Er komt veel kijken bij het ontwerpen van een database, en slechts weinigen van ons kunnen zich elke waardevolle tip en truc herinneren die we hebben geleerd. Laten we dus eens kijken naar enkele online bronnen met tips voor databaseontwerp en best practices. Gaandeweg deel ik mijn eigen mening over de gepresenteerde ideeën, gebaseerd op mijn ervaring met databaseontwerp.
Het is duidelijk dat dit artikel geen uitputtende lijst is, maar ik heb geprobeerd een dwarsdoorsnede van bronnen te bekijken en te becommentariëren. Hopelijk vindt u de informatie die het beste past bij uw behoeften en doelen.
Even terzijde:ik was verrast toen ik ontdekte dat veel artikelen met betrekking tot database-ontwerppraktijken maar heel weinig voorbeelden bevatten; de online bronnen die ik heb beoordeeld voor het artikel over fouten en vergissingen hadden een hoger percentage. Dit gebrek is een nadeel, omdat voorbeelden uiterst belangrijk zijn om het punt over te brengen.
Databasetips voor ervaren ontwerpers
Laten we eerst beginnen met bronnen met geavanceerde tips voor het ontwerpen van databases en best practices. Deze zijn voor ontwerpers die al bezig zijn met datamodellering en dat al een tijdje doen. Sommige artikelen zijn gericht op een meer gemiddeld niveau, maar als ze geavanceerde concepten bespreken, heb ik ze in deze lijst opgenomen.
Databaserichtlijnen (RDBMS/SQL)
door Steve Djajasaputra | SOA, Java, softwareontwikkeling – BlogSpot | 16 januari 2013
Dit artikel van de heer Djajasaputra is behoorlijk indrukwekkend:hij somt talloze tips op voor het schema, indexen en weergaven; hij geeft ook een vrij gedetailleerde naamgevingsconventie. En zijn tips gaan maar door (en verder). De breedte is indrukwekkend, maar er zijn bijna geen voorbeelden. Sommige van zijn punten kunnen als discutabel worden beschouwd, maar over het algemeen is dit een zeer solide presentatie.
Ik was vooral onder de indruk dat hij een precieze regel geeft over het gebruik van natuurlijke versus kunstmatige (d.w.z. surrogaat of gegenereerde) primaire sleutels. Hij houdt dit mooi en eenvoudig en specificeert dat we de voorkeur moeten geven aan een natuurlijke sleutel omdat deze betekenisvol is. Hij geeft ook richtlijnen voor het beste gebruik van een kunstmatige sleutel, met name wanneer de natuurlijke sleutel niet uniek is of wanneer u de waarde van de natuurlijke sleutel moet wijzigen. In zijn eigen woorden:
Geef er eerst de voorkeur aan om de natuurlijke sleutel te gebruiken, omdat deze zinvoller is en duplicaties voorkomt (bestaande kolom opnieuw gebruiken). Maar er zijn gevallen waarin u een kunstmatige sleutel nodig hebt:wanneer de natuurlijke sleutel niet uniek is (bijvoorbeeld namen) of als u de waarde moet wijzigen.Omdat zijn lijst met tips zo lang is, kan ik me niet voorstellen ze allemaal te onthouden. Maar er kan naar elke sectie worden verwezen wanneer u werkt aan databaseontwerp, prestaties, opgeslagen procedures en versiebeheer. Er is ook een sectie over Oracle-specifieke punten die handig kunnen zijn als u met Oracle werkt of van plan bent om Oracle te ondersteunen.
Al met al is dit een zeer waardevolle en uitgebreide bron.
9 tips voor een beter databaseontwerp
door Jeffrey Edison | Vertabelo Blog | 22 september 2015
Ik zal me hier overgeven aan een beetje zelfpromotie.
Dit artikel met 9 tips voor een beter databaseontwerp is gebaseerd op mijn ervaring als ontwerper en architect. Ik heb ook aanvullende inzichten gevonden door onderzoek te doen naar de best practices van anderen voor het ontwerpen van databases.
