Over de hele wereld is de vacaturesite een bekend kenmerk van het internetlandschap. Grote spelers zoals Indeed en Monster hebben van het zoeken naar en werven van een baan een echte online industrie gemaakt. Laten we een duik nemen in de elementaire functies die worden gebruikt door vacatureportalen en een gegevensmodel bouwen dat deze kan ondersteunen.
Mensen houden ervan om tijd te besparen door gebruik te maken van technologische innovaties; het online banenportaal is een andere versie van slimmer werken, niet harder. Zowel werkzoekenden als bedrijven beseffen de waarde van online zoeken:ze krijgen een groter bereik tegen hogere snelheden en lagere kosten.
De jobportal-industrie is nu behoorlijk gestabiliseerd, althans wat betreft verkeersvolumes. Werkzoekenden gebruiken deze portals om posities te vinden in veel sectoren, waarbij ze verder gaan dan IT naar sectoren als engineering, verkoop, productie en financiële dienstverlening. Ze krijgen echter harde concurrentie van sociale media en professionele netwerksites zoals LinkedIn. Maar er zijn nog steeds mogelijkheden om te verkennen, zoals het uitbreiden van hun penetratie naar landelijke gebieden en kleinere steden.
Dus zoals we al zeiden, we gaan dit onderwerp onderzoeken vanuit het perspectief van databaseontwerp. Laten we beginnen met het opsommen van de fundamentele verwachtingen voor een banenportaal.
Wat verwachten mensen van een online banenportaal?
Zowel werkgevers als werkzoekenden verwachten de volgende functionaliteiten van een online vacaturesite:
- Mensen kunnen zich registreren als werkzoekende, hun profiel opbouwen en banen zoeken die bij hun vaardigheden passen.
- Gebruikers kunnen hun bestaande cv's uploaden. Als ze er geen hebben, moeten ze een formulier kunnen invullen en een cv voor ze kunnen laten maken.
- Mensen kunnen direct solliciteren op geplaatste vacatures.
- Bedrijven kunnen zich registreren, vacatures plaatsen en zoeken naar werkzoekendenprofielen.
- Meerdere vertegenwoordigers van een bedrijf moeten zich kunnen registreren en vacatures kunnen plaatsen.
- Bedrijfsvertegenwoordigers kunnen een lijst met sollicitanten bekijken en contact met hen opnemen, een sollicitatiegesprek initiëren of een andere actie uitvoeren die verband houdt met hun functie.
- Geregistreerde gebruikers moeten naar banen kunnen zoeken en de resultaten kunnen filteren op basis van locatie, vereiste vaardigheden, salaris, ervaringsniveau, enz.
Het gegevensmodel bouwen
Na het overwegen van de bovenstaande vereisten, kwam ik tot drie brede functionele categorieën:
- Gebruikers beheren – Hoe de portal gebruikers beheert, d.w.z. werkzoekenden, HR-personeel en onafhankelijke of adviserende recruiters. (Voor de toepassing van dit model worden individuele HR-vertegenwoordigers en onafhankelijke of adviserende recruiters behandeld als bedrijven, althans wat betreft het gebruik van de portal.)
- Profielen bouwen – Hoe het portaal werkzoekenden en organisaties in staat stelt profielen en cv's aan te maken.
- Vacatures plaatsen en opzoeken – Hoe de portal het proces van plaatsen, zoeken en solliciteren faciliteert.
Laten we elk van deze gebieden afzonderlijk bekijken.
1. Gebruikers beheren
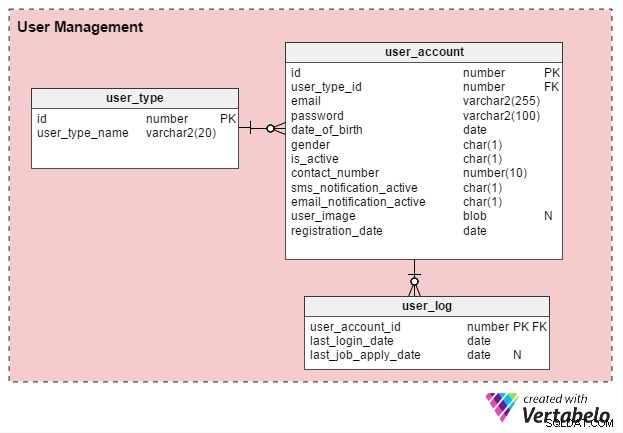
Er zijn hoofdzakelijk twee soorten gebruikers van online vacaturesites:individuele werkzoekenden en HR-recruiters (of onafhankelijke wervingsconsulenten). Laten we een tabel maken met de naam user_type om deze records op te slaan. Om te beginnen heeft het twee records:een voor werkzoekenden en een voor recruiters. (We kunnen altijd extra recordtypen maken als dat nodig is.)
