Dit artikel is het zesde deel in een serie over tabeluitdrukkingen. Vorige maand heb ik in deel 5 de logische behandeling van niet-recursieve CTE's behandeld. Deze maand behandel ik de logische behandeling van recursieve CTE's. Ik beschrijf de ondersteuning van T-SQL voor recursieve CTE's, evenals standaardelementen die nog niet door T-SQL worden ondersteund. Ik bied logisch equivalente T-SQL-oplossingen voor de niet-ondersteunde elementen.
Voorbeeldgegevens
Voor voorbeeldgegevens gebruik ik een tabel met de naam Werknemers, die een hiërarchie van werknemers bevat. De empid-kolom vertegenwoordigt het werknemers-ID van de ondergeschikte (het onderliggende knooppunt) en de mgrid-kolom vertegenwoordigt het werknemers-ID van de manager (het bovenliggende knooppunt). Gebruik de volgende code om de tabel Werknemers in de tempdb-database te maken en in te vullen:
SET NOCOUNT ON;
USE tempdb;
DROP TABLE IF EXISTS dbo.Employees;
GO
CREATE TABLE dbo.Employees
(
empid INT NOT NULL
CONSTRAINT PK_Employees PRIMARY KEY,
mgrid INT NULL
CONSTRAINT FK_Employees_Employees REFERENCES dbo.Employees,
empname VARCHAR(25) NOT NULL,
salary MONEY NOT NULL,
CHECK (empid <> mgrid)
);
INSERT INTO dbo.Employees(empid, mgrid, empname, salary)
VALUES(1, NULL, 'David' , $10000.00),
(2, 1, 'Eitan' , $7000.00),
(3, 1, 'Ina' , $7500.00),
(4, 2, 'Seraph' , $5000.00),
(5, 2, 'Jiru' , $5500.00),
(6, 2, 'Steve' , $4500.00),
(7, 3, 'Aaron' , $5000.00),
(8, 5, 'Lilach' , $3500.00),
(9, 7, 'Rita' , $3000.00),
(10, 5, 'Sean' , $3000.00),
(11, 7, 'Gabriel', $3000.00),
(12, 9, 'Emilia' , $2000.00),
(13, 9, 'Michael', $2000.00),
(14, 9, 'Didi' , $1500.00);
CREATE UNIQUE INDEX idx_unc_mgrid_empid
ON dbo.Employees(mgrid, empid)
INCLUDE(empname, salary); Merk op dat de wortel van de werknemershiërarchie - de CEO - een NULL heeft in de mgrid-kolom. Alle overige werknemers hebben een manager, dus hun mgrid-kolom is ingesteld op de werknemers-ID van hun manager.
Afbeelding 1 toont een grafische weergave van de werknemershiërarchie, met de naam, ID en locatie van de werknemer in de hiërarchie.
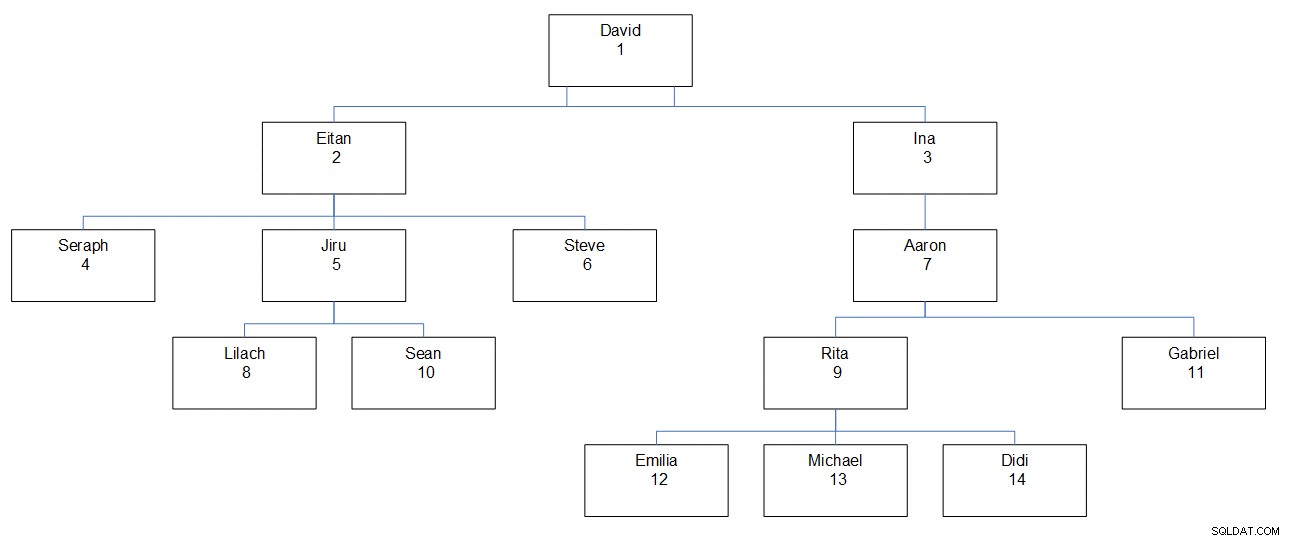 Figuur 1:Werknemershiërarchie
Figuur 1:Werknemershiërarchie
Recursieve CTE's
Recursieve CTE's hebben veel gebruiksscenario's. Een klassieke gebruikscategorie heeft te maken met het hanteren van grafiekstructuren, zoals onze werknemershiërarchie. Taken met grafieken vereisen vaak het doorlopen van paden met een willekeurige lengte. Geef bijvoorbeeld, gegeven de werknemers-ID van een manager, de invoermedewerker terug, evenals alle ondergeschikten van de invoermedewerker op alle niveaus; dat wil zeggen, directe en indirecte ondergeschikten. Als u een bekende kleine limiet had voor het aantal niveaus dat u mogelijk moet volgen (de graad van de grafiek), zou u een query kunnen gebruiken met een join per niveau van ondergeschikten. Als de graad van de grafiek echter potentieel hoog is, wordt het op een gegeven moment onpraktisch om een query met veel joins te schrijven. Een andere optie is om imperatieve iteratieve code te gebruiken, maar dergelijke oplossingen zijn vaak lang. Dit is waar recursieve CTE's echt uitblinken:ze stellen u in staat om declaratieve, beknopte en intuïtieve oplossingen te gebruiken.
