Dit artikel is het vijfde deel in een serie over T-SQL-bugs, valkuilen en best practices. Voorheen behandelde ik determinisme, subquery's, joins en windowing. Deze maand behandel ik draaien en ongedaan maken. Bedankt Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man en Paul White voor het delen van uw suggesties!
In mijn voorbeelden gebruik ik een voorbeelddatabase met de naam TSQLV5. U vindt het script dat deze database maakt en vult hier, en het ER-diagram hier.
Impliciete groepering met PIVOT
Wanneer mensen gegevens willen draaien met T-SQL, gebruiken ze ofwel een standaardoplossing met een gegroepeerde query en CASE-expressies, of de gepatenteerde PIVOT-tabeloperator. Het belangrijkste voordeel van de PIVOT-operator is dat het meestal resulteert in kortere code. Deze operator heeft echter enkele tekortkomingen, waaronder een inherente ontwerpval die kan leiden tot bugs in uw code. Hier beschrijf ik de valstrik, de mogelijke bug en een best practice die de bug voorkomt. Ik zal ook een suggestie beschrijven om de syntaxis van de PIVOT-operator te verbeteren op een manier die de bug helpt voorkomen.
Wanneer u gegevens draait, zijn er drie stappen die betrokken zijn bij de oplossing, met drie bijbehorende elementen:
- Groeperen op basis van een element voor groeperen/op rijen
- Spread op basis van een spread/op cols-element
- Aggregeren op basis van een aggregatie/data-element
Hieronder volgt de syntaxis van de PIVOT-operator:
SELECT <select_list>
FROM <source_table>
PIVOT( <aggregate_function>(<aggregate_col>)
FOR <spread_col> IN(<target_cols>) ) AS <alias>; Het ontwerp van de PIVOT-operator vereist dat u expliciet de aggregatie- en spreidingselementen specificeert, maar laat SQL Server impliciet het groeperingselement achterhalen door eliminatie. Welke kolommen ook verschijnen in de brontabel die wordt geleverd als invoer voor de PIVOT-operator, ze worden impliciet het groeperingselement.
Stel dat u bijvoorbeeld de tabel Sales.Orders in de TSQLV5-voorbeelddatabase wilt opvragen. U wilt verzender-ID's op rijen retourneren, jaren van verzending op kolommen en het totaal aantal bestellingen per verzender en jaar.
Veel mensen vinden het moeilijk om de syntaxis van de PIVOT-operator te achterhalen, en dit resulteert vaak in het groeperen van de gegevens op ongewenste elementen. Als voorbeeld bij onze taak, stel dat je je niet realiseert dat het groeperingselement impliciet wordt bepaald, en je komt met de volgende vraag:
SELECT shipperid, [2017], [2018], [2019] FROM Sales.Orders CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear) PIVOT( COUNT(shippeddate) FOR shippedyear IN([2017], [2018], [2019]) ) AS P;
Er zijn slechts drie verzenders aanwezig in de gegevens, met verzender-ID's 1, 2 en 3. U verwacht dus slechts drie rijen in het resultaat te zien. De daadwerkelijke query-uitvoer toont echter veel meer rijen:
shipperid 2017 2018 2019 ----------- ----------- ----------- ----------- 3 1 0 0 1 1 0 0 2 1 0 0 1 1 0 0 2 1 0 0 2 1 0 0 2 1 0 0 3 1 0 0 2 1 0 0 3 1 0 0 ... 3 0 1 0 3 0 1 0 3 0 1 0 1 0 1 0 3 0 1 0 1 0 1 0 3 0 1 0 3 0 1 0 3 0 1 0 1 0 1 0 ... 3 0 0 1 1 0 0 1 2 0 0 1 1 0 0 1 2 0 0 1 1 0 0 1 3 0 0 1 3 0 0 1 2 0 1 0 ... (830 rows affected)
Wat is er gebeurd?
U kunt een aanwijzing vinden die u zal helpen de bug in de code te achterhalen door te kijken naar het queryplan dat wordt weergegeven in afbeelding 1.
 Figuur 1:Plannen voor pivot-query met impliciete groepering
Figuur 1:Plannen voor pivot-query met impliciete groepering
Laat u niet verwarren door het gebruik van de CROSS APPLY-operator met de VALUES-component in de query. Dit wordt eenvoudig gedaan om de resultaatkolom verzonden jaar te berekenen op basis van de bron verzonden datumkolom, en wordt afgehandeld door de eerste Compute Scalar-operator in het plan.
