Dit artikel gaat over T-SQL (Transact-SQL) vensterfuncties en hun basisgebruik in dagelijkse gegevensanalysetaken.
Er zijn veel alternatieven voor T-SQL als het gaat om data-analyse. Wanneer echter verbeteringen in de loop van de tijd en de introductie van Window-functies worden overwogen, is T-SQL in staat om gegevensanalyse uit te voeren op een basisniveau en, in sommige gevallen, zelfs daarbuiten.
Over SQL-vensterfuncties
Laten we eerst vertrouwd raken met SQL Window-functies in de context van de Microsoft-documentatie.
Microsoft-definitie
Een vensterfunctie berekent een waarde voor elke rij in het venster.
Eenvoudige definitie
Een vensterfunctie helpt ons om ons te concentreren op een bepaald deel (venster) van de resultatenset, zodat we gegevensanalyse alleen op dat specifieke deel (venster) kunnen uitvoeren, in plaats van op de hele resultatenset.
Met andere woorden, SQL-vensterfuncties zetten een resultatenset om in verschillende kleinere sets voor gegevensanalysedoeleinden.
Wat is een resultaatset
Simpel gezegd, een resultatenset bestaat uit alle records die zijn opgehaald door een SQL-query uit te voeren.
We kunnen bijvoorbeeld een tabel maken met de naam Product en voeg de volgende gegevens in:
-- (1) Create the Product table CREATE TABLE [dbo].[Product] ( [ProductId] INT NOT NULL PRIMARY KEY, [Name] VARCHAR(40) NOT NULL, [Region] VARCHAR(40) NOT NULL ) -- (2) Populate the Product table INSERT INTO Product (ProductId,Name,Region) VALUES (1,'Laptop','UK'),(2,'PC','UAE'),(3,'iPad','UK')
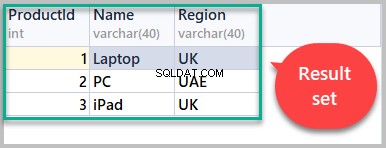
De resultatenset die is opgehaald met behulp van het onderstaande script, bevat nu alle rijen van het Product tafel:
-- (3) Result set SELECT [ProductId], [Name],[Region] FROM Product
Wat is een venster
Het is belangrijk om eerst het concept van een venster te begrijpen, aangezien het betrekking heeft op SQL-vensterfuncties. In deze context is een venster slechts een manier om uw bereik te verkleinen door een specifiek deel van de resultatenset te targeten (zoals we hierboven al vermeldden).
U vraagt zich nu misschien af:wat betekent 'targeten op een specifiek deel van de resultatenset' eigenlijk?
Terugkerend naar het voorbeeld dat we hebben bekeken, kunnen we een SQL-venster maken op basis van de productregio door de resultaatset in twee vensters te verdelen.
Rijnummer() begrijpen
Om verder te gaan, moeten we de functie Row_Number() gebruiken die tijdelijk een volgnummer geeft aan de uitvoerrijen.
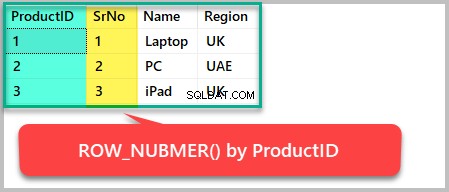
Als we bijvoorbeeld rijnummers willen toevoegen aan de resultatenset op basis van ProductID, we moeten ROW_NUMBER() . gebruiken om het als volgt op product-ID te bestellen:
--Using the row_number() function to order the result set by ProductID SELECT ProductID,ROW_NUMBER() OVER (ORDER BY ProductID) AS SrNo,Name,Region FROM Product
Als we nu de functie Row_Number() . willen om het resultaat te bestellen dat is ingesteld door ProductID aflopend, dan de volgorde van uitvoerrijen op basis van ProductID zal als volgt veranderen:
--Using the row_number() function to order the result set by ProductID descending SELECT ProductID,ROW_NUMBER() OVER (ORDER BY ProductID DESC) AS SrNo,Name,Region FROM Product

Er zijn nog geen SQL-vensters, omdat het enige dat we hebben gedaan, de set op specifieke criteria is gerangschikt. Zoals eerder besproken, betekent windowing het opsplitsen van de resultatenset in verschillende kleinere sets om ze elk afzonderlijk te analyseren.
