Het relationele model van gegevensbeheer werd voor het eerst ontwikkeld door Dr. Edgar F. Codd in 1969. Moderne relationele databasebeheersystemen (RDBMS'en) zijn afgestemd op het paradigma. De sleutelstructuur die wordt geïdentificeerd met RDBMS is de logische structuur die een "tabel" wordt genoemd. Tabellen bestaan voornamelijk uit rijen en kolommen (ook wel records en attributen of tupels en velden genoemd). In strikte wiskundige zin is de term tabel wordt eigenlijk een relatie genoemd en verklaart de term "Relationeel Model". In de wiskunde is een relatie een weergave van een verzameling.
Het expression attribuut geeft een goede beschrijving van het doel van een kolom – het karakteriseert de reeks rijen die ermee verbonden zijn. Elke kolom moet van een bepaald gegevenstype zijn en elke rij moet een aantal unieke identificerende kenmerken hebben die "sleutels" worden genoemd. Het wijzigen van gegevens is doorgaans efficiënter wanneer het relationele model wordt gebruikt, terwijl het ophalen van gegevens sneller kan zijn met het oudere hiërarchische model dat opnieuw is gedefinieerd in model NoSQL-systemen.
Gegevensnormalisatie is een wiskundig proces waarbij bedrijfsgegevens worden gemodelleerd in een vorm die ervoor zorgt dat elke entiteit wordt weergegeven door één enkele relatie (tabel). De vroege voorstanders van het relationele model stelden een concept van normaalvormen voor. Edgar Codd definieerde de eerste, de tweede en derde normaalvorm. Hij werd toen vergezeld door Raymond F. Boyce. Samen definieerden ze de Boyce-Codd Normal Form. Inmiddels zijn er theoretisch zes normaalvormen gedefinieerd, maar in de meeste praktische toepassingen breiden we normalisatie doorgaans uit tot de derde normaalvorm. Elke normale vorm streeft ernaar afwijkingen tijdens het wijzigen van gegevens te voorkomen en de redundantie en afhankelijkheid van gegevens in een tabel te verminderen. Elk normalisatieniveau heeft de neiging om meer tabellen te introduceren, redundantie te verminderen, de eenvoud van elke tabel te vergroten, maar verhoogt ook de complexiteit van het gehele relationele databasebeheersysteem. Dus structureel zijn RDBM-systemen vaak complexer dan hiërarchische systemen.
Waarom databasenormalisatie:vier afwijkingen
Gegevensopslag zonder normalisatie veroorzaakt een aantal problemen met het gegevensverbruik. De voorstanders van normalisering noemden dergelijke problemen anomalieën. Laten we, om deze anomalieën te beschrijven, eens kijken naar de gegevens in Fig. 1.

Afb. 1 Staftabel
Lijst 1. Basistabel om databasenormalisatie aan te tonen.
1.1. Tabel maken
use privatework go create table staffers ( staffID int identity (1,1) ,StaffName varchar(50) ,Role varchar(50) ,Department varchar (100) ,Manager varchar (50) ,Gender char(1) ,DateofBirth datetime2 )
1.2. Rijen invoegen
insert into staffers values ('John Doe','Engineering','Kweku Amarh','M','06-Oct-1965');
insert into staffers values ('Henry Ofori','Engineering','Kweku Amarh','M','06-Mar-1982');
insert into staffers values ('Jessica Yuiah','Engineering','Kweku Amarh','F','06-Oct-1965');
insert into staffers values ('Ahmed Assah','Engineering','Kweku Amarh','M','06-Oct-1965'); 1.3. Doorzoek de tabel
select * from staffers;
Deze tabel vertegenwoordigt in wezen twee sets gegevens die per ongeluk zijn gecombineerd:namen van medewerkers en afdelingen. Merk op dat alle medewerkers van dezelfde afdeling zijn:Engineering. Dat is gedaan voor de eenvoud en om normalisatie aan te tonen. Er zijn drie hoofdproblemen verbonden aan het manipuleren van deze structuur:
De invoegafwijking
Om een nieuw record in te voegen, moeten we de namen van afdelingen en managers blijven herhalen.