Mijn lijst vertegenwoordigt enkele van de belangrijkste problemen die kunnen optreden bij het werken met gegevensmodellen. Ik heb de tips geordend in de volgorde waarin ze voorkomen tijdens de levenscyclus van het project (in plaats van op belangrijkheid of hoe vaak ze voorkomen), omdat dat naar mijn mening het nuttigst zou zijn. Lezers kunnen deze checklist met best practices volgen gedurende de levenscyclus van een project.
Uit het artikel:
Om Al Capone (of John Van Buren, zoon van de 8e Amerikaanse president) te parafraseren:"test vroeg, test vaak". Zo volg je het pad van Continuous Integration. Testen in een vroeg ontwikkelingsstadium bespaart tijd en geld. Bij het testen van de database moet het doel zijn om een productieomgeving te simuleren:"A Day in the Life of the Database". Welke volumes zijn te verwachten? Welke gebruikersinteracties zijn waarschijnlijk? Worden de grensgevallen behandeld?Door aandacht te besteden aan deze tips, heb ik gemerkt dat databases beter ontworpen en robuuster worden. Hoewel geen van deze activiteiten enorm veel tijd in beslag zal nemen, kan elk een enorme impact hebben op de kwaliteit van uw datamodel.
Ik hoop dat mijn lijst met tips nuttig is voor halfgevorderde en gevorderde ontwerpers.
20 best practices voor databaseontwerp
door Cagdas Basaraner | Codesaldo – BlogSpot | 24 juli 2011
De heer Basaraner presenteert ons een interessante lijst van 20 best practices voor databaseontwerp. Ik had liever gehad dat hij er enkele had gegroepeerd; de eerste vier items kunnen bijvoorbeeld allemaal worden behandeld onder "Gebruik goede naamgevingsconventies".
Daarnaast stelt hij dat het gebruik van een synthetische, gegenereerde (integer) ID als primaire sleutel van alle tabellen een goede gewoonte is. In feite is dit nog steeds een onderwerp van discussie, met argumenten voor en tegen. Sommige van zijn best practices zijn vrij algemeen, zoals "Voor ... missiecriticus [sic] databasesystemen, gebruik noodherstel en beveiligingsservice ..." Ik ben het niet oneens met dit punt, maar het is van zeer hoog niveau.
Positief is dat dit artikel een van de weinige was die het gebruik van een object-relationele mapping (ORM) -raamwerk noemde. Sommige reageerders waren het niet eens met de formulering van de tip, maar er wordt in ieder geval melding gemaakt van een ORM-framework:
Gebruik een ORM-framework (object relational mapping) (d.w.z. Hibernate, iBatis ...) als de toepassingscode groot genoeg is. Prestatieproblemen van ORM-frameworks kunnen worden afgehandeld door gedetailleerde configuratieparameters.Toch had deze lijst verbeterd kunnen worden. Het moet duidelijk punten aangeven die specifiek zijn voor slechts sommige databasebeheersystemen (bijvoorbeeld SQL Server). Nauwkeurige statistieken met betrekking tot prestaties, heuristieken of het belang van tijd besteden aan ontwerp in plaats van op onderhoud en herontwerp zou goed zijn geweest. Er waren ook meer voorbeelden nodig, maar dat is een probleem voor de meeste van deze artikelen.
Als je met SQL Server werkt, overweegt een ORM-framework te gebruiken, of een lijst met tips met opsommingstekens nodig hebt in plaats van een lang en gedetailleerd artikel, dan is dit stuk iets voor jou.
(Opmerking:dit artikel verscheen ook op verschillende andere sites, waaronder CodeBuild, Java Code Geeks en DZone.)
Benodigdheden voor databaseontwerp. 10 dingen die u absoluut moet doen
door Michelle A. Poolet | SQL Server Pro | 1 maart 2011
Een deel van de tips van mevrouw Poolet is vrij standaard en kan in veel andere bronnen worden gevonden, maar er zijn ook een paar nogal ongebruikelijke punten. Onder haar algemene punten promoot ze het gebruik van subtypes en supertypes (waar ik het volledig mee eens ben), omdat dit objectgeoriënteerd ontwerp weerspiegelt en gemakkelijk kan worden begrepen door ontwikkelaars. Uit haar artikel:
Wees niet bang om supertype- en subtype-entiteiten in uw ontwerp op te nemen in de CDM en verder. De subtypen vertegenwoordigen classificaties of categorieën van het supertype... Entiteiten worden weergegeven als subtypen wanneer er meer dan één woord of zin nodig is om de entiteit te categoriseren.
