De stijgende vraag naar systemen met hoge beschikbaarheid en strakke SLA's dwingt ons om handmatige procedures te vervangen door geautomatiseerde oplossingen. Maar heeft u de tijd en de nodige middelen om de complexiteit van failover-operaties zelf aan te pakken? Zul je de downtime van de productiedatabase opofferen om het op de harde manier te leren?
ClusterControl biedt geavanceerde ondersteuning voor storingsdetectie en -afhandeling. Het wordt gebruikt door veel zakelijke organisaties, waardoor de meest kritieke productiesystemen 24/7 operationeel blijven.
Deze databasebeheeroplossing ondersteunt u ook bij de inzet van verschillende laadproxy's. Deze proxy's spelen een sleutelrol in de HA-stack, dus het is niet nodig om de toepassingsverbindingsreeks of DNS-invoer aan te passen om toepassingsverbindingen om te leiden naar het nieuwe hoofdknooppunt.
Wanneer een storing wordt gedetecteerd, doet ClusterControl al het achtergrondwerk om een nieuwe master te kiezen, failover-slaveservers in te zetten en load balancers te configureren. In deze blog leert u hoe u een automatische failover van TimescaleDB in uw productiesystemen kunt realiseren.
Volledige replicatietopologieën implementeren
Vanaf ClusterControl 1.7.2 kunt u een volledige TimescaleDB-replicatie-setup op dezelfde manier implementeren als PostgreSQL:u kunt het menu "Cluster implementeren" gebruiken om een primaire en een of meer TimescaleDB-standbyservers te implementeren. Laten we eens kijken hoe het eruit ziet.
Eerst moet u toegangsdetails definiëren wanneer u nieuwe clusters implementeert met ClusterControl. Het vereist root- of sudo-wachtwoordtoegang tot alle knooppunten waarop uw nieuwe cluster zal worden geïmplementeerd.
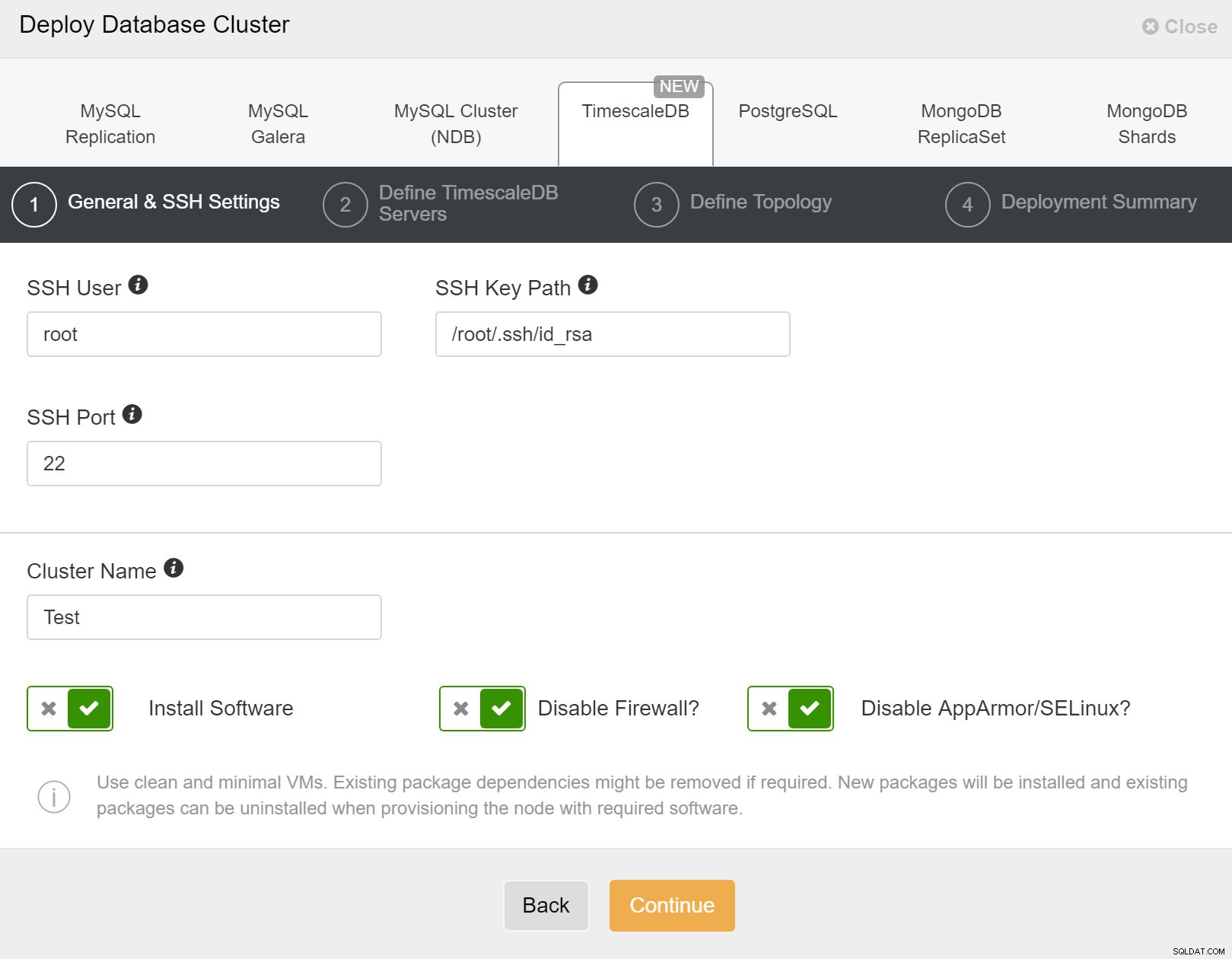 ClusterControl:nieuw cluster implementeren
ClusterControl:nieuw cluster implementeren Vervolgens moeten we de gebruiker en het wachtwoord voor de TimescaleDB-gebruiker definiëren.
