Om elke database efficiënt te laten werken, moet u inzicht hebben in de databaseprestaties. Dit is misschien niet duidelijk als alles goed gaat, maar zodra er iets misgaat, kan toegang tot informatie van groot belang zijn om het probleem snel en correct te diagnosticeren.
Alle databases stellen een deel van hun interne statusgegevens beschikbaar aan gebruikers. In MySQL kunt u deze gegevens meestal verkrijgen door 'SHOW STATUS' en 'SHOW GLOBAL STATUS' uit te voeren, door 'SHOW ENGINE INNODB STATUS' uit te voeren, informatieschematabellen te controleren en, in nieuwere versies, door prestatieschematabellen op te vragen.

Deze methoden zijn verre van handig in de dagelijkse bedrijfsvoering, vandaar de populariteit van verschillende monitoring- en trending-oplossingen. Tools zoals Nagios/Icinga zijn ontworpen om hosts/services te bekijken en te waarschuwen wanneer een service buiten een acceptabel bereik valt. Andere tools zoals Cacti en Munin bieden een grafische weergave van host-/service-informatie en geven historische context aan prestaties en gebruik. ClusterControl combineert deze twee soorten monitoring, dus we zullen kijken naar de informatie die het presenteert en hoe we deze moeten interpreteren.
Als u Galera Cluster (MySQL Galera Cluster by Codership of MariaDB Cluster of Percona XtraDB Cluster) gebruikt, is u wellicht de volgende sectie opgevallen op het tabblad "Overzicht" van ClusterControl:
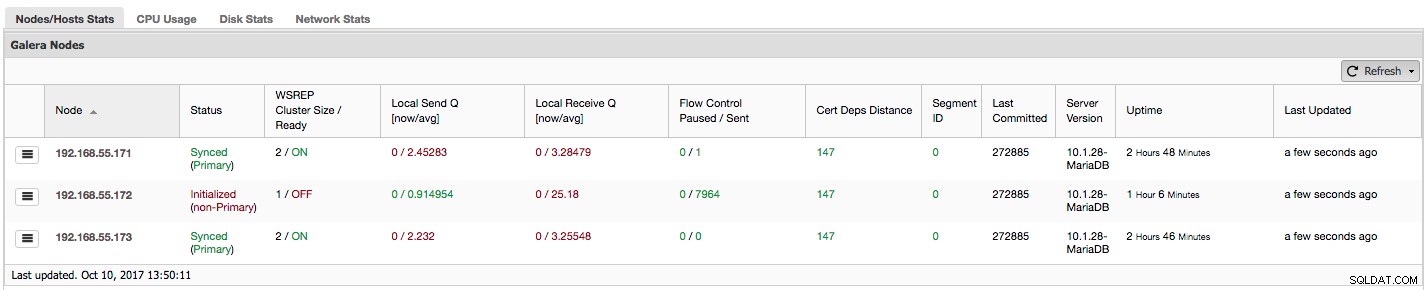
Laten we stap voor stap eens kijken wat voor soort gegevens we hier hebben.
De eerste kolom bevat de lijst met knooppunten met hun IP-adressen - meer valt er niet over te zeggen.
De tweede kolom is interessanter - deze beschrijft de knooppuntstatus (wsrep_local_state_comment toestand). Een knoop kan zich in verschillende toestanden bevinden:
- Geïnitialiseerd - Het knooppunt is actief, maar maakt geen deel uit van een cluster. Het kan bijvoorbeeld worden veroorzaakt door netwerkproblemen;
- Deelnemen - Het knooppunt is bezig met het toevoegen van het cluster en het ontvangt of vraagt een statusoverdracht van een van de andere knooppunten;
- Donor/Desynced - Het knooppunt dient als donor voor een ander knooppunt dat lid wordt van het cluster;
- Toegevoegd - Het knooppunt is lid geworden van het cluster, maar is bezig met het inhalen van vastgelegde schrijfsets;
- Gesynchroniseerd - Het knooppunt werkt normaal.