Gebruikers moeten zich registreren voordat ze de portal kunnen gebruiken. Het user_account table slaat hun basisaccountgegevens op. Ik heb eerder overwogen om deze tabel "gebruiker" te noemen, maar aangezien gebruiker een door het systeem gedefinieerd sleutelwoord is in bijna alle databases, blijf ik liever bij "gebruikersaccount".
Het user_account tabel heeft de volgende kolommen:
- id – Dit is zowel de primaire sleutel van de tabel als een unieke identificatie voor elke gebruiker. Naar deze ID wordt verwezen door andere tabellen in het gegevensmodel.
- user_type_id – Dit geeft aan of de gebruiker een werkzoekende of een recruiter is.
- e-mail – Deze kolom bevat het e-mailadres van de gebruiker. Het fungeert als een andere gebruikers-ID voor de portal.
- wachtwoord – Dit slaat een gecodeerd accountwachtwoord op (aangemaakt door gebruikers tijdens de registratie).
- datum_van_geboorte en geslacht – Zoals hun namen doen vermoeden, bevatten deze kolommen de geboortedatum en het geslacht van de gebruikers.
- is_active – In eerste instantie zou deze kolom “Y” zijn, maar gebruikers kunnen hun profiel op inactief of op “N” zetten. In deze kolom wordt hun keuze opgeslagen.
- contactnummer – Dit is het telefoonnummer (meestal mobiel) dat tijdens de registratie is opgegeven. Gebruikers kunnen op dit nummer sms-meldingen ontvangen. Het kan hetzelfde nummer zijn (of niet) als de lijst met werkzoekenden in hun profiel of cv.
- sms_notification_active en email_notification_active – In deze kolommen worden de voorkeuren van gebruikers opgeslagen met betrekking tot het ontvangen van meldingen via sms en/of e-mail.
- user_image – Dit is een attribuut van het BLOB-type waarin de profielafbeelding van elke gebruiker wordt opgeslagen. Aangezien deze portal slechts één profielafbeelding per gebruiker toestaat, is het logisch om deze hier op te slaan.
- registratiedatum – Deze kolom houdt bij wanneer de gebruiker zich bij de portal heeft geregistreerd.
We maken nog een tabel, user_log , dat een record opslaat van de laatste inlogdatum van gebruikers en hun laatste sollicitatiedatum. Er zijn veel functies die op basis van deze kennis kunnen worden gebouwd. We kunnen deze informatie bijvoorbeeld gebruiken om de vraag te beantwoorden Is gebruiker X actief op zoek naar een baan ? Dan kan hen een product worden aangeboden voor het maken van een effectief cv. Gebruikers die niet actief op zoek zijn naar een baan, krijgen zo'n aanbod niet.
2. Profielen bouwen
We kunnen deze sectie verder onderverdelen in twee gebieden:bedrijfs- of organisatieprofielen en werkzoekendenprofielen.
Bedrijfsprofielen
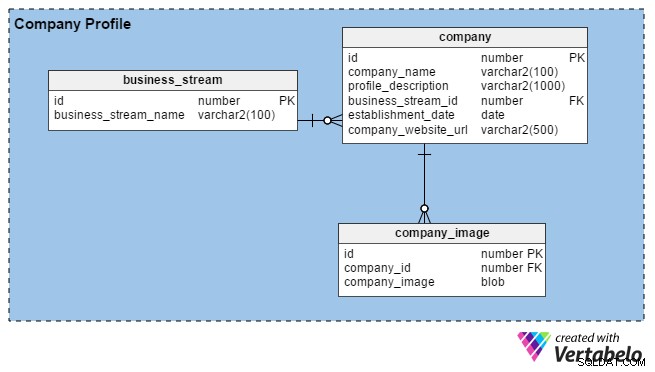
Gewoonlijk bouwen HR-teams bedrijfsprofielen op door details over hun organisatie en afbeeldingen van hun kantoren, gebouwen, enz. in te voeren. Hun belangrijkste doel is om goed talent aan te trekken. Wanneer recruiters zich registreren bij het portaal, kunnen ook zij profielen van hun bedrijven (of hun persoonlijke merk, als ze onafhankelijk zijn) opbouwen door enkele basisgegevens te verstrekken, zoals hoe lang ze al actief zijn, hun locatie en hun belangrijkste zakelijke stroom ( productie, IT-diensten, financiën, enz.).