De invoertabel voor de PIVOT-operator bevat alle kolommen uit de tabel Sales.Orders, plus de resultaatkolom verzondenjaar. Zoals vermeld, bepaalt SQL Server het groeperingselement impliciet door eliminatie op basis van wat u niet hebt gespecificeerd als de aggregatie- (verzenddatum) en spreidings- (verzendjaar) elementen. Misschien verwachtte u intuïtief dat de kolom Shipperid de groeperingskolom zou zijn omdat deze in de SELECT-lijst voorkomt, maar zoals u in het plan kunt zien, kreeg u in de praktijk een veel langere lijst met kolommen, inclusief orderid, de primaire sleutelkolom in de brontabel. Dit betekent dat u in plaats van een rij per verzender een rij per bestelling krijgt. Aangezien je in de SELECT-lijst alleen de kolommen shipperid, [2017], [2018] en [2019] hebt opgegeven, zie je de rest niet, wat de verwarring vergroot. Maar de rest nam wel deel aan de impliciete groepering.
Wat geweldig zou kunnen zijn, is als de syntaxis van de PIVOT-operator een clausule zou ondersteunen waarin je expliciet het grouping/on rows-element kunt aangeven. Zoiets als dit:
SELECT <select_list>
FROM <source_table>
PIVOT( <aggregate_function>(<aggregate_col>)
FOR <spread_col> IN(<target_cols>)
ON ROWS <grouping_cols> ) AS <alias>; Op basis van deze syntaxis zou u de volgende code gebruiken om onze taak uit te voeren:
SELECT shipperid, [2017], [2018], [2019]
FROM Sales.Orders
CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear)
PIVOT( COUNT(shippeddate)
FOR shippedyear IN([2017], [2018], [2019])
ON ROWS shipperid ) AS P; U kunt hier een feedbackitem vinden met een suggestie om de syntaxis van de PIVOT-operator te verbeteren. Om van deze verbetering een permanente verandering te maken, kan deze clausule optioneel worden gemaakt, met als standaard het bestaande gedrag. Er zijn andere suggesties om de syntaxis van de PIVOT-operator te verbeteren door deze dynamischer te maken en door meerdere aggregaten te ondersteunen.
Ondertussen is er een best practice die u kan helpen de bug te voorkomen. Gebruik een tabeluitdrukking zoals een CTE of een afgeleide tabel waarin u alleen de drie elementen projecteert die u bij de draaibewerking nodig hebt, en gebruik vervolgens de tabeluitdrukking als invoer voor de PIVOT-operator. Zo heb je de volledige controle over het groeperingselement. Hier is de algemene syntaxis volgens deze best practice:
WITH <CTE_name> AS
(
SELECT <group_cols>, <spread_col>, <aggregate_col>
FROM <source_table>
)
SELECT <select_list>
FROM <CTE_name>
PIVOT( <aggregate_function>(<aggregate_col>)
FOR <spread_col> IN(<target_cols>) ) AS <alias>; Toegepast op onze taak, gebruik je de volgende code:
WITH C AS
(
SELECT shipperid, YEAR(shippeddate) AS shippedyear, shippeddate
FROM Sales.Orders
)
SELECT shipperid, [2017], [2018], [2019]
FROM C
PIVOT( COUNT(shippeddate)
FOR shippedyear IN([2017], [2018], [2019]) ) AS P; Deze keer krijg je slechts drie resultaatrijen zoals verwacht:
shipperid 2017 2018 2019 ----------- ----------- ----------- ----------- 3 51 125 73 1 36 130 79 2 56 143 116
Een andere optie is om de oude en klassieke standaardoplossing te gebruiken voor het draaien met behulp van een gegroepeerde query en CASE-expressies, zoals:
SELECT shipperid, COUNT(CASE WHEN shippedyear = 2017 THEN 1 END) AS [2017], COUNT(CASE WHEN shippedyear = 2018 THEN 1 END) AS [2018], COUNT(CASE WHEN shippedyear = 2019 THEN 1 END) AS [2019] FROM Sales.Orders CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear) WHERE shippeddate IS NOT NULL GROUP BY shipperid;
Met deze syntaxis moeten alle drie de draaiende stappen en de bijbehorende elementen expliciet in de code staan. Als u echter een groot aantal spreidingswaarden hebt, is deze syntaxis vaak uitgebreid. In dergelijke gevallen geven mensen er vaak de voorkeur aan om de PIVOT-operator te gebruiken.
