U hebt waarschijnlijk een aantal van deze fouten gemaakt toen u aan uw databaseontwerpcarrière begon. Misschien ben je ze nog steeds aan het maken, of maak je er in de toekomst een paar. We kunnen niet terug in de tijd gaan en u helpen uw fouten ongedaan te maken, maar we kunnen u wel wat toekomstige (of huidige) hoofdpijn besparen.
Het lezen van dit artikel kan u vele uren besparen bij het oplossen van ontwerp- en codeproblemen, dus laten we erin duiken. Ik heb de lijst met fouten opgesplitst in twee hoofdgroepen:de fouten die niet-technisch zijn van aard en die strikt technisch . zijn . Beide groepen vormen een belangrijk onderdeel van het databaseontwerp.
Het is duidelijk dat als je geen technische vaardigheden hebt, je niet weet hoe je iets moet doen. Het is niet verwonderlijk om deze fouten in de lijst te zien. Maar niet-technische vaardigheden? Mensen vergeten ze misschien, maar deze vaardigheden zijn ook een heel belangrijk onderdeel van het ontwerpproces. Ze voegen waarde toe aan uw code en brengen de technologie in verband met het echte probleem dat u moet oplossen.
Laten we dus eerst beginnen met de niet-technische problemen en dan naar de technische gaan.
Niet-technische databaseontwerpfouten
#1 Slechte planning
Dit is absoluut een niet-technisch probleem, maar het is een groot en veelvoorkomend probleem. We worden allemaal enthousiast wanneer een nieuw project begint en als we erin gaan, ziet alles er geweldig uit. In het begin is het project nog een blanco pagina en gaan jij en je klant graag aan de slag met iets dat een betere toekomst voor jullie beiden zal creëren. Dit is allemaal geweldig, en een geweldige toekomst zal waarschijnlijk het uiteindelijke resultaat zijn. Maar toch moeten we gefocust blijven. Dit is het deel van het project waar we cruciale fouten kunnen maken.
Voordat u gaat zitten om een gegevensmodel te tekenen, moet u er zeker van zijn dat:
- U bent volledig op de hoogte van wat uw klant doet (d.w.z. hun bedrijfsplannen met betrekking tot dit project en ook hun algemene beeld) en wat ze willen dat dit project nu en in de toekomst bereikt.
- Je begrijpt het bedrijfsproces en bent bereid om, indien nodig, suggesties te doen om het te vereenvoudigen en te verbeteren (bijvoorbeeld om de efficiëntie en inkomsten te verhogen, kosten en werkuren te verminderen, enz.).
- Je begrijpt de datastroom in het bedrijf van de klant. Idealiter zou je elk detail weten:wie met de gegevens werkt, wie wijzigingen aanbrengt, welke rapporten nodig zijn, wanneer en waarom dit allemaal gebeurt.
- U kunt de taal/terminologie gebruiken die uw klant gebruikt. Hoewel u misschien wel of niet een expert op hun gebied bent, is uw klant dat zeker. Vraag hen uit te leggen wat je niet begrijpt. En wanneer u technische details aan de klant uitlegt, gebruik dan taal en terminologie die zij begrijpen.
- Je weet welke technologieën je gaat gebruiken, van de database-engine en programmeertalen tot andere tools. Wat u besluit te gebruiken hangt nauw samen met het probleem dat u gaat oplossen, maar het is belangrijk om de voorkeuren van de klant en hun huidige IT-infrastructuur op te nemen.
Tijdens de planningsfase zou u antwoord moeten krijgen op deze vragen:
- Welke tabellen worden de centrale tabellen in uw model? U zult er waarschijnlijk een paar hebben, terwijl de andere tabellen enkele van de gebruikelijke zullen zijn (bijv. user_account, role). Vergeet woordenboeken en relaties tussen tabellen niet.
- Welke namen worden gebruikt voor tabellen in het model? Vergeet niet om de terminologie gelijk te houden aan wat de klant momenteel gebruikt.
- Welke regels zijn van toepassing bij het benoemen van tabellen en andere objecten? (Zie punt 4 over naamgevingsconventies.)
- Hoe lang duurt het hele project? Dit is belangrijk, zowel voor uw planning als voor de tijdlijn van de klant.
Pas als je al deze antwoorden hebt, ben je klaar om een eerste oplossing voor het probleem te delen. Die oplossing hoeft geen volledige aanvraag te zijn – misschien een kort document of zelfs een paar zinnen in de taal van het bedrijf van de klant.
