Een van de meest voorkomende termen die naar voren komen in discussies over het afstemmen van SQL Server-prestaties is wachtstatistieken . Dit gaat ver terug, zelfs vóór dit Microsoft-document uit 2006, "SQL Server 2005 Waits and Queues."
Wachttijden zijn absoluut niet alles, en deze methode is niet de enige manier om een instantie af te stemmen, laat staan een individuele vraag. Wachten is in feite vaak nutteloos als je alleen de vraag hebt die eraan ten grondslag ligt, en geen omringende context, vooral lang daarna. Dit komt omdat, heel vaak, het ding waarop een vraag wacht niet de fout van die vraag is . Zoals alles zijn er uitzonderingen, maar als je een tool of script kiest alleen omdat het deze zeer specifieke functionaliteit biedt, denk ik dat je jezelf een slechte dienst bewijst. Ik heb de neiging om een advies op te volgen dat Paul Randal me enige tijd geleden gaf:
...in het algemeen raad ik aan om te beginnen met wachttijden voor de hele instantie. Ik zou nooit beginnen probleemoplossing door te kijken naar de individuele wachttijden voor vragen.
Af en toe, ja, wil je misschien dieper in een individuele vraag graven en zien waar deze op wacht; in feite heeft Microsoft onlangs wachtstatistieken op vraagniveau toegevoegd aan showplan om te helpen bij deze analyse. Maar deze cijfers helpen u doorgaans niet om de prestaties van uw instantie als geheel af te stemmen, tenzij ze u helpen iets aan te wijzen dat toevallig ook van invloed is op uw volledige werklast. Als u één zoekopdracht van gisteren ziet die 5 minuten duurde en u merkt dat het wachttype LCK_M_S was , wat ga je er nu aan doen? Hoe ga je opsporen wat de vraag eigenlijk blokkeerde en dat wachttype veroorzaakte? Het kan zijn veroorzaakt door een transactie die om een andere reden niet werd uitgevoerd, maar dat kun je niet zien als je de status van het hele systeem niet kunt zien en je alleen kunt concentreren op individuele vragen en de wachttijden die ze hebben ondervonden.
Jason Hall (@SQLSaurus) noemde terloops iets dat ook voor mij interessant was. Hij zei dat als wachtstatistieken op queryniveau zo'n belangrijk onderdeel waren van de afstemmingsinspanningen, deze methodologie vanaf het begin in Query Store zou zijn ingebakken. Het is onlangs toegevoegd (in SQL Server 2017). Maar u krijgt nog steeds geen wachtstatistieken per uitvoering; u krijgt gemiddelden in de loop van de tijd, zoals de querystatistieken en procedurestatistieken die u in DMV's ziet. Dus plotselinge afwijkingen kunnen duidelijk zijn op basis van andere statistieken die worden vastgelegd per query-uitvoering, maar niet op basis van gemiddelden van wachttijden die over alle worden getrokken executies. U kunt het bereik aanpassen dat de wachttijden worden geaggregeerd, maar op drukke systemen is dit misschien nog niet gedetailleerd genoeg om te doen wat u denkt dat het voor u gaat doen.
Het doel van dit bericht is om enkele van de meest voorkomende soorten wachttijden te bespreken die we in ons klantenbestand zien, en wat voor soort acties je kunt (en niet moet) ondernemen wanneer ze zich voordoen. We hebben een database met anonieme wachtstatistieken die we al geruime tijd verzamelen van onze Cloud Sync-klanten, en sinds mei 2017 laten we iedereen zien hoe deze eruitzien in de SQLskills Waits Library.
Paul vertelt over de reden achter de bibliotheek en ook over onze integratie met deze gratis dienst. Kortom, je zoekt een wachttype op dat je ervaart of waar je nieuwsgierig naar bent, en hij legt uit wat het betekent en wat je eraan kunt doen. We vullen deze kwalitatieve informatie aan met een grafiek die laat zien hoe vaak het huidige wachten is onder onze gebruikers, en dat vergelijken met alle andere soorten wachten die we zien, zodat je snel kunt zien of je te maken hebt met een veelvoorkomend type wachten of iets meer exotisch. (Houd er rekening mee dat SQL Sentry niet de goedaardige, achtergrond- en wachtrijwachten bevat die zoveel ruis veroorzaken en dat de meeste scripts eruit filteren, zoals WAITFOR of LAZYWRITER_SLEEP - dit zijn gewoon geen bronnen van prestatieproblemen.)