Impliciete verwijdering van NULL's met UNPIVOT
Het volgende item in dit artikel is meer een valkuil dan een bug. Het heeft te maken met de gepatenteerde T-SQL UNPIVOT-operator, waarmee u de draaiing van gegevens van een staat van kolommen naar een staat van rijen kunt ongedaan maken.
Ik gebruik een tabel met de naam CustOrders als mijn voorbeeldgegevens. Gebruik de volgende code om deze tabel te maken, in te vullen en te doorzoeken om de inhoud ervan weer te geven:
DROP TABLE IF EXISTS dbo.CustOrders;
GO
WITH C AS
(
SELECT custid, YEAR(orderdate) AS orderyearyear, val
FROM Sales.OrderValues
)
SELECT custid, [2017], [2018], [2019]
INTO dbo.CustOrders
FROM C
PIVOT( SUM(val)
FOR orderyearyear IN([2017], [2018], [2019]) ) AS P;
SELECT * FROM dbo.CustOrders; Deze code genereert de volgende uitvoer:
custid 2017 2018 2019 ------- ---------- ---------- ---------- 1 NULL 2022.50 2250.50 2 88.80 799.75 514.40 3 403.20 5960.78 660.00 4 1379.00 6406.90 5604.75 5 4324.40 13849.02 6754.16 6 NULL 1079.80 2160.00 7 9986.20 7817.88 730.00 8 982.00 3026.85 224.00 9 4074.28 11208.36 6680.61 10 1832.80 7630.25 11338.56 11 479.40 3179.50 2431.00 12 NULL 238.00 1576.80 13 100.80 NULL NULL 14 1674.22 6516.40 4158.26 15 2169.00 1128.00 513.75 16 NULL 787.60 931.50 17 533.60 420.00 2809.61 18 268.80 487.00 860.10 19 950.00 4514.35 9296.69 20 15568.07 48096.27 41210.65 ...
Deze tabel bevat de totale orderwaarden per klant en per jaar. NULL's vertegenwoordigen gevallen waarin een klant geen orderactiviteit had in het doeljaar.
Stel dat u de draaiing van de gegevens uit de tabel CustOrders ongedaan wilt maken, waarbij een rij per klant en per jaar wordt geretourneerd, met een resultaatkolom met de naam val die de totale orderwaarde voor de huidige klant en het huidige jaar bevat. Elke niet-pivoterende taak omvat over het algemeen drie elementen:
- De namen van de bestaande bronkolommen waarvan u de draaiing ongedaan maakt:[2017], [2018], [2019] in ons geval
- Een naam die u toewijst aan de doelkolom die de namen van de bronkolommen bevat:besteljaar in ons geval
- Een naam die u toewijst aan de doelkolom die de bronkolomwaarden bevat:val in ons geval
Als u besluit om de UNPIVOT-operator te gebruiken om de niet-draaiende taak uit te voeren, moet u eerst de bovenstaande drie elementen uitzoeken en vervolgens de volgende syntaxis gebruiken:
SELECT <table_cols except source_cols>, <names_col>, <values_col> FROM <source_table> UNPIVOT( <values_col> FOR <names_col> IN(<source_cols>) ) AS <alias>;
Toegepast op onze taak, gebruik je de volgende vraag:
SELECT custid, orderyear, val FROM dbo.CustOrders UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) ) AS U;
Deze query genereert de volgende uitvoer:
custid orderyear val ------- ---------- ---------- 1 2018 2022.50 1 2019 2250.50 2 2017 88.80 2 2018 799.75 2 2019 514.40 3 2017 403.20 3 2018 5960.78 3 2019 660.00 4 2017 1379.00 4 2018 6406.90 4 2019 5604.75 5 2017 4324.40 5 2018 13849.02 5 2019 6754.16 6 2018 1079.80 6 2019 2160.00 7 2017 9986.20 7 2018 7817.88 7 2019 730.00 ...
Als u naar de brongegevens en het zoekresultaat kijkt, merkt u dan wat er ontbreekt?
