In dit tijdperk van zware concurrentie zijn vacatureportalen niet alleen platforms voor het publiceren en vinden van banen. Ze maken gebruik van geavanceerde services en functies om hun klanten betrokken te houden. Laten we een duik nemen in enkele geavanceerde functies en een gegevensmodel bouwen dat ze aankan.
In een vorig artikel heb ik de basisfuncties uitgelegd die nodig zijn voor een jobportal-website. Het model is hieronder weergegeven. We zullen dit model als basis beschouwen, die we zullen aanpassen aan de nieuwe eisen. Laten we eerst eens kijken wat deze vereisten (of verbeteringen) zouden moeten zijn.
Wat voegen we toe aan het online jobportaal-gegevensmodel?
In het kort, we gaan vier verbeteringen toevoegen aan ons voormalige datamodel:
- Een persoonlijk dashboard voor werkzoekenden. Dit houdt al hun sollicitaties bij en biedt realtime updates over eventuele statuswijzigingen (d.w.z. een sollicitatie verandert van ontvangen naar beoordeeld).
- Een profieldashboard. Dit geeft aan wie het profiel van een werkzoekende bezoekt en hoe vaak hun cv de afgelopen dag, week of maand is gedownload.
- Betaald servicebeheer. Jobportalen bieden vaak diensten aan zoals het opstellen van cv's door experts, beheer van sociale profielen, loopbaanadvies, enz. Onze nieuwe functionaliteiten zullen het aanbod tegen betaling kunnen ondersteunen.
- Pre-aanvraagformulier beheer. Als sollicitanten een sollicitatie indienen, kan hen worden gevraagd een korte vragenlijst in te vullen met betrekking tot werktijden, locaties en achtergrondcontroles. We zullen ervoor zorgen dat dit formulier door recruiters kan worden aangepast en dat vragen en antwoorden door het systeem worden vastgelegd.
Verbetering# 1:Persoonlijk dashboard
Vragen om te beantwoorden: Wat is de huidige status van een ingediende aanvraag? Staat het op de shortlist voor een interview? Is het zelfs al bekeken?
We kunnen sollicitaties bijhouden door de job_application_status_id kolom in de job_post_activity tafel. In deze kolom staat de actuele status van een sollicitatie. We moeten een andere tabel maken, job_application_status , om alle mogelijke aanvraagstatussen vast te houden. Sommige statussen kunnen 'ingediend', 'onder beoordeling', 'gearchiveerd', 'afgewezen', 'op de shortlist voor interview', 'onder wervingsproces', enzovoort zijn.
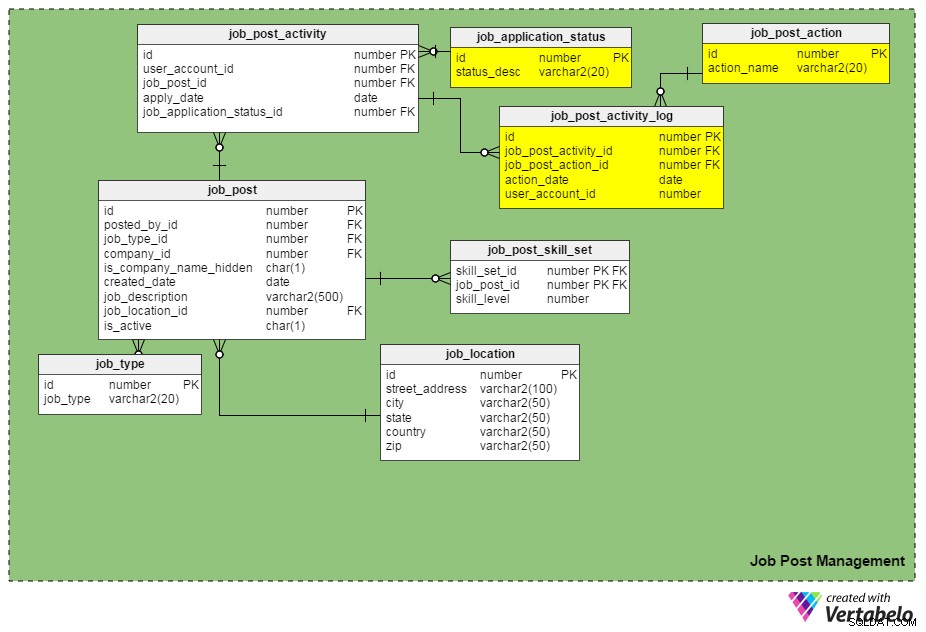
Nog een nieuwe tabel, job_post_activity_log , slaat informatie op over alle acties die zijn uitgevoerd op sollicitaties, wie de actie heeft uitgevoerd en wanneer deze is uitgevoerd. Deze tabel bevat de volgende kolommen:
id– De primaire sleutel van de tabel.job_post_activity_id– De applicatie-ID waarop de actie wordt uitgevoerd.job_post_action_id– De ID van de uitgevoerde actie. Dit is een externe sleutel die linkt naar dejob_post_actiontafel. De soorten acties die we hier kunnen opslaan, zijn onder meer 'ingediend', 'bekeken', 'geïnterviewd', 'geschreven test gedaan', 'aanbieding in behandeling', 'aanbieding verzonden', 'aanbieding geaccepteerd', enz.action_date– De datum waarop een actie is uitgevoerd.user_account_id– De ID van de persoon die de actie heeft uitgevoerd.
