Gaps and Islands-taken zijn klassieke query-uitdagingen waarbij u reeksen van ontbrekende waarden en reeksen van bestaande waarden in een reeks moet identificeren. De reeks is vaak gebaseerd op bepaalde datum- of datum- en tijdwaarden, die normaal gesproken met regelmatige tussenpozen zouden moeten verschijnen, maar sommige vermeldingen ontbreken. De taak met gaten zoekt naar de ontbrekende perioden en de taak met eilanden zoekt naar de bestaande perioden. Ik heb in het verleden veel oplossingen voor hiaten en eilandtaken behandeld in mijn boeken en artikelen. Onlangs kreeg ik van mijn vriend, Adam Machanic, een nieuwe uitdaging voor speciale eilanden voorgeschoteld, en het oplossen ervan vergde wat creativiteit. In dit artikel presenteer ik de uitdaging en de oplossing die ik bedacht heb.
De uitdaging
In uw database houdt u de services bij die uw bedrijf ondersteunt in een tabel met de naam CompanyServices, en elke service meldt normaal gesproken ongeveer één keer per minuut dat deze online is in een tabel met de naam EventLog. De volgende code maakt deze tabellen en vult ze met kleine sets voorbeeldgegevens:
SET NOCOUNT ON; USE tempdb; IF OBJECT_ID(N'dbo.EventLog') IS NOT NULL DROP TABLE dbo.EventLog; IF OBJECT_ID(N'dbo.CompanyServices') IS NOT NULL DROP TABLE dbo.CompanyServices; CREATE TABLE dbo.CompanyServices ( serviceid INT NOT NULL, CONSTRAINT PK_CompanyServices PRIMARY KEY(serviceid) ); GO INSERT INTO dbo.CompanyServices(serviceid) VALUES(1), (2), (3); CREATE TABLE dbo.EventLog ( logid INT NOT NULL IDENTITY, serviceid INT NOT NULL, logtime DATETIME2(0) NOT NULL, CONSTRAINT PK_EventLog PRIMARY KEY(logid) ); GO INSERT INTO dbo.EventLog(serviceid, logtime) VALUES (1, '20180912 08:00:00'), (1, '20180912 08:01:01'), (1, '20180912 08:01:59'), (1, '20180912 08:03:00'), (1, '20180912 08:05:00'), (1, '20180912 08:06:02'), (2, '20180912 08:00:02'), (2, '20180912 08:01:03'), (2, '20180912 08:02:01'), (2, '20180912 08:03:00'), (2, '20180912 08:03:59'), (2, '20180912 08:05:01'), (2, '20180912 08:06:01'), (3, '20180912 08:00:01'), (3, '20180912 08:03:01'), (3, '20180912 08:04:02'), (3, '20180912 08:06:00'); SELECT * FROM dbo.EventLog;
De EventLog-tabel is momenteel gevuld met de volgende gegevens:
logid serviceid logtime ----------- ----------- --------------------------- 1 1 2018-09-12 08:00:00 2 1 2018-09-12 08:01:01 3 1 2018-09-12 08:01:59 4 1 2018-09-12 08:03:00 5 1 2018-09-12 08:05:00 6 1 2018-09-12 08:06:02 7 2 2018-09-12 08:00:02 8 2 2018-09-12 08:01:03 9 2 2018-09-12 08:02:01 10 2 2018-09-12 08:03:00 11 2 2018-09-12 08:03:59 12 2 2018-09-12 08:05:01 13 2 2018-09-12 08:06:01 14 3 2018-09-12 08:00:01 15 3 2018-09-12 08:03:01 16 3 2018-09-12 08:04:02 17 3 2018-09-12 08:06:00
De taak van de speciale eilanden is het identificeren van de beschikbaarheidsperioden (service, starttijd, eindtijd). Een addertje onder het gras is dat er geen garantie is dat een service precies elke minuut zal melden dat deze online is; je wordt verondersteld een interval van bijvoorbeeld 66 seconden vanaf de vorige logboekinvoer te tolereren en het toch als onderdeel van dezelfde beschikbaarheidsperiode (eiland) te beschouwen. Na 66 seconden begint de nieuwe logboekinvoer een nieuwe beschikbaarheidsperiode. Dus voor de bovenstaande invoervoorbeeldgegevens wordt verondersteld dat uw oplossing de volgende resultatenset retourneert (niet noodzakelijk in deze volgorde):