In dezelfde kolom tussen de haakjes staat de clusterstatus (wsrep_cluster_status toestand). Het kan drie verschillende toestanden hebben:
- Primair - De communicatie tussen knooppunten werkt en het quorum is aanwezig (de meeste knooppunten zijn beschikbaar)
- Niet-primair:het knooppunt maakte deel uit van het cluster, maar verloor om de een of andere reden het contact met de rest van het cluster. Als gevolg hiervan wordt dit knooppunt als inactief beschouwd en accepteert het geen zoekopdrachten
- Verbinding verbroken - Het knooppunt kon geen groepscommunicatie tot stand brengen.
"WSREP-clustergrootte / gereed" vertelt ons over een clustergrootte zoals het knooppunt deze ziet en of het knooppunt gereed is om query's te accepteren. Niet-primaire componenten maken een cluster met een grootte van 1 en de gereedheid voor wsrep is UIT.
Laten we eens kijken naar de bovenstaande schermafbeelding en kijken wat het ons vertelt over Galera. We kunnen drie knooppunten zien. Twee ervan (192.168.55.171 en 192.168.55.173) zijn prima in orde, ze zijn beide "gesynchroniseerd" en het cluster bevindt zich in de "primaire" staat. Het cluster bestaat momenteel uit twee knooppunten. Knooppunt 192.168.55.172 is "geïnitialiseerd" en vormt een "niet-primair" onderdeel. Dit betekent dat dit knooppunt de verbinding met het cluster heeft verloren - hoogstwaarschijnlijk een soort netwerkproblemen (we hebben in feite iptables gebruikt om verkeer naar dit knooppunt van zowel 192.168.55.171 als 192.168.55.173) te blokkeren).
Op dit moment moeten we even stilstaan en beschrijven hoe Galera Cluster intern werkt. We zullen niet te veel in detail treden omdat dit niet binnen het bestek van deze blogpost valt, maar er is enige kennis vereist om het belang van de gegevens in de volgende kolommen te begrijpen.
Galera is een "vrijwel" synchroon, multi-master cluster. Het betekent dat je mag verwachten dat gegevens "virtueel" tegelijkertijd over knooppunten worden overgedragen (geen vervelende problemen meer met achterblijvende slaves) en dat je naar elk knooppunt in een cluster kunt schrijven (geen vervelende problemen meer met het promoveren van een slave naar master ). Om dat te bereiken, gebruikt Galera schrijfsets - een atomaire reeks wijzigingen die in het cluster worden gerepliceerd. Een schrijfset kan verschillende rijwijzigingen en aanvullende benodigde informatie bevatten, zoals gegevens over vergrendeling.
Zodra een klant COMMIT uitgeeft, maar voordat MySQL daadwerkelijk iets vastlegt, wordt een schrijfset gemaakt en naar alle knooppunten in het cluster verzonden voor certificering. Alle knooppunten controleren of het mogelijk is om de wijzigingen vast te leggen of niet (omdat wijzigingen andere schrijfacties kunnen verstoren die in de tussentijd rechtstreeks op een ander knooppunt worden uitgevoerd). Zo ja, dan worden de gegevens daadwerkelijk vastgelegd door MySQL, zo niet, dan wordt een rollback uitgevoerd.
Wat belangrijk is om te onthouden, is het feit dat nodes, vergelijkbaar met slaves bij reguliere replicatie, anders kunnen presteren - sommige hebben betere hardware dan andere, sommige zijn meer belast dan andere. Toch vereist Galera dat ze de schrijfsets op een korte en snelle manier verwerken om "virtuele" synchronisatie te behouden. Er moet een mechanisme zijn dat de replicatie kan vertragen en ervoor kan zorgen dat langzamere nodes de rest van het cluster kunnen bijhouden.
