We hebben onlangs een nieuwe ondersteuningssite gelanceerd, waar u vragen kunt stellen, productfeedback of functieverzoeken kunt indienen of ondersteuningstickets kunt openen. Een deel van het doel was om alle plaatsen waar we hulp aan de gemeenschap boden, te centraliseren. Dit omvatte de Q&A-site SQLPerformance.com, waar Paul White, Hugo Kornelis en vele anderen hebben geholpen bij het oplossen van uw meest gecompliceerde vragen over het afstemmen van zoekopdrachten en uitvoeringsplannen, helemaal terug tot februari 2013. Ik vertel u met gemengde gevoelens dat de Q&A-site is gesloten.
Er is echter een voordeel. Je kunt die lastige vragen nu stellen op het nieuwe ondersteuningsforum. Als je op zoek bent naar de oude inhoud, wel, die is er nog steeds, maar het ziet er een beetje anders uit. Om verschillende redenen waar ik vandaag niet op in zal gaan, hebben we, toen we besloten om de originele Q&A-site te beëindigen, uiteindelijk besloten om alle bestaande inhoud eenvoudigweg op een alleen-lezen WordPress-site te hosten, in plaats van deze naar de back-end te migreren van de nieuwe site.
Dit bericht gaat niet over de redenen achter die beslissing.
Ik voelde me erg slecht over hoe snel de antwoordensite offline moest gaan, de DNS overschakelde en de inhoud werd gemigreerd. Omdat er een waarschuwingsbanner op de site was geïmplementeerd, maar AnswerHub deze niet echt zichtbaar maakte, was dit een schok voor veel gebruikers. Dus ik wilde ervoor zorgen dat ik zoveel mogelijk van de inhoud goed bewaarde, en ik wilde dat het goed was. Dit bericht is hier omdat ik dacht dat het interessant zou zijn om te praten over het eigenlijke proces, hoeveel verschillende stukjes technologie erbij betrokken waren om het voor elkaar te krijgen, en om te pronken met het resultaat. Ik verwacht niet dat iemand van jullie hier profijt van heeft, aangezien dit een relatief obscuur migratiepad is, maar meer als een voorbeeld van het samenbinden van een heleboel technologieën om een taak te volbrengen. Het dient ook als een goede herinnering voor mezelf dat veel dingen niet zo eenvoudig zijn als ze klinken voordat je begint.
De TL;DR is dit:ik heb veel tijd en moeite gestoken om de gearchiveerde inhoud er goed uit te laten zien, hoewel ik nog steeds probeer de laatste paar berichten te herstellen die tegen het einde zijn binnengekomen. Ik heb deze technologieën gebruikt:
- Perl
- SQL-server
- PowerShell
- Verzenden (FTP)
- HTML
- CSS
- C#
- MarkdownSharp
- phpMyAdmin
- MySQL
Vandaar de titel. Als je een groot deel van de bloederige details wilt, hier zijn ze. Als je vragen of feedback hebt, neem dan contact met ons op of reageer hieronder.
AnswerHub heeft een dumpbestand van 665 MB geleverd uit de MySQL-database die de Q&A-inhoud heeft gehost. Elke editor die ik probeerde, verslikte zich erin, dus ik moest het eerst opdelen in een bestand per tabel met dit handige Perl-script van Jared Cheney. De tabellen die ik nodig had, heetten network11_nodes (vragen, antwoorden en opmerkingen), network11_authoritables (gebruikers), en network11_managed_files (alle bijlagen, inclusief uploads van abonnementen):perl extract_sql.pl -t network11_nodes -r dump.sql>> nodes.sql
perl extract_sql.pl -t network11_authoritables -r dump.sql>> users.sql
perl extract_sql.pl -t network11_managed_files -r dump.sql>> files.sql
Nu waren die niet extreem snel te laden in SSMS, maar daar kon ik tenminste Ctrl gebruiken +H om (bijvoorbeeld) dit te wijzigen:
CREATE TABLE `network11_managed_files` ( `c_id` bigint(20) NOT NULL, ... ); INSERT INTO `network11_managed_files` (`c_id`, ...) VALUES (1, ...);
Hierop:
CREATE TABLE dbo.files ( c_id bigint NOT NULL, ... ); INSERT dbo.files (c_id, ...) VALUES (1, ...);
Dan kon ik de gegevens in SQL Server laden, zodat ik het kon manipuleren. En geloof me, ik heb het gemanipuleerd.