Hier is een voorbeeldkaart voor CXPACKET , het meest voorkomende wachttype dat er is:
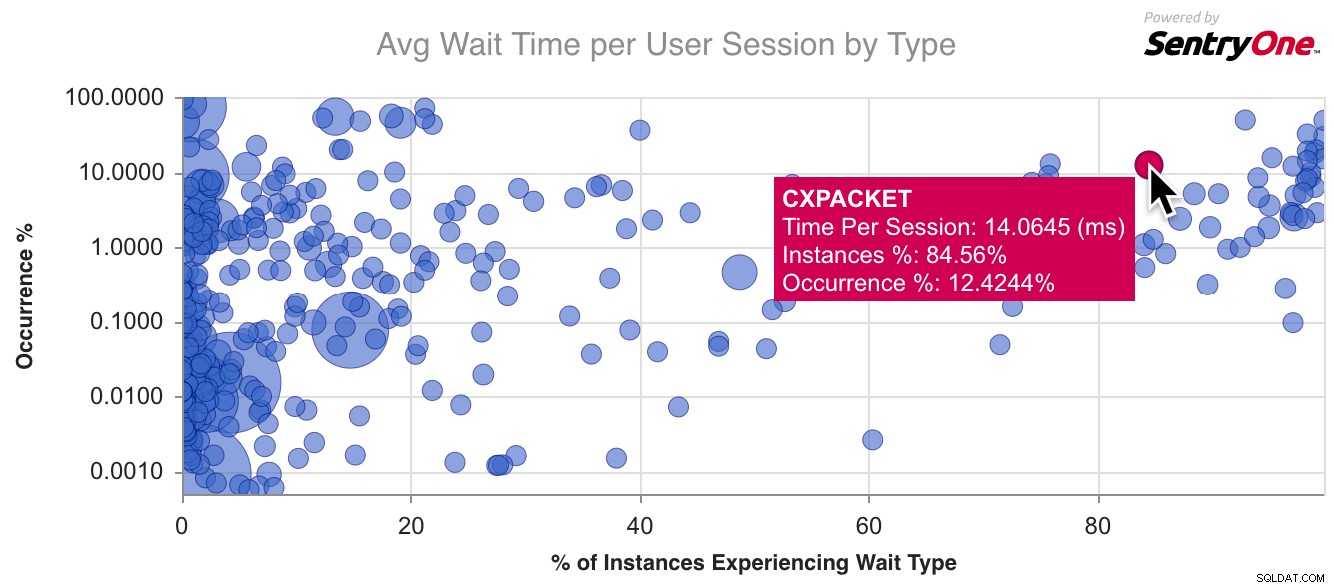
Ik begon een beetje verder te gaan dan dit, bracht enkele van de meest voorkomende soorten wacht in kaart en noteerde enkele van de eigenschappen die ze deelden. Vertaald naar vragen die een tuner zou kunnen hebben over een soort wachttijd die ze ervaren:
- Kan het type wacht worden opgelost op vraagniveau?
- Is het kernsymptoom van het wachten waarschijnlijk van invloed op andere vragen?
- Is het waarschijnlijk dat u meer informatie nodig heeft buiten de context van een enkele zoekopdracht en de wachttijden die het heeft ondervonden om het probleem te "oplossen"?
Toen ik begon met het schrijven van dit bericht, was het mijn doel om de meest voorkomende soorten wachten te groeperen en vervolgens aantekeningen te maken over de bovenstaande vragen. Jason haalde de meest voorkomende uit de bibliotheek en toen tekende ik wat kippenkras op een whiteboard, dat ik later een beetje opruimde. Dit eerste onderzoek leidde tot een lezing die Jason gaf op de meest recente TechOutbound SQL Cruise in Alaska. Ik schaam me een beetje dat hij maanden voordat ik deze post kon afmaken een gesprek in elkaar had gezet, dus laten we gewoon doorgaan. Dit zijn de hoogste wachttijden die we zien (die grotendeels overeenkomen met de enquête van Paul uit 2014), mijn antwoorden op de bovenstaande vragen en wat commentaar op elk:
Als u wilt communiceren met de links in de onderstaande tabel, gaat u naar deze pagina op een groter scherm.
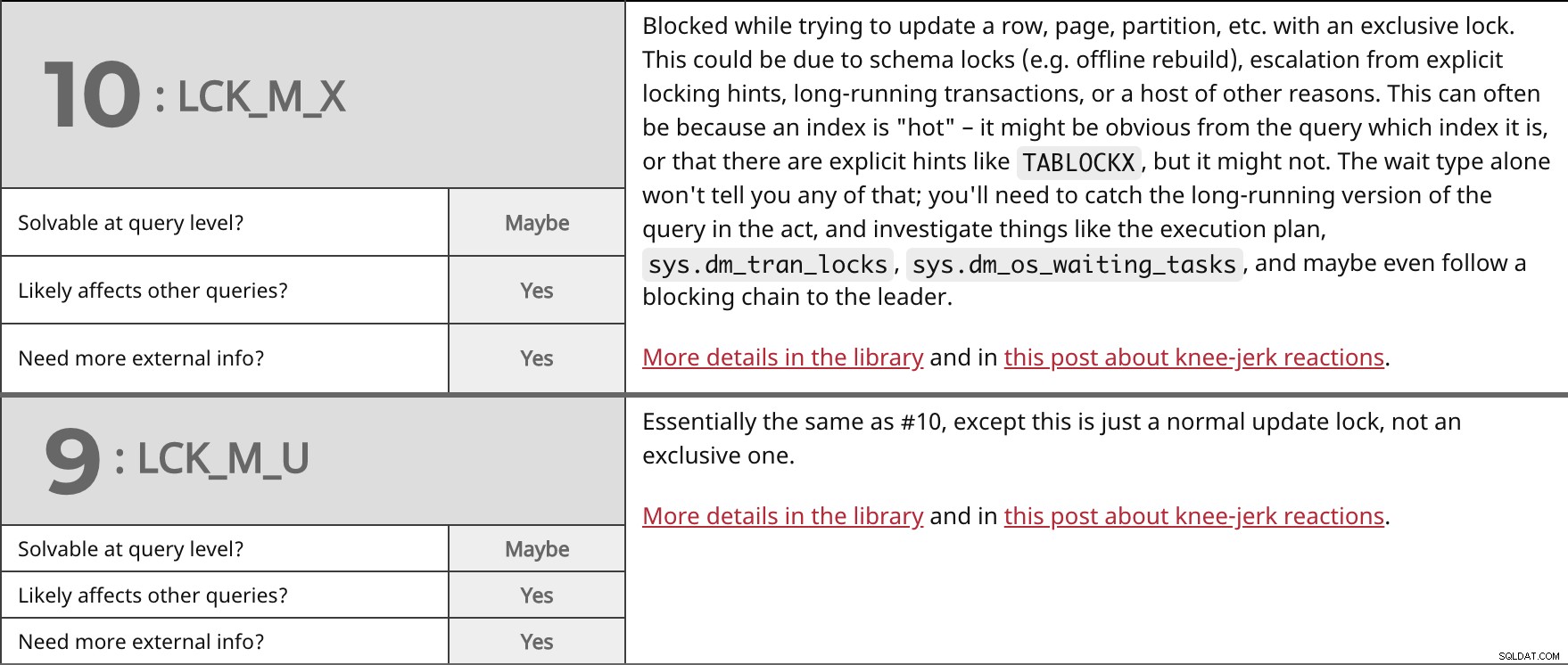