Laten we eens kijken naar de kolommen "Local Send Q [now/avg]" en "Local Receive Q [now/avg]". Elk knooppunt heeft een lokale wachtrij voor het verzenden en ontvangen van schrijfsets. Het maakt het mogelijk om een deel van de schrijf- en wachtrijgegevens te parallelliseren die niet tegelijk kunnen worden verwerkt als het knooppunt het verkeer niet kan bijhouden. In SHOW GLOBAL STATUS kunnen we acht tellers vinden die beide wachtrijen beschrijven, vier tellers per wachtrij:
- wsrep_local_send_queue - huidige status van de verzendwachtrij
- wsrep_local_send_queue_min - minimum sinds FLUSH STATUS
- wsrep_local_send_queue_max - maximum sinds FLUSH STATUS
- wsrep_local_send_queue_avg - gemiddelde sinds FLUSH STATUS
- wsrep_local_recv_queue - huidige status van de ontvangstwachtrij
- wsrep_local_recv_queue_min - minimum sinds FLUSH STATUS
- wsrep_local_recv_queue_max - maximum sinds FLUSH STATUS
- wsrep_local_recv_queue_avg - gemiddelde sinds FLUSH STATUS
De bovenstaande statistieken zijn verenigd over knooppunten onder ClusterControl -> Prestaties -> DB-status:
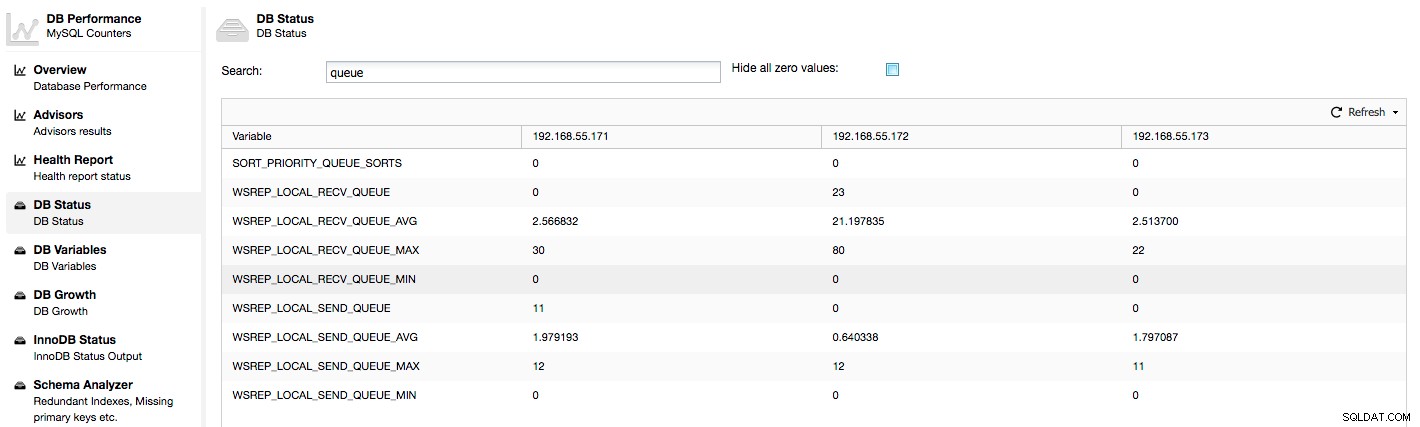
ClusterControl geeft "nu" en "gemiddelde" tellers weer, omdat deze het meest betekenisvol zijn als een enkel getal (u kunt ook aangepaste grafieken maken op basis van variabelen die de huidige status van de wachtrijen beschrijven). Als we zien dat een van de wachtrijen toeneemt, betekent dit dat de node de replicatie niet kan bijhouden en dat andere nodes moeten vertragen om de achterstand in te halen. We raden aan om een werklast van dat gegeven knooppunt te onderzoeken - controleer de proceslijst op een aantal langlopende query's, controleer OS-statistieken zoals CPU-gebruik en I/O-werklast. Misschien is het ook mogelijk om een deel van het verkeer van dat knooppunt naar de rest van het cluster te herverdelen.