Een venster maken met Row_Number()
Om een SQL-venster in onze resultatenset te maken, moeten we het partitioneren op basis van een van de kolommen die het bevat.
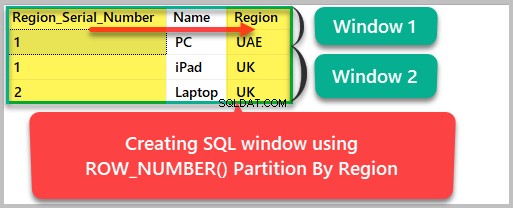
We kunnen het resultaat dat per regio is ingesteld nu als volgt indelen:
--Creating a SQL window based on Region SELECT ROW_NUMBER() OVER (Partition by region ORDER BY Region) as Region_Serial_Number , Name, Region FROM dbo.Product
Selecteren – Over clausule
Met andere woorden, Selecteer met de Over clausule maakt de weg vrij voor SQL-vensterfuncties door een resultaatset op te delen in kleinere vensters.
Volgens de Microsoft-documentatie, Selecteer met de Over clausule definieert een venster dat vervolgens door elke vensterfunctie kan worden gebruikt.
Laten we nu een tabel maken met de naam KitchenProduct als volgt:
CREATE TABLE [dbo].[KitchenProduct]
(
[KitchenProductId] INT NOT NULL PRIMARY KEY IDENTITY(1,1),
[Name] VARCHAR(40) NOT NULL,
[Country] VARCHAR(40) NOT NULL,
[Quantity] INT NOT NULL,
[Price] DECIMAL(10,2) NOT NULL
);
GO
INSERT INTO dbo.KitchenProduct
(Name, Country, Quantity, Price)
VALUES
('Kettle','Germany',10,15.00)
,('Kettle','UK',20,12.00)
,('Toaster', 'France',10,10.00)
,('Toaster','UAE',10,12.00)
,('Kitchen Clock','UK',50,20.00)
,('Kitchen Clock','UAE',35,15.00) Laten we nu de tabel bekijken:
SELECT [KitchenProductId], [Name], [Country], [Quantity], [Price] FROM dbo.KitchenProduct

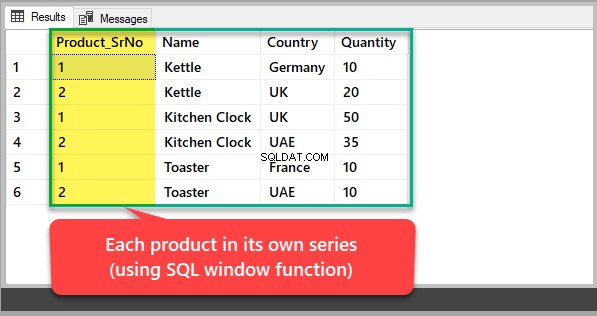
Als u elk product met zijn eigen serienummer wilt zien in plaats van een nummer op basis van de algemene product-ID, dan moet u een SQL-vensterfunctie gebruiken om de resultatenset als volgt op product te partitioneren:
-- Viewing each product in its own series SELECT ROW_NUMBER() OVER (Partition by Name order by Name) Product_SrNo,Name,Country,Quantity FROM dbo.KitchenProduct
Compatibiliteit (Selecteren – Over Clausule)
Volgens Microsoft-documentatie , Select – Over Clause is compatibel met de volgende SQL-databaseversies:
- SQL Server 2008 en hoger
- Azure SQL-database
- Azure SQL Data Warehouse
- Parallel datawarehouse
Syntaxis
SELECT – OVER (Partition by
Houd er rekening mee dat ik de syntaxis heb vereenvoudigd om i t gemakkelijk te begrijpen; raadpleeg s.v.p. de Microsoft-documentatie om de . te zien vol syntaxis.
Vereisten
Dit artikel is in principe geschreven voor beginners, maar er zijn nog enkele vereisten waarmee rekening moet worden gehouden.