Geblokkeerd tijdens het updaten van een rij, pagina, partitie, etc. met een exclusieve vergrendeling. Dit kan te wijten zijn aan schemavergrendelingen (bijvoorbeeld offline opnieuw opbouwen), escalatie van expliciete vergrendelingshints, langlopende transacties of tal van andere redenen. Dit kan vaak zijn omdat een index "hot" is - uit de query kan duidelijk zijn welke index het is, of dat er expliciete hints zijn zoals TABLOCKX , maar misschien ook niet. Het wachttype alleen zal je daar niets van vertellen; je moet de langlopende versie van de query op heterdaad betrappen en dingen onderzoeken zoals het uitvoeringsplan, sys.dm_tran_locks , sys.dm_os_waiting_tasks , en misschien zelfs een blokkeerketen naar de leider volgen. Meer details in de bibliotheek en in dit bericht over reflexmatige reacties. | ||
| Oplosbaar op queryniveau? | Misschien | |
| Ja | ||
| Meer externe informatie nodig? | Ja | |
|
In wezen hetzelfde als #10, behalve dat dit een normale updatevergrendeling is, geen exclusieve. Meer details in de bibliotheek en in dit bericht over reflexmatige reacties. | ||
| Oplosbaar op queryniveau? | Misschien | |
| Ja | ||
| Meer externe informatie nodig? | Ja | |
|
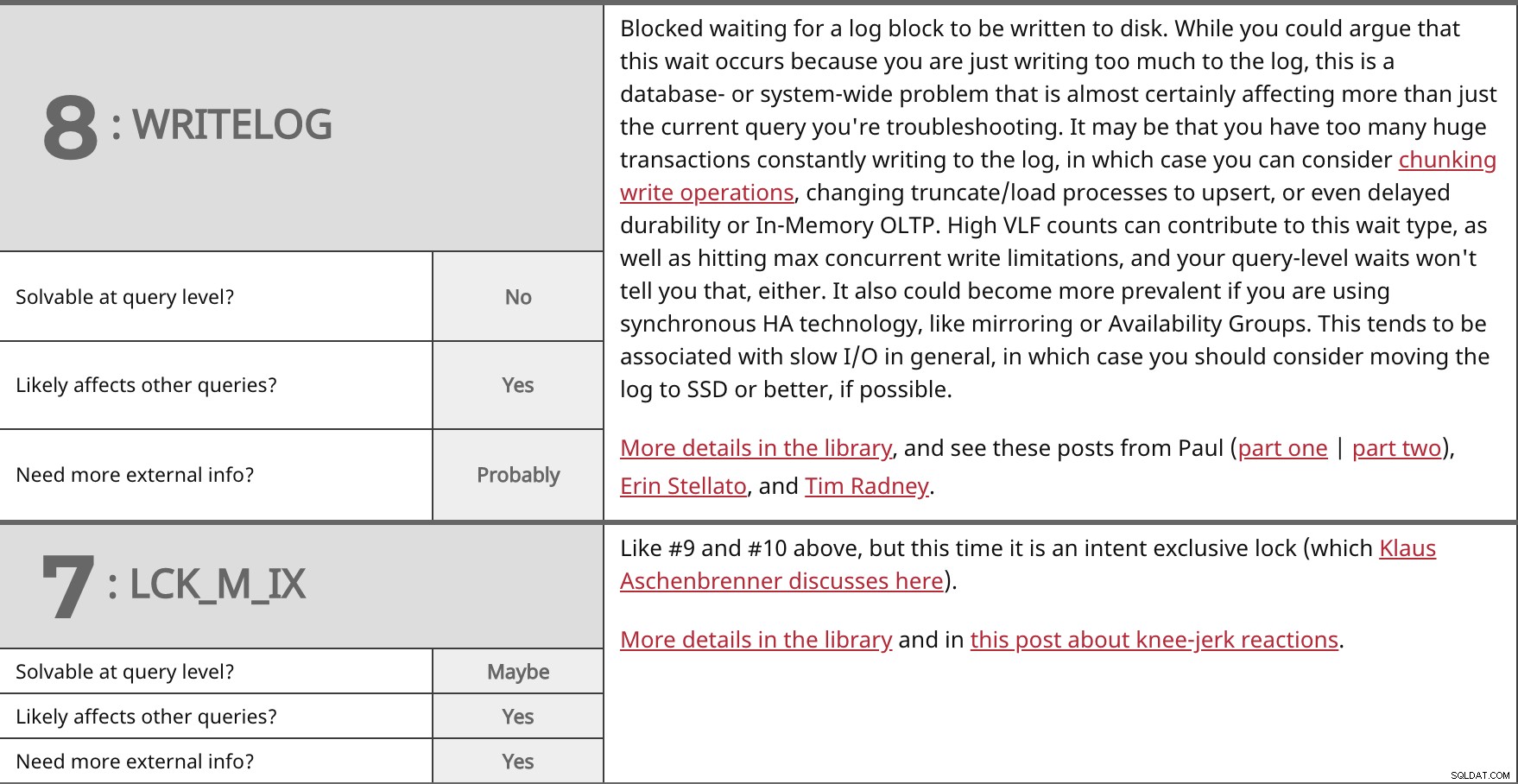
Geblokkeerd in afwachting van het schrijven van een logblok naar schijf. Hoewel je zou kunnen stellen dat dit wachten optreedt omdat je gewoon te veel naar het logboek schrijft, is dit een database- of systeembreed probleem dat vrijwel zeker van invloed is op meer dan alleen de huidige vraag die je aan het oplossen bent. Het kan zijn dat je te veel enorme transacties hebt die constant