
Voor de T-SQL Tuesday van deze maand vroeg Steve Jones (@way0utwest) ons om te praten over onze beste of slechtste triggerervaringen. Hoewel het waar is dat triggers vaak worden afgekeurd en zelfs gevreesd, hebben ze verschillende geldige gebruiksscenario's, waaronder:
- Auditing (vóór 2016 SP1, toen deze functie gratis werd in alle edities)
- Handhaving van bedrijfsregels en gegevensintegriteit, wanneer ze niet gemakkelijk binnen beperkingen kunnen worden geïmplementeerd en u niet wilt dat ze afhankelijk zijn van applicatiecode of de DML-query's zelf
- Het bijhouden van historische versies van gegevens (vóór het vastleggen van wijzigingsgegevens, het bijhouden van wijzigingen en tijdelijke tabellen)
- Wachtrijwaarschuwingen of asynchrone verwerking als reactie op een specifieke wijziging
- Wijzigingen aan weergaven toestaan (via INSTEAD OF triggers)
Dat is geen uitputtende lijst, maar een korte samenvatting van een paar scenario's die ik heb meegemaakt waarbij triggers op dat moment het juiste antwoord waren.
Wanneer triggers nodig zijn, vind ik het altijd leuk om het gebruik van IN PLAATS VAN triggers te onderzoeken in plaats van NA triggers. Ja, het is wat meer werk vooraf*, maar ze hebben een aantal behoorlijk belangrijke voordelen. In theorie lijkt het vooruitzicht om een actie te voorkomen (en de logge gevolgen ervan) in ieder geval een stuk efficiënter dan alles te laten gebeuren en het vervolgens ongedaan te maken.
*Ik zeg dit omdat je de DML-instructie opnieuw moet coderen binnen de trigger; daarom worden ze niet BEFORE-triggers genoemd. Het onderscheid is hier belangrijk, omdat sommige systemen echte BEFORE-triggers implementeren, die gewoon als eerste worden uitgevoerd. In SQL Server annuleert een INSTEAD OF-trigger effectief de instructie die ervoor zorgde dat deze werd geactiveerd.
Laten we doen alsof we een eenvoudige tabel hebben om accountnamen op te slaan. In dit voorbeeld maken we twee tabellen, zodat we twee verschillende triggers en hun impact op de duur van de query en het loggebruik kunnen vergelijken. Het concept is dat we een bedrijfsregel hebben:de accountnaam is niet aanwezig in een andere tabel, die "slechte" namen vertegenwoordigt, en de trigger wordt gebruikt om deze regel af te dwingen. Hier is de database:
USE [master];
GO
CREATE DATABASE [tr] ON (name = N'tr_dat', filename = N'C:\temp\tr.mdf', size = 4096MB)
LOG ON (name = N'tr_log', filename = N'C:\temp\tr.ldf', size = 2048MB);
GO
ALTER DATABASE [tr] SET RECOVERY FULL;
GO En de tafels:
USE [tr]; GO CREATE TABLE dbo.Accounts_After ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.Accounts_Instead ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.InvalidNames ( name sysname PRIMARY KEY ); INSERT dbo.InvalidNames(name) VALUES (N'poop'),(N'hitler'),(N'boobies'),(N'cocaine');
En tot slot de triggers. Voor de eenvoud hebben we alleen te maken met invoegingen, en in zowel het na- als het in plaats van geval gaan we de hele batch afbreken als een enkele naam onze regel schendt:
CREATE TRIGGER dbo.tr_Accounts_After
ON dbo.Accounts_After
AFTER INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
ROLLBACK TRANSACTION;
RETURN;
END
END
GO
CREATE TRIGGER dbo.tr_Accounts_Instead
ON dbo.Accounts_After
INSTEAD OF INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
RETURN;
END
ELSE
BEGIN
INSERT dbo.Accounts_Instead(AccountID, name, filler)
SELECT AccountID, name, filler FROM inserted;
END
END
GO Om de prestaties te testen, proberen we gewoon 100.000 namen in elke tabel in te voegen, met een voorspelbaar foutpercentage van 10%. Met andere woorden, 90.000 zijn goede namen, de andere 10.000 slagen niet voor de test en zorgen ervoor dat de trigger al dan niet wordt teruggedraaid, afhankelijk van de batch.