Ik begin met de basis van recursieve CTE's voordat ik bij de interessantere dingen kom waar ik zoek- en fietsmogelijkheden behandel.
Onthoud dat de syntaxis van een zoekopdracht tegen een CTE als volgt is:
WITHAS
(
)
Hier laat ik één CTE zien die is gedefinieerd met behulp van de WITH-component, maar zoals u weet, kunt u meerdere CTE's definiëren, gescheiden door komma's.
In reguliere, niet-recursieve CTE's is de innerlijke tabelexpressie gebaseerd op een query die slechts één keer wordt geëvalueerd. In recursieve CTE's is de expressie van de binnenste tabel gebaseerd op doorgaans twee query's die bekend staan als leden , hoewel u er meer dan twee kunt hebben om aan sommige gespecialiseerde behoeften te voldoen. De leden worden doorgaans gescheiden door een UNION ALL-operator om aan te geven dat hun resultaten uniform zijn.
Een lid kan een ankerlid zijn —wat betekent dat het slechts één keer wordt geëvalueerd; of het kan een recursief lid zijn -wat betekent dat het herhaaldelijk wordt geëvalueerd, totdat het een lege resultatenset retourneert. Dit is de syntaxis van een zoekopdracht tegen een recursieve CTE die is gebaseerd op één ankerlid en één recursief lid:
WITHAS
(
UNION ALL
)
Wat een lid recursief maakt, is een verwijzing naar de CTE-naam. Deze referentie vertegenwoordigt de resultatenset van de laatste uitvoering. Bij de eerste uitvoering van het recursieve lid vertegenwoordigt de verwijzing naar de CTE-naam de resultaatset van het ankerlid. In de N-de uitvoering, waarbij N> 1, staat de verwijzing naar de CTE-naam voor de resultaatset van de (N – 1) uitvoering van het recursieve lid. Zoals gezegd, zodra het recursieve lid een lege set retourneert, wordt het niet opnieuw uitgevoerd. Een verwijzing naar de CTE-naam in de buitenste query vertegenwoordigt de uniforme resultaatsets van de enkele uitvoering van het ankerlid en alle uitvoeringen van het recursieve lid.
De volgende code implementeert de bovengenoemde taak van het retourneren van de substructuur van werknemers voor een bepaalde invoermanager, waarbij werknemer-ID 3 wordt doorgegeven als de root-werknemer in dit voorbeeld:
DECLARE @root AS INT = 3;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname
FROM C; De ankerquery wordt slechts één keer uitgevoerd, waarbij de rij wordt geretourneerd voor de invoer root-werknemer (werknemer 3 in ons geval).
De recursieve query voegt zich bij de groep werknemers van het vorige niveau (weergegeven door de verwijzing naar de CTE-naam, alias M voor managers) met hun directe ondergeschikten uit de tabel Werknemers, alias S voor ondergeschikten. Het join-predikaat is S.mgrid =M.empid, wat betekent dat de mgrid-waarde van de ondergeschikte gelijk is aan de empid-waarde van de manager. De recursieve query wordt als volgt vier keer uitgevoerd:
- Retour ondergeschikten van werknemer 3; output:werknemer 7
- Retour ondergeschikten van medewerker 7; output:medewerkers 9 en 11
- Retour ondergeschikten van medewerkers 9 en 11; uitvoer:12, 13 en 14
- Retour ondergeschikten van werknemers 12, 13 en 14; uitgang:lege set; recursie stopt
De verwijzing naar de CTE-naam in de buitenste query vertegenwoordigt de uniforme resultaten van de enkele uitvoering van de ankerquery (werknemer 3) met de resultaten van alle uitvoeringen van de recursieve query (werknemers 7, 9, 11, 12, 13 en 14). Deze code genereert de volgende uitvoer:
empid mgrid empname ------ ------ -------- 3 1 Ina 7 3 Aaron 9 7 Rita 11 7 Gabriel 12 9 Emilia 13 9 Michael 14 9 Didi
Een veelvoorkomend probleem bij programmeeroplossingen is op hol geslagen code zoals oneindige lussen die doorgaans worden veroorzaakt door een bug. Met recursieve CTE's kan een bug leiden tot een runway-uitvoering van het recursieve lid. Stel bijvoorbeeld dat u in onze oplossing voor het retourneren van de ondergeschikten van een invoermedewerker een fout had in het lidmaatschapspredikaat van het recursieve lid. In plaats van ON S.mgrid =M.empid te gebruiken, gebruikte je ON S.mgrid =S.mgrid, zoals:
DECLARE @root AS INT = 3;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = S.mgrid
)
SELECT empid, mgrid, empname