Als een categorie een eigen leven leidt, met aparte attributen die beschrijven hoe de categorie eruitziet en zich gedraagt en relaties met andere entiteiten scheidt, dan is het tijd om de supertype/subtype-structuur aan te roepen . Als u dit niet doet, wordt een volledig begrip van de gegevens en de bedrijfsregels die de gegevensverzameling stimuleren, belemmerd.
Sommige van haar opmerkingen verwijzen specifiek naar MS SQL Server, zelfs als de opmerkingen eigenlijk algemene problemen zijn. Een belangrijk punt dat mevrouw Poolet maakt, is zeer SQL Server-specifiek:"Bewaar code die de gegevens van een database raakt als een opgeslagen procedure".
Dit is prima als u alleen van plan bent om één enkel databasebeheersysteem, zoals SQL Server, te ondersteunen. Maar voor draagbare implementaties zou dit geen goed advies zijn. Over het algemeen ontwerp ik voor overdraagbaarheid naar ten minste twee beheersystemen met verschillende taalondersteuning voor opgeslagen procedures. Daarom zou ik deze praktijk vermijden.
Dit artikel is vooral nuttig voor mensen die zich ontwikkelen voor SQL Server en zich richten op de Amerikaanse markt (in plaats van een internationaal systeem). Als Amerikaan die in het buitenland woont, ontdekte ik echter dat sommige van haar voorbeelden een beetje te "VS-gericht" zijn. Een niet-Amerikaan begrijpt bijvoorbeeld misschien niet wat een Zip+4 domein is en zou daarom niet begrijpen waarom een dit domein een NOT NULL-kenmerk zou moeten hebben.
Om dit te illustreren heb ik een datamodel gemaakt voor beide Amerikaanse niet-Amerikaanse adressen. We gaan ervan uit dat ons gegevensmodel mogelijk vereist dat entiteiten aan meer dan één adres worden gekoppeld:bijvoorbeeld één voor facturering, één voor verzending. Het eerste adres zou worden gekoppeld aan een betaalmethode; in dit geval wordt het adres gebruikt om uw recht te verifiëren om die betaling te autoriseren. Het verzendadres is natuurlijk waar de bestelling wordt afgeleverd.
Laten we een Amerikaans adres maken als onderdeel van een databasemodel voor klantorders. (Opmerking:dit is geen compleet model, maar een voorbeeld van het opslaan van productbestellingen.)
Wise Coders Solutions raadt aan om aparte velden voor huisnummers en straatnamen te definiëren en deze velden in te stellen op NOT NULL; dit zou elk adres weigeren dat geen huisnummer en straatnaam heeft. Maar hoe zit het met mensen die postbussen gebruiken? Hun adressen worden meestal geschreven als "PO Box 123". Moeten we ze dwingen om het postbusnummer als huisnummer en 'postbus' als straatnaam te gebruiken? Ik denk het niet.
In plaats daarvan gebruiken we een formulier met "Adresregel 1" en "Adresregel 2". Verschillende mensen hebben bezwaar gemaakt tegen het gebruik van getallen in veldnamen, maar voor mij is dit een nogal voor de hand liggende oplossing. Ook heb ik maximale veldlengtes (35 en 70 tekens) gedefinieerd die typisch zijn voor internationale betalingen.
Merk op dat de Amerikaanse en de niet-Amerikaanse ontwerpen beide een veld hebben voor regio's binnen een land, maar voor het Amerikaanse ontwerp moet een staatsafkorting van 2 tekens worden opgenomen. Merk ook op dat het Amerikaanse ontwerp geen adressen in andere landen toestaat.
Als u zich zorgen maakt over het wereldwijde gebruik van uw database, moet u tijdens de ontwerpfase globaal denken. Zijn onze databases voorbereid op het multinationale gebruik van onze applicaties?