Is "job_post_action" identiek aan "job_application_status"? Hoe verschillen ze?
Ze lijken op het eerste gezicht identiek, maar ze zijn inderdaad verschillend. Er zijn geldige redenen waarom we twee vergelijkbare velden nodig hebben:
- Een kandidaat wordt door twee of meer personen afzonderlijk geïnterviewd. In dit geval blijft de sollicitatiestatus hetzelfde (d.w.z. 'ondergaan wervingsproces') totdat alle sollicitatierondes zijn voltooid. De records voor elke individuele interviewer worden echter ingevoegd in de
job_post_activity_logtafel, en ze hebben de actie 'geïnterviewd'. - Een sollicitatie kan door meer dan één recruiter in hetzelfde bedrijf worden bekeken. Door deze twee kenmerken te gebruiken, raakt u de informatie van een sollicitant niet kwijt.
- Het doen van een aanbod aan een geselecteerde kandidaat is onderworpen aan meerdere goedkeuringen (d.w.z. goedkeuring van het financiële team, goedkeuring van de manager van de aanwervingsafdeling, enzovoort). In dit geval blijft de status van een sollicitatie 'offer in beoordeling', maar kan de database via de
job_post_activity_logtafel.
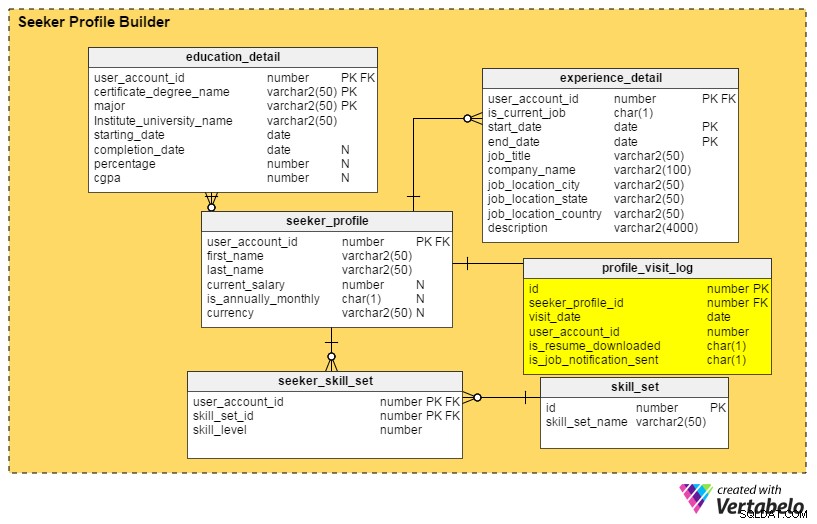
Verbetering #2:een profieldashboard
Vragen om te beantwoorden: Wie heeft mijn profiel onlangs gevonden? Hoe vaak is het de afgelopen maand, week of dag door recruiters bekeken? Hebben recruiters van topbedrijven naar mijn profiel gekeken?
De antwoorden op al deze vragen staan in de profile_visit_log tafel. Deze tabel legt alle profielbezoekgegevens vast, inclusief wie een profiel heeft bezocht, wanneer het is bekeken, enzovoort. De kolommen in deze tabel zijn:
id– De primaire sleutel van de tabel.seeker_profile_id– Welk profiel is bezocht.visit_date– Wanneer het profiel werd geopend.user_account_id– Wie heeft het profiel gezien.is_resume_downloaded– Een vlagkolom die aangeeft of het gerelateerde cv tijdens het bezoek is gedownload. Deze kolom helpt ons af te leiden hoe vaak een cv wordt gedownload door recruiters.is_job_notification_sent– Nog een vlagkolom, deze geeft aan of er een taakmelding is verzonden naar de eigenaar van het profiel.