Vervolgens moest ik alle bijlagen ophalen. Kijk, het MySQL-dumpbestand dat ik van de leverancier kreeg, bevatte een ontelbaar aantal INSERT verklaringen, maar geen van de daadwerkelijke planbestanden die gebruikers hadden geüpload - de database had alleen de relatieve paden naar de bestanden. Ik heb T-SQL gebruikt om een reeks PowerShell-opdrachten te bouwen die Invoke-WebRequest zouden aanroepen om alle bestanden op te halen en ze lokaal op te slaan (veel manieren om deze kat te villen, maar dit was doodeenvoudig). Hieruit:
SELECT 'Invoke-WebRequest -Uri ' + '"$($url)' + RTRIM(c_id) + '-' + c_name + '"' + ' -OutFile "E:\s\temp\' + RTRIM(c_id) + '-' + c_name + '";' FROM dbo.files WHERE LOWER(c_mime_type) LIKE 'application/%';
Dat leverde deze reeks opdrachten op (samen met een pre-opdracht om dit TLS-probleem op te lossen); het hele ding liep vrij snel, maar ik raad deze aanpak niet aan voor een combinatie van {massive set of files} en/of {low bandbreedte}:
$AllProtocols = [System.Net.SecurityProtocolType]'Ssl3,Tls,Tls11,Tls12'; [System.Net.ServicePointManager]::SecurityProtocol = $AllProtocols; $u = "https://answers.sqlperformance.com/s/temp/"; Invoke-WebRequest -Uri "$($u)/1-proc.pesession" -OutFile "E:\s\temp\1-proc.pesession"; Invoke-WebRequest -Uri "$($u)/14-test.pesession" -OutFile "E:\s\temp\14-test.pesession"; Invoke-WebRequest -Uri "$($u)/15-a.QueryAnalysis" -OutFile "E:\s\temp\15-a.QueryAnalysis"; ...
Hiermee werden bijna alle bijlagen gedownload, maar toegegeven, sommige werden gemist vanwege fouten op de oude site toen ze voor het eerst werden geüpload. Op de nieuwe site ziet u dus af en toe een verwijzing naar een bijlage die niet bestaat.
Daarna gebruikte ik Panic Transmit 5 om de temp . te uploaden map naar de nieuwe site, en nu wanneer de inhoud wordt geüpload, links naar /s/temp/1-proc.pesession zal blijven werken.
Vervolgens ben ik overgestapt op SSL. Om een certificaat op de nieuwe WordPress-site aan te vragen, moesten we de DNS voor answer.sqlperformance.com bijwerken om naar de CNAME te wijzen op onze WordPress-host, WPEngine. Het was hier een soort kip en ei - we hadden wat downtime voor https-URL's, wat zou mislukken zonder certificaat op de nieuwe site. Dit was oké omdat het certificaat op de oude site was verlopen, dus echt, we waren niet slechter af. Ik moest ook wachten om dit te doen totdat ik alle bestanden van de oude site had gedownload, want als DNS eenmaal was omgedraaid, was er geen manier om ze te bereiken, behalve via een achterdeur.
Terwijl ik wachtte tot DNS zich verspreidde, begon ik aan de logica te werken om alle vragen, antwoorden en opmerkingen in iets verbruiksartikelen in WordPress te verwerken. Niet alleen waren de tabelschema's anders dan die van WordPress, de soorten entiteiten zijn ook behoorlijk verschillend. Mijn visie was om elke vraag - en alle antwoorden en/of opmerkingen - te combineren in een enkele post.