Het ontwerp van de UNPIVOT-operator omvat een impliciete eliminatie van resultaatrijen die een NULL hebben in de waardenkolom - in ons geval val. Als u naar het uitvoeringsplan voor deze query kijkt, weergegeven in afbeelding 2, kunt u zien dat de filteroperator de rijen verwijdert met de NULL's in de val-kolom (Expr1007 in het plan).
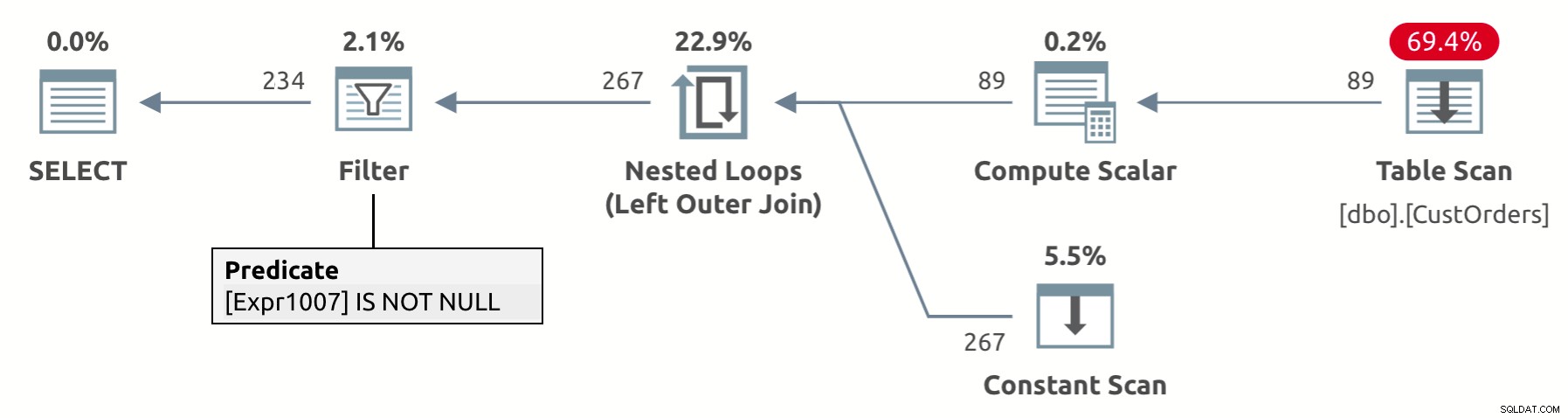 Afbeelding 2:plan voor unpivot-query met impliciete verwijdering van NULL's
Afbeelding 2:plan voor unpivot-query met impliciete verwijdering van NULL's
Soms is dit gedrag wenselijk, dan hoeft u niets speciaals te doen. Het probleem is dat je soms de rijen met de NULL's wilt behouden. De valkuil is wanneer je de NULL's wilt behouden en je je niet eens realiseert dat de UNPIVOT-operator is ontworpen om ze te verwijderen.
Wat geweldig zou kunnen zijn, is als de UNPIVOT-operator een optionele clausule had waarmee je kunt specificeren of je NULL's wilt verwijderen of behouden, waarbij de eerste de standaard is voor achterwaartse compatibiliteit. Hier is een voorbeeld van hoe deze syntaxis eruit zou kunnen zien:
SELECT <table_cols except source_cols>, <names_col>, <values_col>
FROM <source_table>
UNPIVOT( <values_col> FOR <names_col> IN(<source_cols>)
[REMOVE NULLS | KEEP NULLS] ) AS <alias>; Als u NULL's wilt behouden, zou u op basis van deze syntaxis de volgende query gebruiken:
SELECT custid, orderyear, val FROM dbo.CustOrders UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) KEEP NULLS ) AS U;
U kunt hier een feedbackitem vinden met een suggestie om de syntaxis van de UNPIVOT-operator op deze manier te verbeteren.