naar het logboek schrijven, in welk geval je kunt overwegen om schrijfbewerkingen op te splitsen, processen voor afkappen/laden te wijzigen in upsert, of zelfs vertraagde duurzaamheid of In-Memory OLTP. Hoge VLF-aantallen kunnen bijdragen aan dit type wacht, evenals maximale gelijktijdige schrijfbeperkingen bereiken, en uw wachttijden op queryniveau zullen u dat ook niet vertellen. Het kan ook vaker voorkomen als u synchrone HA-technologie gebruikt, zoals mirroring of beschikbaarheidsgroepen. Dit wordt meestal geassocieerd met trage I/O in het algemeen, in welk geval u zou moeten overwegen om het logboek indien mogelijk naar SSD of beter te verplaatsen. Meer details in de bibliotheek en deze berichten van Paul (deel één | deel twee), Erin Stellato en Tim Radney. | ||
| Oplosbaar op queryniveau? | Nee | |
| Ja | ||
| Meer externe informatie nodig? | Waarschijnlijk | |
|
Zoals #9 en #10 hierboven, maar deze keer is het een exclusieve vergrendeling (die Klaus Aschenbrenner hier bespreekt). Meer details in de bibliotheek en in dit bericht over reflexmatige reacties. | ||
| Oplosbaar op queryniveau? | Misschien | |
| Ja | ||
| Meer externe informatie nodig? | Ja | |
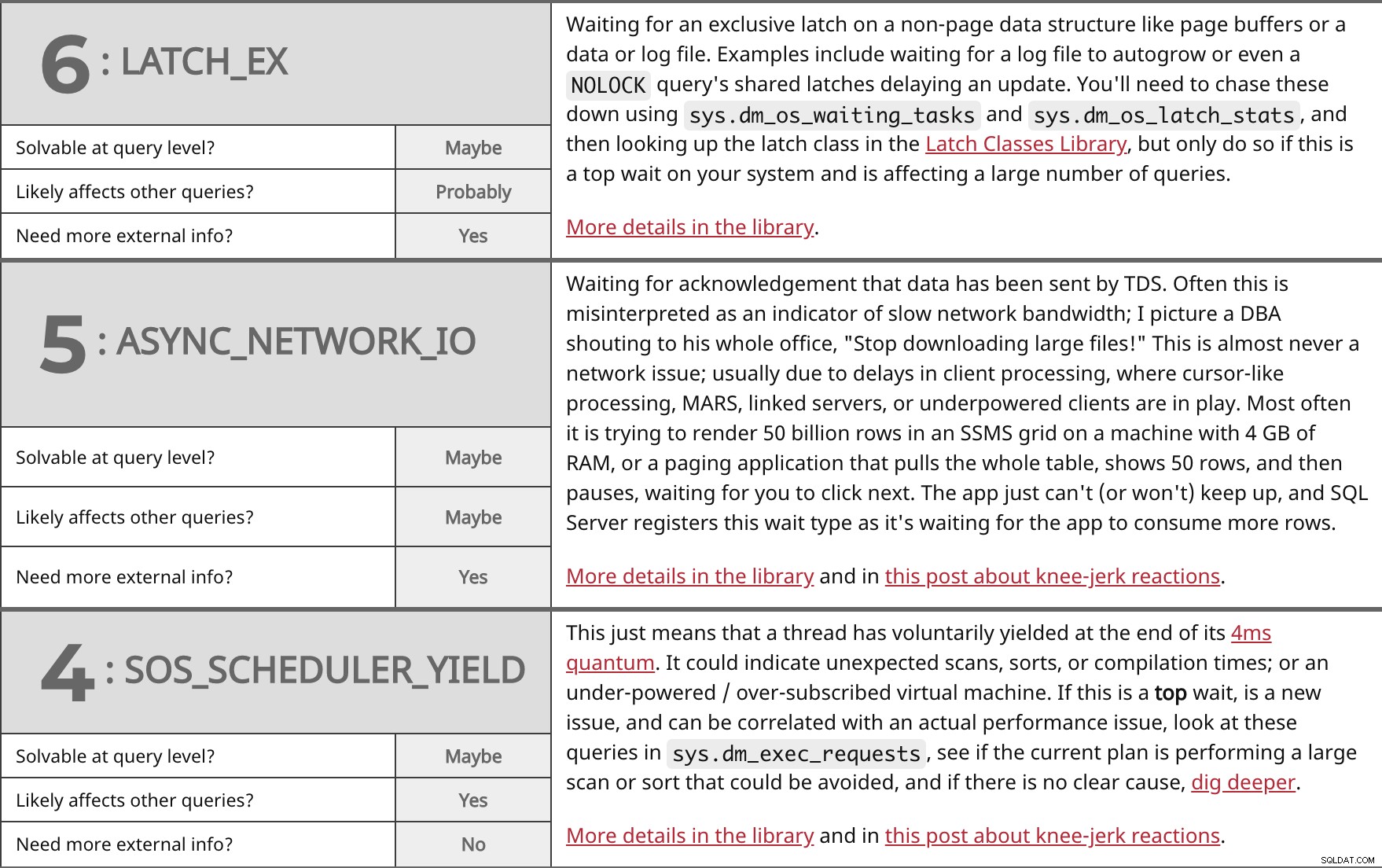
Wachten op een exclusieve vergrendeling op een niet-paginagegevensstructuur zoals paginabuffers of een gegevens- of logbestand. Voorbeelden zijn onder meer wachten op een logbestand om automatisch te groeien of zelfs een NOLOCK de gedeelde vergrendelingen van de query vertragen een update. U moet deze opsporen met sys.dm_os_waiting_tasks en sys.dm_os_latch_stats , en zoek vervolgens de vergrendelingsklasse op in de Latch Classes-bibliotheek, maar doe dit alleen als dit een topwachttijd op uw systeem is en een groot aantal vragen beïnvloedt. Meer details in de bibliotheek. | ||