Het lastige is dat de tabel met knooppunten alle drie de inhoudstypen in dezelfde tabel bevat, met ouderlijke en originele ("master") bovenliggende verwijzingen. Hun front-endcode gebruikt waarschijnlijk een soort cursor om door de inhoud te bladeren en deze in een hiërarchische en chronologische volgorde weer te geven. Ik zou die luxe niet hebben in WordPress, dus ik moest de HTML in één keer aan elkaar rijgen. Als voorbeeld, hier is hoe de gegevens eruit zagen:
SELECT c_type, c_id, c_parent, oParent = c_originalParent, c_creation_date, c_title FROM dbo.nodes WHERE c_originalParent = 285; /* c_type c_id c_parent oParent c_creation_date accepted c_title ---------- ------ -------- ------- ---------------- -------- ------------------------- question 285 NULL 285 2013-02-13 16:30 why is the MERGE JOIN ... answer 287 285 285 2013-02-14 01:15 1 NULL comment 289 285 285 2013-02-14 13:35 NULL answer 293 285 285 2013-02-14 18:22 NULL comment 294 287 285 2013-02-14 18:29 NULL comment 298 285 285 2013-02-14 20:40 NULL comment 299 298 285 2013-02-14 18:29 NULL */
Ik kon niet bestellen op id, of type, of op ouder, omdat soms een opmerking later op een eerder antwoord kwam, het eerste antwoord niet altijd het geaccepteerde antwoord zou zijn, enzovoort. Ik wilde deze uitvoer (waar ++ staat voor één inspringingsniveau):
/* c_type c_id c_parent oParent c_creation_date reason ---------- ------ -------- ------- ---------------- ------------------------- question 285 NULL 285 2013-02-13 16:30 question is ALWAYS first ++comment 289 285 285 2013-02-14 13:35 comments on the question before answers answer 287 285 285 2013-02-14 01:15 first answer (accepted = 1) ++comment 294 287 285 2013-02-14 18:29 first comment on first answer ++comment 298 287 285 2013-02-14 20:40 second comment on first answer ++++comment 299 298 285 2013-02-14 18:29 reply to second comment on first answer answer 293 285 285 2013-02-14 18:22 second answer */
Ik begon een recursieve CTE te schrijven en,
DECLARE @foo TABLE
(
c_type varchar(255),
c_id int,
c_parent int,
oParent int,
accepted bit
);
INSERT @foo(c_type, c_id, c_parent, oParent, accepted) VALUES
('question', 285, NULL, 285, 0),
('answer', 287, 285 , 285, 1),
('comment', 289, 285 , 285, 0),
('comment', 294, 287 , 285, 0),
('comment', 298, 287 , 285, 0),
('comment', 299, 298 , 285, 0),
('answer', 293, 285 , 285, 0);
;WITH cte AS
(
SELECT
lvl = 0,
f.c_type,
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f WHERE f.c_parent IS NULL
UNION ALL
SELECT
lvl = c.lvl + 1,
c_type = CONVERT(varchar(255), CASE
WHEN f.accepted = 1 THEN 'accepted answer'
WHEN f.c_type = 'comment' THEN c.c_type + ' ' + f.c_type
ELSE f.c_type
END),
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),c.Sort + RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f INNER JOIN cte AS c ON c.c_id = f.c_parent
)
SELECT lvl = CASE lvl WHEN 0 THEN 1 ELSE lvl END, c_type, c_id, c_parent, oParent, Sort
FROM cte
ORDER BY
oParent,
CASE
WHEN c_type LIKE 'question%' THEN 1 -- it's a question *or* a comment on the question
WHEN c_type LIKE 'accepted answer%' THEN 2 -- accepted answer *or* comment on accepted answer
ELSE 3 END,
Sort; Resultaten:
/* lvl c_type c_id c_parent oParent Sort ---- --------------------------------- ----------- ----------- ----------- -------------------- 1 question 285 NULL 285 00285 1 question comment 289 285 285 0028500289 1 accepted answer 287 285 285 0028500287 2 accepted answer comment 294 287 285 002850028700294 2 accepted answer comment 298 287 285 002850028700298 3 accepted answer comment comment 299 298 285 00285002870029800299 1 answer 293 285 285 0028500293 */
Genie. Ik zag een tiental anderen gecontroleerd en was blij dat ik door kon naar de volgende stap. Ik heb Andy verschillende keren uitgebreid bedankt, maar laat me het nog een keer doen:Bedankt Andy!
