Ik schreef onlangs een bericht over DISTINCT en GROUP BY. Het was een vergelijking die aantoonde dat GROUP BY over het algemeen een betere optie is dan DISTINCT. Het staat op een andere site, maar kom later zeker terug naar sqlperformance.com..
Een van de queryvergelijkingen die ik in dat bericht liet zien, was tussen een GROUP BY en DISTINCT voor een subquery, wat aantoont dat de DISTINCT een stuk langzamer is, omdat het de productnaam voor elke rij in de Sales-tabel moet ophalen, in plaats van dan alleen voor elke verschillende ProductID. Dit blijkt vrij duidelijk uit de queryplannen, waar je kunt zien dat in de eerste query het aggregaat werkt op gegevens uit slechts één tabel, in plaats van op de resultaten van de join. Oh, en beide zoekopdrachten geven dezelfde 266 rijen.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID;
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od;

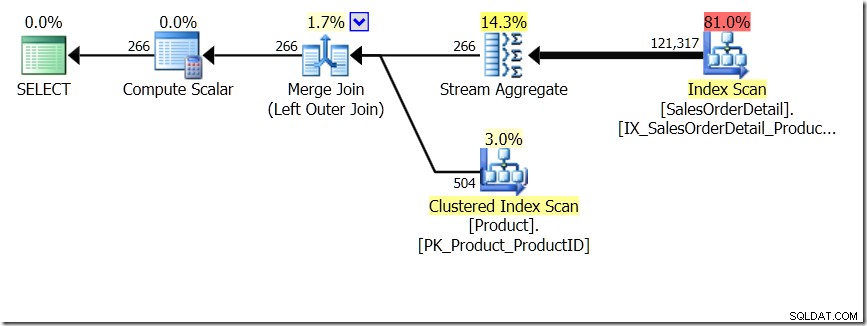
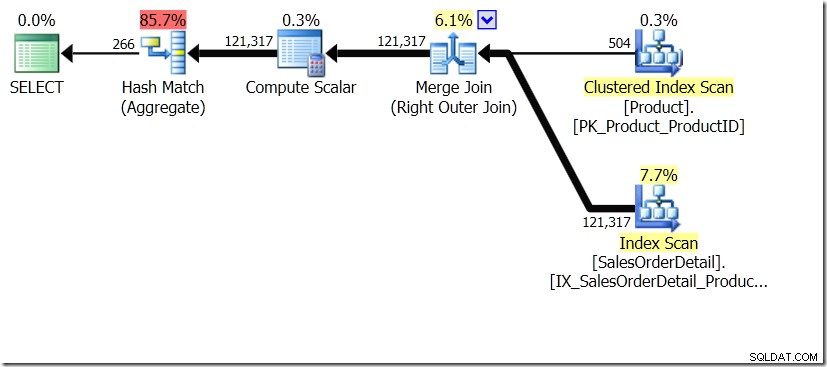
Nu is er op gewezen, onder meer door Adam Machanic (@adammachanic) in een tweet die verwijst naar Aarons post over GROUP BY v DISTINCT dat de twee zoekopdrachten wezenlijk verschillend zijn, dat men eigenlijk vraagt om de reeks verschillende combinaties van de resultaten van de subquery, in plaats van de subquery uit te voeren over de verschillende waarden die worden doorgegeven. Dit is wat we zien in het plan en is de reden waarom de prestaties zo verschillend zijn.
Het punt is dat we allemaal aannemen dat de resultaten identiek zullen zijn.
Maar dat is een aanname en geen goede.