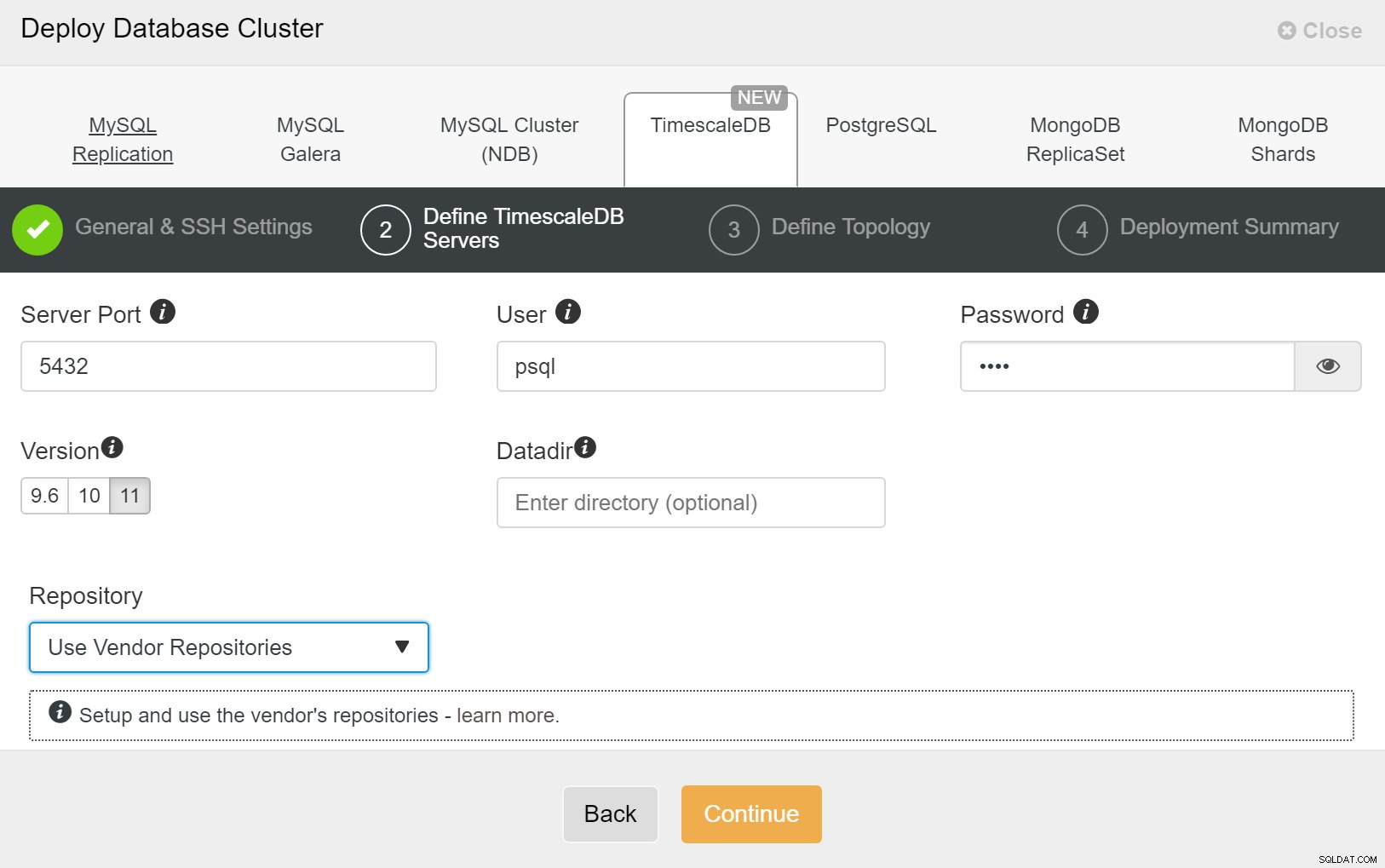 ClusterControl:databasecluster implementeren
ClusterControl:databasecluster implementeren Ten slotte wilt u de topologie definiëren - welke host de primaire moet zijn en welke hosts als stand-by moeten worden geconfigureerd. Terwijl u hosts definieert in de topologie, controleert ClusterControl of de ssh-toegang werkt zoals verwacht - hierdoor kunt u eventuele verbindingsproblemen in een vroeg stadium opmerken. Op het laatste scherm wordt u gevraagd naar het type replicatie, synchroon of asynchroon.