Lessen geleerd van slecht datawarehouse-ontwerp
door Michelle A. Poolet | SQL Server Pro | 15 juni 2009
Dit artikel gaat in op het Data Warehouse (DWH) en enkele ontwerp- en implementatieproblemen. Er is een lichte focus op SQL Server, maar het is een vrij orthodox overzicht van ontwerpen voor datawarehousing en business intelligence. Het hebben van buy-in en het creëren van gebruiksvriendelijke interfaces zijn misschien niet de meest bruikbare tips, maar ik ben het er niet mee eens - ik denk gewoon niet dat ze deel uitmaken van DWH-ontwerp.
Mevrouw Poolet stelt dat het extract-transform-load (ETL)-proces gegevenskwaliteitscontroles moet uitvoeren en mogelijk gegevens moet "opschonen" totdat er een acceptabele standaard voor gegevenskwaliteit is. Naar mijn mening riskeert dit het creëren van een datawarehouse dat de informatie uit het bronsysteem niet goed weerspiegelt. Het opschonen van gegevens moet worden uitgevoerd in de bronsystemen. ETL mag gegevens alleen transformeren zodat ze in het datawarehouse kunnen worden geladen.
Positief is dat de aanbeveling van recycling of het maken van herbruikbare ETL-routines zeer relevant is. Daarnaast ben ik het eens met mevrouw Poolet over schaalbaarheid. Haar opmerkingen over risicobeheer en compliance, met name de Sarbanes-Oxley Act, lijken vrij specifiek; Ik neem aan dat deze uit haar vakgebied komen.
Ten slotte heeft ze een mooie checklist met punten met betrekking tot dimensies, feitentabellen en schemakeuzes tijdens OLAP-ontwerp (online analytische verwerking). Deze blijken zeer relevant te zijn tijdens het ontwerpproces van de database. Ik had graag gezien dat deze lijst langer was, met meer details of voorbeelden, maar ik was blij dat deze praktische tips erin stonden.
11 Belangrijke regels voor het ontwerpen van databases die ik volg
door Shivprasad Koirala | Codeproject | 25 februari 2014
Ik hou echt van het verstandige en duidelijke advies aan het begin van dit artikel. Begrippen als 'overweeg de aard van de applicatie' en 'breek je gegevens in logische stukjes' zijn perfect. Dit zijn belangrijke hulpmiddelen bij het maken van uw gegevensmodel. Zoals meneer Koirala zegt:
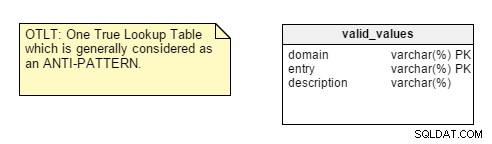
Wanneer u begint met het ontwerpen van uw database, is het eerste dat u moet analyseren de aard van de toepassing waarvoor u ontwerpt, of deze nu Transactioneel of Analytisch is. U zult zien dat veel ontwikkelaars standaard normalisatieregels toepassen zonder na te denken over de aard van de toepassing en later in prestatie- en aanpassingsproblemen te komen.Er zijn echter een paar punten die mij niet overtuigen. Neem bijvoorbeeld het centraliseren van naam-waarde-paren in een enkele tabel. Dit One True Lookup Table (OTLT) -ontwerp staat ter discussie, maar wordt over het algemeen als een slechte gewoonte beschouwd of op zijn minst als een anti-patroon in het ontwerp. Ik sluit me aan bij de anti-OTLT-groep; deze tabellen introduceren tal van problemen. We zouden de analogie van softwareontwikkeling kunnen gebruiken door een enkele enumerator te gebruiken om alle mogelijke waarden van alle mogelijke constanten weer te geven als een equivalent van deze praktijk.
Ter herinnering:de OTLT-tabel ziet er meestal ongeveer zo uit, met vermeldingen van meerdere domeinen in dezelfde tabel. Ik ben het eens met anti-OTLT-groep; deze tabellen introduceren tal van problemen.
Bovendien lijken sommige punten een beetje esoterisch, zoals "let op gegevens gescheiden door scheidingstekens". Hoewel dit een geldig punt is, denk ik er meestal niet aan bij het maken van een nieuw gegevensmodel.
De heer Koirala heeft een aantal OLAP-ontwerpitems die over het algemeen niet worden vermeld in andere lijsten met beste praktijken. Zijn toevoeging van een ontwerp met dimensies en feiten kan nuttig zijn, maar het kan ook gevaarlijk zijn voor beginnende ontwerpers.