serviceid starttime endtime ----------- --------------------------- --------------------------- 1 2018-09-12 08:00:00 2018-09-12 08:03:00 1 2018-09-12 08:05:00 2018-09-12 08:06:02 2 2018-09-12 08:00:02 2018-09-12 08:06:01 3 2018-09-12 08:00:01 2018-09-12 08:00:01 3 2018-09-12 08:03:01 2018-09-12 08:04:02 3 2018-09-12 08:06:00 2018-09-12 08:06:00
Merk bijvoorbeeld op hoe loginvoer 5 een nieuw eiland start aangezien het interval van de vorige loginvoer 120 seconden is (> 66), terwijl loginvoer 6 geen nieuw eiland start aangezien het interval van de vorige invoer 62 seconden is ( <=66). Een ander nadeel is dat Adam wilde dat de oplossing compatibel zou zijn met pre-SQL Server 2012-omgevingen, wat het een veel moeilijkere uitdaging maakt, omdat je geen vensteraggregatiefuncties met een frame kunt gebruiken om lopende totalen en offsetvensterfuncties te berekenen. zoals LAG en LEAD. Zoals gewoonlijk raad ik aan eerst de uitdaging zelf op te lossen voordat je naar mijn oplossingen kijkt. Gebruik de kleine sets met voorbeeldgegevens om de geldigheid van uw oplossingen te controleren. Gebruik de volgende code om uw tabellen te vullen met grote sets voorbeeldgegevens (500 services, ~10M logboekvermeldingen om de prestaties van uw oplossingen te testen):
-- Helper function dbo.GetNums
IF OBJECT_ID(N'dbo.GetNums') IS NOT NULL DROP FUNCTION dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
-- ~10,000,000 intervals
DECLARE
@numservices AS INT = 500,
@logsperservice AS INT = 20000,
@enddate AS DATETIME2(0) = '20180912',
@validinterval AS INT = 60, -- seconds
@normdifferential AS INT = 3, -- seconds
@percentmissing AS FLOAT = 0.01;
TRUNCATE TABLE dbo.EventLog;
TRUNCATE TABLE dbo.CompanyServices;
INSERT INTO dbo.CompanyServices(serviceid)
SELECT A.n AS serviceid
FROM dbo.GetNums(1, @numservices) AS A;
WITH C AS
(
SELECT S.n AS serviceid,
DATEADD(second, -L.n * @validinterval + CHECKSUM(NEWID()) % (@normdifferential + 1), @enddate) AS logtime,
RAND(CHECKSUM(NEWID())) AS rnd
FROM dbo.GetNums(1, @numservices) AS S
CROSS JOIN dbo.GetNums(1, @logsperservice) AS L
)
INSERT INTO dbo.EventLog WITH (TABLOCK) (serviceid, logtime)
SELECT serviceid, logtime
FROM C
WHERE rnd > @percentmissing; De uitvoer die ik zal leveren voor de stappen van mijn oplossingen, zal uitgaan van de kleine sets met voorbeeldgegevens, en de prestatienummers die ik zal leveren, zullen de grote sets aannemen.
Alle oplossingen die ik zal presenteren, profiteren van de volgende index:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Veel succes!
Oplossing 1 voor SQL Server 2012+
Voordat ik een oplossing behandel die compatibel is met pre-SQL Server 2012-omgevingen, zal ik er een behandelen die minimaal SQL Server 2012 vereist. Ik noem het oplossing 1.