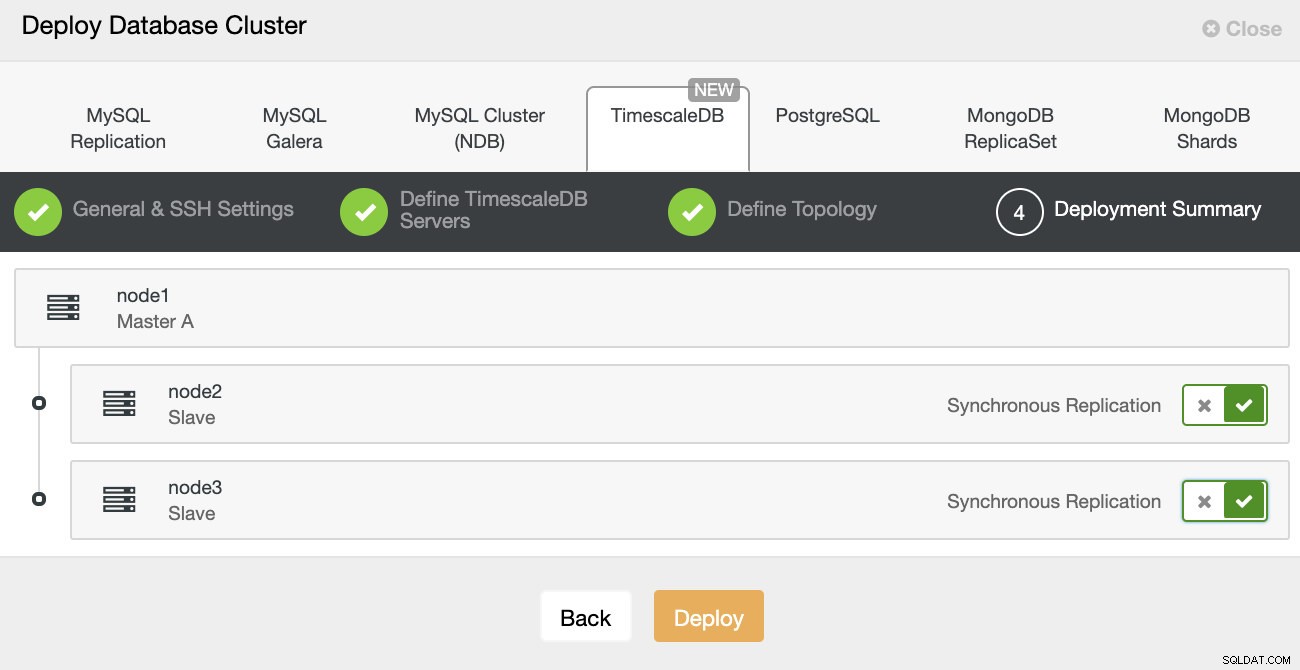 ClusterControl-implementatie
ClusterControl-implementatie Dat is alles, het is dan een kwestie van de implementatie starten. Er wordt een taak aangemaakt in ClusterControl en u kunt de voortgang volgen.