Verbetering# 3:Betaald servicebeheer
Vraag om te beantwoorden: Hoe kunnen online portals gebruikmaken van aanvullende betaalde services?
Naast een platform voor het plaatsen en zoeken van vacatures, bieden veel online portals andere diensten, zoals het samenstellen van cv's voor experts, loopbaanadvies, enz. Ze bieden ook producten aan om werkzoekenden te helpen hun droombaan in hun droomstad te vinden. Een van de toonaangevende vacaturesites biedt bijvoorbeeld een product dat uw profiel bovenaan de lijsten van recruiters houdt, zodat u meer sollicitatiegesprekken kunt krijgen. De meeste van deze producten of diensten zijn beschikbaar op abonnementsbasis. Wanneer een gebruiker een dienst of product koopt, betalen ze over een bepaalde periode (d.w.z. een maand, drie maanden, een jaar) voor het gebruik van dat product of die dienst.
Toen ik naar deze vacatureportalen keek, viel het me op dat er nauwelijks producten of diensten afzonderlijk worden aangeboden. Voor het grootste deel zijn meerdere producten en diensten gebundeld in een pakket, en dit pakket wordt aangeboden aan werkzoekenden of recruiters.
Rekening houdend met al deze punten, kwam ik tot het volgende datamodel voor het opnemen van betaalde diensten en producten in onze bestaande online vacaturesite:
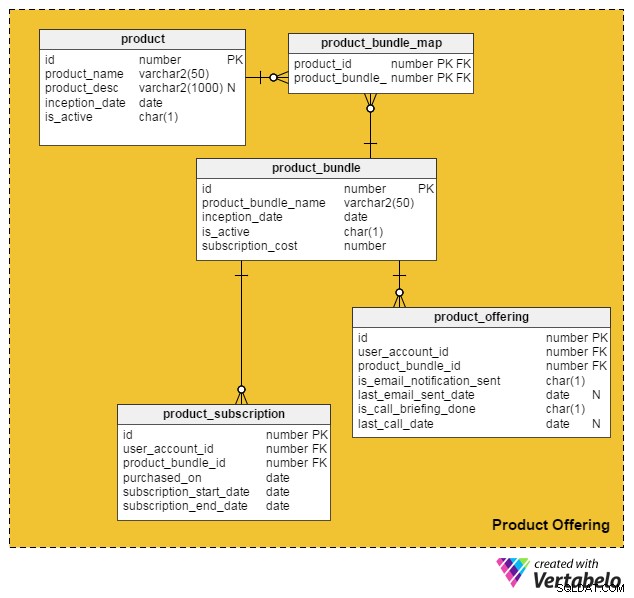
Het product tabel bevat details over individuele producten. (We zullen naar zowel producten als diensten verwijzen als 'producten'). De kolommen in deze tabel zijn:
id– De primaire sleutel van deze tabel, die een unieke ID geeft aan elk product dat op onze portal wordt aangeboden.product_name– Bevat de naam van het product.product_desc– Slaat een korte beschrijving van het product op.inception_date– De datum waarop een product werd geïntroduceerd.is_active– Of een product actief is of niet.
Omdat producten en diensten in een bundel kunnen worden samengevoegd en aan klanten kunnen worden aangeboden, heb ik de product_bundle tabel om records van al dergelijke bundels op te slaan. De attributen zijn:
id– De primaire sleutel van de tabel, die een unieke ID biedt voor elke productbundel.product_bundle_name– Slaat de naam van de bundel op.inception_date– De datum waarop de bundel werd geïntroduceerd.is_active– Geeft aan of een bundel actief is of niet.subscription_cost– Slaat de prijs op die voor de bundel wordt gevraagd.
Kan een enkel product aan klanten worden aangeboden?
Ja. In dit datamodel kan een enkel product zijn eigen “bundel” zijn. De volgende tabellen behandelen deze en enkele andere belangrijke functionaliteiten.
De product_bundle_map table slaat een lijst op van alle producten die deel uitmaken van een bundel. De kenmerken spreken voor zich.