Bekendheid met T-SQL
Dit artikel gaat ervan uit dat de lezers een basiskennis van T-SQL hebben en in staat zijn om basis SQL-scripts te schrijven en uit te voeren.
Stel de voorbeeldtabel voor verkoop in
Dit artikel vereist de volgende voorbeeldtabel zodat we onze SQL-vensterfunctievoorbeelden kunnen uitvoeren:
-- (1) Create the Sales sample table
CREATE TABLE [dbo].[Sales]
(
[SalesId] INT NOT NULL IDENTITY(1,1),
[Product] VARCHAR(40) NOT NULL,
[Date] DATETIME2,
[Revenue] DECIMAL(10,2),
CONSTRAINT [PK_Sales] PRIMARY KEY ([SalesId])
);
GO
-- (2) Populating the Sales sample table
SET IDENTITY_INSERT [dbo].[Sales] ON
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (1, N'Laptop', N'2017-01-01 00:00:00', CAST(200.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (2, N'PC', N'2017-01-01 00:00:00', CAST(100.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (3, N'Mobile Phone', N'2018-01-01 00:00:00', CAST(300.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (4, N'Accessories', N'2018-01-01 00:00:00', CAST(150.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (5, N'iPad', N'2019-01-01 00:00:00', CAST(300.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (6, N'PC', N'2019-01-01 00:00:00', CAST(200.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (7, N'Laptop', N'2019-01-01 00:00:00', CAST(300.00 AS Decimal(10, 2)))
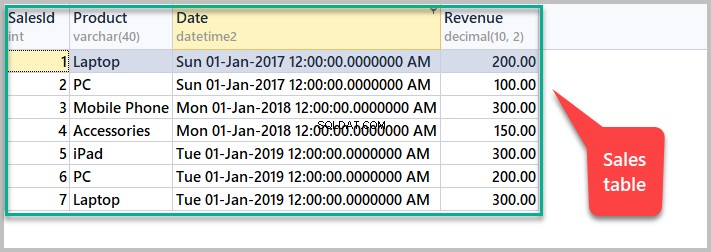
SET IDENTITY_INSERT [dbo].[Sales] OFF Bekijk alle verkopen door het volgende script uit te voeren:
-- View sales SELECT [SalesId],[Product],[Date],[Revenue] FROM dbo.Sales
Groeperen op vs SQL-vensterfuncties
Je kunt je afvragen:wat is het verschil tussen het gebruik van de Group By-clausule en SQL-vensterfuncties?
Welnu, het antwoord ligt in de onderstaande voorbeelden.
Groep op voorbeeld
Om de totale verkoop per product te zien, kunnen we Group By als volgt gebruiken:
-- Total sales by product using Group By SELECT Product ,SUM(REVENUE) AS Total_Sales FROM dbo.Sales GROUP BY Product ORDER BY Product

Dus de Group By-clausule helpt ons de totale verkoop te zien. De totale verkoopwaarde is de som van de omzet voor alle vergelijkbare producten in dezelfde rij zonder dat er een Group By-clausule wordt gebruikt. Wat als we geïnteresseerd zijn in het zien van de opbrengst (verkoop) van elk afzonderlijk product samen met de totale verkoop?
Dit is waar SQL-vensterfuncties in actie komen.
Voorbeeld van SQL-vensterfunctie
Om het product, de omzet en de totale omzet van alle vergelijkbare producten te zien, moeten we de gegevens op bijproductbasis verdelen met OVER() als volgt:
-- Total sales by product using an SQL window function SELECT Product ,REVENUE ,SUM(REVENUE) OVER (PARTITION BY PRODUCT) AS Total_Sales FROM dbo.Sales
De uitvoer zou als volgt moeten zijn:

We kunnen nu dus gemakkelijk de verkoop voor elk afzonderlijk product zien, samen met de totale verkoop voor dat product. Bijvoorbeeld de opbrengst voor PC is 100,00 maar totale verkoop (som van de omzet voor de pc product) is 300,00 omdat er twee verschillende pc-modellen werden verkocht.