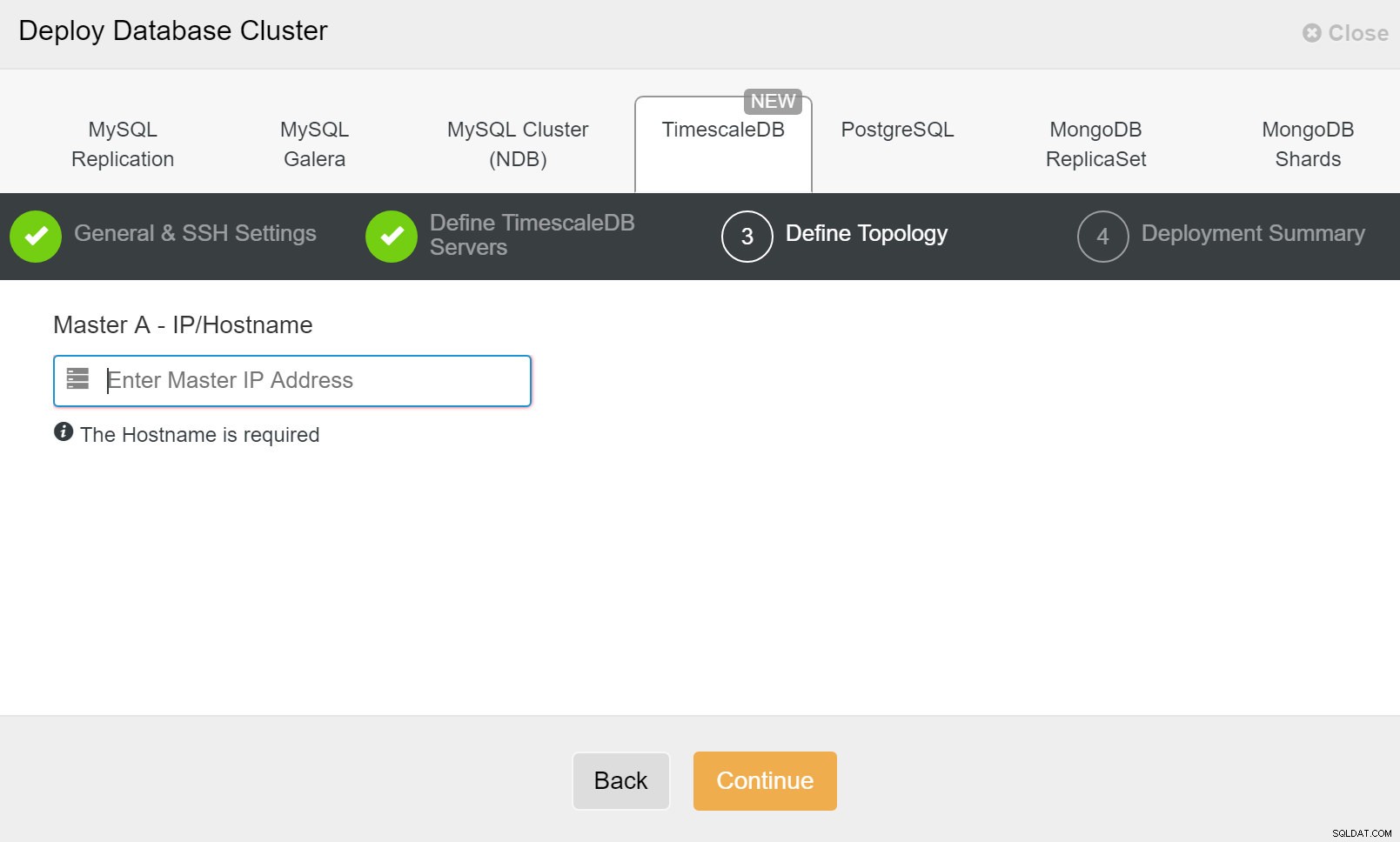 ClusterControl:definieer topologie voor TimescleDb-cluster
ClusterControl:definieer topologie voor TimescleDb-cluster Als u klaar bent, ziet u de topologie-instellingen met rollen in het cluster. Houd er rekening mee dat we ook een load balancer (HAProxy) hebben toegevoegd vóór de database-instanties, zodat de automatische failover geen wijzigingen in de instellingen voor de databaseverbinding vereist.