De volgende tabel, product_subscription , komt in het spel wanneer klanten zich abonneren op productbundels. Het registreert de details van welke klanten op welke bundels hebben ingeschreven. De kolommen in deze tabel zijn:
id– De primaire sleutel van de tabel.user_account_id– De gebruiker die de bundel heeft gekocht.product_bundle_id– De productbundel die door de gebruiker is gekocht.purchased_on– De aankoopdatum.subscription_start_date– De datum waarop het abonnement ingaat. Houd er rekening mee dat de aankoopdatum van het product en de startdatum van het abonnement kunnen verschillen. We hebben hier dus twee verschillende kolommen voor.subscription_end_date– Wanneer het abonnement afloopt.
De finaletafel, product_offering , wordt voornamelijk gebruikt voor marketing. Gewoonlijk analyseren banenportalen de recente activiteiten van gebruikers (zowel werkzoekenden als recruiters) en beslissen vervolgens welke producten gunstig zijn voor welke gebruikers. Vervolgens gebruiken ze e-mails of telefoontjes om contact op te nemen met klanten met geselecteerde aanbiedingen. De kolommen voor deze tabel zijn:
id– De primaire sleutel van de tabel.user_account_id– De gebruiker op wie de vacatureportal is gericht.product_bundle_id– De productbundel die de portalmarketeers aan de gebruiker hebben gekoppeld.is_email_notification_sent– Of er een e-mail met betrekking tot het productaanbod is verzonden.last_email_sent_date– Wanneer de gebruiker voor het laatst een product-e-mail heeft ontvangen van het marketingteam. Het is gebruikelijk dat marketeers meerdere meldingen naar een gebruiker sturen en periodiek andere meldingen sturen. In deze kolom wordt de datum opgeslagen waarop de laatste melding is verzonden.is_call_briefing_done– Of de klant een telefoontje heeft ontvangen met informatie over een product.last_call_date–De datum van het meest recente telefoongesprek. Er kunnen meerdere oproepen (vervolggesprekken) naar klanten worden gedaan.
Verbetering nr. 4:Beheer van pre-aanvraagformulier
Vraag om te beantwoorden: Hoe kan een recruiter een aangepast toestemmingsformulier krijgen dat wordt ingevuld door alle potentiële sollicitanten?
Vaak beantwoorden werkzoekenden specifieke vragen als ze solliciteren naar een functie. Dit omvat vaak zaken als toestemming geven voor een criminele antecedentenonderzoek. Er zijn echter verschillende andere soorten toestemmingen die nodig kunnen zijn. Voor een baan in marketing moet je bijvoorbeeld veel reizen; banen in business process outsourcing (BPO) kunnen werknemers vereisen om kerkhofdiensten (d.w.z. nachtdiensten) te werken. Deze worden behandeld in pre-aanvraagformulieren.
Het is altijd het beste om toestemming te krijgen bij het indienen van de sollicitatie. Op deze manier zullen kandidaten die niet aan deze vereisten willen voldoen, niet op de baan solliciteren.
Voordat ik naar het datamodel spring, wil ik eerst enkele basisfeiten over toestemmingsformulieren benadrukken:
- Een vacature kan meer dan één toestemmingsformulier hebben.
- Elk toestemmingsformulier heeft verschillende vragen die verband houden met verschillende secties.
- Een vraag kan als verplicht of optioneel worden ingesteld, afhankelijk van hoe de vraag in het formulier is getagd. Een vraag kan in de ene vorm optioneel zijn en in een andere verplicht.
- Elke vraag kan worden beantwoord met (1) ja, (2) nee of (3) niet van toepassing.
- Alle antwoorden worden opgenomen.