FROM C; Gegeven ten minste één werknemer met een niet-null manager-ID in de tabel, zal de uitvoering van het recursieve lid een niet-leeg resultaat blijven opleveren. Onthoud dat de impliciete beëindigingsvoorwaarde voor het recursieve lid is wanneer de uitvoering ervan een lege resultaatset retourneert. Als het een niet-lege resultaatset retourneert, voert SQL Server het opnieuw uit. Je realiseert je dat als SQL Server geen mechanisme had om de recursieve uitvoeringen te beperken, het het recursieve lid gewoon voor altijd zou blijven uitvoeren. Als veiligheidsmaatregel ondersteunt T-SQL een MAXRECURSION-queryoptie die het maximaal toegestane aantal uitvoeringen van het recursieve lid beperkt. Deze limiet is standaard ingesteld op 100, maar u kunt deze wijzigen in elke niet-negatieve SMALLINT-waarde, waarbij 0 staat voor geen limiet. Het instellen van de maximale recursielimiet op een positieve waarde N betekent dat de N + 1 poging tot uitvoering van het recursieve lid wordt afgebroken met een fout. Als u bijvoorbeeld de bovenstaande buggy-code ongewijzigd uitvoert, betekent dit dat u vertrouwt op de standaard maximale recursielimiet van 100, dus de 101-uitvoering van het recursieve lid mislukt:
empid mgrid empname ------ ------ -------- 3 1 Ina 2 1 Eitan 3 1 Ina ...Msg 530, Level 16, State 1, Line 121
De instructie is beëindigd. De maximale recursie 100 is uitgeput voordat de verklaring is voltooid.
Stel dat het in uw organisatie veilig is om aan te nemen dat de werknemershiërarchie niet hoger zal zijn dan 6 managementniveaus. U kunt de maximale recursielimiet verlagen van 100 naar een veel kleiner aantal, zoals 10 voor de zekerheid, zoals zo:
DECLARE @root AS INT = 3;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = S.mgrid
)
SELECT empid, mgrid, empname
FROM C
OPTION (MAXRECURSION 10); Als er nu een bug is die resulteert in een runaway-uitvoering van het recursieve lid, wordt deze ontdekt bij de 11 poging tot uitvoering van het recursieve lid in plaats van bij de 101-uitvoering:
empid mgrid empname ------ ------ -------- 3 1 Ina 2 1 Eitan 3 1 Ina ...Msg 530, Level 16, State 1, Line 149
De instructie is beëindigd. De maximale recursie 10 is uitgeput voordat de verklaring is voltooid.
Het is belangrijk op te merken dat de maximale recursielimiet voornamelijk moet worden gebruikt als een veiligheidsmaatregel om de uitvoering van buggy-runaway-code af te breken. Onthoud dat wanneer de limiet wordt overschreden, de uitvoering van de code wordt afgebroken met een fout. Gebruik deze optie niet om het aantal te bezoeken niveaus te beperken voor filterdoeleinden. Je wilt niet dat er een fout wordt gegenereerd als er geen probleem is met de code.
Voor filterdoeleinden kunt u het aantal niveaus beperken dat u programmatisch kunt bezoeken. U definieert een kolom met de naam lvl die het niveaunummer van de huidige werknemer bijhoudt in vergelijking met de ingevoerde rootwerknemer. In de ankerquery stelt u de lvl-kolom in op de constante 0. In de recursieve query stelt u deze in op de lvl-waarde van de manager plus 1. Om zoveel niveaus onder de invoerroot als @maxlevel te filteren, voegt u het predikaat M.lvl <@ toe maxlevel toe aan de ON-clausule van de recursieve query. De volgende code retourneert bijvoorbeeld werknemer 3 en twee niveaus van ondergeschikten van werknemer 3:
DECLARE @root AS INT = 3, @maxlevel AS INT = 2;
WITH C AS
(
SELECT empid, mgrid, empname, 0 AS lvl
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname, M.lvl + 1 AS lvl
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
AND M.lvl < @maxlevel
)
SELECT empid, mgrid, empname, lvl
FROM C; Deze query genereert de volgende uitvoer:
empid mgrid empname lvl ------ ------ -------- ---- 3 1 Ina 0 7 3 Aaron 1 9 7 Rita 2 11 7 Gabriel 2
Standaard SEARCH- en CYCLE-clausules
De ISO/IEC SQL-standaard definieert twee zeer krachtige opties voor recursieve CTE's. Een daarvan is een clausule genaamd SEARCH die de recursieve zoekvolgorde bestuurt, en een andere is een clausule genaamd CYCLE die cycli in de afgelegde paden identificeert. Dit is de standaardsyntaxis voor de twee clausules:
7.18Functie
Specificeer het genereren van informatie over volgorde en cyclusdetectie in het resultaat van recursieve query-expressies.