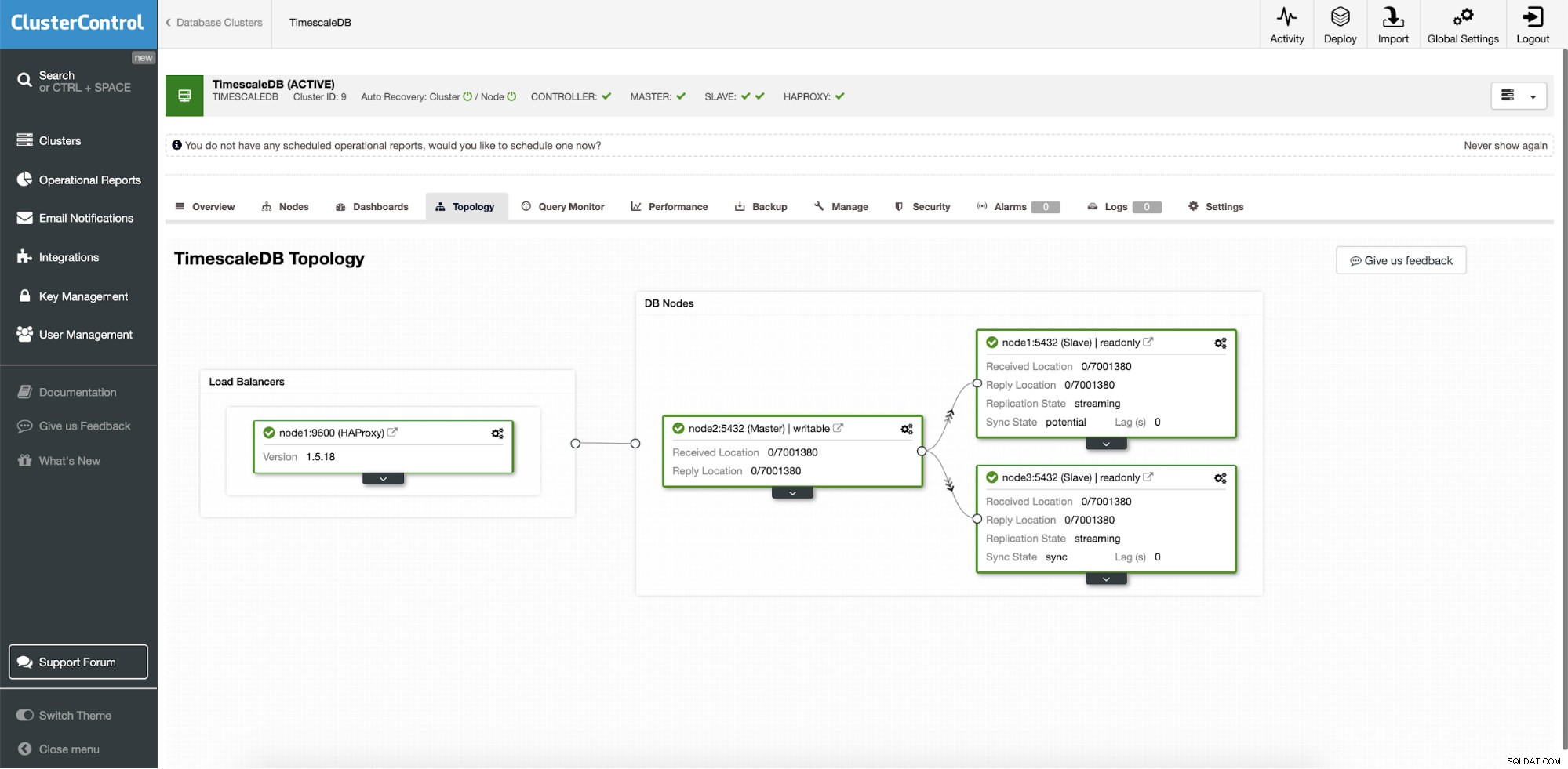 ClusterControl:Topologie
ClusterControl:Topologie Wanneer Timescale wordt geïmplementeerd door ClusterControl is automatisch herstel standaard ingeschakeld. De status kan worden gecontroleerd in de clusterbalk.
 ClusterControl:automatisch herstelcluster en knooppuntstatus
ClusterControl:automatisch herstelcluster en knooppuntstatus Failover-configuratie
Zodra de replicatie-installatie is geïmplementeerd, kan ClusterControl de installatie bewaken en automatisch defecte servers herstellen. Het kan ook veranderingen in de topologie orkestreren.
ClusterControl automatische failover is ontworpen met de volgende principes:
- Zorg ervoor dat de master echt dood is voordat je een failover uitvoert
- Slechts één keer failover
- Maak geen failover naar een inconsistente slaaf
- Schrijf alleen naar de master
- Herstel de mislukte master niet automatisch
Met de ingebouwde algoritmen kan een failover vaak vrij snel worden uitgevoerd, zodat u verzekerd bent van de hoogste SLA's voor uw database-omgeving.
Het proces is configureerbaar. Het wordt geleverd met meerdere parameters die u kunt gebruiken om herstel aan te passen aan de specifieke kenmerken van uw omgeving.