De eerste stap in de oplossing is het berekenen van een vlag genaamd isstart die 0 is als de gebeurtenis geen nieuw eiland start, en anders 1. Dit kan worden bereikt door de LAG-functie te gebruiken om de logtijd van de vorige gebeurtenis te verkrijgen en te controleren of het tijdsverschil in seconden tussen de vorige en huidige gebeurtenissen kleiner is dan of gelijk is aan de toegestane tussenruimte. Hier is de code die deze stap implementeert:
DECLARE @allowedgap AS INT = 66; -- in seconds
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog; Deze code genereert de volgende uitvoer:
logid serviceid logtime isstart ----------- ----------- --------------------------- ----------- 1 1 2018-09-12 08:00:00 1 2 1 2018-09-12 08:01:01 0 3 1 2018-09-12 08:01:59 0 4 1 2018-09-12 08:03:00 0 5 1 2018-09-12 08:05:00 1 6 1 2018-09-12 08:06:02 0 7 2 2018-09-12 08:00:02 1 8 2 2018-09-12 08:01:03 0 9 2 2018-09-12 08:02:01 0 10 2 2018-09-12 08:03:00 0 11 2 2018-09-12 08:03:59 0 12 2 2018-09-12 08:05:01 0 13 2 2018-09-12 08:06:01 0 14 3 2018-09-12 08:00:01 1 15 3 2018-09-12 08:03:01 1 16 3 2018-09-12 08:04:02 0 17 3 2018-09-12 08:06:00 1
Vervolgens produceert een eenvoudig lopend totaal van de isstart-vlag een eiland-ID (ik noem het grp). Hier is de code die deze stap implementeert:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
)
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1; Deze code genereert de volgende uitvoer:
logid serviceid logtime isstart grp ----------- ----------- --------------------------- ----------- ----------- 1 1 2018-09-12 08:00:00 1 1 2 1 2018-09-12 08:01:01 0 1 3 1 2018-09-12 08:01:59 0 1 4 1 2018-09-12 08:03:00 0 1 5 1 2018-09-12 08:05:00 1 2 6 1 2018-09-12 08:06:02 0 2 7 2 2018-09-12 08:00:02 1 1 8 2 2018-09-12 08:01:03 0 1 9 2 2018-09-12 08:02:01 0 1 10 2 2018-09-12 08:03:00 0 1 11 2 2018-09-12 08:03:59 0 1 12 2 2018-09-12 08:05:01 0 1 13 2 2018-09-12 08:06:01 0 1 14 3 2018-09-12 08:00:01 1 1 15 3 2018-09-12 08:03:01 1 2 16 3 2018-09-12 08:04:02 0 2 17 3 2018-09-12 08:06:00 1 3
Ten slotte groepeert u de rijen op service-ID en de eiland-ID en retourneert u de minimale en maximale logtijden als de start- en eindtijd van elk eiland. Hier is de complete oplossing:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
),
C2 AS
(
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1
)
SELECT serviceid, MIN(logtime) AS starttime, MAX(logtime) AS endtime
FROM C2
GROUP BY serviceid, grp; Deze oplossing nam 41 seconden in beslag op mijn systeem en leverde het plan op dat wordt getoond in Afbeelding 1.
 Figuur 1:plan voor oplossing 1
Figuur 1:plan voor oplossing 1
Zoals u kunt zien, worden beide vensterfuncties berekend op basis van indexvolgorde, zonder dat expliciete sortering nodig is.
Als u SQL Server 2016 of hoger gebruikt, kunt u de truc gebruiken die ik hier behandel om de batchmodus Window Aggregate-operator in te schakelen door een lege gefilterde columnstore-index te maken, zoals:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
Dezelfde oplossing duurt nu slechts 5 seconden om te voltooien op mijn systeem, waardoor het plan wordt weergegeven in Afbeelding 2.
 Figuur 2:Plan voor oplossing 1 met behulp van de batchmodus Window Aggregate-operator
Figuur 2:Plan voor oplossing 1 met behulp van de batchmodus Window Aggregate-operator
Dit is allemaal geweldig, maar zoals gezegd, Adam was op zoek naar een oplossing die op pre-2012-omgevingen kan draaien.
Voordat u verder gaat, moet u ervoor zorgen dat u de columnstore-index laat vallen voor opschonen:
DROP INDEX idx_cs ON dbo.EventLog;
Oplossing 2 voor pre-SQL Server 2012-omgevingen
Helaas hadden we vóór SQL Server 2012 geen ondersteuning voor offset-vensterfuncties zoals LAG, en evenmin hadden we ondersteuning voor het berekenen van lopende totalen met vensteraggregatiefuncties met een frame. Dit betekent dat je veel harder moet werken om tot een redelijke oplossing te komen.
De truc die ik heb gebruikt, is om elke logboekinvoer om te zetten in een kunstmatig interval waarvan de starttijd de logboektijd van het item is en waarvan de eindtijd de logboektijd van het item plus de toegestane opening is. U kunt de taak dan behandelen als een klassieke intervalverpakkingstaak.