Eerst moeten we voor elke batch wat opruimen:
TRUNCATE TABLE dbo.Accounts_Instead; TRUNCATE TABLE dbo.Accounts_After; GO CHECKPOINT; CHECKPOINT; BACKUP LOG triggers TO DISK = N'C:\temp\tr.trn' WITH INIT, COMPRESSION; GO
Voordat we met het vlees van elke batch beginnen, tellen we de rijen in het transactielogboek en meten we de grootte en vrije ruimte. Vervolgens gaan we door een cursor om de 100.000 rijen in willekeurige volgorde te verwerken, waarbij we proberen elke naam in de juiste tabel in te voegen. Als we klaar zijn, meten we het aantal rijen en de grootte van het logboek opnieuw en controleren we de duur.
SET NOCOUNT ON;
DECLARE @batch varchar(10) = 'After', -- or After
@d datetime2(7) = SYSUTCDATETIME(),
@n nvarchar(129),
@i int,
@err nvarchar(512);
-- measure before and again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CONVERT(int, FILEPROPERTY(name,N'SpaceUsed')))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR
SELECT name, i = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM
(
SELECT DISTINCT TOP (90000) LEFT(o.name,64) + '/' + LEFT(c.name,63)
FROM sys.all_objects AS o
CROSS JOIN sys.all_columns AS c
UNION ALL
SELECT TOP (10000) N'boobies' FROM sys.all_columns
) AS x (name)
ORDER BY i;
OPEN c;
FETCH NEXT FROM c INTO @n, @i;
WHILE @@FETCH_STATUS = 0
BEGIN
BEGIN TRY
IF @batch = 'After'
INSERT dbo.Accounts_After(AccountID,name) VALUES(@i,@n);
IF @batch = 'Instead'
INSERT dbo.Accounts_Instead(AccountID,name) VALUES(@i,@n);
END TRY
BEGIN CATCH
SET @err = ERROR_MESSAGE();
END CATCH
FETCH NEXT FROM c INTO @n, @i;
END
-- measure again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT duration = DATEDIFF(MILLISECOND, @d, SYSUTCDATETIME()),
CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CAST(FILEPROPERTY(name,N'SpaceUsed') AS int))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