| max_replication_lag | Max. toegestane replicatievertraging in seconden voor |
| replication_stop_on_error | Failover-/omschakelprocedures mislukken als er fouten worden aangetroffen die gegevensverlies kunnen veroorzaken. Standaard ingeschakeld. 0 betekent uitschakelen, |
| replication_auto_rebuild_slave | Als de SQL-THREAD is gestopt en de foutcode niet nul is, wordt de slave automatisch opnieuw opgebouwd. 1 betekent inschakelen, 0 betekent uitschakelen (standaard). |
| replication_failover_blacklist | Door komma's gescheiden lijst van hostnaam:poort-paren. Op de zwarte lijst geplaatste servers worden tijdens een failover niet als kandidaat beschouwd. replication_failover_blacklist wordt genegeerd als replication_failover_whitelist is ingesteld. |
| replication_failover_whitelist | Door komma's gescheiden lijst van hostnaam:poort-paren. Alleen servers op de witte lijst worden tijdens een failover als kandidaat beschouwd. Als er geen server op de witte lijst beschikbaar is (up/connected), zal de failover mislukken. replication_failover_blacklist wordt genegeerd als replication_failover_whitelist is ingesteld. |
Failover-afhandeling
Wanneer een masterfout wordt gedetecteerd, wordt een lijst met masterkandidaten gemaakt en wordt een van hen gekozen als de nieuwe master. Het is mogelijk om een witte lijst te hebben met servers die naar primair kunnen worden gepromoveerd, evenals een zwarte lijst met servers die niet naar primair kunnen worden gepromoveerd. De resterende slaves worden nu als slaaf gemaakt van de nieuwe primaire en de oude primaire wordt niet opnieuw gestart.
Hieronder zien we een simulatie van het falen van een knoop.
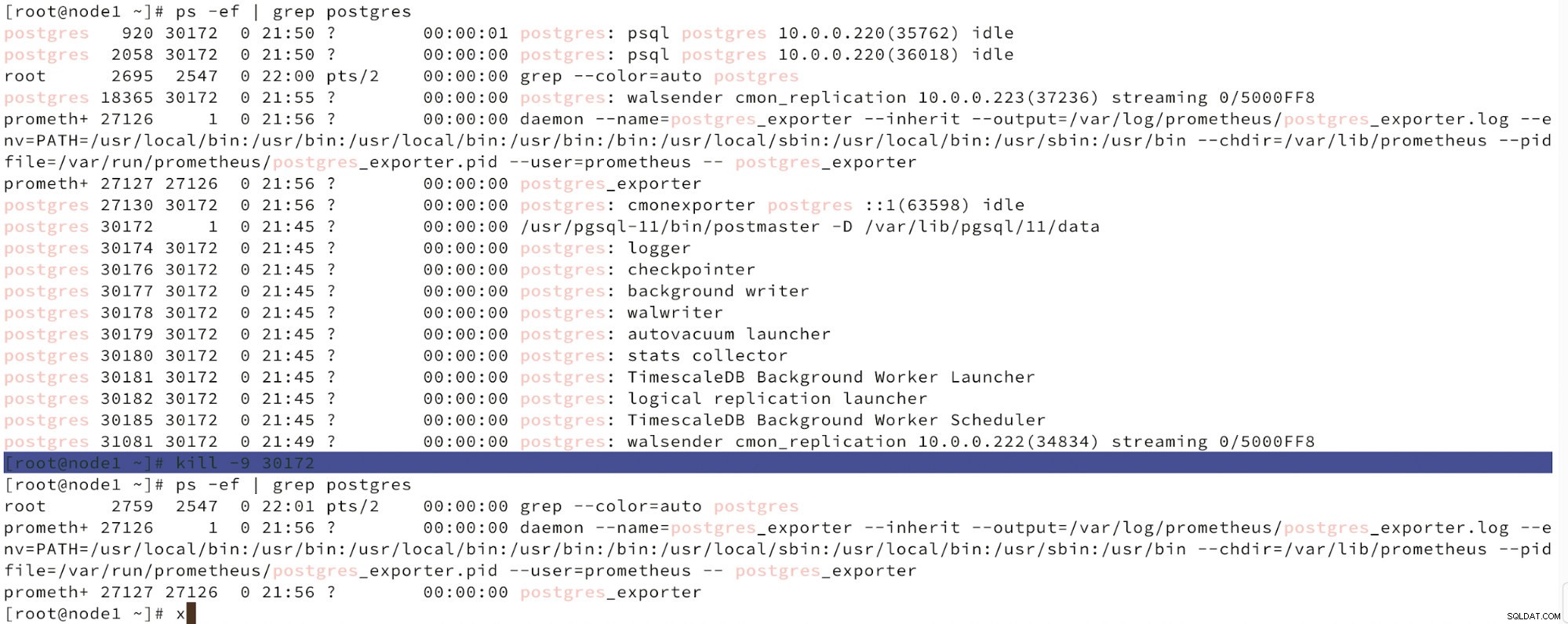 Simuleer een masternode-fout met kill
Simuleer een masternode-fout met kill Wanneer een storing in de knooppunten wordt gedetecteerd en automatisch herstel wordt gedetecteerd, activeert ClusterControl de taak om een failover uit te voeren. Hieronder kunnen we de acties zien die zijn genomen om het cluster te herstellen.