De verwijderingsafwijking
Om het record van een medewerker te verwijderen, moeten we ook de bijbehorende manager en afdeling verwijderen. Als het nodig is om ALLE stafgegevens te verwijderen, moeten we ook alle afdelingen en alle managers verwijderen.
De updateafwijking
Als het nodig is om de manager van een afdeling te wijzigen, moeten we de wijziging in elke afzonderlijke rij van deze tabel aanbrengen, aangezien de waarden voor elke medewerker worden gedupliceerd.
Database normale formulieren
In de volgende paragrafen van het artikel zullen we proberen de 1e, de 2e en de 3e normaalvorm te beschrijven die veel vaker voorkomt in echte RDBM-systemen. Er zijn andere uitbreidingen van de theorie, zoals de vierde, de vijfde en Boyce-Codd-normaalvorm, maar in dit artikel zullen we ons beperken tot drie normale vormen.
De eerste normaalvorm
De 1e normaalvorm wordt gedefinieerd door vier regels:
Elke kolom moet waarden van hetzelfde gegevenstype bevatten.
De Staffers-tabel voldoet al aan deze regel.
Elke kolom in een tabel moet atomair zijn.
Dit betekent in wezen dat u de inhoud van een kolom moet verdelen totdat ze niet langer kunnen worden verdeeld. Merk op dat de Rol kolom in de Personeels tabel breekt regel 2 voor de rij met StaffID=3.
Elke rij in een tabel moet uniek zijn.
Uniekheid in genormaliseerde tabellen wordt meestal bereikt met behulp van primaire sleutels. Een primaire sleutel definieert op unieke wijze elke rij in een tabel. Meestal wordt een primaire sleutel gedefinieerd door slechts één kolom. Een primaire sleutel die uit meer dan één kolom bestaat, wordt een samengestelde sleutel genoemd.
De volgorde waarin records worden opgeslagen, doet er niet toe.
Om de gegevens in de Staffers uit te lijnen tabel met de principes van de eerste normaalvorm moeten we de tabel splitsen zoals weergegeven in figuren 2, 3 en 4.
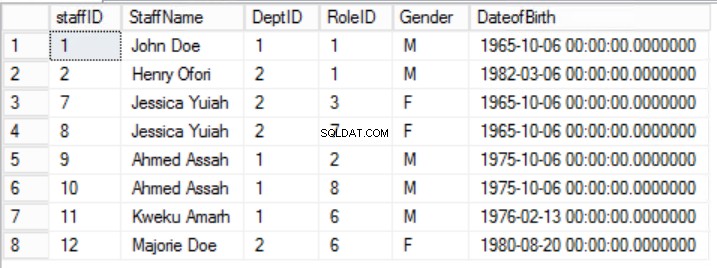
Afb. 2 Staftafel
We hebben de gegevens in de Staffers beperkt table en implementeerde een Composite Primary Key om uniciteit te garanderen. We hebben ook twee extra tabellen gemaakt Rollen en Afdelingen die relaties hebben met de kern Staffers tabel geïmplementeerd met behulp van Foreign Keys. Bekijk de DDL in listing 2.
Lijst 2. DDL van nieuwe Staffers Tabel voor de eerste normaalvorm.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID] [int] NOT NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC, [RoleID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([RoleID]) REFERENCES [dbo].[Roles] ([RoleID]) GO
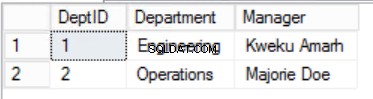
Afb. Tabel met 3 afdelingen
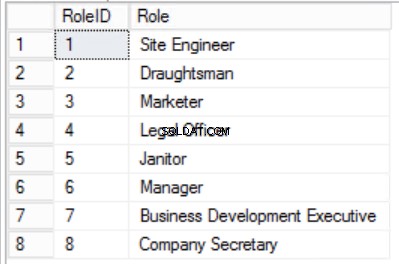
Afb. Tabel met 4 rollen
De tweede normaalvorm
De eerste normaalvorm moet al aanwezig zijn.
Elke niet-sleutelkolom mag geen gedeeltelijke afhankelijkheid van de primaire sleutel hebben.