De eerste stap in de oplossing berekent de kunstmatige intervalscheidingstekens en rijnummers die de posities van elk van de gebeurtenissoorten markeren (counteach). Hier is de code die deze stap implementeert:
DECLARE @allowedgap AS INT = 66; SELECT logid, serviceid, logtime AS s, -- important, 's' > 'e', for later ordering DATEADD(second, @allowedgap, logtime) AS e, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach FROM dbo.EventLog;
Deze code genereert de volgende uitvoer:
logid serviceid s e counteach ------ ---------- -------------------- -------------------- ---------- 1 1 2018-09-12 08:00:00 2018-09-12 08:01:06 1 2 1 2018-09-12 08:01:01 2018-09-12 08:02:07 2 3 1 2018-09-12 08:01:59 2018-09-12 08:03:05 3 4 1 2018-09-12 08:03:00 2018-09-12 08:04:06 4 5 1 2018-09-12 08:05:00 2018-09-12 08:06:06 5 6 1 2018-09-12 08:06:02 2018-09-12 08:07:08 6 7 2 2018-09-12 08:00:02 2018-09-12 08:01:08 1 8 2 2018-09-12 08:01:03 2018-09-12 08:02:09 2 9 2 2018-09-12 08:02:01 2018-09-12 08:03:07 3 10 2 2018-09-12 08:03:00 2018-09-12 08:04:06 4 11 2 2018-09-12 08:03:59 2018-09-12 08:05:05 5 12 2 2018-09-12 08:05:01 2018-09-12 08:06:07 6 13 2 2018-09-12 08:06:01 2018-09-12 08:07:07 7 14 3 2018-09-12 08:00:01 2018-09-12 08:01:07 1 15 3 2018-09-12 08:03:01 2018-09-12 08:04:07 2 16 3 2018-09-12 08:04:02 2018-09-12 08:05:08 3 17 3 2018-09-12 08:06:00 2018-09-12 08:07:06 4
De volgende stap is het ongedaan maken van de draaiing van de intervallen in een chronologische volgorde van begin- en eindgebeurtenissen, respectievelijk aangeduid als gebeurtenistypen 's' en 'e'. Merk op dat de keuze van de letters s en e belangrijk is ('s' > 'e' ). Deze stap berekent rijnummers die de juiste chronologische volgorde markeren van beide gebeurtenissoorten, die nu zijn doorschoten (countboth). In het geval dat een interval precies eindigt waar een ander begint, door het begingebeurtenis vóór het eindgebeurtenis te plaatsen, verpakt u ze samen. Hier is de code die deze stap implementeert:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
)
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U; Deze code genereert de volgende uitvoer:
logid serviceid logtime eventtype counteach countboth ------ ---------- -------------------- ---------- ---------- ---------- 1 1 2018-09-12 08:00:00 s 1 1 2 1 2018-09-12 08:01:01 s 2 2 1 1 2018-09-12 08:01:06 e 1 3 3 1 2018-09-12 08:01:59 s 3 4 2 1 2018-09-12 08:02:07 e 2 5 4 1 2018-09-12 08:03:00 s 4 6 3 1 2018-09-12 08:03:05 e 3 7 4 1 2018-09-12 08:04:06 e 4 8 5 1 2018-09-12 08:05:00 s 5 9 6 1 2018-09-12 08:06:02 s 6 10 5 1 2018-09-12 08:06:06 e 5 11 6 1 2018-09-12 08:07:08 e 6 12 7 2 2018-09-12 08:00:02 s 1 1 8 2 2018-09-12 08:01:03 s 2 2 7 2 2018-09-12 08:01:08 e 1 3 9 2 2018-09-12 08:02:01 s 3 4 8 2 2018-09-12 08:02:09 e 2 5 10 2 2018-09-12 08:03:00 s 4 6 9 2 2018-09-12 08:03:07 e 3 7 11 2 2018-09-12 08:03:59 s 5 8 10 2 2018-09-12 08:04:06 e 4 9 12 2 2018-09-12 08:05:01 s 6 10 11 2 2018-09-12 08:05:05 e 5 11 13 2 2018-09-12 08:06:01 s 7 12 12 2 2018-09-12 08:06:07 e 6 13 13 2 2018-09-12 08:07:07 e 7 14 14 3 2018-09-12 08:00:01 s 1 1 14 3 2018-09-12 08:01:07 e 1 2 15 3 2018-09-12 08:03:01 s 2 3 16 3 2018-09-12 08:04:02 s 3 4 15 3 2018-09-12 08:04:07 e 2 5 16 3 2018-09-12 08:05:08 e 3 6 17 3 2018-09-12 08:06:00 s 4 7 17 3 2018-09-12 08:07:06 e 4 8
Zoals vermeld, markeert counteach de positie van de gebeurtenis tussen alleen de gebeurtenissen van dezelfde soort, en countboth markeert de positie van de gebeurtenis tussen de gecombineerde, verweven gebeurtenissen van beide soorten.