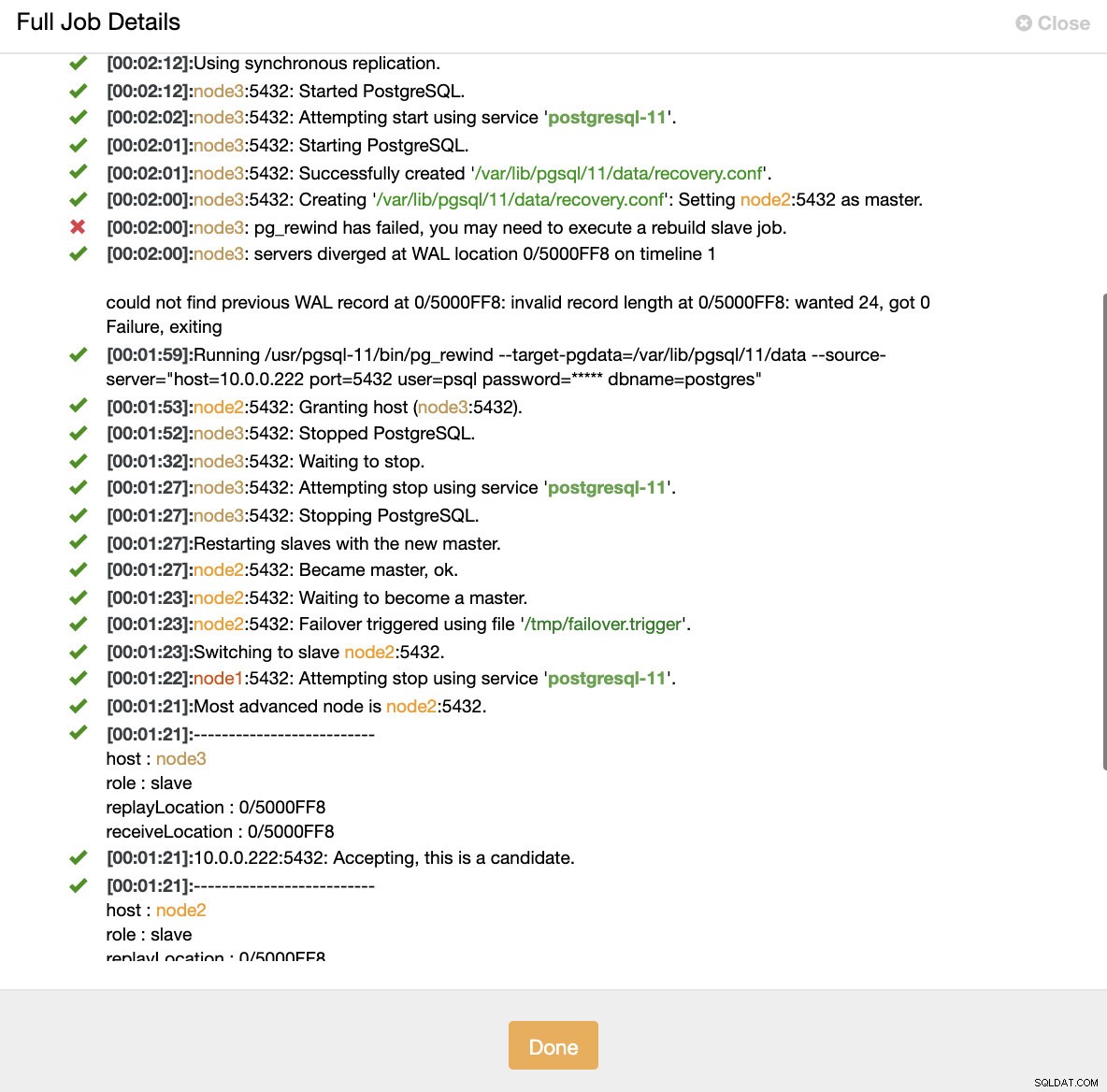 ClusterControl:taak geactiveerd om het cluster opnieuw op te bouwen
ClusterControl:taak geactiveerd om het cluster opnieuw op te bouwen ClusterControl houdt bewust de oude primary offline omdat het kan gebeuren dat een deel van de data niet naar de standby servers is overgebracht. In een dergelijk geval is de primaire host de enige host die deze gegevens bevat en wilt u misschien de ontbrekende gegevens handmatig herstellen. Voor degenen die de mislukte primaire automatisch opnieuw willen opbouwen, is er een optie in het cmon-configuratiebestand:replication_auto_rebuild_slave. Standaard is het uitgeschakeld, maar wanneer de gebruiker het inschakelt, wordt de mislukte primaire opnieuw opgebouwd als een slaaf van de nieuwe primaire. Natuurlijk, als er ontbrekende gegevens zijn die alleen op de mislukte primaire staan, gaan die gegevens verloren.