De strekking van de tweede regel is dat alle kolommen van de tabel afhankelijk moeten zijn van alle kolommen die samen de primaire sleutel vormen. Als we terugkijken naar de tabellen in de figuren 2, 3 en 4, zien we dat we aan alle vereisten van de eerste normaalvorm hebben voldaan. We hebben ook voldaan aan de vereisten van de tweede normaalvorm voor twee tabellen rollen en Afdelingen . In het geval van de Staffers tafel, we hebben nog steeds een probleem. Onze primaire sleutel is samengesteld uit de kolommen StaffID en RoleID.
Regel 2 van de tweede normaalvorm wordt hier overtreden door het feit dat het geslacht en de geboortedatum van het personeel niet afhankelijk zijn van de RoleID. Er is een gedeeltelijke afhankelijkheid.
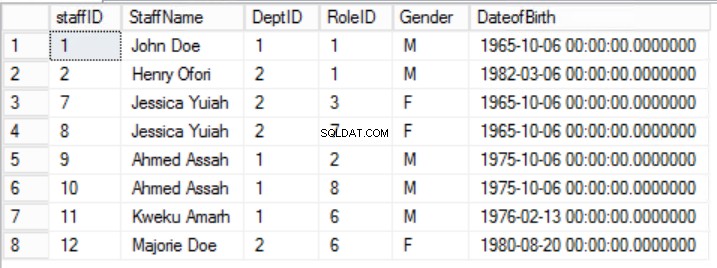
Afb. 5 stafleden voor de eerste normaalvorm
In het gegeven voorbeeld kunnen we proberen dit op te lossen door RoleID uit de primaire sleutel te verwijderen, maar als we dit doen, overtreden we een andere regel:de rol van uniciteit vermeld in de eerste normaalvorm. We moeten een andere aanpak kiezen. We zullen de Staffers wijzigen tafel met dien verstande dat een stafmedewerker meer dan één rol kan spelen. Zie Afb. 6.
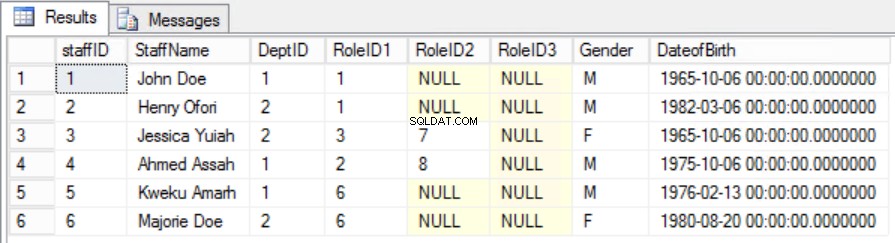
Afb. 6 Staftabel voor de tweede normaalvorm
We zijn erin geslaagd de uniciteit te behouden en gedeeltelijke afhankelijkheid te verwijderen.
Lijst 3. DDL van nieuwe staftabel voor de tweede normaalvorm.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers2NF]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID1] [int] NOT NULL, [RoleID2] [int] NULL, [RoleID3] [int] NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID1]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID2]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID3]) REFERENCES [dbo].[Roles] ([RoleID]) GO
De derde normaalvorm
De 2e normaalvorm moet al aanwezig zijn.
Elke niet-sleutelkolom mag geen transitieve afhankelijkheid van de primaire sleutel hebben.
De strekking van de derde normaalvorm is dat er geen kolommen mogen zijn die afhankelijk zijn van niet-sleutelkolommen, zelfs als die niet-sleutelkolommen al afhankelijk zijn van de primaire sleutel.
Stel bijvoorbeeld dat we hebben besloten een extra kolom toe te voegen aan de Staffers tabel zoals getoond in Fig. 7 om de manager van de staf duidelijk te zien. Door dat te doen zouden we de tweede regel van de derde normale vorm hebben overtreden, omdat de Manager Name afhankelijk is van de DeptID en de DeptID op zijn beurt weer van de StaffID. Dit is een transitieve afhankelijkheid.