| Oplosbaar op queryniveau? | Misschien | |
| Waarschijnlijk | ||
| Meer externe informatie nodig? | Ja | |
|
Wachten op bevestiging dat gegevens zijn verzonden door TDS. Vaak wordt dit verkeerd geïnterpreteerd als een indicator van trage netwerkbandbreedte; Ik stel me een DBA voor die tegen zijn hele kantoor schreeuwt:"Stop met het downloaden van grote bestanden!" Dit is bijna nooit een netwerkprobleem; meestal als gevolg van vertragingen in de verwerking van clients, waarbij cursorachtige verwerking, MARS, gekoppelde servers of te weinig krachtige clients in het spel zijn. Meestal probeert het 50 miljard rijen in een SSMS-raster weer te geven op een machine met 4 GB RAM, of een paging-toepassing die de hele tabel trekt, 50 rijen toont en vervolgens pauzeert, wachtend tot u op volgende klikt. De app kan (of wil) het gewoon niet bijhouden, en SQL Server registreert dit wachttype terwijl het wacht tot de app meer rijen verbruikt. Meer details in de bibliotheek en in dit bericht over reflexmatige reacties. | ||
| Oplosbaar op queryniveau? | Misschien | |
| Misschien | ||
| Meer externe informatie nodig? | Ja | |
Dit betekent alleen dat een thread vrijwillig heeft meegegeven aan het einde van zijn kwantum van 4 ms. Het kan duiden op onverwachte scans, sorteringen of compilatietijden; of een virtuele machine met te weinig vermogen/te veel inschrijvingen. Als dit een top . is wacht, is een