Nu ik de hele set in de gewenste volgorde kon retourneren, moest ik wat manipulatie van de uitvoer uitvoeren om HTML-elementen en klassenamen toe te passen waarmee ik vragen, antwoorden, opmerkingen en inspringingen op een zinvolle manier kon markeren. Het einddoel was een uitvoer die er als volgt uitzag (en onthoud, dit is een van de eenvoudigere gevallen):
<div class="question">
<span class="authorq" title=" Author : author name ">
<i class="fas fa-user"></i>Author name</span>
<span class="createdq" title=" February 13th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-13 16:30:36</span>
<div class=mainbodyq>I don't understand why the merge operator is passing over 4million
rows to the hash match operator when there is only 41K and 19K from other operators.
<div class=attach><i class="fas fa-file"></i>
<a target="_blank" href="/s/temp/254-tmp4DA0.queryanalysis" rel="noopener noreferrer">
/s/temp/254-tmp4DA0.queryanalysis</a>
</div>
</div>
<div class="comment indent1 ">
<div class=linecomment>
<span class="authorc" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createdc" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 13:35:39</span>
</div>
<div class=mainbodyc>
I am still trying to understand the significant amount of rows from the MERGE operator.
Unless it's a result of a Cartesian product from the two inputs then finally the WHERE
predicate is applied to filter out the unmatched rows leaving the 4 million row count.
</div>
</div>
<div class="answer indent1 [accepted]">
<div class=lineanswer>
<span class="authora" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createda" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 01:15:42</span>
</div>
<div class=mainbodya>
The reason for the large number of rows can be seen in the Plan Explorer tool tip for
the Merge Join operator:
<img src="/s/temp/259-sp.png" alt="Merge Join tool tip" />
...
</div>
</div>
</div>
Ik zal niet door het belachelijke aantal iteraties gaan dat ik moest doorlopen om op een betrouwbare vorm van die uitvoer te komen voor alle 5.000+ items (wat zich vertaalde in bijna 1.000 berichten zodra alles aan elkaar was gelijmd). Bovendien moest ik deze genereren in de vorm van INSERT uitspraken die ik vervolgens in phpMyAdmin op de WordPress-site kon plakken, wat betekende dat ik me aan hun bizarre syntaxisdiagram moest houden. Die verklaringen moesten andere aanvullende informatie bevatten die door WordPress wordt vereist, maar die niet aanwezig of nauwkeurig is in de brongegevens (zoals post_type ). En die beheerdersconsole zou een time-out krijgen als er te veel gegevens zijn, dus ik moest het opsplitsen in ~ 750 inserts per keer. Hier is de procedure waarmee ik eindigde (dit is niet echt om iets specifieks van te leren, alleen een demonstratie van hoeveel manipulatie van de geïmporteerde gegevens nodig was):
CREATE /* OR ALTER */ PROCEDURE dbo.BuildMySQLInserts
@LowerBound int = 1,
@UpperBound int = 750
AS
BEGIN
SET NOCOUNT ON;
;WITH CTE AS
(
SELECT lvl = 0,
[type] = CONVERT(varchar(100),f.[type]),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
WHERE f.type = 'question'
AND master_parent BETWEEN @LowerBound AND @UpperBound
UNION ALL
SELECT lvl = c.lvl + 1,
CONVERT(varchar(100),CASE