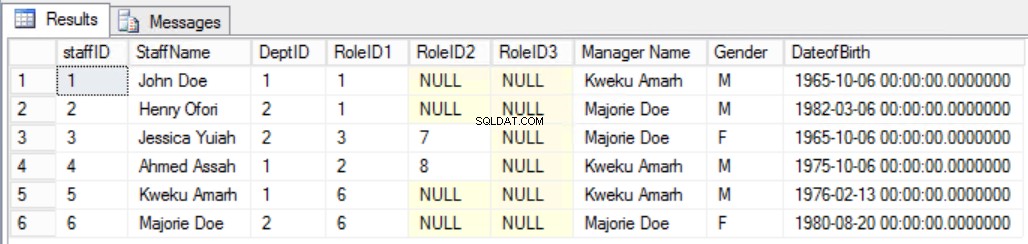
Afb. 7 Staftabel voor de derde normaalvorm (gebroken regel)
Het zou beter zijn om het oude formulier te behouden en de vereiste informatie weer te geven met behulp van een join tussen de Staffers-tabel en de Department-tabel.
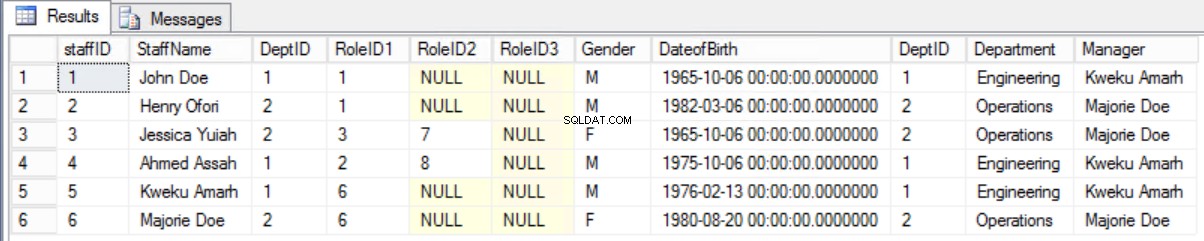
Afb. 8 Samenwerken tussen stafmedewerker en afdeling
Vermelding 4. Query om personeel en managers weer te geven.
select * from staffers2NF s join Department d on s.DeptID=d.DeptID;
Praktische toepassing
De meeste volwassen applicaties implementeren de regels van normalisatie in redelijke mate. We zien dat de implementatie van gegevensnormalisatie aanleiding geeft tot het gebruik van Primary Key Constraints en Foreign Key Constraints. Bovendien komen zaken als het indexeren van buitenlandse sleutels ook aan het licht als we dieper op het onderwerp ingaan. Eerder vermeldden we hoe het gebrek aan normalisatie de vlotte manipulatie van gegevens kan beïnvloeden, zoals beschreven in de invoeg-, verwijderings- en updateanomalieën. Een gebrek aan goede normalisatie kan ook indirect van invloed zijn op de queryprestaties.
Ik ben onlangs een tabel tegengekomen met de vorm zoals weergegeven in tabel 1, die we Customer_Accounts zullen noemen.
S/Nee | Naam | Account_No | Telefoonnr |
1 | Kenneth Igiri | 9922344592 | 2348039988456, 2348039988456, 2348039988456 |
2 | Ernest Doe | 6677554897 | 2348022887546, 2348039988456 |
Tabel 1 Klantaccounts
Het grootste probleem met deze tabel is dat deze de tweede regel van de eerste normaalvorm overtreedt. Het resultaat in ons geval was dat het zoeken naar klanten op basis van hun telefoonnummers het gebruik van een LIKE in de WHERE-clausule en een leidend % vereiste.
Select account_no from Customer_Accounts where Phone_No like ‘%2348039988456%’;
De impact van de bovenstaande constructie was dat de optimizer nooit een index gebruikte, wat een enorm prestatieprobleem was.
Conclusie
Datanormalisatie ligt op het gebied van databaseontwerp en zowel ontwikkelaars als DBA's moeten aandacht besteden aan de regels die in dit artikel worden beschreven. Het is altijd beter om de normalisatie uit te voeren voordat de database in productie gaat. De voordelen van een goed ontworpen relationeel databasebeheersysteem zijn gewoon de moeite waard.