Basisanalyse met de aggregatiefuncties
Geaggregeerde functies retourneren een enkele waarde na het uitvoeren van berekeningen op een set gegevens.
In deze sectie gaan we de SQL-vensterfuncties verder verkennen, met name door ze samen met geaggregeerde functies te gebruiken om basisgegevensanalyse uit te voeren.
Algemene aggregatiefuncties
De meest voorkomende aggregatiefuncties zijn:
- Som
- Tellen
- Min
- Max
- Gemiddeld (gemiddeld)
Geaggregeerde gegevensanalyse per product
Om de resultatenset op een bijproductbasis te analyseren met behulp van geaggregeerde functies, moeten we gewoon een aggregatiefunctie gebruiken met een bijproductpartitie in de OVER()-instructie:
-- Data analysis by product using aggregate functions SELECT Product,Revenue ,SUM(REVENUE) OVER (PARTITION BY PRODUCT) as Total_Sales ,MIN(REVENUE) OVER (PARTITION BY PRODUCT) as Minimum_Sales ,MAX(REVENUE) OVER (PARTITION BY PRODUCT) as Maximum_Sales ,AVG(REVENUE) OVER (PARTITION BY PRODUCT) as Average_Sales FROM dbo.Sales

Als u de pc . van dichterbij bekijkt oflaptop producten, u zult zien hoe geaggregeerde functies samenwerken naast de SQL-vensterfunctie.
In het bovenstaande voorbeeld kunnen we zien dat de waarde Opbrengst voor PC is de eerste keer 100,00 en de volgende keer 200,00, maar de totale verkoop bedraagt 300,00. De vergelijkbare informatie is te zien voor de rest van de geaggregeerde functies.
Geaggregeerde gegevensanalyse op datum
Laten we nu wat gegevensanalyse van de producten uitvoeren op datumbasis met behulp van SQL-vensterfuncties in combinatie met aggregatiefuncties.
Deze keer gaan we het resultaat als volgt indelen op datum in plaats van op product:
-- Data analysis by date using aggregate functions SELECT Product,date,Revenue ,SUM(REVENUE) OVER (PARTITION BY DATE) as Total_Sales ,MIN(REVENUE) OVER (PARTITION BY DATE) as Minimum_Sales ,MAX(REVENUE) OVER (PARTITION BY DATE) as Maximum_Sales ,AVG(REVENUE) OVER (PARTITION BY DATE) as Average_Sales FROM dbo.Sales
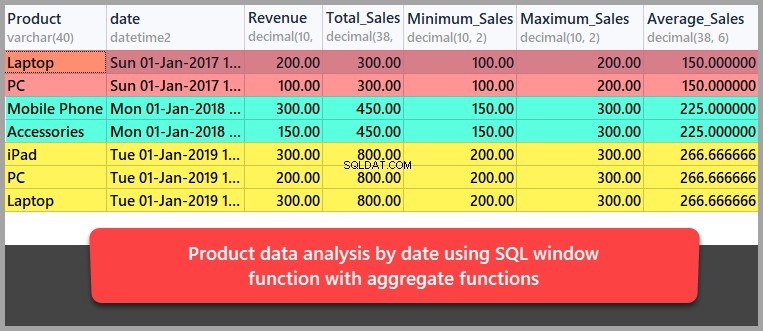
Hiermee hebben we basistechnieken voor gegevensanalyse geleerd met behulp van de benadering van SQL-vensterfuncties.
Dingen om te doen
Nu u bekend bent met de SQL-vensterfuncties, kunt u het volgende proberen:
- Rekening houdend met de voorbeelden die we hebben bekeken, voer basisgegevensanalyse uit met behulp van SQL-vensterfuncties op de voorbeelddatabase die in dit artikel wordt genoemd.
- Een kolom Klant toevoegen aan de voorbeeldtabel Verkoop en zien hoe rijk uw gegevensanalyse kan worden wanneer er een andere kolom (klant) aan wordt toegevoegd.
- Een kolom Regio toevoegen aan de voorbeeldtabel Verkoop en basisgegevensanalyse uitvoeren met behulp van geaggregeerde functies per regio.