De magie wordt vervolgens afgehandeld door de volgende stap:het berekenen van het aantal actieve intervallen na elke gebeurtenis op basis van counteach en count both. Het aantal actieve intervallen is het aantal startgebeurtenissen dat tot nu toe heeft plaatsgevonden minus het aantal eindgebeurtenissen dat tot nu toe heeft plaatsgevonden. Voor startgebeurtenissen vertelt counteach je hoeveel startgebeurtenissen er tot nu toe zijn gebeurd, en je kunt erachter komen hoeveel er tot nu toe zijn geëindigd door counteach af te trekken van countboth. Dus de volledige uitdrukking die aangeeft hoeveel intervallen actief zijn, is dan:
counteach - (countboth - counteach)
Voor eindgebeurtenissen vertelt counteach u hoeveel eindgebeurtenissen er tot nu toe zijn gebeurd, en u kunt erachter komen hoeveel er tot nu toe zijn begonnen door counteach af te trekken van countboth. Dus de volledige uitdrukking die aangeeft hoeveel intervallen actief zijn, is dan:
(countboth - counteach) - counteach
Met behulp van de volgende CASE-expressie berekent u de countactive-kolom op basis van het gebeurtenistype:
CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END In dezelfde stap filtert u alleen gebeurtenissen die het begin en einde van ingepakte intervallen vertegenwoordigen. Begin van gepakte intervallen hebben een type 's' en een countactive 1. Uiteinden van gepakte intervallen hebben een type 'e' en een countactive 0.
Na het filteren blijven er paren van begin-eindgebeurtenissen met ingepakte intervallen over, maar elk paar is opgesplitst in twee rijen:een voor het begingebeurtenis en een ander voor het eindgebeurtenis. Daarom berekent dezelfde stap de identificatie van het paar met behulp van rijnummers, met de formule (rownum – 1) / 2 + 1.
Hier is de code die deze stap implementeert:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
)
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0); Deze code genereert de volgende uitvoer:
serviceid eventtype logtime grp ----------- ---------- -------------------- ---- 1 s 2018-09-12 08:00:00 1 1 e 2018-09-12 08:04:06 1 1 s 2018-09-12 08:05:00 2 1 e 2018-09-12 08:07:08 2 2 s 2018-09-12 08:00:02 1 2 e 2018-09-12 08:07:07 1 3 s 2018-09-12 08:00:01 1 3 e 2018-09-12 08:01:07 1 3 s 2018-09-12 08:03:01 2 3 e 2018-09-12 08:05:08 2 3 s 2018-09-12 08:06:00 3 3 e 2018-09-12 08:07:06 3
De laatste stap draait de paren gebeurtenissen in een rij per interval en trekt de toegestane tussenruimte van de eindtijd af om de juiste gebeurtenistijd te regenereren. Hier is de code van de volledige oplossing:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
),
C3 AS
(
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0)
)
SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtime
FROM C3
PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P; Deze oplossing nam 43 seconden in beslag op mijn systeem en genereerde het plan dat wordt getoond in Afbeelding 3.