nieuw probleem en kan worden gecorreleerd met een daadwerkelijk prestatieprobleem, bekijk deze vragen in sys.dm_exec_requests , kijk of het huidige plan een grote scan of sortering uitvoert die vermeden kan worden, en als er geen duidelijke oorzaak is, graaf dan dieper. Meer details in de bibliotheek en in dit bericht over reflexmatige reacties. | ||
| Oplosbaar op queryniveau? | Misschien | |
| Ja | ||
| Meer externe informatie nodig? | Nee | |
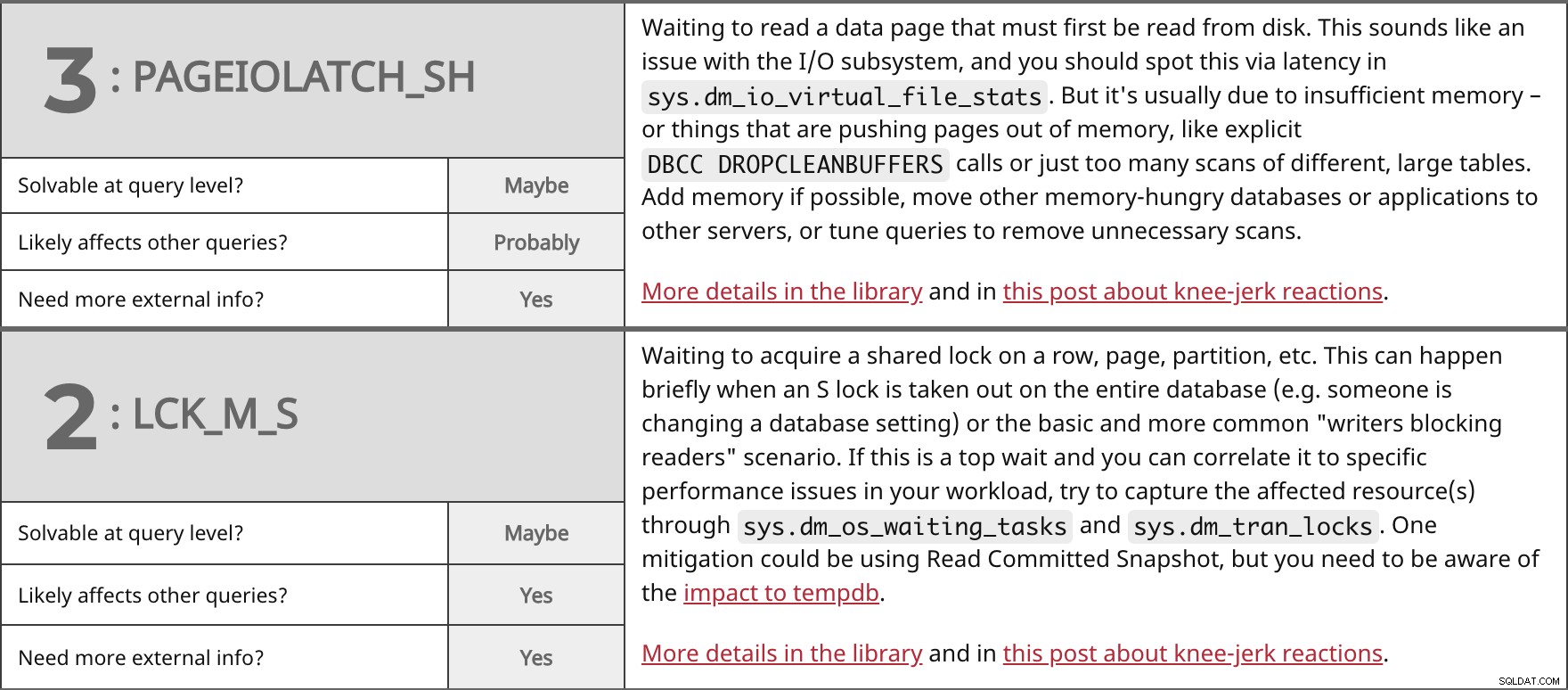
Wachten op het lezen van een gegevenspagina die eerst van schijf moet worden gelezen. Dit klinkt als een probleem met het I/O-subsysteem, en je zou dit moeten zien via latentie in sys.dm_io_virtual_file_stats . Maar het is meestal te wijten aan onvoldoende geheugen - of dingen die pagina's uit het geheugen duwen, zoals expliciete DBCC DROPCLEANBUFFERS telefoontjes of gewoon te veel scans van verschillende, grote tafels. Voeg indien mogelijk geheugen toe, verplaats andere geheugenverslindende databases of applicaties naar andere servers, of stem zoekopdrachten af om onnodige scans te verwijderen. Meer details in de bibliotheek en in dit bericht over reflexmatige reacties. | ||
| Oplosbaar op queryniveau? | Misschien | |
| Waarschijnlijk | ||
| Meer externe informatie nodig? | Ja | |
Wachten op het verkrijgen van een gedeelde vergrendeling op een rij, pagina, partitie, enz. Dit kan kort gebeuren wanneer een S-vergrendeling op de hele database wordt verwijderd (bijv. een database-instelling) of het standaard en meer algemene scenario "schrijvers die lezers blokkeren". Als dit een topwachttijd is en je het