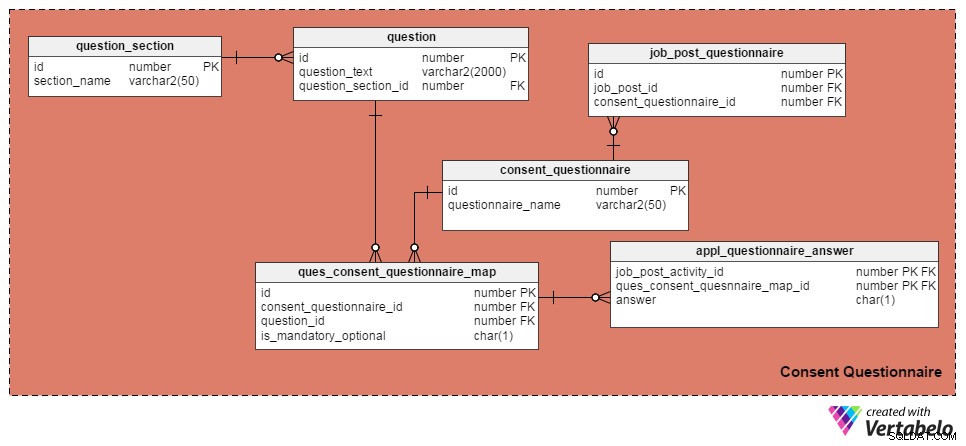
Ik heb de volgende vier tabellen gebruikt om vragen en toestemmingsformulieren te beheren. De eerste, de question tafel, bevat een lijst met vragen. Het heeft deze kenmerken:
id– De primaire sleutel van de tabel, die een uniek ID-nummer geeft aan elke vraag.question_text– Slaat de eigenlijke vraagtekst op.question_section_id– Het gedeelte waar de vraag verschijnt. (Bijvoorbeeld:"Heeft u ten minste vijf jaar in softwareontwikkeling gewerkt?" verschijnt in het gedeelte "Werkervaring".) Dit is een kolom met refererende sleutels waarnaar wordt verwezen vanuit dequestion_sectiontafel.
De question_section tabel slaat sectie-informatie op. Het is een manier om vragen over hetzelfde onderwerp te groeperen. Afgezien van de id attribuut, dat de primaire sleutel voor de tabel is, het enige attribuut is section_name , wat voor zich spreekt.
De consent_questionnaire tabel bevat namen van toestemmingsformulieren. De twee kenmerken spreken ook voor zich.
De ques_consent_questionnaire_map tafel vormt de kern van dit vakgebied. Alle andere tabellen in dit vakgebied zijn er direct of indirect mee verbonden. Het doel is om een lijst met vragen bij te houden die zijn getagd op toestemmingsformulieren. De kolommen in deze tabel zijn:
id– De primaire sleutel van deze tabel.consent_questionnaire_id– Het ID-nummer van het toestemmingsformulier.question_id– Het ID-nummer van de vraag.is_mandatory_optional– Geeft aan of de vraag verplicht of optioneel is voor een bepaald toestemmingsformulier. Een vraag kan deel uitmaken van meerdere toestemmingsformulieren, maar kan in sommige verplicht zijn en in andere optioneel. Dat is de enige reden om deze kolom hier te houden in plaats van in dequestiontafel.
In de volgende tabellen bespreken we toestemmingsformulieren voor individuele vacatures en leggen we de antwoorden van kandidaten vast. Laten we beginnen met de job_post_questionnaire tabel, waarin informatie wordt opgeslagen over welke toestemmingsformulieren deel uitmaken van een vacature. Er kunnen een of meer toestemmingsformulieren zijn getagd met een vacature. De kolommen in deze tabel zijn:
id– De primaire sleutel van de tabel.job_post_id– Geeft aan met welke vacature het toestemmingsformulier is getagd.consent_questionnaire_id– Het toestemmingsformulier getagd aan een vacature.
Vervolgens de appl_questionnaire_answer tabel registreert de individuele antwoorden van elke toestemmingsformuliervraag zoals ingevuld door de aanvragers. De kolommen in deze tabel zijn:
job_post_activity_id– Een kolom met een externe sleutel waarnaar wordt verwezen vanuit dejob_post_activitytafel. Het slaat informatie op over de kandidaat die de vraag heeft beantwoord.quest_consent_quesnnaire_map_id– Een andere kolom voor buitenlandse sleutels waarnaar wordt verwezen vanuit dequest_consent_questionnaire_maptafel. Het slaat op welke vraag van welk toestemmingsformulier wordt beantwoord.answer– Het daadwerkelijke antwoord van de sollicitant. Ik heb het als een CHAR(1)-kolom gehouden omdat alle vragen in ons model kunnen worden beantwoord met 'Ja' (antwoord ='Y'), 'Nee' (antwoord ='N') of 'Niet van toepassing' (antwoord ='X').
Het nieuwe en verbeterde online jobportaal datamodel
Hieronder ziet u het ingevulde datamodel.
Wat zou je toevoegen?
Kun je nog andere functies bedenken om toe te voegen aan ons online banenportaal? Deel uw mening in het opmerkingengedeelte.