Ik ga me even voorstellen dat de Query Optimizer een ander plan heeft bedacht. Ik heb hiervoor hints gebruikt, maar zoals je weet, kan de Query Optimizer ervoor kiezen om om allerlei redenen plannen te maken in allerlei vormen.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID
option (loop join);
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
option (loop join);
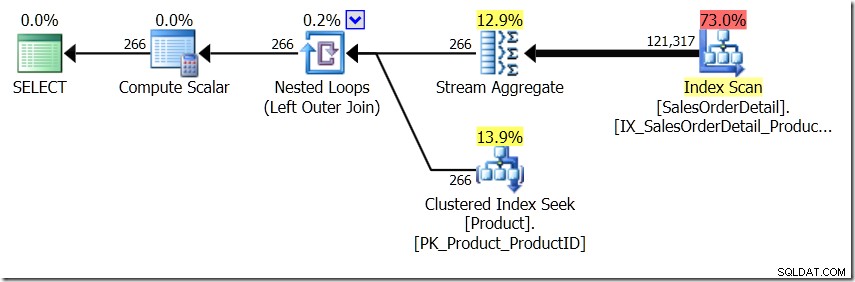
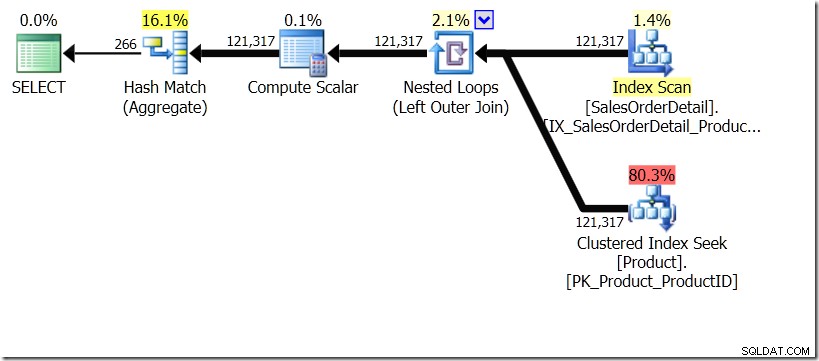
In deze situatie voeren we ofwel 266 Zoekopdrachten uit in de tabel Product, één voor elke verschillende Product-ID waarin we geïnteresseerd zijn, of 121.317 Zoekopdrachten. Dus als we aan een bepaalde ProductID denken, weten we dat we een enkele naam terugkrijgen van de eerste. En we gaan ervan uit dat we een enkele Naam terugkrijgen voor die ProductID, zelfs als we er honderd keer om moeten vragen. We gaan er gewoon van uit dat we dezelfde resultaten terugkrijgen.
Maar wat als we dat niet doen?
Dit klinkt als een isolatieniveau-ding, dus laten we NOLOCK gebruiken wanneer we naar de Product-tabel gaan. En laten we (in een ander venster) een script uitvoeren om de tekst in de Naam-kolommen te wijzigen. Ik ga het keer op keer doen, om te proberen enkele van de wijzigingen tussen mijn query door te krijgen.
update Production.Product set Name = cast(newid() as varchar(36)); go 1000
Nu zijn mijn resultaten anders. De plannen zijn hetzelfde (behalve het aantal rijen dat uit de Hash Aggregate komt in de tweede zoekopdracht), maar mijn resultaten zijn anders.
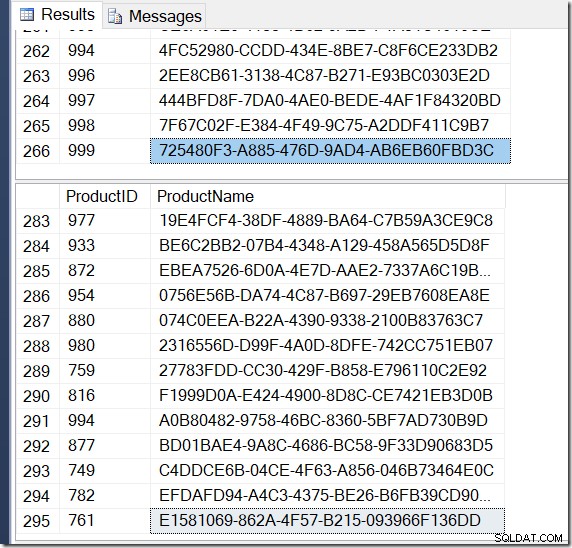
En ja hoor, ik heb meer rijen met DISTINCT, omdat het verschillende Name-waarden vindt voor dezelfde ProductID. En ik heb niet per se 295 rijen. Als ik het nog een keer uitvoer, krijg ik misschien 273, of 300, of mogelijk 121.317.