Dit artikel is interessant als u van het begin overstapt naar meer geavanceerde gegevensmodellering. Het zal u helpen om de analytische versus transactionele aard van uw toekomstige modellen te overwegen.
Big data:vijf eenvoudige prestatietips voor database-ontwerp
door Dave Beulke | davebeulke.com | 19 maart 2013

Het artikel van de heer Beulke gaat in op prestatiegerichte ontwerptips. Hij laat zien hoe je kunt controleren op een goede normalisatie:niet te veel en niet te weinig. (Overnormalisatie heeft een negatief effect op de databaseprestaties.)
Het gebruik van natuurlijke bedrijfssleutels in plaats van gegenereerde primaire sleutels is ook een goed advies als u wilt voorkomen dat u voor elke databasetoegang vertaalt van een bedrijfssleutel naar een gegenereerde rij-ID.
Het gebruik van de juiste naamgevingsnormen en kolomtypen is ook een goed advies. Het punt over het overmatig gebruik van nullable-kolommen is correct:het is een vergissing om alle kolommen als nullable te maken, maar het definiëren van een kolom als nullable kan vereist zijn voor een bepaalde bedrijfsfunctie. In de eigen woorden van de auteur:
Zijn alle kolommen NULLable? Binnen de definities van databasekolommen moeten goede gegevensdomeinen, bereiken en waarden worden geanalyseerd, geëvalueerd en geprototypeerd voor de bedrijfstoepassing. Goede standaardwaarden, een beperkt aantal waarden en altijd een waarde zijn het beste voor prestaties en toepassingslogica. NULL-kolommen zijn alleen goed als gegevens onbekend zijn of nog geen waarde hebben. Iemands overlijdensdatumgegevens zijn het klassieke voorbeeld van een NULL-kolom omdat deze onbekend is, tenzij ze al dood zijn. Zorg ervoor dat uw databaseontwerp gegevens vertegenwoordigt die bekend zijn en slechts een minimum aan NULL-kolommen gebruikt.De tips van meneer Beulke zijn allemaal erg solide, ook al zijn ze enigszins onorigineel. Ik had graag meer Big Data-items gezien, dat is tenslotte de titel van het artikel. Uiteindelijk vond ik dat het artikel zowel diepte als breedte miste en geen voorbeelden had om de punten te verduidelijken. Hij biedt echter waardevol advies met betrekking tot normalisatie en natuurlijke sleutels.
10 best practices voor databaseontwerp
door Ann All | Enterprise-apps vandaag | 15 juli 2014
Ten Database Design Best Practices wordt eigenlijk gepresenteerd als een reeks dia's. Ms. All bevat informatie van ervaren ontwikkelaars, zoals Michael Blaha. Hij moedigt het hergebruik van uw best practices en patronen aan. Deze zijn begrepen en bewezen, en in dat opzicht te verkiezen boven datamodellen die vanaf nul moeten worden gecreëerd. Uit het artikel van mevrouw All:
Ik ben bijvoorbeeld vaak bezig met reverse-engineering van databases:databases van een te vervangen applicatie en databases van gerelateerde applicaties. Deze bestaande databases hebben vaak geen beschikbaar datamodel. Maar een datamodel is impliciet in het databaseschema en kan op zijn minst gedeeltelijk worden geëxtraheerd met reverse engineering-technieken voor databases. … Er zijn beproefde gegevensrepresentaties die vaak voorkomen en niet helemaal opnieuw hoeven te worden gemaakt.Dit is een korte diavoorstelling waar ontwerpers van gegevensmodellen snel doorheen kunnen bladeren en de tips kunnen verzamelen die ermee resoneren. Voor mij is de hergebruiktip een van mijn favorieten.
Beste praktijken voor databases
door Cunningham &Cunningham, Inc.
Deze best practices begonnen prima, maar kwamen toen in een aantal lastige problemen. Ik ben er niet van overtuigd dat het advies dat wordt gegeven altijd klopt.