Met de portal kunnen HR- en consulting-recruiters zoveel afbeeldingen uploaden als ze willen (in tegenstelling tot werkzoekenden, die er maar één kunnen uploaden). Daarom hebben we de company_image tabel om meerdere afbeeldingen voor elk recruiter-account op te slaan. De company_id kolom in deze tabel is een refererende sleutel die verwijst naar de unieke identificatie die wordt gebruikt in het company tafel.
In het company tabel hebben we de volgende kolommen:
- id – De primaire sleutel van deze tabel wordt ook gebruikt om bedrijven uniek te identificeren.
- bedrijfsnaam – Zoals de kolomnaam suggereert, bevat dit de officiële naam van een bedrijf.
- profile_description – Dit bevat een korte beschrijving van elk bedrijf.
- business_stream_id – Deze kolom geeft weer tot welke bedrijfsstroom een bedrijf behoort. Een olie- en gasexploratiebedrijf kan bijvoorbeeld IT-ingenieurs inhuren, maar hun belangrijkste bedrijfsstroom blijft "Olie en Gas".
- establishment_date – In deze kolom staat hoe oud een bedrijf is.
- company_website_url – Dit is een verplichte (niet-nullable) kolom. Het bevat een verwijzing naar de officiële website van het bedrijf, zodat werkzoekenden meer informatie kunnen vinden.
Eindelijk, de business_stream tabel heeft slechts twee attributen, een id die de primaire sleutel is voor deze tabel, en een beschrijving van de belangrijkste bedrijfsstroom van het bedrijf (business_stream_name ).
Profielen voor werkzoekenden
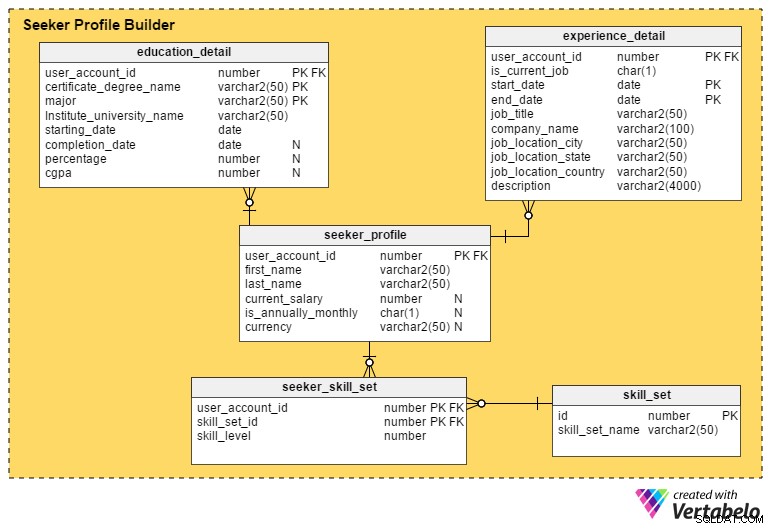
Dit is het meest kritieke gedeelte van een banenportaal. Tenzij een portal zoveel mogelijk details van werkzoekenden vastlegt, is het moeilijk voor recruiters om de profielen of kandidaten op de shortlist te plaatsen.
Het seeker_profile tabel bevat aanvullende details die niet zijn vastgelegd tijdens het registratieproces. Het bevat deze velden:
- user_account_id – Deze kolom is afkomstig van het
user_accounttable, en het fungeert als de primaire sleutel voor deze tabel. Het zorgt ervoor dat er maximaal één profiel per werkzoekende is. - voornaam en achternaam – Zoals de namen doen vermoeden, bevatten deze kolommen de voor- en achternaam van de werkzoekende.