WHEN f.[state] = '[accepted]' THEN 'accepted answer'
WHEN f.type = 'comment' THEN c.type + ' ' + f.type
ELSE f.type
END),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),c.sort + RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
JOIN CTE AS c ON c.id = f.parent
)
SELECT
master_parent,
prefix = CASE WHEN lvl = 0 THEN
CONVERT(varchar(11), master_parent) + ', 3, ''' + created + ''', '''
+ created + ''',''' END,
bodypre = '<div class="' + COALESCE(c_type, RTRIM(LEFT([type],8)))
+ CASE WHEN c_type <> 'question' THEN ' indent' + RTRIM(lvl)
+ COALESCE(' ' + [state], '') ELSE '' END + '">'
+ CASE WHEN c_type <> 'question' THEN
'<div class=line' + c_type + '>' ELSE '' END
+ '<span class="author' + LEFT(c_type, 1) + '" title=" Author : '
+ REPLACE(REPLACE(Fullname,'''','\'''),'"','')
+ ' "><i class="fas fa-user"></i>' + REPLACE(Fullname,'''','\''') --"
+ '</span> <span class="created' + LEFT(c_type,1) + '" title=" '
+ DATENAME(MONTH, c_creation_date) + ' ' + RTRIM(DAY(c_creation_date))
+ CASE
WHEN DAY(c_creation_date) IN (1,21,31) THEN 'st'
WHEN DAY(c_creation_date) IN (2,22) THEN 'nd'
WHEN DAY(c_creation_date) IN (3,23) THEN 'rd' ELSE 'th' END
+ ', ' + RTRIM(YEAR(c_creation_date))
+ ' "><i class="fas fa-calendar-alt"></i>' + created + '</span>'
+ CASE WHEN c_type <> 'question' THEN '</div>' ELSE '' END,
body = '<div class=mainbody' + left(c_type,1) + '>'
+ REPLACE(REPLACE(c_body, char(39), '\' + char(39)), '’', '\' + char(39)),
bodypost = COALESCE(urls, '') + '</div></div>',--'
+ CASE WHEN c_type = 'question' THEN '</div>' ELSE '' END,
suffix = ''',''' + REPLACE(n.c_title, '''', '\''') + ''','''',''publish'',
''closed'',''closed'','''',''' + REPLACE(n.c_plug, '''', '\''')
+ ''','''','''',''' + created + ''',''' + created + ''','''',0,
''https://answers.sqlperformance.com/?p=' + CONVERT(varchar(11), master_parent)
+ ''', 0, ''post'','''',0);',
rn = RTRIM(ROW_NUMBER() OVER (PARTITION BY master_parent
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort)),
c = RTRIM(COUNT(*) OVER (PARTITION BY master_parent))
FROM CTE
LEFT OUTER JOIN dbo.network11_nodes AS n
ON cte.id = n.c_id
LEFT OUTER JOIN dbo.Users AS u
ON n.c_author = u.UserID
LEFT OUTER JOIN
(
SELECT NodeID, urls = STRING_AGG('<div class=attach>
<i class="fas fa-file'
+ CASE WHEN c_mime_type IN ('image/jpeg','image/png')
THEN '-image' ELSE '' END
+ '"></i><a target="_blank" href=' + url + ' rel="noopener noreferrer">' + url + '</a></div>', '\n')
FROM dbo.Attachments
GROUP BY NodeID
) AS a
ON n.c_id = a.NodeID
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort;
END
GO De uitvoer daarvan is nog niet compleet en nog niet klaar om in WordPress te vullen:
 Voorbeelduitvoer (klik om te vergroten)
Voorbeelduitvoer (klik om te vergroten)
Ik zou wat extra hulp van C# nodig hebben om de daadwerkelijke inhoud (inclusief markdown) om te zetten in HTML en CSS die ik beter zou kunnen beheersen, en om de uitvoer te schrijven (een heleboel INSERT uitspraken die toevallig een heleboel HTML-code bevatten) naar bestanden op de schijf die ik kon openen en in phpMyAdmin plakken. Voor de HTML, platte tekst + markdown die als volgt begon:
SELECTEER iets uit dbo.sometable;
[1]:https://elders
Zou dit moeten worden:
Er is een blogpost hier die erover praat, en ook dit bericht .