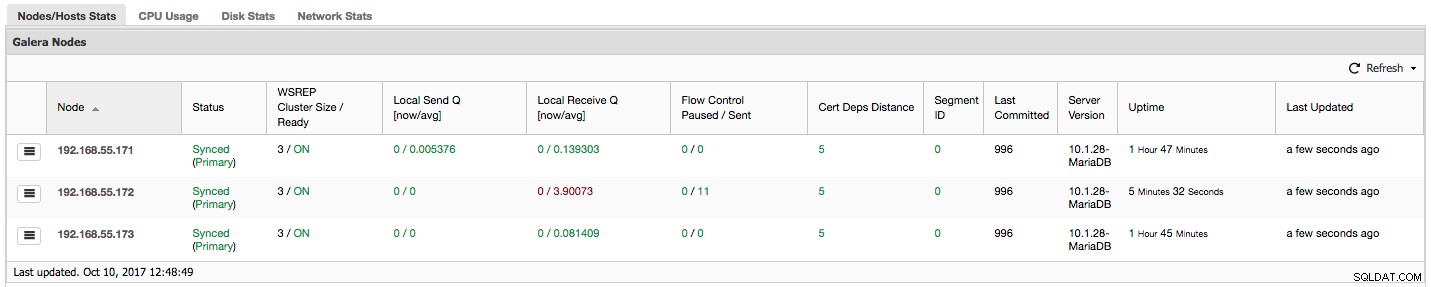
"Flow Control gepauzeerd" toont informatie over het percentage tijd dat een bepaald knooppunt de replicatie moest pauzeren vanwege een te zware belasting. Wanneer een knooppunt de werklast niet kan bijhouden, stuurt het Flow Control-pakketten naar andere knooppunten, met de mededeling dat ze het verzenden van schrijfsets moeten vertragen. In onze schermafbeelding hebben we de waarde '0.30' voor knooppunt 192.168.55.172. Dit betekent dat bijna 30% van de tijd dit knooppunt de replicatie moest pauzeren omdat het de certificeringssnelheid van de schrijfset niet bij kon houden die vereist was door andere knooppunten (of eenvoudiger, te veel schrijfacties raakten het!). Zoals we kunnen zien, wijst de "Local Receive Q [avg]" ons ook op dit feit.
De volgende kolom, "Flow Control verzonden" geeft ons informatie over hoeveel Flow Control-pakketten een bepaald knooppunt naar het cluster heeft verzonden. Nogmaals, we zien dat het knooppunt 192.168.55.172 is dat het cluster vertraagt.