Standby-servers opnieuw opbouwen
Een andere functie is de taak "Rebuild Replication Slave" die beschikbaar is voor alle slaves (of standby-servers) in de replicatie-instellingen. Dit wordt bijvoorbeeld gebruikt wanneer u de gegevens op de standby wilt wissen en deze opnieuw wilt opbouwen met een nieuwe kopie van de gegevens van de primaire. Het kan handig zijn als een standby-server om de een of andere reden geen verbinding kan maken en repliceren vanaf de primaire server.
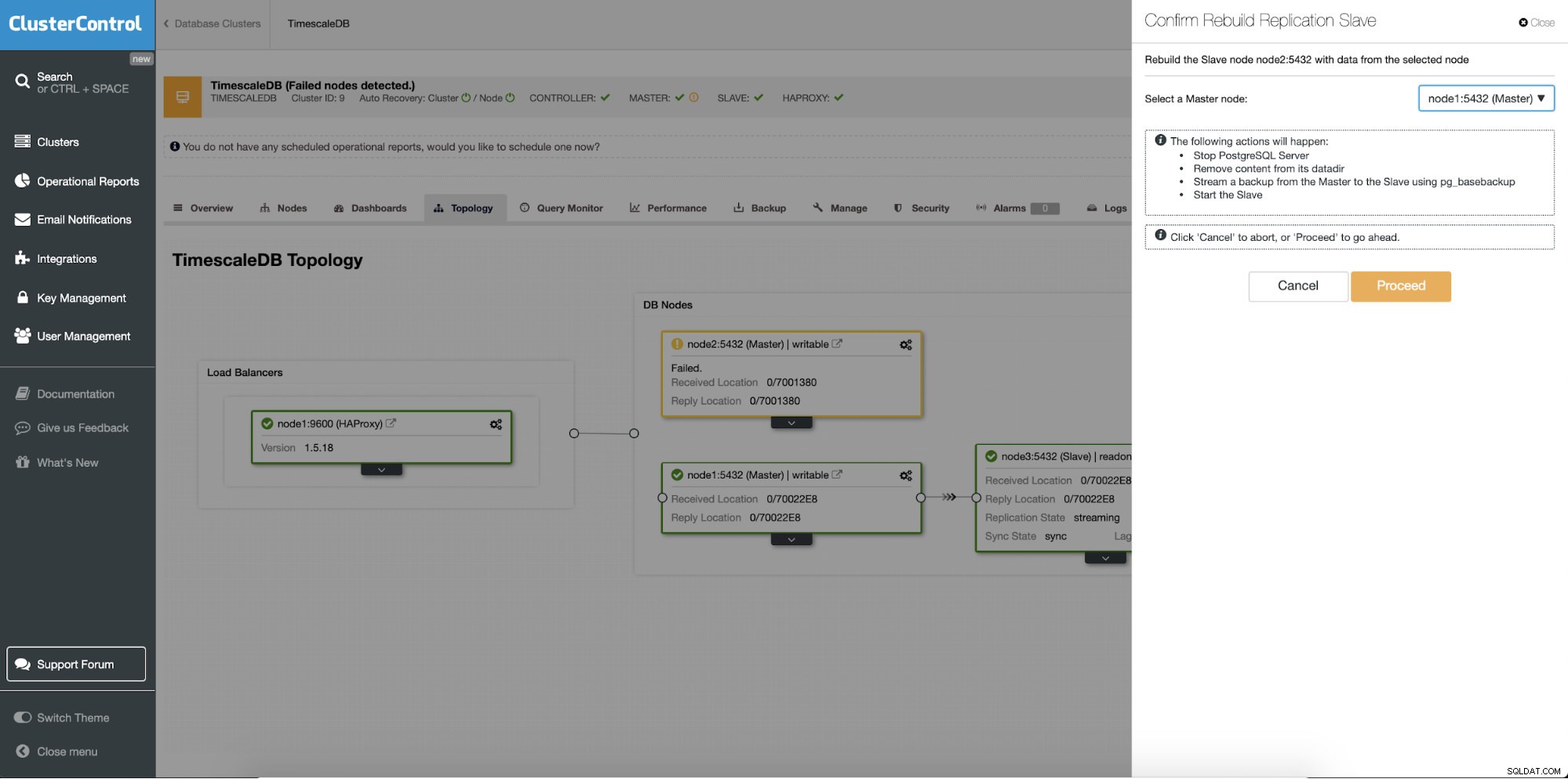 ClusterControl:replicatieslave opnieuw opbouwen
ClusterControl:replicatieslave opnieuw opbouwen  ClusterControl:slaaf opnieuw opbouwen
ClusterControl:slaaf opnieuw opbouwen