Een goede planning is niet specifiek voor datamodellering; het is toepasbaar op bijna elk IT (en niet-IT) project. Overslaan is alleen een optie als 1) je een heel klein project hebt; 2) de taken en doelen zijn duidelijk, en 3) je hebt echt haast. Een historisch voorbeeld zijn de lanceeringenieurs van de Spoetnik 1 die mondelinge instructies gaven aan de technici die het in elkaar zetten. Het project had haast vanwege het nieuws dat de VS van plan waren binnenkort hun eigen satelliet te lanceren - maar ik denk dat je niet zo'n haast zult hebben.
#2 Onvoldoende communicatie met klanten en ontwikkelaars
Wanneer u het databaseontwerpproces start, zult u waarschijnlijk de meeste van de belangrijkste vereisten begrijpen. Sommige zijn heel gebruikelijk, ongeacht het bedrijf, b.v. gebruikersrollen en -statussen. Aan de andere kant zullen sommige tabellen in uw model vrij specifiek zijn. Als u bijvoorbeeld een model bouwt voor een taxibedrijf, heeft u tabellen voor voertuigen, chauffeurs, klanten enz.
Toch zal niet alles duidelijk zijn bij de start van een project. Misschien begrijp je bepaalde vereisten verkeerd, de klant voegt misschien nieuwe functionaliteiten toe, je ziet iets dat anders kan, het proces kan veranderen, enz. Dit alles veroorzaakt veranderingen in het model. Voor de meeste wijzigingen moeten nieuwe tabellen worden toegevoegd, maar soms moet u tabellen verwijderen of wijzigen. Als je al bent begonnen met het schrijven van code die deze tabellen gebruikt, moet je die code ook herschrijven.
Om de tijd die besteed wordt aan onverwachte wijzigingen te verminderen, moet u:
- Praat met ontwikkelaars en klanten en wees niet bang om essentiële zakelijke vragen te stellen. Als je denkt dat je klaar bent om te beginnen, vraag jezelf dan af Is situatie X opgenomen in onze database? De klant doet Y momenteel op deze manier; verwachten we in de nabije toekomst verandering? Zodra we er zeker van zijn dat ons model alles wat we nodig hebben op de juiste manier kan opslaan, kunnen we beginnen met coderen.
- Als je te maken krijgt met een grote verandering in je ontwerp en je hebt al veel code geschreven, moet je niet proberen om een snelle oplossing te vinden. Doe het zoals het had moeten gebeuren, ongeacht de huidige situatie. Een snelle oplossing kan nu wat tijd besparen en zou waarschijnlijk een tijdje goed werken, maar het kan later een echte nachtmerrie worden.
- Als je denkt dat iets nu in orde is, maar later een probleem kan worden, negeer het dan niet. Analyseer dat gebied en voer wijzigingen door als ze de kwaliteit en prestaties van het systeem verbeteren. Het kost wat tijd, maar je levert een beter product af en slaapt veel beter.
Als u wijzigingen in uw datamodel probeert te vermijden wanneer u een mogelijk probleem ziet - of als u kiest voor een snelle oplossing in plaats van het goed te doen - betaalt u daar vroeg of laat voor.
Blijf ook gedurende het hele project in contact met uw klant en de ontwikkelaars. Controleer altijd of er wijzigingen zijn aangebracht sinds uw laatste discussie.
#3 Slechte of ontbrekende documentatie
Voor de meesten van ons komt documentatie aan het einde van het project. Als we goed georganiseerd zijn, hebben we onderweg waarschijnlijk dingen gedocumenteerd en hoeven we alleen maar alles af te ronden. Maar eerlijk gezegd is dat meestal niet het geval. Het schrijven van documentatie gebeurt net voordat het project wordt afgesloten - en net nadat we mentaal klaar zijn met dat datamodel!
De prijs die betaald wordt voor een slecht gedocumenteerd project kan behoorlijk hoog zijn, een paar keer hoger dan de prijs die we betalen om alles goed te documenteren. Stel je voor dat je een paar maanden nadat je het project hebt afgesloten een bug vindt. Omdat je niet goed hebt gedocumenteerd, weet je niet waar je moet beginnen.
Vergeet niet om opmerkingen te schrijven terwijl u aan het werk bent. Leg alles uit dat extra uitleg nodig heeft, en schrijf eigenlijk alles op waarvan je denkt dat het ooit nuttig zal zijn. Je weet nooit of en wanneer je die extra informatie nodig hebt.
Technische fouten bij het ontwerpen van databases
#4 Geen naamgevingsconventie gebruiken
Je weet nooit zeker hoe lang een project duurt en of er meer dan één persoon aan het datamodel werkt. Er komt een moment dat je heel dicht bij het datamodel bent, maar je bent nog niet begonnen met het daadwerkelijk tekenen ervan. Dit is wanneer het verstandig is om te beslissen hoe u objecten in uw model, in de database en in de algemene toepassing gaat benoemen. Voordat je gaat modelleren, moet je weten:
- Zijn tabelnamen enkelvoud of meervoud?