kunt correleren met specifieke prestatieproblemen in je werklast, probeer dan de getroffen resource(s) vast te leggen via sys.dm_os_waiting_tasks en sys.dm_tran_locks . Een oplossing zou het gebruik van Read Committed Snapshot kunnen zijn, maar u moet zich bewust zijn van de impact op tempdb. Meer details in de bibliotheek en in dit bericht over reflexmatige reacties. | ||
| Oplosbaar op queryniveau? | Misschien | |
| Ja | ||
| Meer externe informatie nodig? | Ja | |
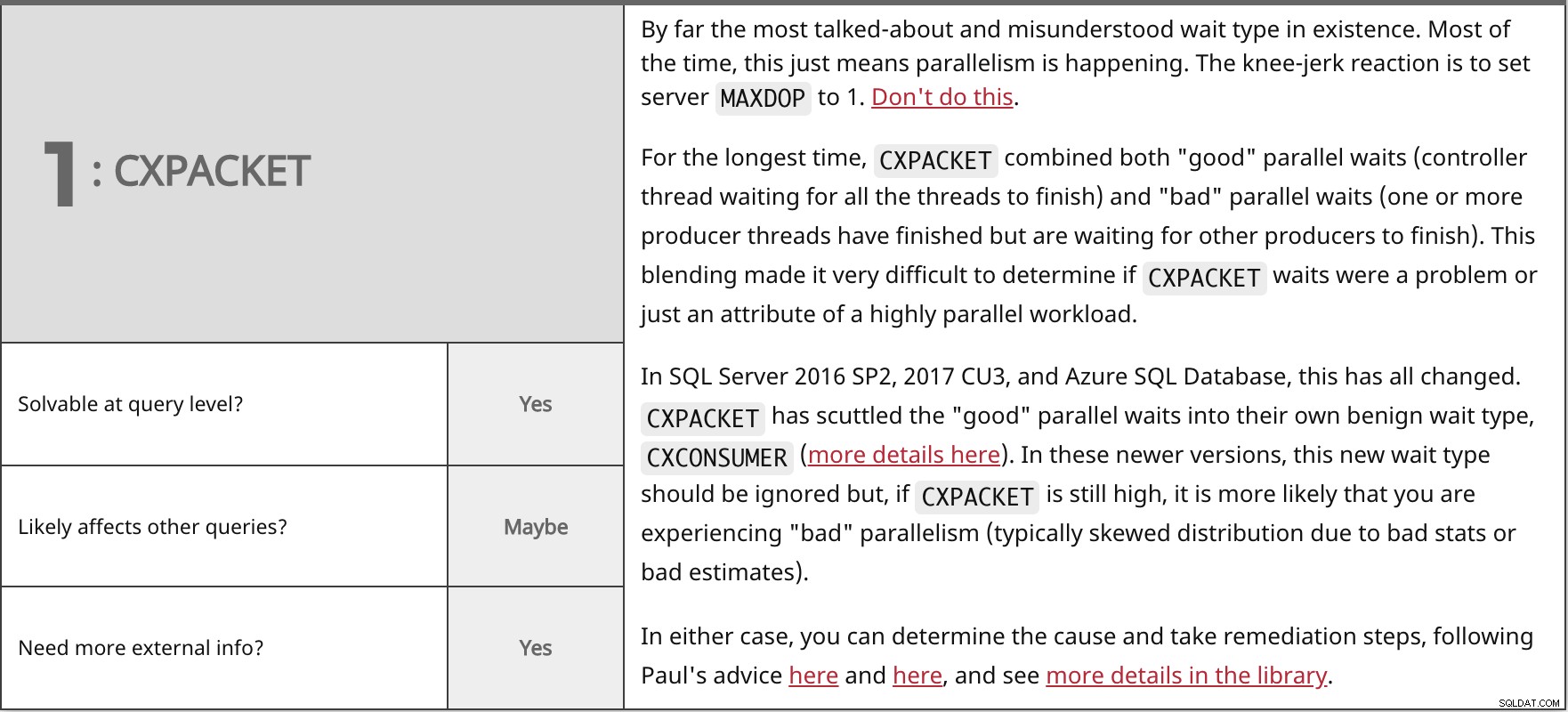
Verreweg het meest spraakmakende en verkeerd begrepen wachttype dat er bestaat. Meestal betekent dit gewoon dat er parallellisme plaatsvindt. De reflexmatige reactie is het instellen van server MAXDOP tot 1. Doe dit niet.
Voor de langste tijd,
In SQL Server 2016 SP2, 2017 CU3 en Azure SQL Database is dit allemaal veranderd. In beide gevallen kunt u de oorzaak achterhalen en herstelmaatregelen nemen, volgens het advies van Paul hier en hier, en meer details bekijken in de bibliotheek. | ||
| Oplosbaar op queryniveau? | Ja | |
| Misschien | ||
| Meer externe informatie nodig? | Ja | |
Samenvatting
In de meeste van deze gevallen is het beter om de wachttijden op instantieniveau te bekijken en alleen de wachttijden op queryniveau aan te scherpen wanneer u problemen oplost met specifieke query's die prestatieproblemen vertonen, ongeacht het type wachttijd. Dit zijn dingen die om andere redenen naar boven komen, zoals lange duur, hoge CPU of hoge I/O, en die niet kunnen worden verklaard door eenvoudigere dingen (zoals een geclusterde indexscan wanneer je een zoekopdracht verwachtte).
