In een recente thread op StackExchange had een gebruiker het volgende probleem:
Ik wil een query die de eerste persoon in de tabel retourneert met een GroupID =2. Als er niemand met een GroupID =2 bestaat, wil ik de eerste persoon met een RoleID =2.
Laten we voorlopig het feit negeren dat "eerste" vreselijk gedefinieerd is. In werkelijkheid maakte het de gebruiker niet uit welke persoon ze kregen, of het nu willekeurig, willekeurig of door een of andere expliciete logica naast hun belangrijkste criteria kwam. Laten we dat negeren, laten we zeggen dat je een basistabel hebt:
CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT );
In de echte wereld zijn er waarschijnlijk andere kolommen, extra beperkingen, misschien buitenlandse sleutels naar andere tabellen en zeker andere indexen. Maar laten we het simpel houden en een vraag bedenken.
Waarschijnlijke oplossingen
Met dat tafelontwerp lijkt het oplossen van het probleem eenvoudig, toch? De eerste poging die u waarschijnlijk zou doen is:
SELECT TOP (1) UserID, GroupID, RoleID FROM dbo.Users WHERE GroupID = 2 OR RoleID = 2 ORDER BY CASE GroupID WHEN 2 THEN 1 ELSE 2 END;
Dit gebruikt TOP en een voorwaardelijke ORDER BY om die gebruikers met een GroupID =2 als hogere prioriteit te behandelen. Het plan voor deze query is vrij eenvoudig, waarbij de meeste kosten plaatsvinden in een sorteerbewerking. Hier zijn runtime-statistieken voor een lege tabel:
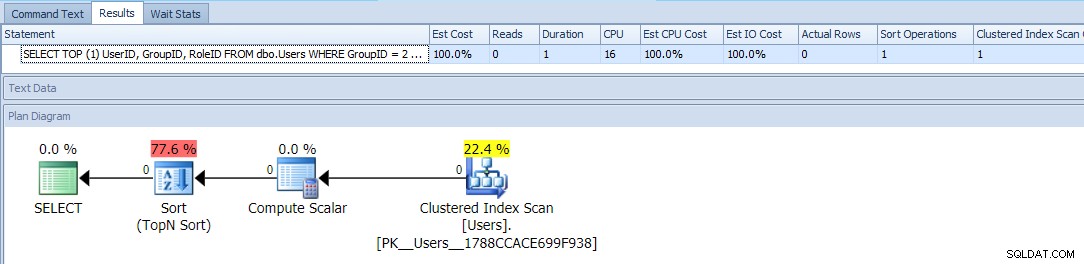
Dit lijkt ongeveer net zo goed te zijn als jij kunt doen - een eenvoudig plan dat de tafel maar één keer scant, en anders dan een vervelende soort waarmee je zou moeten kunnen leven, geen probleem, toch?
Welnu, een ander antwoord in de thread bood deze meer complexe variatie:
SELECT TOP (1) UserID, GroupID, RoleID FROM ( SELECT TOP (1) UserID, GroupID, RoleID, o = 1 FROM dbo.Users WHERE GroupId = 2 UNION ALL SELECT TOP (1) UserID, GroupID, RoleID, o = 2 FROM dbo.Users WHERE RoleID = 2 ) AS x ORDER BY o;
Op het eerste gezicht zou je waarschijnlijk denken dat deze query extreem minder efficiënt is, omdat er twee geclusterde indexscans nodig zijn. Daar zou je zeker gelijk in hebben; hier zijn de plan- en runtime-statistieken tegen een lege tabel:
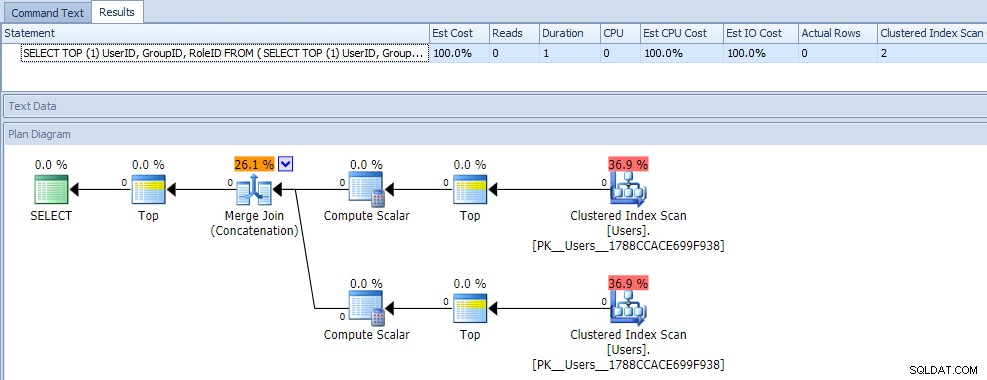
Maar laten we nu gegevens toevoegen
Om deze vragen te testen, wilde ik wat realistische gegevens gebruiken. Dus eerst vulde ik 1.000 rijen uit sys.all_objects, met modulo-bewerkingen tegen de object_id om een fatsoenlijke distributie te krijgen:
INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 7, ABS([object_id]) % 4 FROM sys.all_objects ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 126 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 248 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 26 overlap
Als ik nu de twee query's uitvoer, zijn hier de runtime-statistieken:

De UNION ALL-versie wordt geleverd met iets minder I/O (4 reads vs. 5), een kortere duur en lagere geschatte totale kosten, terwijl de voorwaardelijke ORDER BY-versie lagere geschatte CPU-kosten heeft. De gegevens hier zijn vrij klein om conclusies over te trekken; Ik wilde het gewoon als een paal in de grond. Laten we nu de verdeling wijzigen zodat de meeste rijen voldoen aan ten minste één van de criteria (en soms beide):
DROP TABLE dbo.Users; GO CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT ); GO INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 2 + 1, SUBSTRING(RTRIM([object_id]),7,1) % 2 + 1 FROM sys.all_objects WHERE ABS([object_id]) > 9999999 ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 500 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 475 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 221 overlap
Deze keer heeft de voorwaardelijke volgorde door de hoogste geschatte kosten in zowel CPU als I/O:

Maar nogmaals, bij deze gegevensomvang is er een relatief onbelangrijke impact op de duur en het lezen, en afgezien van de geschatte kosten (die toch grotendeels worden verzonnen), is het moeilijk om hier een winnaar aan te wijzen.
Laten we dus veel meer gegevens toevoegen
Hoewel ik het leuk vind om voorbeeldgegevens op te bouwen uit de catalogusweergaven, aangezien iedereen die heeft, ga ik deze keer tekenen op de tafel Sales.SalesOrderHeaderEnlarged van AdventureWorks2012, uitgebreid met dit script van Jonathan Kehayias. Op mijn systeem heeft deze tabel 1.258.600 rijen. Het volgende script zal een miljoen van die rijen in onze dbo.Users-tabel invoegen:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000000) SalesOrderID, SalesOrderID % 7, SalesOrderID % 4 FROM Sales.SalesOrderHeaderEnlarged; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 142,857 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 250,000 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 35,714 overlap
Oké, als we nu de query's uitvoeren, zien we een probleem:de ORDER BY-variant is parallel gegaan en heeft zowel reads als CPU uitgewist, wat een verschil van bijna 120x in duur opleverde:
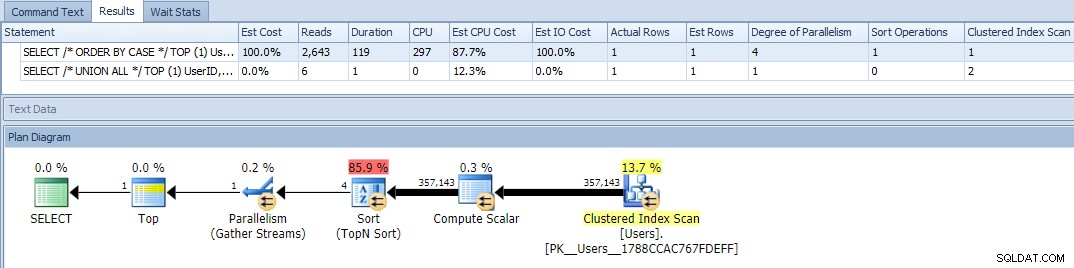
Het elimineren van parallellisme (met MAXDOP) hielp niet:
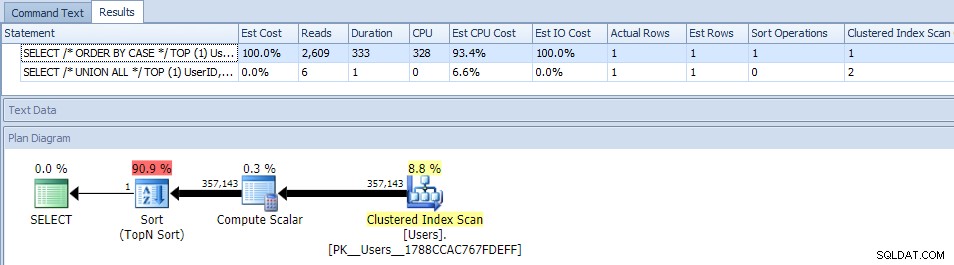
(Het UNION ALL-plan ziet er nog steeds hetzelfde uit.)
En als we de scheefheid gelijk maken, waarbij 95% van de rijen aan ten minste één criterium voldoen:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (475000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 1 UNION ALL SELECT TOP (475000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 0; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, 1, 1 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 135,702 overlap
Uit de zoekopdrachten blijkt nog steeds dat de sortering onbetaalbaar is:

En met MAXDOP =1 was het veel erger (kijk maar naar de duur):

Tot slot, hoe zit het met 95% scheeftrekking in beide richtingen (bijv. de meeste rijen voldoen aan de GroupID-criteria, of de meeste rijen voldoen aan de RoleID-criteria)? Dit script zorgt ervoor dat ten minste 95% van de gegevens GroupID =2 heeft:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
De resultaten zijn vrij gelijkaardig (ik ga vanaf nu gewoon stoppen met het proberen van MAXDOP):

En als we dan de andere kant op scheeftrekken, waar ten minste 95% van de gegevens RoleID =2 heeft:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Resultaten:

Conclusie
In geen enkel geval dat ik kon maken, presteerde de "eenvoudigere" ORDER BY-query - zelfs met een minder geclusterde indexscan - beter dan de meer complexe UNION ALL-query. Soms moet u erg op uw hoede zijn voor wat SQL Server moet doen wanneer u bewerkingen zoals sorteringen in uw query-semantiek introduceert, en niet alleen vertrouwen op de eenvoud van het plan (laat staan dat u vooringenomen bent op basis van eerdere scenario's).
Je eerste instinct is misschien vaak correct, maar ik wed dat er momenten zijn dat er een betere optie is die er op het eerste gezicht uitziet alsof het onmogelijk beter kan uitpakken. Zoals in dit voorbeeld. Ik word een stuk beter in het in twijfel trekken van aannames die ik heb gemaakt op basis van observaties, en geen algemene uitspraken doen als "scans presteren nooit goed" en "eenvoudigere zoekopdrachten werken altijd sneller". Als je de woorden nooit en altijd uit je vocabulaire verwijdert, zul je merken dat je meer van die aannames en algemene uitspraken op de proef stelt, en uiteindelijk veel beter af bent.