Formaat
Op het moment van schrijven ondersteunt T-SQL deze opties niet, maar in de volgende links kunt u verzoeken voor functieverbetering vinden waarin wordt gevraagd om hun opname in T-SQL in de toekomst, en hierop stemmen:
In de volgende paragrafen beschrijf ik de twee standaardopties en geef ik ook logisch equivalente alternatieve oplossingen die momenteel beschikbaar zijn in T-SQL.
De standaard SEARCH-clausule definieert de recursieve zoekvolgorde als BREADTH FIRST of DEPTH FIRST door enkele gespecificeerde volgordekolom(men), en creëert een nieuwe reekskolom met de ordinale posities van de bezochte knooppunten. U specificeert BREADTH FIRST om eerst over elk niveau (breedte) en vervolgens naar beneden (diepte) te zoeken. U geeft DEPTH FIRST op om eerst naar beneden (diepte) en vervolgens over (breedte) te zoeken.
U specificeert de SEARCH-component vlak voor de buitenste zoekopdracht.
Ik zal beginnen met een voorbeeld voor de eerste recursieve zoekvolgorde in de breedte. Houd er rekening mee dat deze functie niet beschikbaar is in T-SQL, dus u kunt de voorbeelden die de standaardclausules in SQL Server of Azure SQL Database gebruiken niet daadwerkelijk uitvoeren. De volgende code retourneert de substructuur van werknemer 1, die vraagt om een breedte eerste zoekvolgorde op empid, waardoor een reekskolom wordt gemaakt met de naam seqbreadth met de ordinale posities van de bezochte knooppunten:
Hier is de gewenste uitvoer van deze code:
Raak niet in de war door het feit dat de seqbreadth-waarden identiek lijken te zijn aan de empid-waarden. Dat is puur toeval als gevolg van de manier waarop ik de empid-waarden handmatig heb toegewezen in de voorbeeldgegevens die ik heb gemaakt.
Afbeelding 2 heeft een grafische weergave van de werknemershiërarchie, met een stippellijn die de breedte van de eerste volgorde aangeeft waarin de knooppunten zijn doorzocht. De empid-waarden verschijnen direct onder de namen van de werknemers en de toegewezen seqbreadth-waarden verschijnen in de linkerbenedenhoek van elk vak.
Wat hier interessant is om op te merken, is dat binnen elk niveau de knooppunten worden doorzocht op basis van de opgegeven kolomvolgorde (duidelijk in ons geval), ongeacht de bovenliggende associatie van het knooppunt. Merk bijvoorbeeld op dat in het vierde niveau Lilach als eerste wordt benaderd, Rita als tweede, Sean als derde en Gabriel als laatste. Dat komt omdat van alle medewerkers op het vierde niveau dat hun volgorde is op basis van hun empirische waarden. Het is niet zo dat Lilach en Sean achter elkaar worden gefouilleerd omdat ze directe ondergeschikten zijn van dezelfde manager, Jiru.
Het is vrij eenvoudig om een T-SQL-oplossing te bedenken die het logische equivalent biedt van de standaard SAERCH DEPTH FIRST-optie. Je maakt een kolom met de naam lvl zoals ik eerder heb laten zien om het niveau van het knooppunt te volgen met betrekking tot de wortel (0 voor het eerste niveau, 1 voor het tweede, enzovoort). Vervolgens berekent u de gewenste resultatenreekskolom in de buitenste query met behulp van een ROW_NUMBER-functie. Als venster bestellen geeft u eerst lvl op, en vervolgens de gewenste bestelkolom (duidelijk in ons geval). Hier is de code van de volledige oplossing:
Laten we vervolgens de DEPTH FIRST-zoekvolgorde bekijken. Volgens de standaard moet de volgende code de substructuur van werknemer 1 retourneren, waarbij wordt gevraagd om een eerste zoekvolgorde voor diepte door empid, waarbij een reekskolom wordt gemaakt met de naam seqdepth met de ordinale posities van de gezochte knooppunten:
Hieronder volgt de gewenste uitvoer van deze code:
Als we naar de gewenste query-uitvoer kijken, is het waarschijnlijk moeilijk om erachter te komen waarom de reekswaarden zijn toegewezen zoals ze waren. Figuur 3 zou moeten helpen. Het heeft een grafische weergave van de werknemershiërarchie, met een stippellijn die de diepte van de eerste zoekvolgorde weergeeft, met de toegewezen reekswaarden in de linkerbenedenhoek van elk vak.
Het bedenken van een T-SQL-oplossing die het logische equivalent biedt van de standaard SEARCH DEPTH FIRST-optie is een beetje lastig, maar toch uitvoerbaar. Ik zal de oplossing in twee stappen beschrijven.
In stap 1 berekent u voor elk knooppunt een binair sorteerpad dat is gemaakt van een segment per voorouder van het knooppunt, waarbij elk segment de sorteerpositie van de voorouder onder zijn broers en zussen weergeeft. Je bouwt dit pad op dezelfde manier als de manier waarop je de lvl-kolom berekent. Dat wil zeggen, begin met een lege binaire tekenreeks voor het hoofdknooppunt in de ankerquery. Vervolgens voegt u in de recursieve query het pad van de ouder samen met de sorteerpositie van het knooppunt tussen broers en zussen nadat u het naar een binair segment hebt geconverteerd. U gebruikt de ROW_NUMBER-functie om de positie te berekenen, gepartitioneerd door de ouder (mgrid in ons geval) en geordend op de relevante bestelkolom (empid in ons geval). U converteert het rijnummer naar een binaire waarde van voldoende grootte, afhankelijk van het maximale aantal directe kinderen dat een ouder in uw grafiek kan hebben. BINARY(1) ondersteunt tot 255 kinderen per ouder, BINARY(2) ondersteunt 65.535, BINARY(3):16.777.215, BINARY(4):4.294.967.295. In een recursieve CTE moeten de corresponderende kolommen in de anker- en recursieve zoekopdrachten van hetzelfde type en grootte zijn , zorg er dus voor dat u het sorteerpad in beide converteert naar een binaire waarde van dezelfde grootte.