- Gaan we tabellen groeperen met namen? (Alle klantgerelateerde tabellen bevatten bijvoorbeeld "client_", alle taakgerelateerde tabellen bevatten "task_", enz.)
- Gaan we hoofdletters en kleine letters gebruiken, of alleen kleine letters?
- Welke naam gebruiken we voor de ID-kolommen? (Hoogstwaarschijnlijk zal het "id" zijn.)
- Hoe zullen we buitenlandse sleutels een naam geven? (Hoogstwaarschijnlijk "id_" en de naam van de tabel waarnaar wordt verwezen.)
Vergelijk een deel van een model dat geen naamgevingsconventies gebruikt met hetzelfde deel dat wel naamgevingsconventies gebruikt, zoals hieronder weergegeven:
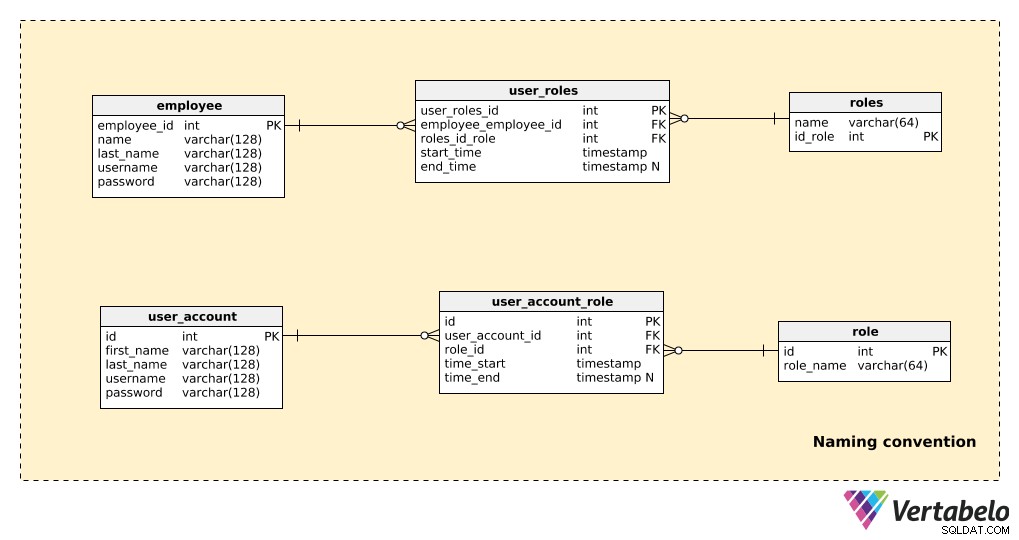
Er zijn hier maar een paar tabellen, maar het is nog steeds vrij duidelijk welk model gemakkelijker te lezen is. Merk op dat:
- Beide modellen "werken", dus er zijn geen problemen aan de technische kant.
- In het voorbeeld van een niet-naamgevingsconventie (de bovenste drie tabellen) zijn er een paar dingen die de leesbaarheid aanzienlijk beïnvloeden:het gebruik van zowel enkelvoud als meervoud in de tabelnamen; niet-gestandaardiseerde primaire sleutelnamen (
employees_id,id_role); en attributen in verschillende tabellen hebben dezelfde naam (naam verschijnt bijvoorbeeld in zowel de "employee” en de “roles” tabellen).
Stel je nu de puinhoop voor die we zouden creëren als ons model honderden tabellen zou bevatten. Misschien zouden we met zo'n model kunnen werken (als we het zelf hebben gemaakt), maar we zouden iemand heel veel pech hebben als ze er na ons aan moesten werken.
Gebruik geen gereserveerde SQL-woorden, speciale tekens of spaties erin om toekomstige problemen met namen te voorkomen.
Dus, voordat je begint met het maken van namen, maak een eenvoudig document (misschien slechts een paar pagina's lang) dat de naamgevingsconventie beschrijft die je hebt gebruikt. Dit zal de leesbaarheid van het hele model vergroten en toekomstig werk vereenvoudigen.
U kunt meer lezen over naamgevingsconventies in deze twee artikelen:
- Naamconventies in databasemodellering
- Een emotieloze, logische kijk op de naamgevingsconventies van SQL Server
#5 Normalisatieproblemen
Normalisatie is een essentieel onderdeel van het databaseontwerp. Elke database moet worden genormaliseerd naar ten minste 3NF (primaire sleutels zijn gedefinieerd, kolommen zijn atomair en er zijn geen herhalende groepen, gedeeltelijke afhankelijkheden of transitieve afhankelijkheden). Dit vermindert gegevensduplicatie en zorgt voor referentiële integriteit.