- current_salary – Dit kenmerk bevat het huidige salaris van de werkzoekende. Het is nullable omdat mensen het misschien niet willen onthullen.
- is_jaarlijks_maandelijks – Dit bepaalt of hun salaris per jaar of per maand is.
- valuta – Hiermee wordt de valuta van het salaris opgeslagen.
De education_detail tabel slaat de educatieve geschiedenis van elke werkzoekende op, zoals door hen verstrekt. Het heeft een samengestelde primaire sleutel die bestaat uit de user_account_id , certificaat_graad_naam en groot kolommen. Dit zorgt ervoor dat gebruikers slechts één . invoeren record voor elke graad of getuigschrift. De tabel bevat deze attributen:
- user_account_id – Deze kolom is afkomstig van het
user_accounttabel en dient als de primaire sleutel voor deze tabel. - certificate_degree_name – Dit is het type getuigschrift of diploma; bijv. middelbare school, hoger secundair, afgestudeerd, postdoctoraal of professioneel certificaat.
- groot – Deze kolom bevat de hoofdopleiding van het getuigschrift of diploma – bijv. een bachelor's degree met een major in computerwetenschappen.
- instituut_university_name – Dit is het instituut, de school of de universiteit die het diploma of getuigschrift heeft uitgereikt.
- startdatum – Dit kenmerk slaat de datum op waarop de gebruiker werd toegelaten tot een educatief programma.
- completion_date – Dit is de datum waarop de graad of het getuigschrift is uitgereikt. Dit attribuut is echter nullable; mensen zijn misschien nog bezig met het afronden van hun programma terwijl ze op zoek zijn naar een baan, of ze zijn misschien helemaal gestopt met het programma.
- percentage en cgpa – In deze kolommen wordt het cijferpercentage of CGPA (cumulatief cijferpuntgemiddelde) opgeslagen dat gebruikers hebben behaald in hun diploma- of certificaatcursus.
De experience_detail table houdt gegevens bij van de vroegere en huidige professionele ervaring van gebruikers. Het bevat de volgende belangrijke kolommen:
- user_account_id – Deze kolom is afkomstig van het
user_accounttabel en is de primaire sleutel voor deze tabel. - is_current_job – Dit is een indicatorkolom die de huidige baan van de gebruiker aangeeft. Deze kolom speelt ook een belangrijke rol bij het afleiden van de huidige locaties van gebruikers en hoe lang ze hun huidige positie hebben behouden.
- startdatum – Dit slaat op wanneer een gebruiker een taak start.
- einddatum – Dit slaat op wanneer een gebruiker een taak beëindigt.
- job_title – Dit bevat informatie over de functie van de gebruiker.
- bedrijfsnaam – Dit kenmerk bevat de relevante bedrijfsnaam die aan een baan is gekoppeld.
- job_location_city – Dit geeft de stad aan waar de baan zich bevond.
- job_location_state – Dit geeft de staat aan waar de taak zich bevond.
- job_location_country – Dit geeft het land aan waar de baan zich bevond.
- beschrijving – Deze kolom bevat details over functies en verantwoordelijkheden, uitdagingen en prestaties.
Werkzoekenden kunnen meerdere vaardigheden bezitten. Om al deze vaardigheden bij te houden, maken we de tabel seeker_skill_set . De kolommen zijn:
- user_account_id – Deze kolom is afkomstig van het
user_accounttabel en is de primaire sleutel voor deze tabel. - skill_set_id – Deze ID geeft aan over welke vaardigheden de gebruiker beschikt.
- vaardigheidsniveau – Dit numerieke attribuut kwantificeert de expertise van werkzoekenden in een bepaalde vaardigheid. Een getal van 1 (beginner) tot 10 (expert) geeft hun ervaringsniveau aan.
Ten slotte, de skill_set tabel bevat beschrijvingen van alle vaardigheden waarnaar wordt verwezen in de skill_set_id van de bovenstaande tabel attribuut. Het bevat slechts twee kolommen, een skill_set_name en de bijbehorende id .