Als je ondertussen de rijen met de NULL's wilt behouden, moet je een tijdelijke oplossing bedenken. Als u erop staat de UNPIVOT-operator te gebruiken, moet u twee stappen toepassen. In de eerste stap definieert u een tabeluitdrukking op basis van een query die de functie ISNULL of COALESCE gebruikt om NULL's in alle niet-gedraaide kolommen te vervangen door een waarde die normaal niet in de gegevens kan voorkomen, bijvoorbeeld -1 in ons geval. In de tweede stap gebruik je de NULLIF-functie in de buitenste query tegen de waardenkolom om de -1 terug te vervangen door een NULL. Hier is de volledige oplossingscode:
WITH C AS
(
SELECT custid,
ISNULL([2017], -1.0) AS [2017],
ISNULL([2018], -1.0) AS [2018],
ISNULL([2019], -1.0) AS [2019]
FROM dbo.CustOrders
)
SELECT custid, orderyear, NULLIF(val, -1.0) AS val
FROM C UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) ) AS U; Hier is de uitvoer van deze query die laat zien dat rijen met NULL's in de val-kolom behouden blijven:
custid orderyear val ------- ---------- ---------- 1 2017 NULL 1 2018 2022.50 1 2019 2250.50 2 2017 88.80 2 2018 799.75 2 2019 514.40 3 2017 403.20 3 2018 5960.78 3 2019 660.00 4 2017 1379.00 4 2018 6406.90 4 2019 5604.75 5 2017 4324.40 5 2018 13849.02 5 2019 6754.16 6 2017 NULL 6 2018 1079.80 6 2019 2160.00 7 2017 9986.20 7 2018 7817.88 7 2019 730.00 ...
Deze aanpak is onhandig, vooral als je een groot aantal kolommen hebt om de draaiing ongedaan te maken.
Een alternatieve oplossing gebruikt een combinatie van de APPLY-operator en de VALUES-clausule. U construeert een rij voor elke niet-gedraaide kolom, waarbij één kolom de kolom met doelnamen vertegenwoordigt (besteljaar in ons geval), en een andere die de kolom met doelwaarden vertegenwoordigt (val in ons geval). U geeft het constante jaar op voor de namenkolom en de relevante gecorreleerde bronkolom voor de waardenkolom. Hier is de volledige oplossingscode:
SELECT custid, orderyear, val
FROM dbo.CustOrders
CROSS APPLY ( VALUES(2017, [2017]),
(2018, [2018]),
(2019, [2019]) ) AS A(orderyear, val); Het leuke hier is dat, tenzij je geïnteresseerd bent in het verwijderen van de rijen met de NULL's in de val-kolom, je niets speciaals hoeft te doen. Er is hier geen impliciete stap die de rijen met de NULLS verwijdert. Bovendien, aangezien de val-kolomalias is gemaakt als onderdeel van de FROM-component, is deze toegankelijk voor de WHERE-component. Dus als u geïnteresseerd bent in het verwijderen van de NULL's, kunt u hierover expliciet zijn in de WHERE-component door rechtstreeks te interageren met de alias van de waardenkolom, zoals:
SELECT custid, orderyear, val
FROM dbo.CustOrders
CROSS APPLY ( VALUES(2017, [2017]),
(2018, [2018]),
(2019, [2019]) ) AS A(orderyear, val)
WHERE val IS NOT NULL; Het punt is dat deze syntaxis je controle geeft over of je NULL's wilt behouden of verwijderen. Het is op een andere manier flexibeler dan de UNPIVOT-operator, waardoor u meerdere niet-geroteerde meetwaarden kunt verwerken, zoals zowel val als aantal. Mijn focus in dit artikel was echter de valkuil met NULL's, dus ik ben niet op dit aspect ingegaan.
Conclusie
Het ontwerp van de PIVOT- en UNPIVOT-operators leidt soms tot bugs en valkuilen in je code. De syntaxis van de PIVOT-operator laat u niet expliciet het groeperingselement aangeven. Als u zich dit niet realiseert, kunt u ongewenste groeperingselementen krijgen. Als best practice wordt aanbevolen dat u een tabelexpressie gebruikt als invoer voor de PIVOT-operator, en dit waarom expliciet bepaalt wat het groeperingselement is.
Met de syntaxis van de UNPIVOT-operator kunt u niet bepalen of u rijen met NULL's in de kolom met resultaatwaarden wilt verwijderen of behouden. Als tijdelijke oplossing gebruikt u ofwel een onhandige oplossing met de ISNULL- en NULLIF-functies, of een oplossing op basis van de APPLY-operator en de VALUES-component.
Ik noemde ook twee feedbackitems met suggesties om de PIVOT- en UNPIVOT-operatoren te verbeteren met meer expliciete opties om het gedrag van de operator en zijn elementen te controleren.