In dit artikel lees je meer over normalisatie. Kortom, wanneer we het hebben over het relationele databasemodel, hebben we het over de genormaliseerde database. Als een database niet wordt genormaliseerd, zullen we een aantal problemen tegenkomen met betrekking tot gegevensintegriteit.
In sommige gevallen willen we onze database misschien denormaliseren. Als je dit doet, heb dan een hele goede reden. U kunt hier meer lezen over databasedenormalisatie.
#6 Het Entity-Attribute-Value (EAV)-model gebruiken
EAV staat voor entiteit-attribuut-waarde. Deze structuur kan worden gebruikt om aanvullende gegevens over alles in ons model op te slaan. Laten we een voorbeeld bekijken.
Stel dat we wat extra klantkenmerken willen opslaan. De "customer ” tabel is onze entiteit, het “attribute ” tabel is uiteraard ons attribuut, en de “attribute_value ” tabel bevat de waarde van dat kenmerk voor die klant.
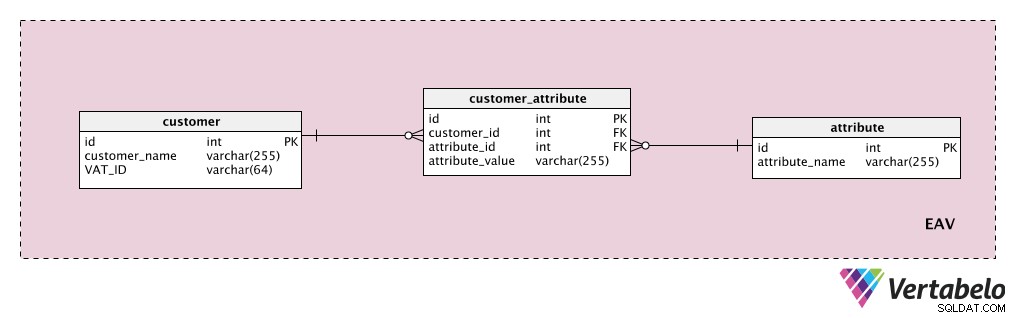
Eerst voegen we een woordenboek toe met een lijst van alle mogelijke eigenschappen die we aan een klant kunnen toewijzen. Dit is het "attribute " tafel. Het kan eigenschappen bevatten zoals "klantwaarde", "contactgegevens", "aanvullende informatie" enz. Het "customer_attribute ” tabel bevat een lijst van alle attributen, met waarden, voor elke klant. Voor elke klant hebben we alleen records voor de kenmerken die ze hebben, en we slaan de "attribute_value ” voor dat kenmerk.
Dit kan echt geweldig lijken. Het zou ons in staat stellen om gemakkelijk nieuwe eigenschappen toe te voegen (omdat we ze toevoegen als waarden in de "customer_attribute " tafel). Zo vermijden we het aanbrengen van wijzigingen in de database. Bijna te mooi om waar te zijn.
En het is te goed. Hoewel het model de gegevens zal opslaan die we nodig hebben, is het werken met dergelijke gegevens veel gecompliceerder. En dat omvat bijna alles, van het schrijven van eenvoudige SELECT-query's tot het verkrijgen van alle klantgerelateerde waarden tot het invoegen, bijwerken of verwijderen van waarden.
Kortom, we moeten de EAV-structuur vermijden. Als je het moet gebruiken, gebruik het dan alleen als je 100% zeker weet dat het echt nodig is.
#7 Een GUID/UUID gebruiken als primaire sleutel
Een GUID (Globally Unique Identifier) is een 128-bits nummer dat wordt gegenereerd volgens de regels die zijn gedefinieerd in RFC 4122. Ze worden soms ook wel UUID's (Universally Unique Identifiers) genoemd. Het belangrijkste voordeel van een GUID is dat deze uniek is; de kans dat u twee keer dezelfde GUID raakt, is echt onwaarschijnlijk. Daarom lijken GUID's een goede kandidaat voor de primaire sleutelkolom. Maar dat is niet het geval.