Zelfs op instantieniveau moet u niet elke wachttijd achtervolgen die de beste wachttijd op uw systeem wordt - u zult ALTIJD wacht even en je zult nooit kunnen stoppen met het achtervolgen. Zorg ervoor dat u goedaardige wachttijden negeert (Paul houdt een lijst bij) en u alleen zorgen maakt over wachttijden die u kunt associëren met een daadwerkelijk prestatieprobleem dat u ondervindt. Als CXPACKET de wachttijden zijn hoog, dus wat? Zijn er nog andere symptomen behalve dat het aantal "hoog" is of bovenaan de lijst staat?
Het komt er allemaal op neer waarom u in de eerste plaats problemen oplost. Klaagt een enkele gebruiker over een enkele instantie van een frauduleuze zoekopdracht? Is uw server op zijn knieën? Iets er tussenin? In het eerste geval kan het natuurlijk handig zijn om te weten waarom een zoekopdracht traag is, maar het is vrij duur om alle wachttijden bij te houden die bij elke afzonderlijke zoekopdracht horen, de hele dag, elke dag, met de oneven kans dat u later terug wilt komen om ze te bekijken. Als het een wijdverbreid probleem is dat losstaat van die query, moet u kunnen bepalen waardoor die query traag wordt door deze opnieuw uit te voeren en het uitvoeringsplan, de compilatietijd en andere runtime-statistieken te verzamelen. Als het een eenmalig iets was dat afgelopen dinsdag is gebeurd, of u nu wacht op dat ene exemplaar van de query of niet, kunt u het probleem mogelijk niet oplossen zonder meer context. Misschien was er een blokkering, maar je weet niet waardoor, of misschien was er een I/O-piek, maar je zult dat probleem apart moeten opsporen. Het wachttype op zichzelf biedt meestal niet genoeg informatie, behalve in het beste geval een verwijzing naar iets anders.
Natuurlijk moet ik hier ook mijn brood verdienen. Ons vlaggenschipproduct, SQL Sentry, hanteert een holistische benadering van monitoring. We verzamelen wachtstatistieken voor de hele instantie, categoriseren ze voor u en geven ze een grafiek op ons dashboard:
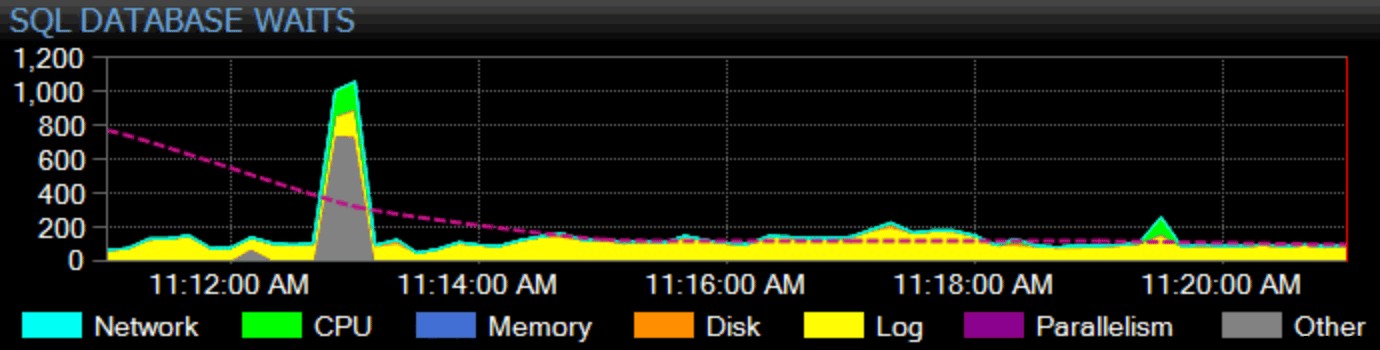
U kunt aanpassen hoe elke individuele wachttijd wordt gecategoriseerd en of die categorie zelfs op het dashboard wordt weergegeven. U kunt de huidige wachtstatistieken vergelijken met ingebouwde of aangepaste baselines, en zelfs waarschuwingen of acties instellen wanneer deze een bepaalde afwijking van de baseline overschrijden. En, misschien wel het belangrijkste, u kunt naar een gegevenspunt uit het verleden kijken en het hele dashboard naar dat tijdstip synchroniseren, zodat u alle omringende context en elke andere situatie die het probleem mogelijk heeft beïnvloed, kunt vastleggen. Wanneer u meer gedetailleerde dingen vindt om op te focussen, zoals blokkering, hoge schijflatentie of query's met hoge I/O of lange duur, kunt u dieper in die statistieken inzoomen en vrij snel tot de kern van het probleem komen.
Voor meer informatie over zowel algemene wachtstatistieken als onze oplossing specifiek, kun je de whitepaper van Kevin Kline, Problemen met SQL Server Wachtstatistieken oplossen, bekijken en een tweedelig webinar downloaden, gepresenteerd door Paul Randal, Andy Yun (@SQLBek), en Andy Mallon (@AMtwo):
- Deel 1:probleemoplossing voor prestaties met behulp van wachtstatistieken
- Deel 2:Snelle analyse van wachtstatistieken met SentryOne
En als je het SentryOne Platform eens wilt proberen, kun je hier aan de slag met een tijdelijke aanbieding:
Download een gratis proefperiode van 15 dagen