Wat kunnen we met deze informatie? Meestal moeten we onderzoeken wat er aan de hand is in het langzame knooppunt. Controleer het CPU-gebruik, controleer de I/O-prestaties en netwerkstatistieken. Deze eerste stap helpt om te beoordelen met wat voor soort probleem we worden geconfronteerd.
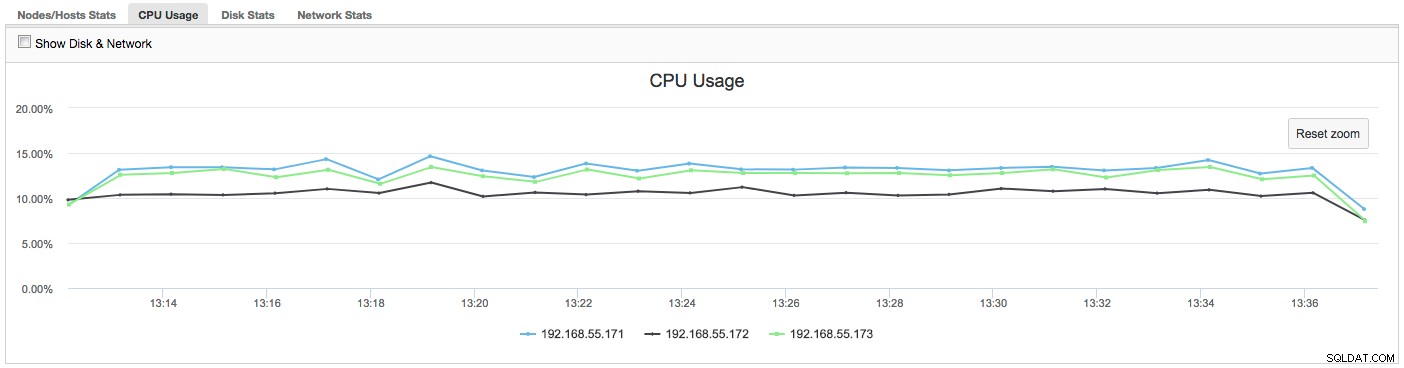
In dit geval, zodra we overschakelen naar het tabblad CPU-gebruik, wordt het duidelijk dat uitgebreid CPU-gebruik onze problemen veroorzaakt. De volgende stap zou zijn om de boosdoener te identificeren door te kijken naar PROCESSLIST (Query Monitor -> Query's uitvoeren -> filteren op 192.168.55.172) om te controleren op beledigende zoekopdrachten:
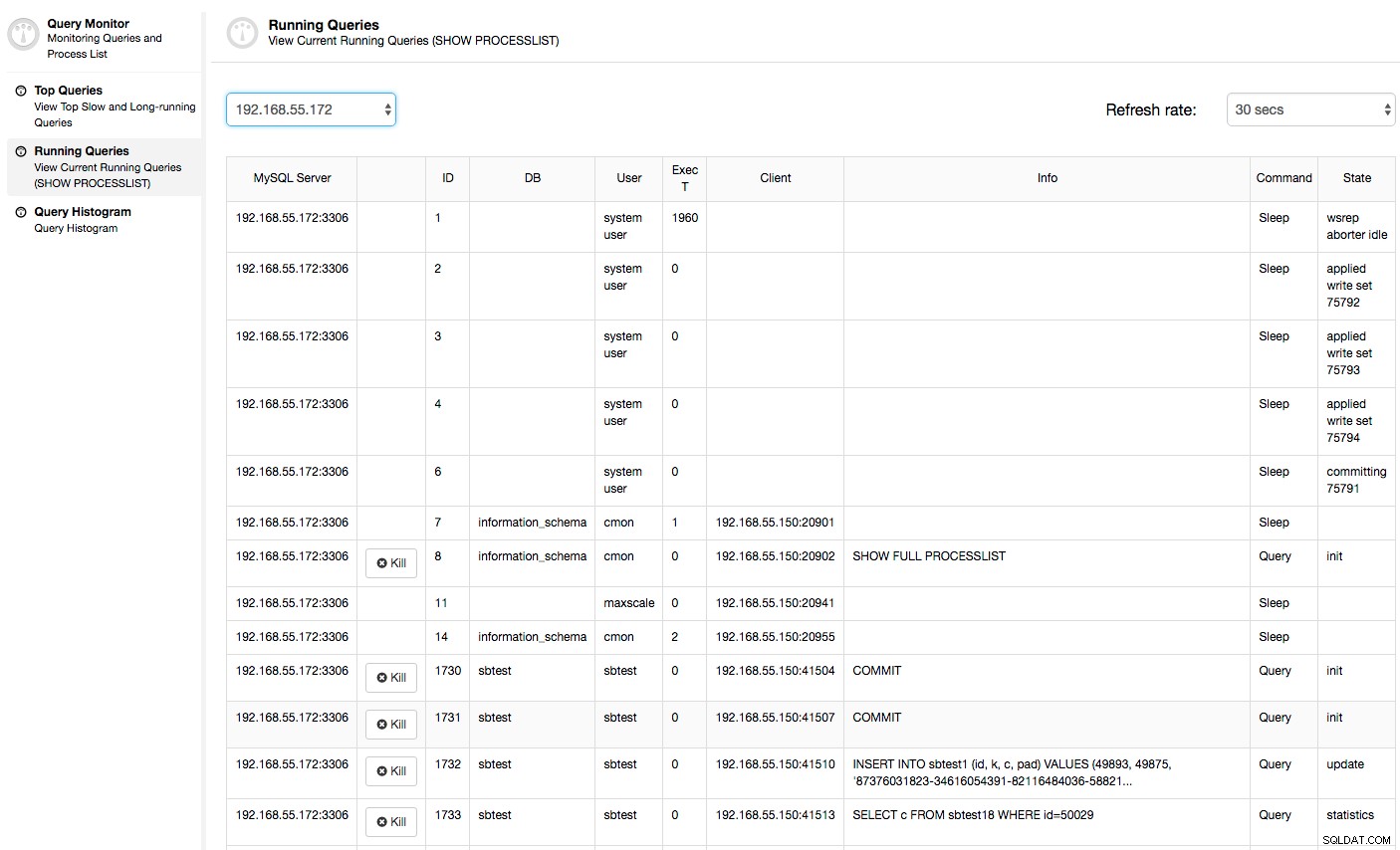
Of controleer de processen op het knooppunt vanaf de kant van het besturingssysteem (Nodes -> 192.168.55.172 -> Top) om te zien of de belasting niet wordt veroorzaakt door iets buiten Galera/MySQL.