CLOSE c; DEALLOCATE c; Resultaten (gemiddeld over 5 runs van elke batch):
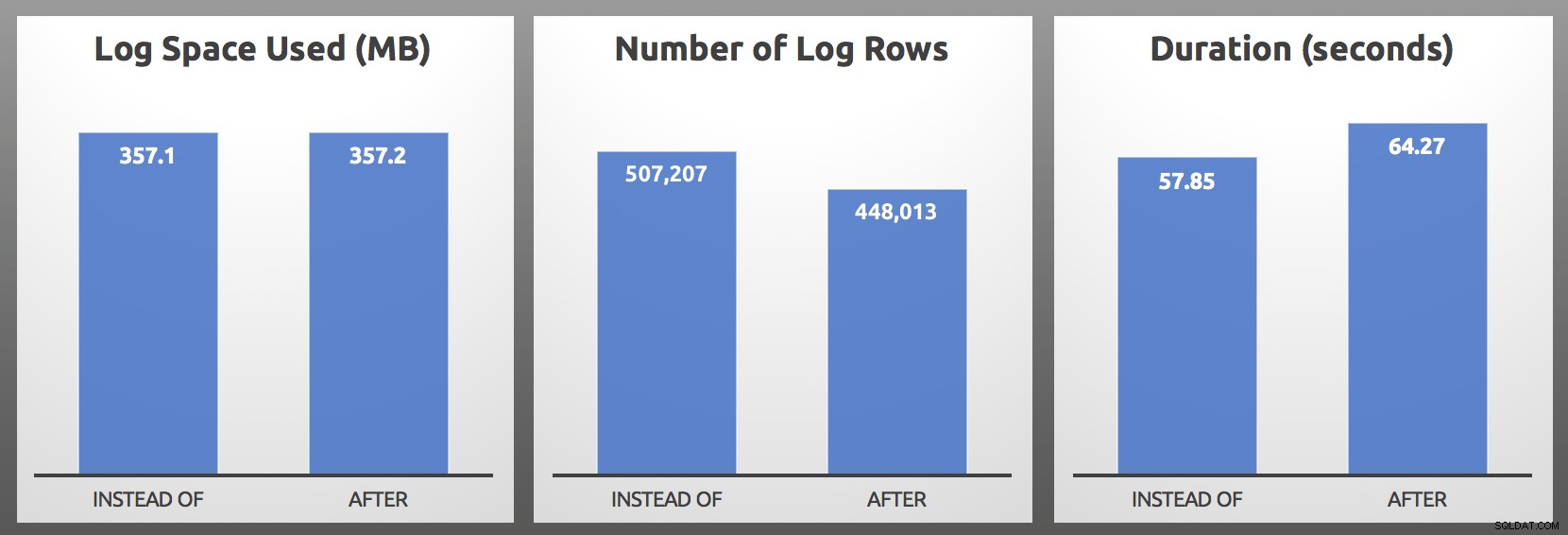 NA vs. IN PLAATS VAN:Resultaten
NA vs. IN PLAATS VAN:Resultaten
In mijn tests was het loggebruik bijna identiek in grootte, met meer dan 10% meer logrijen gegenereerd door de INSTEAD OF-trigger. Ik heb wat gegraven aan het einde van elke batch:
SELECT [Operation], COUNT(*) FROM sys.fn_dblog(NULL, NULL) GROUP BY [Operation] ORDER BY [Operation];
En hier was een typisch resultaat (ik heb de grote delta's gemarkeerd):
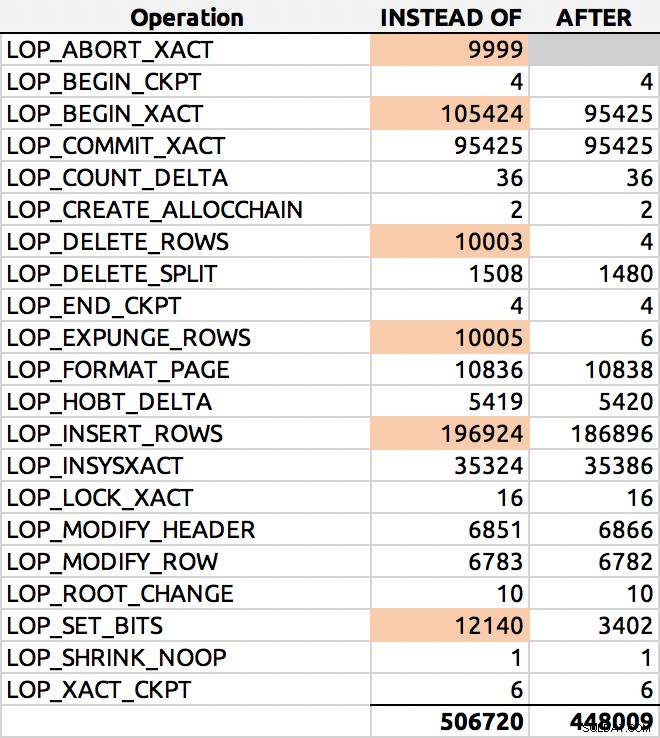 Verdeling van logboekrij
Verdeling van logboekrij
Ik zal daar een andere keer dieper op ingaan.
Maar als je er helemaal voor gaat...
...de belangrijkste statistiek is bijna altijd duur , en in mijn geval presteerde de INSTEAD OF-trigger minstens 5 seconden sneller in elke afzonderlijke head-to-head-test. Voor het geval dit allemaal bekend klinkt, ja, ik heb er al eerder over gesproken, maar toen zag ik dezelfde symptomen niet met de logrijen.
Houd er rekening mee dat dit misschien niet uw exacte schema of werklast is, dat u mogelijk heel andere hardware heeft, dat uw gelijktijdigheid hoger kan zijn en dat uw uitvalpercentage veel hoger (of lager) kan zijn. Mijn tests werden uitgevoerd op een geïsoleerde machine met veel geheugen en zeer snelle PCIe SSD's. Als uw logboek op een langzamere schijf staat, kunnen de verschillen in logboekgebruik opwegen tegen de andere statistieken en de duur aanzienlijk wijzigen. Al deze factoren (en meer!) kunnen uw resultaten beïnvloeden, dus u moet testen in uw omgeving.
Het punt is echter dat IN PLAATS VAN triggers een betere pasvorm zou kunnen zijn. Als we nu maar IN PLAATS VAN DDL-triggers konden krijgen...