Hier is de code die stap 1 in onze oplossing implementeert (ervan uitgaande dat BINARY(1) voldoende is per segment, wat betekent dat u niet meer dan 255 directe ondergeschikten per manager heeft):
Deze code genereert de volgende uitvoer:
Merk op dat ik een lege binaire tekenreeks heb gebruikt als het sorteerpad voor het hoofdknooppunt van de enkele substructuur die we hier opvragen. Als het ankerlid mogelijk meerdere wortels van de substructuur kan retourneren, begin dan gewoon met een segment dat is gebaseerd op een ROW_NUMBER-berekening in de ankerquery, vergelijkbaar met de manier waarop u deze berekent in de recursieve query. In dat geval is uw sorteerpad één segment langer.
Wat je in stap 2 nog moet doen, is het creëren van de gewenste resultaat seq depth-kolom door rijnummers te berekenen die zijn geordend op sortpath in de buitenste query, zoals zo
Deze oplossing is het logische equivalent van het gebruik van de standaard SEARCH DIEPTH FIRST-optie die eerder is weergegeven, samen met de gewenste uitvoer.
Als je eenmaal een sequentiekolom hebt die de eerste zoekvolgorde van diepte weergeeft (seqdepth in ons geval), kun je met een klein beetje meer moeite een heel mooie visuele weergave van de hiërarchie genereren. Je hebt ook de bovengenoemde lvl-kolom nodig. U bestelt de buitenste query op de reekskolom. Je retourneert een attribuut dat je wilt gebruiken om het knooppunt weer te geven (zeg, empname in ons geval), voorafgegaan door een tekenreeks (zeg ' | ') die lvl keer is gerepliceerd. Hier is de volledige code om zo'n visuele afbeelding te bereiken:
Deze code genereert de volgende uitvoer:
Dat is best gaaf!
Grafiekstructuren kunnen cycli hebben. Die cycli kunnen geldig of ongeldig zijn. Een voorbeeld van geldige cycli is een grafiek die snelwegen en wegen weergeeft die steden en dorpen met elkaar verbinden. Dat is wat een cyclische grafiek wordt genoemd . Omgekeerd mag een grafiek die een werknemershiërarchie weergeeft, zoals in ons geval, geen cycli hebben. Dat is wat een acyclische wordt genoemd grafiek. Stel echter dat u door een foutieve update onbedoeld een cyclus krijgt. Stel bijvoorbeeld dat u per ongeluk de manager-ID van de CEO (werknemer 1) bijwerkt naar werknemer 14 door de volgende code uit te voeren:
U heeft nu een ongeldige cyclus in de werknemershiërarchie.
Of cycli nu geldig of ongeldig zijn, wanneer u de grafiekstructuur doorloopt, wilt u zeker niet herhaaldelijk een cyclisch pad volgen. In beide gevallen wil je stoppen met het volgen van een pad zodra een niet-eerste exemplaar van hetzelfde knooppunt is gevonden, en een dergelijk pad markeren als cyclisch.
Dus wat gebeurt er als je een grafiek met cycli opvraagt met een recursieve zoekopdracht, zonder dat er een mechanisme is om die te detecteren? Dit is afhankelijk van de uitvoering. In SQL Server bereikt u op een gegeven moment de maximale recursielimiet en wordt uw zoekopdracht afgebroken. Bijvoorbeeld, aangenomen dat u de bovenstaande update hebt uitgevoerd die de cyclus introduceerde, probeer dan de volgende recursieve query uit te voeren om de substructuur van werknemer 1 te identificeren:
Aangezien deze code geen expliciete maximale recursielimiet instelt, wordt de standaardlimiet van 100 aangenomen. SQL Server breekt de uitvoering van deze code af voordat deze is voltooid en genereert een fout:
De SQL-standaard definieert een clausule met de naam CYCLE voor recursieve CTE's, waardoor u cycli in uw grafiek kunt verwerken. U geeft deze clausule op vlak voor de buitenste query. Als er ook een SEARCH-component aanwezig is, geeft u deze eerst op en vervolgens de CYCLE-component. Dit is de syntaxis van de CYCLE-clausule:
De detectie van een cyclus is gebaseerd op de gespecificeerde cycluskolomlijst . In onze werknemershiërarchie zou u bijvoorbeeld waarschijnlijk de empid-kolom voor dit doel willen gebruiken. Wanneer dezelfde empid-waarde voor de tweede keer verschijnt, wordt een cyclus gedetecteerd en vervolgt de query een dergelijk pad niet verder. U specificeert een nieuwe cyclusmarkeringskolom die aangeeft of een cyclus is gevonden of niet, en uw eigen waarden als de cyclusmarkering en niet-cyclusteken waarden. Dit kunnen bijvoorbeeld 1 en 0 of 'Ja' en 'Nee' zijn, of andere waarden naar keuze. In de clausule USING specificeert u een nieuwe matrixkolomnaam die het pad van de tot nu toe gevonden knooppunten zal bevatten.