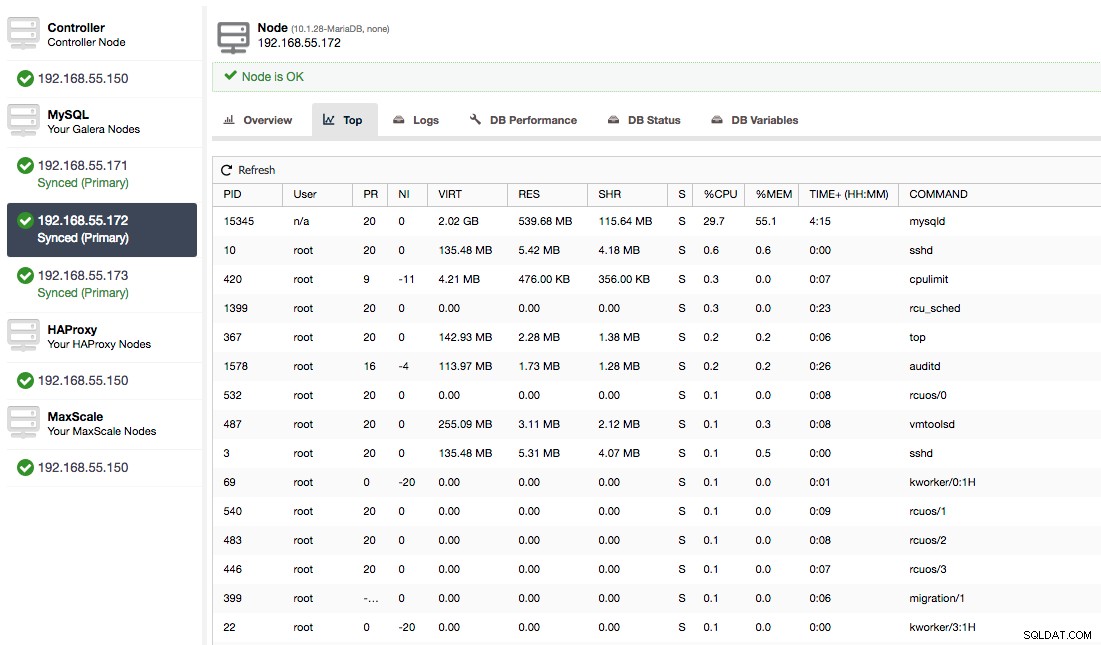
In dit geval hebben we het mysqld-commando uitgevoerd via cpulimit, om langzaam CPU-gebruik te simuleren, specifiek voor het mysqld-proces door het te beperken tot 30% van de 400% beschikbare CPU (de server heeft 4 cores).
De kolom "Cert Deps Distance" geeft ons informatie over hoeveel schrijfsets er gemiddeld parallel kunnen worden toegepast. Writesets kunnen soms tegelijkertijd worden uitgevoerd - Galera profiteert hiervan door meerdere wsrep_slave_threads te gebruiken schrijfsets toepassen. Deze kolom geeft je een idee hoeveel slave-threads je zou kunnen gebruiken voor je werklast. Het is vermeldenswaard dat het geen zin heeft om wsrep_slave_threads in te stellen variabele naar waarden die hoger zijn dan in deze kolom of in wsrep_cert_deps_distance statusvariabele, waarop de kolom "Cert Deps Distance" is gebaseerd. Nog een belangrijke opmerking - het heeft ook geen zin om wsrep_slave_threads in te stellen variabel tot meer dan het aantal cores dat uw CPU heeft.