3. Vacatures plaatsen en opzoeken
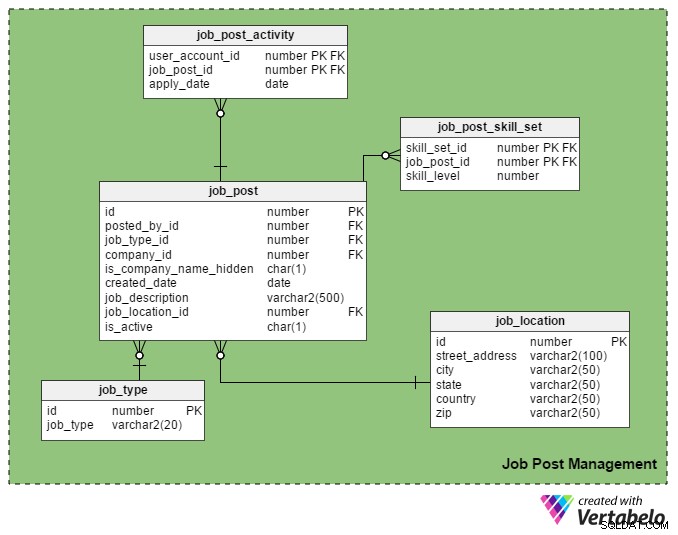
Dit is de belangrijkste USP (Unique Selling Point) van een vacaturesite. Alleen geregistreerde recruiters mogen een vacature op de portal plaatsen en alleen geregistreerde werkzoekenden mogen op hen solliciteren.
De job_post table is de hoofdtabel in dit vakgebied. Zoals je zou kunnen raden, bevat het details over vacatures. Alle andere tabellen in deze sectie zijn eromheen gemaakt en ermee verbonden.
- id – Dit is de primaire sleutel van deze tabel. Elke vacature krijgt een uniek nummer toegewezen, en naar dit nummer wordt verwezen in andere tabellen.
- posted_by_id – Deze kolom bevat de register_user_id van de recruiter die de vacature heeft geplaatst.
- job_type_id – Deze kolom geeft aan of de baanduur vast of tijdelijk (contract) is.
- company_id – In deze kolom wordt de ID opgeslagen van het bedrijf dat is gerelateerd aan de vacature. Het is een verwijzing naar het
companytafel. - is_company_name_hidden – Dit is een vlaggenkolom die aangeeft of de naam van het bedrijf moet worden getoond aan werkzoekenden. Recruiters geven er de voorkeur aan om geen bedrijfsnamen op hun post te tonen. In plaats daarvan gebruiken ze termen als 'Global Automobile Company', 'California-Based IT Company', enzovoort.
- created_date – Dit slaat de datum op waarop de vacature is geplaatst.
- job_description – Hierin staat een korte beschrijving van de baan.
- job_location_id – Dit verwijst naar een attribuut in de
job_locationtabel die de werkelijke locatie van de taak opslaat:adres, stad, staat, land en postcode. - is_active – Dit geeft aan of er nog een vacature openstaat. Recruiters kunnen hun berichten als inactief markeren zodra de vacatures zijn ingevuld.
De job_post_skill_set tabel bevat details over de vaardigheden die nodig zijn voor een baan. De tabelstructuur is identiek aan de seeker_skill_set tafel.
En de laatste tabel in deze sectie, de job_post_activity tabel, bevat details over welke werkzoekenden wanneer solliciteren naar een baan.
Wat zou u toevoegen aan dit online jobportaal-gegevensmodel?
De online vacaturesites van vandaag bieden meer dan een platform om vacatures te plaatsen en te solliciteren. Ze bevatten vaak andere professionele diensten zoals:
- Een persoonlijk dashboard om sollicitaties bij te houden
- Realtime updates over applicaties
- Video-cv-bouwers
- Deskundige diensten voor het schrijven van cv's
- LinkedIn of andere profielbouwers voor sociale media
- Salarisrapporten voor functies, bedrijven, bedrijfstakken of geografische locaties
Als we deze functies in ons systeem wilden inbouwen, welke aanvullende wijzigingen zouden we dan moeten aanbrengen? Kun je nog andere must-haves in een banenportaal bedenken?
Laat ons uw mening weten in het opmerkingengedeelte.