Hier is hoe je een verzoek om ondergeschikten van een of andere input root-medewerker zou behandelen, met de mogelijkheid om cycli te detecteren op basis van de empid-kolom, waarbij 1 in de cyclusmarkeringskolom wordt aangegeven wanneer een cyclus wordt gedetecteerd, en anders 0:
Hier is de gewenste uitvoer van deze code:
T-SQL ondersteunt momenteel de CYCLE-clausule niet, maar er is een tijdelijke oplossing die een logisch equivalent biedt. Het omvat drie stappen. Bedenk dat u eerder een binair sorteerpad hebt gebouwd om de recursieve zoekvolgorde af te handelen. Op een vergelijkbare manier bouwt u als eerste stap in de oplossing een op tekenreeksen gebaseerd voorouderpad gemaakt van de knooppunt-ID's (werknemer-ID's in ons geval) van de voorouders die naar het huidige knooppunt leiden, inclusief het huidige knooppunt. U wilt scheidingstekens tussen de knooppunt-ID's, inclusief één aan het begin en één aan het einde.
Hier is de code om zo'n voorouderpad te bouwen:
Deze code genereert de volgende uitvoer, waarbij nog steeds cyclische paden worden gevolgd en daarom wordt afgebroken voordat deze is voltooid zodra de maximale recursielimiet is overschreden:
Eyeballing the output, you can identify a cyclic path when the current node appears in the path for the nonfirst time, such as in the path
In the second step of the solution you produce the cycle mark column. In the anchor query you simply set it to 0 since clearly a cycle cannot be found in the first node. In the recursive member you use a CASE expression that checks with a LIKE-based predicate whether the current node ID already appears in the parent’s path, in which case it returns the value 1, or not, in which case it returns the value 0.
Here’s the code implementing Step 2:
This code generates the following output, again, still pursuing cyclic paths and failing once the max recursion limit is reached:
The third and last step is to add a predicate to the ON clause of the recursive member that pursues a path only if a cycle was not detected in the parent’s path.
Here’s the code implementing Step 3, which is also the complete solution:
This code runs to completion, and generates the following output:
You identify the erroneous data easily here, and fix the problem by setting the manager ID of the CEO to NULL, like so:
Run the recursive query and you will find that there are no cycles present.
Recursive CTEs enable you to write concise declarative solutions for purposes such as traversing graph structures. A recursive CTE has at least one anchor member, which gets executed once, and at least one recursive member, which gets executed repeatedly until it returns an empty result set. Using a query option called MAXRECURSION you can control the maximum number of allowed executions of the recursive member as a safety measure. To limit the executions of the recursive member programmatically for filtering purposes you can maintain a column that tracks the level of the current node with respect to the root node.
The SQL standard supports two very powerful options for recursive CTEs that are currently not available in T-SQL. One is a clause called SEARCH that controls the recursive search order, and another is a clause called CYCLE that detects cycles in the traversed paths. I provided logically equivalent solutions that are currently available in T-SQL. If you find that the unavailable standard features could be important future additions to T-SQL, make sure to vote for them here:
This article concludes the coverage of the logical aspects of CTEs. Next month I’ll turn my attention to physical/performance considerations of CTEs.
AS [
ZOEKEN
DIEPTE EERST DOOR
CYCLE
STANDAARD
SEARCH-clausule
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SEARCH BREADTH FIRST BY empid SET seqbreadth
--------------------------------------------
SELECT empid, mgrid, empname, seqbreadth
FROM C
ORDER BY seqbreadth; empid mgrid empname seqbreadth
------ ------ -------- -----------
1 NULL David 1
2 1 Eitan 2
3 1 Ina 3
4 2 Seraph 4
5 2 Jiru 5
6 2 Steve 6
7 3 Aaron 7
8 5 Lilach 8
9 7 Rita 9
10 5 Sean 10
11 7 Gabriel 11
12 9 Emilia 12
13 9 Michael 13
14 9 Didi 14
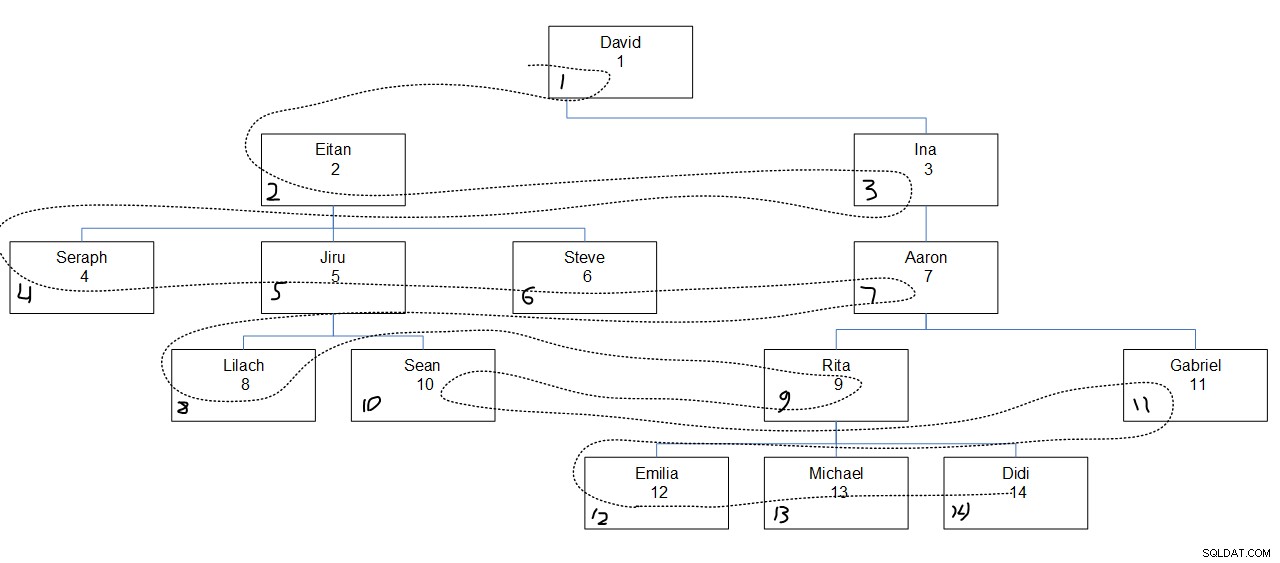 Figuur 2:Zoek eerst in de breedte
Figuur 2:Zoek eerst in de breedte DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname, 0 AS lvl
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname, M.lvl + 1 AS lvl
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname,
ROW_NUMBER() OVER(ORDER BY lvl, empid) AS seqbreadth
FROM C
ORDER BY seqbreadth; DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SEARCH DEPTH FIRST BY empid SET seqdepth
----------------------------------------
SELECT empid, mgrid, empname, seqdepth
FROM C
ORDER BY seqdepth; empid mgrid empname seqdepth
------ ------ -------- ---------
1 NULL David 1
2 1 Eitan 2
4 2 Seraph 3
5 2 Jiru 4
8 5 Lilach 5
10 5 Sean 6
6 2 Steve 7
3 1 Ina 8
7 3 Aaron 9
9 7 Rita 10
12 9 Emilia 11
13 9 Michael 12
14 9 Didi 13
11 7 Gabriel 14
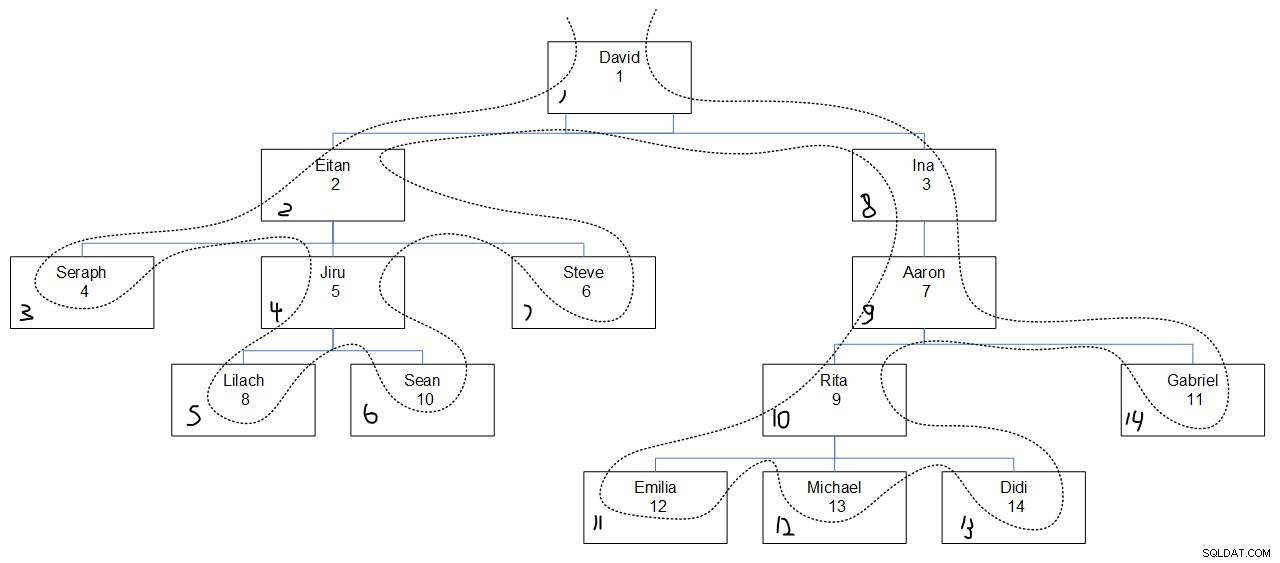 Figuur 3:Zoekdiepte eerst
Figuur 3:Zoekdiepte eerst DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST(0x AS VARBINARY(900)) AS sortpath
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.sortpath
+ CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid)
AS BINARY(1))
AS VARBINARY(900)) AS sortpath
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname, sortpath
FROM C; empid mgrid empname sortpath
------ ------ -------- -----------
1 NULL David 0x
2 1 Eitan 0x01
3 1 Ina 0x02
7 3 Aaron 0x0201
9 7 Rita 0x020101
11 7 Gabriel 0x020102
12 9 Emilia 0x02010101
13 9 Michael 0x02010102
14 9 Didi 0x02010103
4 2 Seraph 0x0101
5 2 Jiru 0x0102
6 2 Steve 0x0103
8 5 Lilach 0x010201
10 5 Sean 0x010202
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST(0x AS VARBINARY(900)) AS sortpath
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.sortpath
+ CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid)
AS BINARY(1))
AS VARBINARY(900)) AS sortpath
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname,
ROW_NUMBER() OVER(ORDER BY sortpath) AS seqdepth
FROM C
ORDER BY seqdepth; DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, empname, 0 AS lvl,
CAST(0x AS VARBINARY(900)) AS sortpath
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.empname, M.lvl + 1 AS lvl,
CAST(M.sortpath
+ CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid)
AS BINARY(1))
AS VARBINARY(900)) AS sortpath
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid,
ROW_NUMBER() OVER(ORDER BY sortpath) AS seqdepth,