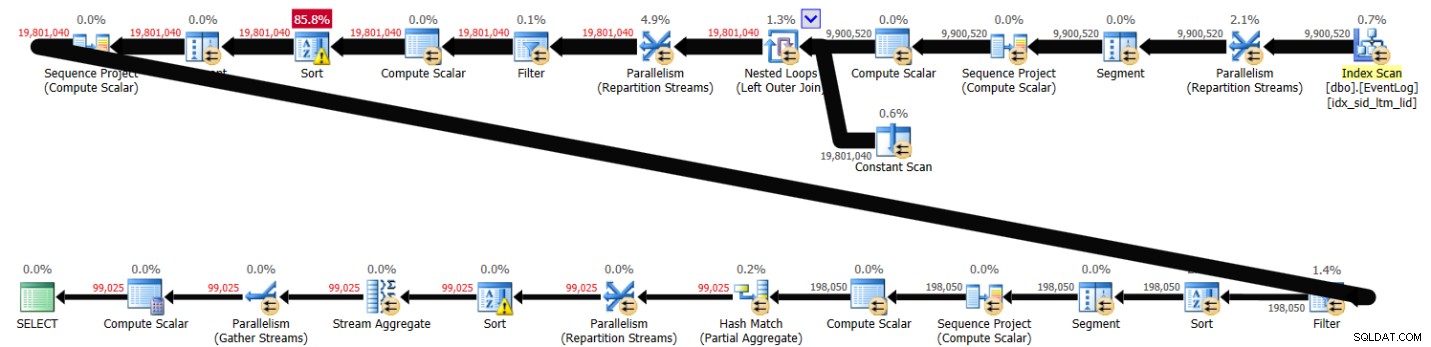 Figuur 3:Plan voor oplossing 2
Figuur 3:Plan voor oplossing 2
Zoals u kunt zien, wordt de berekening van het eerste rijnummer berekend op basis van indexvolgorde, maar de volgende twee omvatten expliciete sortering. Toch zijn de prestaties niet zo slecht, aangezien er ongeveer 10.000.000 rijen bij betrokken zijn.
Hoewel het punt van deze oplossing is om een pre-SQL Server 2012-omgeving te gebruiken, heb ik, gewoon voor de lol, de prestaties getest na het maken van een gefilterde columnstore-index om te zien hoe het werkt met batchverwerking ingeschakeld:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
Met batchverwerking ingeschakeld, duurde het 29 seconden voordat deze oplossing op mijn systeem was voltooid, waardoor het plan werd geproduceerd dat wordt weergegeven in Afbeelding 4.
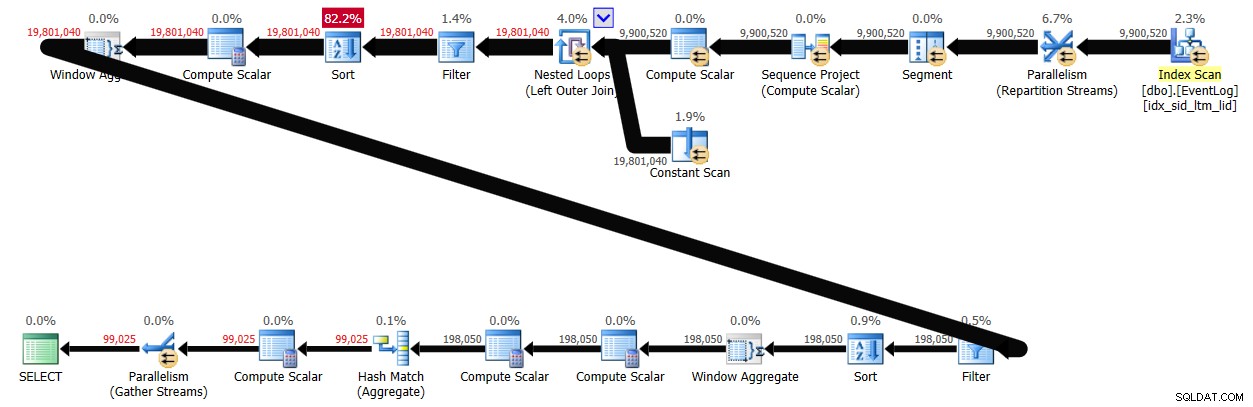
Conclusie
Het is normaal dat hoe beperkter uw omgeving is, hoe uitdagender het wordt om querytaken op te lossen. Adam's speciale Islands-uitdaging is veel gemakkelijker op te lossen op nieuwere versies van SQL Server dan op oudere. Maar dan dwing je jezelf om creatievere technieken te gebruiken. Dus als oefening, om je vraagvaardigheden te verbeteren, zou je uitdagingen kunnen aanpakken die je al kent, maar opzettelijk bepaalde beperkingen opleggen. Je weet nooit wat voor interessante ideeën je tegen kunt komen!