Positief is dat er zeer mooie beschrijvingen zijn van controversiële "best practices", zoals het altijd gebruiken van automatisch gegenereerde surrogaatsleutels en het gebruiken of vermijden van opgeslagen procedures. Als voorbeeld:
Een eerdere auteur schreef:"Vermijd in het algemeen PrimaryKeys die betekenis hebben. Namen zijn niet uniek, en veel schijnbaar unieke identificatiegegevens zoals burgerservicenummers zijn dat ook niet, vanwege problemen met de betrouwbaarheid van gegevens in de echte wereld." Kortom, dit is een aanbeveling om altijd een automatisch gegenereerde (meestal numerieke) SurrogateKey te hebben in plaats van een op een domein gebaseerde LogicalKey. Dit is een tamelijk eenvoudig antwoord op een complexe kwestie, hoewel het in een aantal gevallen voldoende is en op zijn minst de voorkeur heeft boven helemaal geen PrimaryKey.(Opmerking van de auteur:ik heb deze 'vorige auteur' niet kunnen vinden bij het zoeken naar deze twee zinnen op Google.)
En er is een link naar een samenvattend artikel over de belangrijkste argumenten aan elke kant van het debat over Auto Keys versus Domain Keys.
Aan de andere kant vond ik de tips om "besturingssysteem, gegevens en inloggen op verschillende fysieke schijven te verdelen" en "RAID gebruiken" een beetje geheimzinnig. Begrijp me niet verkeerd - dit is in sommige omstandigheden waarschijnlijk een goed advies, maar ik zou het niet in mijn Top 20-lijst opnemen.
Tips voor databaseontwerp
door Wise Coders
Deze verzameling bevat een paar unieke en interessante tips, zoals een aanbeveling om transacties zo snel mogelijk te sluiten.
Ik ben het echter niet helemaal eens met alle ontwerptips hier. Bijvoorbeeld:
Ga uit van een veld ‘Status’ met de waarden ‘Actief’, ‘Inactief’ en ‘Idle’. U kunt de waarde opslaan als de volledige naam, maar dit kan inefficiënt zijn. Het opslaan van een opsomming of een char(1) met mogelijke waarden 'a', 'i', 'd', bijvoorbeeld, zal minder ruimte in beslag nemen in de database.Dit is op zijn zachtst gezegd controversieel - andere bronnen raden af om dergelijke "geheime codes" te gebruiken. Gebruik in plaats daarvan een aparte tabel om deze statuscodes op te slaan.
Bovendien zijn de statistieken die zijn gekoppeld aan prestatiehints twijfelachtig en er zijn geen voorbeelden in het artikel.
Positief is dat dit een mooie korte lijst met tips is die toegankelijk moeten zijn voor intermediaire databasemodelleurs.
Bronnen voor beginnende databaseontwerpers
Laten we nu een paar artikelen bekijken voor degenen die net zijn begonnen met het ontwerpen van databases.
De basis van goed database-ontwerp in webontwikkeling
door Kayla Knight | Onextrapixel.com | 17 maart 2011
Hier worden we wat geavanceerder, met advies variërend van functionaliteit tot modelleringstools.
Mevrouw Knight leidt ons door een inleiding tot databaseontwerp. Haar artikel is interessant omdat het de nadruk legt op databases voor webontwikkeling. Toch zijn haar punten redelijk universeel en kunnen ze in veel situaties worden toegepast op databaseontwerp.
Het artikel begint met ons te vragen om breed na te denken over functionaliteit, niet alleen over de database:
Denk buiten de database. Probeer na te denken over wat de website moet doen. Als er bijvoorbeeld een lidmaatschapswebsite nodig is, kan het eerste instinct zijn om te denken aan alle gegevens die elke gebruiker moet opslaan. Vergeet het maar, dat is voor later. Schrijf liever op dat gebruikers en hun informatie in de database moeten worden opgeslagen, en wat nog meer? Wat moeten die leden doen op de site? Zullen ze berichten plaatsen, bestanden of foto's uploaden of berichten verzenden? Dan heeft de database een plek nodig voor bestanden/foto's, berichten en berichten.Van daaruit neemt mevrouw Knight de lezer mee in de hulpmiddelen voor het ontwerpen van databases en de stappen die bij het proces betrokken zijn. Haar artikel geeft voorbeelden en links naar andere bronnen.