SELECTEER iets uit dbo.sometable; Om dit voor elkaar te krijgen, heb ik de hulp ingeroepen van MarkdownSharp, een open source-bibliotheek van Stack Overflow die een groot deel van de markdown-naar-HTML-conversie afhandelt. Het paste goed bij mijn behoeften, maar niet perfect; Ik zou nog steeds verdere manipulatie moeten uitvoeren:
- MarkdownSharp staat geen dingen toe zoals
target=_blank, dus die zou ik na verwerking zelf moeten injecteren; - code (alles voorafgegaan door vier spaties) erft
using System.Text; using System.Data; using System.Data.SqlClient; using MarkdownSharp; using System.IO; namespace AnswerHubMigrator { class Program { static void Main(string[] args) { StringBuilder output; string suffix = ""; string thisfile = ""; // pass two arguments on the command line, e.g. 1, 750 int LowerBound = int.Parse(args[0]); int UpperBound = int.Parse(args[1]); // auto-expand URLs, and only accept bold/italic markdown // when it completely surrounds an entire word var options = new MarkdownOptions { AutoHyperlink = true, StrictBoldItalic = true }; MarkdownSharp.Markdown mark = new MarkdownSharp.Markdown(options); using (var conn = new SqlConnection("Server=.\\SQL2017;Integrated Security=true")) using (var cmd = new SqlCommand("MigrateDB.dbo.BuildMySQLInserts", conn)) { cmd.CommandType = CommandType.StoredProcedure; cmd.Parameters.Add("@LowerBound", SqlDbType.Int).Value = LowerBound; cmd.Parameters.Add("@UpperBound", SqlDbType.Int).Value = UpperBound; conn.Open(); using (var reader = cmd.ExecuteReader()) { // use a StringBuilder to dump output to a file output = new StringBuilder(); while (reader.Read()) { // on first pass, make a new delete/insert // delete is to make the commands idempotent if (reader["rn"].Equals("1")) { // for each master parent, I would create a // new WordPress post, inheriting the parent ID output.Append("DELETE FROM `wp_posts` WHERE ID = "); output.Append(reader["master_parent"].ToString()); output.Append("; INSERT INTO `wp_posts` (`ID`, `post_author`, "); output.Append("`post_date`, `post_date_gmt`, `post_content`, "); output.Append("`post_title`, `post_excerpt`, `post_status`, "); output.Append("`comment_status`, `ping_status`, `post_password`,"); output.Append(" `post_name`, `to_ping`, `pinged`, `post_modified`,"); output.Append(" `post_modified_gmt`, `post_content_filtered`, "); output.Append("`post_parent`, `guid`, `menu_order`, `post_type`, "); output.Append("`post_mime_type`, `comment_count`) VALUES ("); // I'm sure some of the above columns are optional, but identifying // those would not be a valuable use of time IMHO output.Append(reader["prefix"]); // hold on to the additional values until last row suffix = reader["suffix"].ToString(); } // manipulate the body content to be WordPress and INSERT statement-friendly string body = reader["body"].ToString().Replace(@"\n", "\n"); body = mark.Transform(body).Replace("href=", "target=_blank href="); body = body.Replace("<p>", "").Replace("</p>", ""); body = body.Replace("<pre><code>", "<pre lang=\"tsql\">"); body = body.Replace("</code></"+"pre>", "</"+"pre>"); body = body.Replace(@"'", "\'").Replace(@"’", "\'"); body = reader["bodypre"].ToString() + body.Replace("\n", @"\n"); body += reader["bodypost"].ToString(); body = body.Replace("<", "<").Replace(">", ">"); output.Append(body); // if we are on the last row, add additional values from the first row if (reader["c"].Equals(reader["rn"])) { output.Append(suffix); } } thisfile = UpperBound.ToString(); using (StreamWriter w = new StreamWriter(@"C:\wp\" + thisfile + ".sql")) { w.WriteLine(output); w.Flush(); } } } } } }Ja, dat is een lelijke stapel code, maar het bracht me uiteindelijk bij de reeks uitvoer die phpMyAdmin niet zou laten kotsen, en dat WordPress mooi (genoeg) zou presenteren. Ik heb het C#-programma gewoon meerdere keren aangeroepen met de verschillende parameterbereiken:
AnswerHubMigrator 1 750 AnswerHubMigrator 751 1500 AnswerHubMigrator 1501 2250 ...