"Segment-ID" - deze kolom vereist wat meer uitleg. Segmenten zijn een nieuwe functie die is toegevoegd in Galera 3.0. Voor deze versie werden schrijfsets uitgewisseld tussen alle nodes. Laten we zeggen dat we twee datacenters hebben:
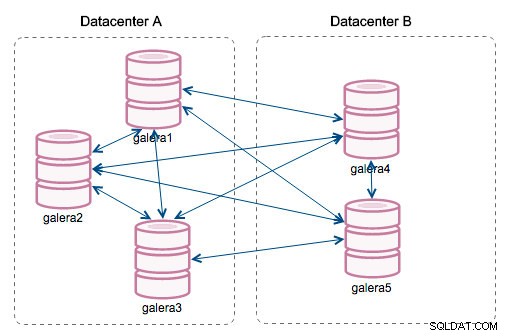
Dit soort chatter werkt prima op lokale netwerken, maar WAN is een ander verhaal - certificering vertraagt vanwege verhoogde latentie, extra kosten worden gegenereerd vanwege netwerkbandbreedte die wordt gebruikt voor het overbrengen van schrijfsets tussen elk lid van het cluster.
Met de introductie van "Segmenten" veranderde dat. U kunt een knooppunt aan een segment toewijzen door wsrep_provider_options aan te passen variabele en voeg er "gmcast.segment=x" (0, 1, 2) aan toe. Knooppunten met hetzelfde segmentnummer worden behandeld alsof ze zich in hetzelfde datacenter bevinden, verbonden via een lokaal netwerk. Onze grafiek wordt dan anders:
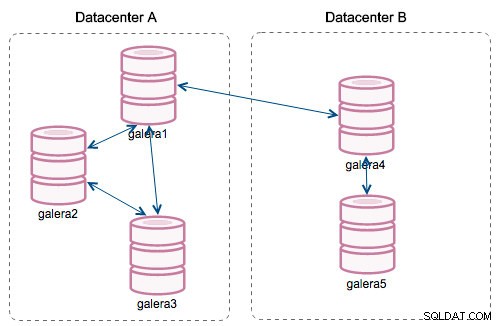
Het belangrijkste verschil is dat het niet meer iedereen tot iedereen communicatie is. Binnen elk segment, ja - het is nog steeds hetzelfde mechanisme, maar beide segmenten communiceren alleen via een enkele verbinding tussen twee gekozen knooppunten. In het geval van downtime zal deze verbinding automatisch een failover uitvoeren. Als gevolg hiervan krijgen we minder netwerkgebabbel en minder bandbreedtegebruik tussen externe datacenters. Dus eigenlijk vertelt de kolom "Segment-ID" ons aan welk segment een knooppunt is toegewezen.
De kolom "Laatst vastgelegd" geeft ons informatie over het volgnummer van de schrijfset die het laatst is uitgevoerd op een bepaald knooppunt. Het kan handig zijn om te bepalen welk knooppunt het meest actueel is als het cluster moet worden opgestart.
De rest van de kolommen spreekt voor zich:Serverversie, uptime van een node en wanneer de status is bijgewerkt.
Zoals u kunt zien, geeft de sectie "Galera Nodes" van de "Nodes/Hosts Stats" op het tabblad "Overview" u een redelijk goed begrip van de status van het cluster - of het nu een "Primary" component vormt, hoeveel nodes gezond zijn , zijn er prestatieproblemen met sommige knooppunten en zo ja, welk knooppunt vertraagt het cluster.
Deze gegevensset is erg handig wanneer u uw Galera-cluster bedient, dus hopelijk geen vliegende blinden meer :-)