Een algemene regel voor primaire sleutels is dat we een integerkolom gebruiken met de autoincrement-eigenschap ingesteld op "yes". Dit zal gegevens in sequentiële volgorde toevoegen aan de primaire sleutel en optimale prestaties leveren. Zonder een sequentiële sleutel of een tijdstempel is er geen manier om te weten welke gegevens het eerst zijn ingevoegd. Dit probleem doet zich ook voor wanneer we UNIEKE echte waarden gebruiken (bijvoorbeeld een btw-nummer). Hoewel ze UNIEKE waarden bevatten, zijn ze geen goede primaire sleutels. Gebruik ze in plaats daarvan als alternatieve toetsen.
Een aanvullende opmerking: Ik geef er de voorkeur aan om automatisch gegenereerde integer-attributen met één kolom als primaire sleutel te gebruiken. Het is absoluut de beste praktijk. Ik raad je aan om geen samengestelde primaire sleutels te gebruiken.
#8 Onvoldoende indexering
Indexen zijn een zeer belangrijk onderdeel van het werken met databases, maar een grondige bespreking ervan valt buiten het bestek van dit artikel. Gelukkig hebben we al een paar artikelen met betrekking tot indexen die u kunt bekijken voor meer informatie:- Wat is een database-index?
- Alles over indexen:de basisprincipes
- Alles over indexen, deel 2:MySQL-indexstructuur en prestaties
De korte versie is dat ik u aanraad om een index toe te voegen waar u verwacht dat deze nodig zal zijn. Je kunt ze ook toevoegen nadat de database in productie is, als je merkt dat het toevoegen van een index op een bepaalde plek de prestaties zal verbeteren.
#9 Redundante gegevens
Redundante gegevens moeten in het algemeen in elk model worden vermeden. Het neemt niet alleen extra schijfruimte in beslag, maar vergroot ook de kans op problemen met gegevensintegriteit aanzienlijk. Als iets overbodig moet zijn, moeten we ervoor zorgen dat de originele gegevens en de "kopie" altijd in consistente toestand zijn. Er zijn zelfs situaties waarin redundante gegevens wenselijk zijn:
- In sommige gevallen moeten we prioriteit toekennen aan een bepaalde actie - en om dit te laten gebeuren, moeten we complexe berekeningen uitvoeren. Deze berekeningen kunnen veel tabellen gebruiken en veel bronnen verbruiken. In dergelijke gevallen is het verstandig om deze berekeningen buiten kantooruren uit te voeren (om prestatieproblemen tijdens werkuren te voorkomen). Als we het op deze manier doen, kunnen we die berekende waarde opslaan en later gebruiken zonder deze opnieuw te hoeven berekenen. Natuurlijk is de waarde overbodig; wat we echter aan prestaties winnen, is aanzienlijk meer dan wat we verliezen (wat ruimte op de harde schijf).
- We kunnen ook een kleine set rapportagegegevens in de database opslaan. Aan het eind van de dag bewaren we bijvoorbeeld het aantal telefoontjes dat we die dag hebben gedaan, het aantal succesvolle verkopen, enz. Rapportagegegevens mogen alleen op deze manier worden opgeslagen als we ze vaak moeten gebruiken. Nogmaals, we verliezen een beetje ruimte op de harde schijf, maar we vermijden het opnieuw berekenen van gegevens of het verbinden met de rapportagedatabase (als we die hebben).
In de meeste gevallen zouden we geen overtollige gegevens moeten gebruiken omdat:
- Het meer dan eens opslaan van dezelfde gegevens in de database kan de gegevensintegriteit beïnvloeden. Als u de naam van een klant op twee verschillende plaatsen opslaat, moet u op beide plaatsen tegelijkertijd wijzigingen aanbrengen (invoegen/bijwerken/verwijderen). Dit bemoeilijkt ook de code die je nodig hebt, zelfs voor de eenvoudigste handelingen.
- Hoewel we enkele geaggregeerde getallen in onze operationele database zouden kunnen opslaan, zouden we dit alleen moeten doen als dat echt nodig is. Een operationele database is niet bedoeld om rapportagegegevens op te slaan, en het mengen van deze twee is over het algemeen een slechte gewoonte. Iedereen die rapporten maakt, zal dezelfde middelen moeten gebruiken als gebruikers die aan operationele taken werken; rapportagequery's zijn meestal complexer en kunnen de prestaties beïnvloeden. Daarom moet u uw operationele database en uw rapportagedatabase scheiden.
Nu is het jouw beurt om te wegen
Ik hoop dat het lezen van dit artikel u nieuwe inzichten heeft gegeven en u zal aanmoedigen om best practices voor gegevensmodellering te volgen. Ze zullen je wat tijd besparen!
Heb je een van de problemen ervaren die in dit artikel worden genoemd? Denk je dat we iets belangrijks hebben gemist? Of vind je dat we iets van onze lijst moeten schrappen? Vertel het ons in de reacties hieronder.