Ik denk dat dit artikel een geweldige introductie zou zijn voor beginnende databaseontwerpers, en het zou goed moeten werken met de Geek Girl's serie.
Tips voor databaseontwerp verkennen
door Doug Lowe | Voor dummies
De lijst met "Dummies" van Mr. Lowe is een brede reeks basisontwerptips. Je kunt veel van deze elders vinden, maar het is handig om ze op één plek te hebben. U zult niets unieks of zeer controversieel vinden, behalve een aanbeveling om opgeslagen procedures te gebruiken. Ik twijfel altijd aan deze sterke uitspraak, omdat ik me grote zorgen maak over de overdraagbaarheid van datamodellen voor meerdere DBM-systemen.
Hier is een van Mr. Lowe's gezond verstand tips:
Vermijd velden met namen zoals CustomerType, waarbij de waarde van het veld een van de constanten is die niet elders in de database zijn gedefinieerd, zoals R voor Retail of W voor Wholesale. U hebt vandaag misschien alleen deze twee soorten klanten, maar de behoeften van de toepassing kunnen in de toekomst veranderen, waardoor een derde klanttype nodig is.Deze aanbevelingen zijn het meest geschikt bij het werken met SQL Server.
Vijf eenvoudige tips voor het ontwerpen van databases
door Lamont Adams | TechRepublic | 25 juni 2001
Het sleutelwoord voor deze bron is "eenvoudig". U vindt deze informatie, met meer uitleg en voorbeelden, in andere artikelen.
Het advies van de heer Adams om "de sleutels van de gebruiker weg te nemen" is echter een interessant punt, dat op andere plaatsen zelden wordt genoemd. Hij vervolgt:
Wanneer u beslist welk veld of welke velden u als sleutel in een tabel wilt gebruiken, moet u altijd rekening houden met de velden die gebruikers gaan bewerken. Het is meestal een slecht idee om een door de gebruiker bewerkbaar veld als sleutel te kiezen.De bedoeling van de heer Adams is dat u rekening moet houden met de potentiële vereiste van de gebruiker om velden te bewerken wanneer u beslist welke velden als sleutels moeten worden gebruikt. Ik had graag meer uitleg gehad over alternatieven, zoals synthetische/gegenereerde sleutels, maar het concept is goed.
Met het laatste punt was ik het niet eens. Hij beveelt een "fudge-factor" aan voor elke tafel die je ontwerpt:
Niets is erger dan te ontdekken, of geïnformeerd te worden, dat uw "voltooide" database een veld mist voor een cruciaal stuk informatie. Bij een bedrijf waar ik voor werkte, kwam dit zo vaak voor dat we "databases vastgelopen" begonnen te noemen als "database-slushes".In mijn gedachten is dit eigenlijk "een paar extra tekstvelden aan het einde toevoegen". Dit lijkt in tegenspraak met enkele van de andere tips van de heer Adams, met name die met betrekking tot het begrijpen van zakelijke behoeften en het gebruik van zinvolle namen. Deze extra fudge-velden zouden gewoon zoiets als "extra1" of "extra2" worden genoemd. Wat is hun zakelijke behoefte? En hoe zijn deze betekenisvolle namen? Hoewel ik de meeste van zijn ontwerptips leuk vind, is deze "fudge-factor" niet iets waar ik me aan houd.
Databaseontwerp:eervolle vermeldingen
Uiteraard zijn er andere artikelen die tips en best practices voor databaseontwerp beschrijven. U kunt aanvullend materiaal vinden via de volgende links:
Relationeel databaseontwerp:een best practices-primer | door Digital Ethos | 24 december 2012
Best practices voor het ontwerpen van databaseschema's (beginners) | door Jim Murphy | 28 maart 2011
IT-best practices:databaseontwerp | door de Universiteit van Nebraska-Lincoln
Online databaseontwerpbronnen:waar zou je heen gaan?
Zoals gezegd, is deze lijst zeker niet bedoeld als een uitputtend onderzoek van elk databaseontwerpartikel op internet. In plaats daarvan hebben we verschillende artikelen geïdentificeerd waarvan we denken dat ze nuttig zijn of die een bepaalde focus hebben die u misschien nuttig vindt.
Voel je vrij om aanvullende artikelen aan te bevelen.