Daarna opende ik elk van de bestanden, plakte ze in phpMyAdmin en drukte op GO:
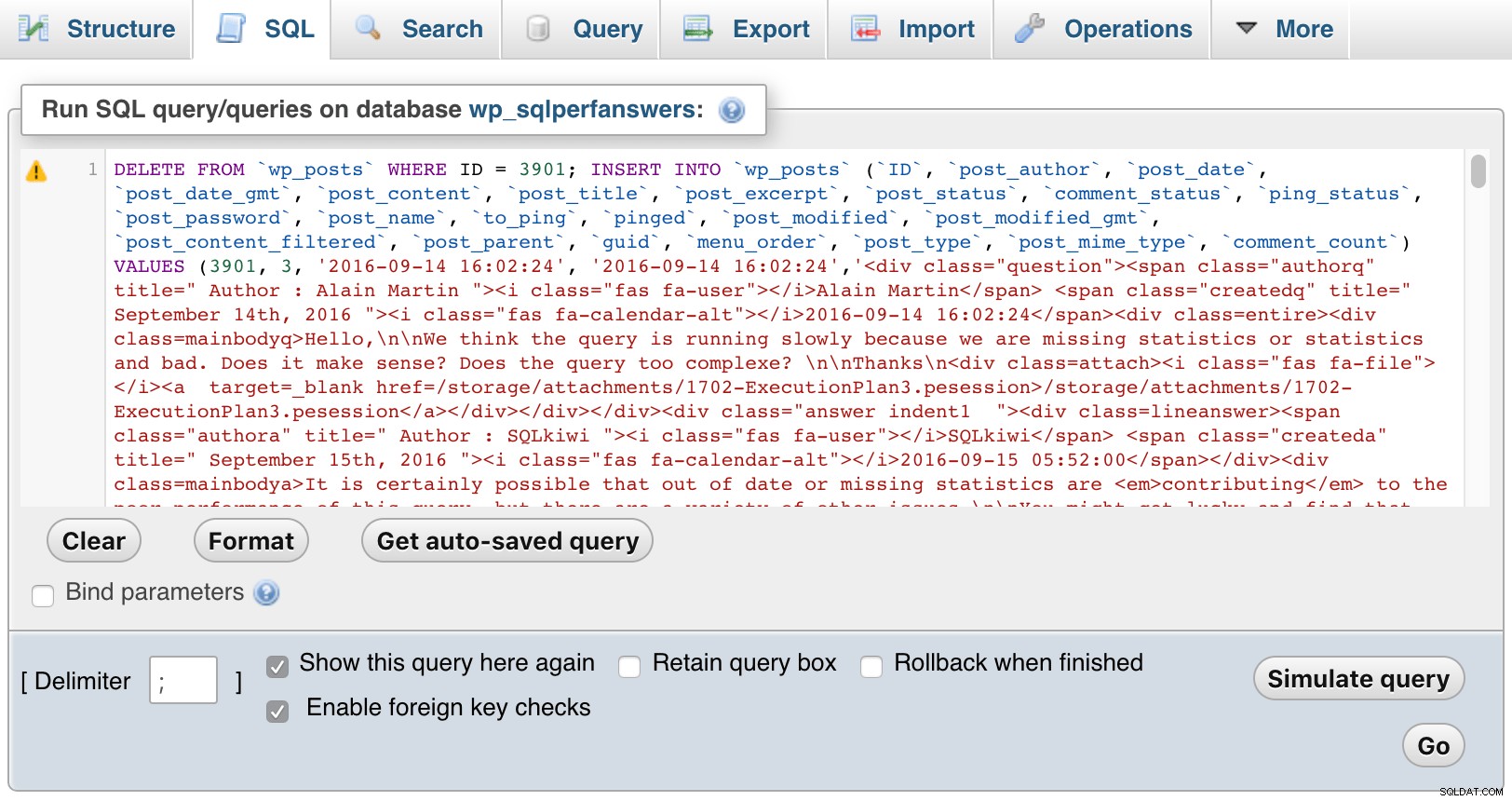 phpMyAdmin (klik om te vergroten)
phpMyAdmin (klik om te vergroten) Natuurlijk moest ik wat CSS toevoegen binnen WordPress om onderscheid te maken tussen vragen, opmerkingen en antwoorden, en ook om opmerkingen te laten inspringen om antwoorden op zowel vragen als antwoorden te tonen, opmerkingen die op opmerkingen reageren te nesten, enzovoort. Dit is hoe een fragment eruitziet als je doorklikt naar de vragen van een maand:
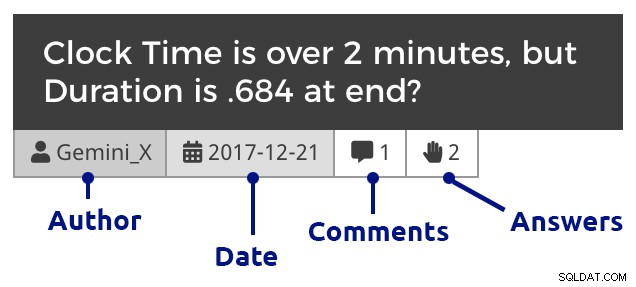 Vraagtegel (klik om te vergroten)
Vraagtegel (klik om te vergroten) En dan een voorbeeldpost met ingesloten afbeeldingen, meerdere bijlagen, geneste opmerkingen en een antwoord:
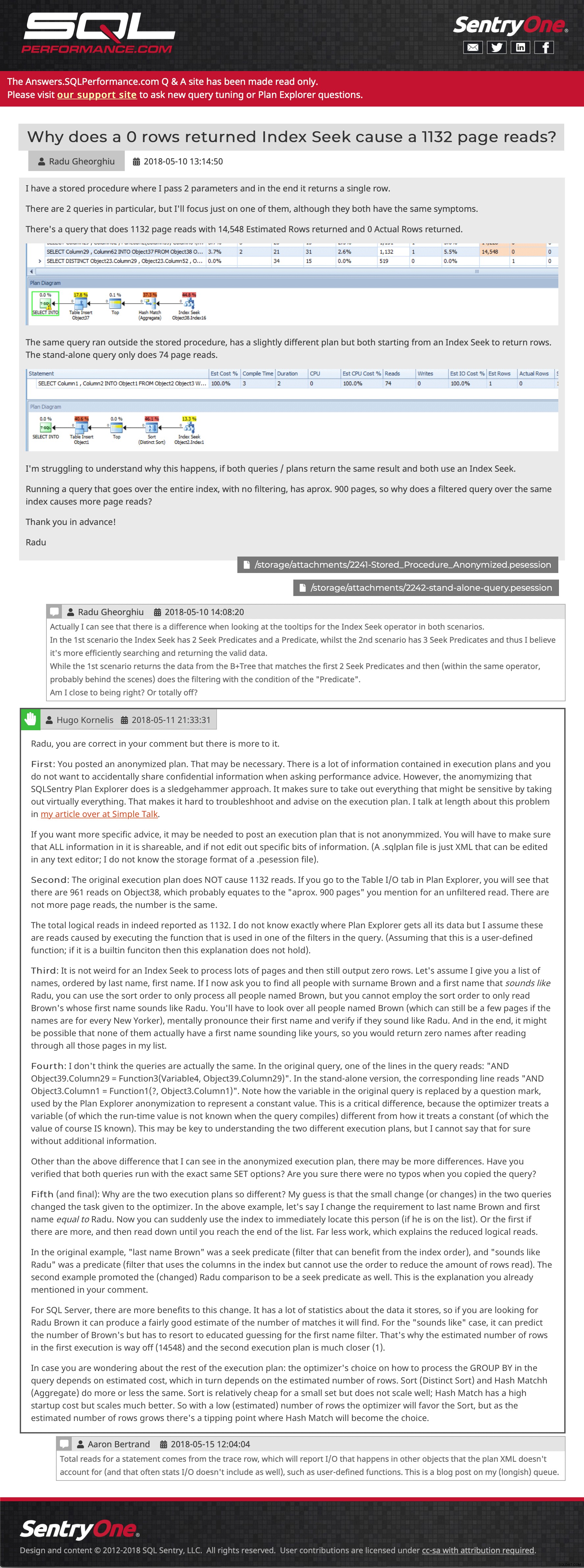 Voorbeeld van vraag en antwoord (klik om daarheen te gaan)
Voorbeeld van vraag en antwoord (klik om daarheen te gaan) Ik probeer nog steeds een paar berichten te herstellen die naar de site zijn verzonden nadat de laatste back-up is gemaakt, maar ik nodig u van harte uit om rond te bladeren. Laat het ons weten als u iets ziet dat ontbreekt of niet op zijn plaats is, of zelfs om ons te vertellen dat de inhoud nog steeds nuttig voor u is. We hopen de uploadfunctionaliteit voor abonnementen opnieuw te introduceren vanuit Plan Explorer, maar het vereist wat API-werk op de nieuwe ondersteuningssite, dus ik heb vandaag geen verwachte aankomsttijd voor je.
- Answers.SQLPerformance.com