Het is niet moeilijk om een voorbeeld te vinden van een ProductID die meerdere Name-waarden toont, wat bevestigt wat er aan de hand is.

Om er zeker van te zijn dat we deze rijen niet in de resultaten zien, moeten we ofwel GEEN DISTINCT gebruiken, ofwel een strikter isolatieniveau gebruiken.
Het punt is dat hoewel ik noemde het gebruik van NOLOCK voor dit voorbeeld, ik dat niet nodig had. Deze situatie doet zich zelfs voor met READ COMMITTED, het standaard isolatieniveau op veel SQL Server-systemen.
U ziet, we hebben het REPEATABLE READ-isolatieniveau nodig om deze situatie te voorkomen, om de vergrendelingen op elke rij vast te houden nadat deze is gelezen. Anders zou een aparte thread de gegevens kunnen veranderen, zoals we zagen.
Maar... ik kan je niet laten zien dat de resultaten zijn opgelost, omdat ik er niet in slaagde om een impasse in de zoekopdracht te voorkomen.
Dus laten we de voorwaarden veranderen, door ervoor te zorgen dat onze andere vraag minder een probleem is. In plaats van de hele tabel tegelijk bij te werken (wat sowieso veel minder waarschijnlijk is in de echte wereld), laten we een enkele rij tegelijk bijwerken.
declare @id int = 1; declare @maxid int = (select count(*) from Production.Product); while (@id < @maxid) begin with p as (select *, row_number() over (order by ProductID) as rn from Production.Product) update p set Name = cast(newid() as varchar(36)) where rn = @id; set @id += 1; end go 100
Nu kunnen we het probleem nog steeds aantonen onder een lager isolatieniveau, zoals READ COMMITTED of READ UNCOMMITTED (hoewel u de query mogelijk meerdere keren moet uitvoeren als u de eerste keer 266 krijgt, omdat de kans dat een rij wordt bijgewerkt tijdens de query is minder), en nu kunnen we aantonen dat REPEATABLE READ dit oplost (ongeacht hoe vaak we de query uitvoeren).
HERHAALBAAR LEZEN doet wat het zegt op het blik. Zodra u een rij binnen een transactie leest, wordt deze vergrendeld om ervoor te zorgen dat u de lezing kunt herhalen en dezelfde resultaten kunt krijgen. De lagere isolatieniveaus verwijderen die vergrendelingen niet totdat u probeert de gegevens te wijzigen. Als uw queryplan nooit een lezing hoeft te herhalen (zoals het geval is met de vorm van onze GROUP BY-plannen), dan heeft u geen HERHAALBAAR LEZEN nodig.
We zouden waarschijnlijk altijd de hogere isolatieniveaus moeten gebruiken, zoals HERHAALBAAR LEZEN of SERIALISEERBAAR, maar het komt allemaal neer op uitzoeken wat onze systemen nodig hebben. Deze niveaus kunnen ongewenste vergrendeling introduceren, en SNAPSHOT-isolatieniveaus vereisen versiebeheer die ook een prijs heeft. Voor mij is het een afweging. Als ik om een vraag vraag die kan worden beïnvloed door het wijzigen van gegevens, moet ik mogelijk het isolatieniveau een tijdje verhogen.
In het ideale geval werkt u gegevens die zojuist zijn gelezen en mogelijk opnieuw moeten worden gelezen tijdens de query gewoon niet bij, zodat u HERHAALBAAR LEZEN niet nodig hebt. Maar het is zeker de moeite waard om te begrijpen wat er kan gebeuren en te erkennen dat dit het soort scenario is waarin DISTINCT en GROUP BY misschien niet hetzelfde zijn.
@rob_farley