Top SQL-, Blocking- en Deadlocks-modules, zodat u problematische query's automatisch op één plek kunt vastleggen en afstemmen. U kunt eenvoudig een interessebereik selecteren op de historische wachttijden, CPU- of IO-diagrammen van het SQL Sentry-dashboard en naar de Top SQL-weergave springen om de belangrijkste resource-intensieve query's in die tijd te vinden. Vervolgens kunt u met een enkele klik een query openen in Plan Explorer en gedetailleerde wachttijden op queryniveau krijgen en middelen op aanvraag wanneer dat nodig is. Ik denk niet dat er een betere belichaming is van de volledige Waits and Queues-afstemmethode dan deze.
 SQL Sentry Dashboard "Wachten"-diagram
SQL Sentry Dashboard "Wachten"-diagram
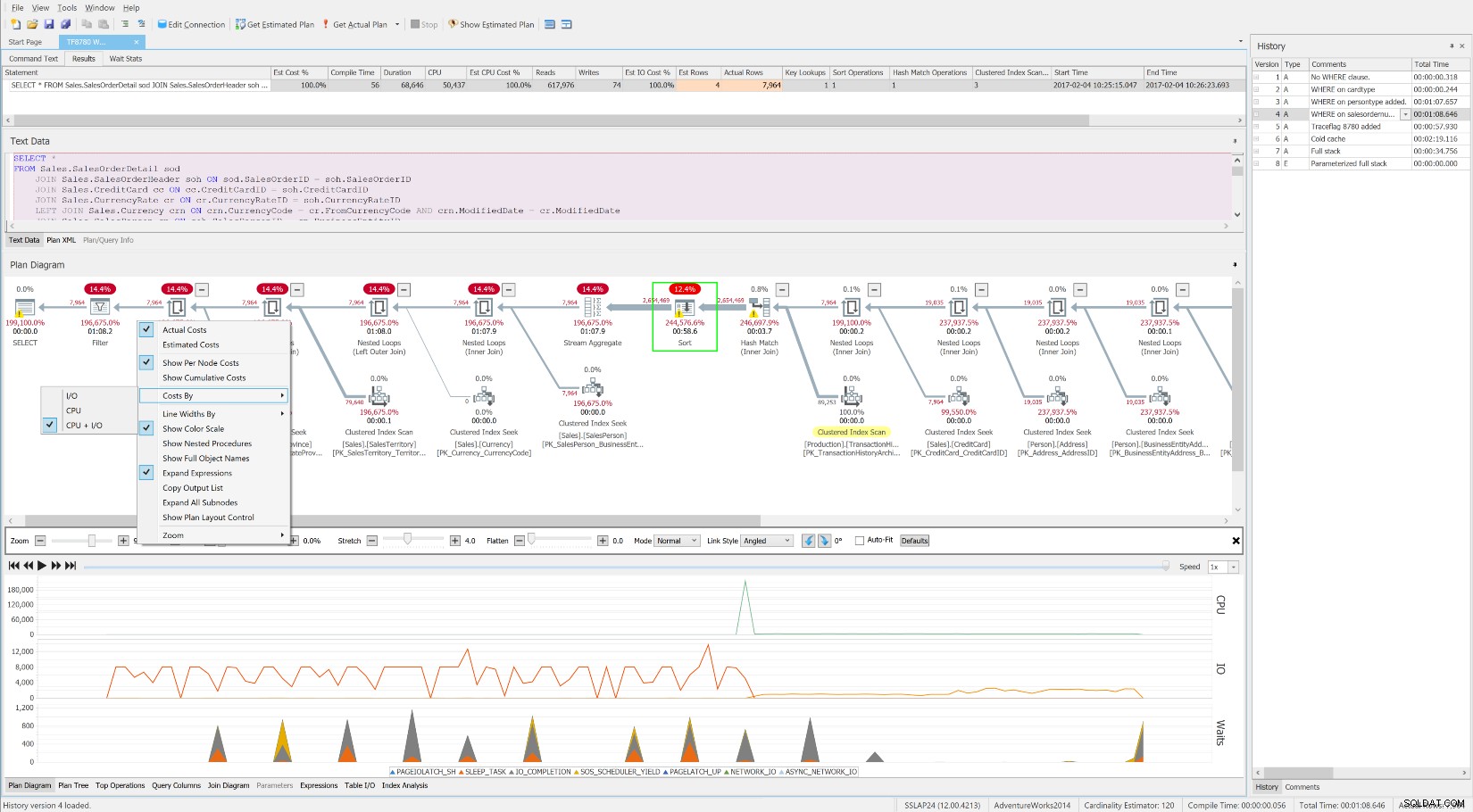 De gratis SentryOne Plan Explorer toont wachttijden in de loop van de tijd, samen met het bewerkingsniveau kosten en middelen
De gratis SentryOne Plan Explorer toont wachttijden in de loop van de tijd, samen met het bewerkingsniveau kosten en middelen
Conclusie
Afstemmen met wachttijden en wachtrijen is vandaag de dag net zo van toepassing op de prestaties van SQL Server als in 2006. Het is echter een gevaarlijke zaak om u te concentreren op wachttijden zonder resources te gebruiken, aangezien uit de gegevens duidelijk blijkt dat dit zal leiden tot over het algemeen niet-geoptimaliseerde en kosteninefficiënte systemen. Als het gaat om hardwareresources en clouduitgaven, betaalt u uiteindelijk voor compute- en IO-resources, niet voor wachttijd, dus het is raadzaam om direct voor consumptie te optimaliseren. Mijn ervaring is dat als het verbruik van hulpbronnen en de daarmee samenhangende conflicten worden verlaagd, de wachttijd vanzelf zal afnemen.
Bevestiging
Ik wil Fred Frost, Lead Data Scientist bij SentryOne, bedanken voor zijn waardevolle input en kritische beoordeling van deze analyse.