REPLICATE(' | ', lvl) + empname AS emp
FROM C
ORDER BY seqdepth; empid seqdepth emp
------ --------- --------------------
1 1 David
2 2 | Eitan
4 3 | | Seraph
5 4 | | Jiru
8 5 | | | Lilach
10 6 | | | Sean
6 7 | | Steve
3 8 | Ina
7 9 | | Aaron
9 10 | | | Rita
12 11 | | | | Emilia
13 12 | | | | Michael
14 13 | | | | Didi
11 14 | | | Gabriel
CYCLE-clausule
UPDATE Employees
SET mgrid = 14
WHERE empid = 1;
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname
FROM C; empid mgrid empname
------ ------ --------
1 14 David
2 1 Eitan
3 1 Ina
7 3 Aaron
9 7 Rita
11 7 Gabriel
12 9 Emilia
13 9 Michael
14 9 Didi
1 14 David
2 1 Eitan
3 1 Ina
7 3 Aaron
...
Msg 530, Level 16, State 1, Line 432
De instructie is beëindigd. De maximale recursie 100 is uitgeput voordat de verklaring is voltooid.
SET
GEBRUIK DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
CYCLE empid SET cycle TO 1 DEFAULT 0
------------------------------------
SELECT empid, mgrid, empname
FROM C; empid mgrid empname cycle
------ ------ -------- ------
1 14 David 0
2 1 Eitan 0
3 1 Ina 0
7 3 Aaron 0
9 7 Rita 0
11 7 Gabriel 0
12 9 Emilia 0
13 9 Michael 0
14 9 Didi 0
1 14 David 1
4 2 Seraph 0
5 2 Jiru 0
6 2 Steve 0
8 5 Lilach 0
10 5 Sean 0
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname, ancpath
FROM C; empid mgrid empname ancpath
------ ------ -------- -------------------
1 14 David .1.
2 1 Eitan .1.2.
3 1 Ina .1.3.
7 3 Aaron .1.3.7.
9 7 Rita .1.3.7.9.
11 7 Gabriel .1.3.7.11.
12 9 Emilia .1.3.7.9.12.
13 9 Michael .1.3.7.9.13.
14 9 Didi .1.3.7.9.14.
1 14 David .1.3.7.9.14.1.
2 1 Eitan .1.3.7.9.14.1.2.
3 1 Ina .1.3.7.9.14.1.3.
7 3 Aaron .1.3.7.9.14.1.3.7.
...
Msg 530, Level 16, State 1, Line 492
De instructie is beëindigd. De maximale recursie 100 is uitgeput voordat de verklaring is voltooid. '.1.3.7.9.14.1.' . DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath,
0 AS cycle
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath,
CASE WHEN M.ancpath LIKE '%.' + CAST(S.empid AS VARCHAR(4)) + '.%' THEN 1
ELSE 0 END AS cycle
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname, ancpath, cycle
FROM C; empid mgrid empname ancpath cycle
------ ------ -------- ------------------- ------
1 14 David .1. 0
2 1 Eitan .1.2. 0
3 1 Ina .1.3. 0
7 3 Aaron .1.3.7. 0
9 7 Rita .1.3.7.9. 0
11 7 Gabriel .1.3.7.11. 0
12 9 Emilia .1.3.7.9.12. 0
13 9 Michael .1.3.7.9.13. 0
14 9 Didi .1.3.7.9.14. 0
1 14 David .1.3.7.9.14.1. 1
2 1 Eitan .1.3.7.9.14.1.2. 0
3 1 Ina .1.3.7.9.14.1.3. 1
7 3 Aaron .1.3.7.9.14.1.3.7. 1
...
Msg 530, Level 16, State 1, Line 532
The statement terminated. The maximum recursion 100 has been exhausted before statement completion. DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath,
0 AS cycle
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath,
CASE WHEN M.ancpath LIKE '%.' + CAST(S.empid AS VARCHAR(4)) + '.%' THEN 1
ELSE 0 END AS cycle
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
AND M.cycle = 0
)
SELECT empid, mgrid, empname, cycle
FROM C; empid mgrid empname cycle
------ ------ -------- -----------
1 14 David 0
2 1 Eitan 0
3 1 Ina 0
7 3 Aaron 0
9 7 Rita 0
11 7 Gabriel 0
12 9 Emilia 0
13 9 Michael 0
14 9 Didi 0
1 14 David 1
4 2 Seraph 0
5 2 Jiru 0
6 2 Steve 0
8 5 Lilach 0
10 5 Sean 0
UPDATE Employees
SET mgrid = NULL
WHERE empid = 1;
Conclusie