Dit bericht maakt deel uit van een serie over rijdoelen. De andere onderdelen vind je hier:
- Deel 1:Rijdoelen stellen en identificeren
- Deel 2:Semi-joins
- Deel 3:Anti-joins
Anti-join toepassen met een topoperator
U zult vaak een binnenste Top (1)-operator zien in anti-join toepassen uitvoeringsplannen. Gebruik bijvoorbeeld de AdventureWorks-database:
SELECT P.ProductID
FROM Production.Product AS P
WHERE
NOT EXISTS
(
SELECT 1
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
); Het plan toont een Top (1) operator aan de binnenkant van de toepassing (buitenste referenties) anti-join:
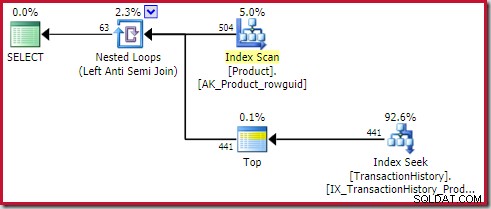
Deze Top-operator is volledig overbodig . Het is niet vereist voor correctheid, efficiëntie of om ervoor te zorgen dat een rijdoel is ingesteld.
De operator anti-join toepassen stopt met het controleren op rijen aan de binnenkant (voor de huidige iteratie) zodra er één rij bij de join wordt gezien. Het is perfect mogelijk om een anti-joint plan te genereren zonder de Top. Dus waarom is er een Top-operator in dit plan?
Bron van de Top-operator
Om te begrijpen waar deze zinloze Top-operator vandaan komt, moeten we de belangrijkste stappen volgen die zijn genomen tijdens de compilatie en optimalisatie van onze voorbeeldquery.
Zoals gebruikelijk wordt de query eerst ontleed in een boomstructuur. Deze bevat een logische 'bestaat niet'-operator met een subquery, die in dit geval nauw overeenkomt met de geschreven vorm van de query:

De subquery die niet bestaat wordt uitgerold in een anti-join toepassen:

Dit wordt dan verder omgezet in een logische linker anti semi-join. De resulterende boom die wordt doorgegeven aan optimalisatie op basis van kosten ziet er als volgt uit:

De eerste verkenning die door de op kosten gebaseerde optimalisatie is uitgevoerd, is het introduceren van een logisch onderscheid bewerking op de onderste anti-join-invoer, om unieke waarden voor de anti-join-sleutel te produceren. Het algemene idee is dat in plaats van dubbele waarden te testen bij de join, het plan er baat bij kan hebben deze waarden vooraf te groeperen.
De verantwoordelijke verkenningsregel heet LASJNtoLASJNonDist (links anti semi join naar links anti semi join op apart). Er is nog geen fysieke implementatie of kostprijsberekening uitgevoerd, dus dit is slechts de optimizer die een logische equivalentie verkent, gebaseerd op de aanwezigheid van dubbele ProductID waarden. De nieuwe boom met de toegevoegde groepering wordt hieronder getoond:

De volgende logische transformatie die wordt overwogen, is om de join te herschrijven als een apply . Dit wordt onderzocht met de regel LASJNtoApply (linker anti semi-join om toe te passen bij relationele selectie). Zoals eerder in de serie vermeld, was de eerdere transformatie van Apply naar Join om transformaties mogelijk te maken die specifiek op joins werken. Het is altijd mogelijk om een join te herschrijven als een toepassing, dus dit vergroot het bereik van beschikbare optimalisaties.
Nu doet de optimizer niet altijd overweeg een herschrijving van toepassing te vinden als onderdeel van op kosten gebaseerde optimalisatie. Er moet iets in de logische boom zitten om het de moeite waard te maken om het join-predikaat aan de binnenkant naar beneden te duwen. Meestal zal dit het bestaan van een matching-index zijn, maar er zijn andere veelbelovende doelen. In dit geval is het de logische sleutel op ProductID gemaakt door de aggregatiebewerking.
Het resultaat van deze regel is een gecorreleerde anti-join met selectie aan de binnenkant:

Vervolgens overweegt de optimizer om de relationele selectie (het gecorreleerde join-predikaat) verder naar beneden te verplaatsen, voorbij de distinct (groep per aggregaat) die eerder door de optimizer is geïntroduceerd. Dit wordt gedaan door regel SelOnGbAgg , die zoveel mogelijk van een selectie (predikaat) langs een geschikte groep per aggregaat beweegt (een deel van de selectie kan achterblijven). Deze activiteit helpt selecties te pushen zo dicht mogelijk bij de operators voor gegevenstoegang op leaf-niveau, om rijen eerder te elimineren en het later gemakkelijker maken van indexen.
In dit geval bevindt het filter zich in dezelfde kolom als de groeperingsbewerking, dus de transformatie is geldig. Het resulteert erin dat de hele selectie onder het aggregaat wordt geduwd:

De laatste bewerking van belang wordt uitgevoerd door regel GbAggToConstScanOrTop . Deze transformatie lijkt vervangen een groep op aggregaat met een Constant Scan of Top logische operatie. Deze regel komt overeen met onze boomstructuur omdat de groeperingskolom constant is voor elke rij die door de ingedrukte selectie gaat. Alle rijen hebben gegarandeerd dezelfde ProductID . Groeperen op die enkele waarde levert altijd één rij op. Daarom is het geldig om het aggregaat te transformeren naar een Top (1). Dus hier komt de top vandaan.
Implementatie en kostprijsberekening
De optimizer voert nu een reeks implementatieregels uit om fysieke operators te vinden voor elk van de veelbelovende logische alternatieven die het tot nu toe heeft overwogen (efficiënt opgeslagen in een memostructuur). Hash en merge anti-join fysieke opties komen uit de initiële boom met geïntroduceerde aggregaat (met dank aan regel LASJNtoLASJNonDist onthouden). De sollicitatie heeft wat meer werk nodig om een fysieke top op te bouwen en de selectie te matchen met een indexzoekopdracht.
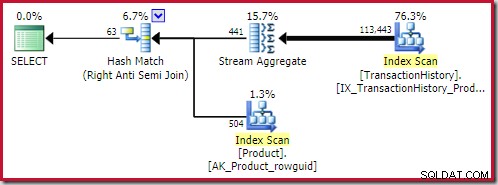
De beste hash anti-join gevonden oplossing kost 0.362143 eenheden:
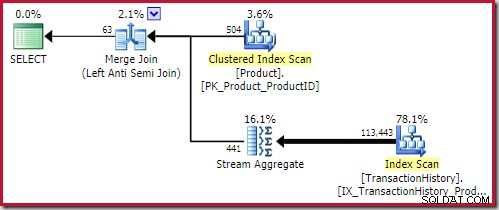
De beste samenvoeg anti-join oplossing komt binnen op 0.353479 eenheden (iets goedkoper):
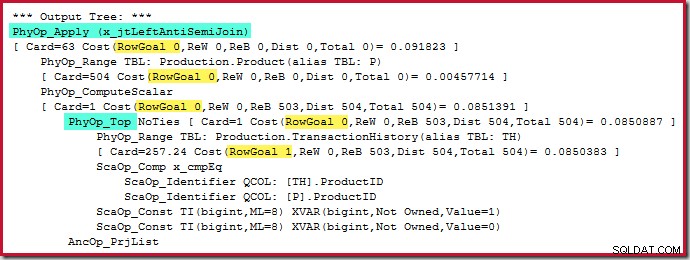
De anti-join toepassen kost 0,091823 eenheden (met een ruime marge het goedkoopst):
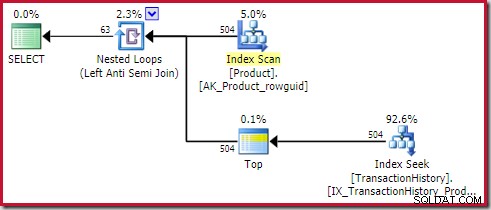
De oplettende lezer kan opmerken dat het aantal rijen aan de binnenkant van de anti-join toepassen (504) verschillen van de vorige schermafbeelding van hetzelfde plan. Dit komt omdat dit een geschat plan is, terwijl het vorige plan na de uitvoering was. Wanneer dit plan wordt uitgevoerd, zijn er over alle iteraties slechts in totaal 441 rijen aan de binnenkant te vinden. Dit wijst op een van de weergaveproblemen bij het toepassen van semi/anti-join-plannen:de minimale optimalisatieschatting is één rij, maar een semi- of anti-join zal altijd één rij of geen rijen op elke iteratie lokaliseren. De 504 rijen die hierboven worden weergegeven, vertegenwoordigen 1 rij op elk van de 504 iteraties. Om ervoor te zorgen dat de getallen overeenkomen, moet de schatting elke keer 441/504 =0,875 rijen zijn, wat mensen waarschijnlijk net zo in verwarring zou brengen.
Hoe dan ook, het bovenstaande plan is 'gelukkig' genoeg om zich te kwalificeren voor een row-goal aan de binnenkant van de 'anti-join' toepassen om twee redenen:
- De anti-join wordt getransformeerd van een join naar een toepassing in de cost-based optimizer. Dit stelt een rijdoel vast (zoals vastgesteld in deel drie).
- De operator Top(1) stelt ook een rijdoel in op zijn substructuur.
De Top-operator zelf heeft geen rijdoel (van toepassing) aangezien het rijdoel van 1 niet minder zou zijn dan de normale schatting, die ook 1 rij is (Card=1 voor de PhyOp_Top hieronder):
Het Anti Join Anti-patroon
De volgende algemene plattegrondvorm beschouw ik als een antipatroon:
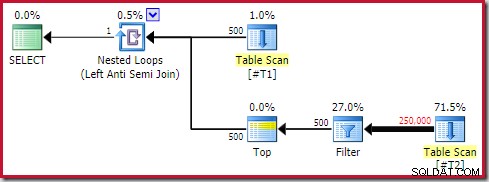
Niet elk uitvoeringsplan met een toepassing van een anti-join met een Top (1)-operator aan de binnenkant zal problematisch zijn. Desalniettemin is het een patroon om te herkennen en een die bijna altijd nader onderzoek vereist.
De vier belangrijkste elementen om op te letten zijn:
- Een gecorreleerde geneste lus (toepassen ) anti-join
- Een Top (1) operator direct aan de binnenkant
- Een aanzienlijk aantal rijen op de buitenste invoer (dus de binnenkant zal vele malen worden uitgevoerd)
- Een mogelijk dure subboom onder de Top
De substructuur "$$$" is er een die mogelijk duur is tijdens runtime . Dit kan moeilijk te herkennen zijn. Als we geluk hebben, is er iets voor de hand liggend, zoals een volledige tabel of indexscan. In meer uitdagende gevallen zal de subboom er op het eerste gezicht volkomen onschuldig uitzien, maar bij nader inzien iets kostbaars bevatten. Om een vrij algemeen voorbeeld te geven:u ziet mogelijk een indexzoekopdracht waarvan wordt verwacht dat deze een klein aantal rijen retourneert, maar die een duur restpredikaat bevat dat een zeer groot aantal rijen test om de weinige rijen te vinden die in aanmerking komen.
Het voorgaande codevoorbeeld van AdventureWorks had geen "potentieel dure" substructuur. De Index Seek (zonder restpredikaat) zou een optimale toegangsmethode zijn, ongeacht de overwegingen van rijdoelen. Dit is een belangrijk punt:de optimizer voorzien van een altijd efficiënte gegevenstoegangspad aan de binnenkant van een gecorreleerde join is altijd een goed idee. Dit geldt des te meer wanneer de applicatie in de anti-join-modus draait met een Top (1)-operator aan de binnenkant.
Laten we nu eens kijken naar een voorbeeld met behoorlijk sombere runtime-prestaties vanwege dit antipatroon.
Voorbeeld
Met het volgende script worden twee tijdelijke heaptabellen gemaakt. De eerste heeft 500 rijen met de gehele getallen van 1 tot en met 500. De tweede tabel heeft 500 exemplaren van elke rij in de eerste tabel, voor een totaal van 250.000 rijen. Beide tabellen gebruiken de sql_variant gegevenstype.
DROP TABLE IF EXISTS #T1, #T2;
CREATE TABLE #T1 (c1 sql_variant NOT NULL);
CREATE TABLE #T2 (c1 sql_variant NOT NULL);
-- Numbers 1 to 500 inclusive
-- Stored as sql_variant
INSERT #T1
(c1)
SELECT
CONVERT(sql_variant, SV.number)
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 500;
-- 500 copies of each row in table #T1
INSERT #T2
(c1)
SELECT
T1.c1
FROM #T1 AS T1
CROSS JOIN #T1 AS T2;
-- Ensure we have the best statistical information possible
CREATE STATISTICS sc1 ON #T1 (c1) WITH FULLSCAN, MAXDOP = 1;
CREATE STATISTICS sc1 ON #T2 (c1) WITH FULLSCAN, MAXDOP = 1; Prestaties
We voeren nu een query uit op zoek naar rijen in de kleinere tabel die niet aanwezig zijn in de grotere tabel (natuurlijk zijn er geen):
SELECT
T1.c1
FROM #T1 AS T1
WHERE
NOT EXISTS
(
SELECT 1
FROM #T2 AS T2
WHERE T2.c1 = T1.c1
); Deze zoekopdracht duurt ongeveer 20 seconden , wat ontzettend lang is om 500 rijen te vergelijken met 250.000. Het geschatte SSMS-plan maakt het moeilijk in te zien waarom de prestaties zo slecht zijn:
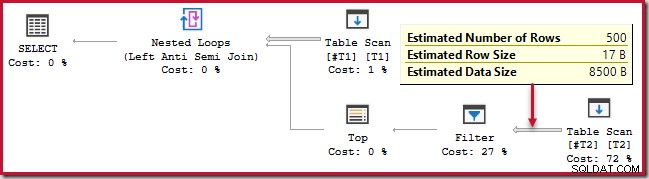
De waarnemer moet zich ervan bewust zijn dat SSMS geschatte plannen binnenzijde schattingen tonen per iteratie van de geneste lusverbinding. Verwarrend genoeg tonen de werkelijke SSMS-plannen het aantal rijen over alle iteraties . Planverkenner voert automatisch de eenvoudige berekeningen uit die nodig zijn voor geschatte plannen om ook het totale aantal verwachte rijen te tonen:
Toch zijn de runtime-prestaties veel slechter dan geschat. Het (werkelijke) uitvoeringsplan na de uitvoering is:
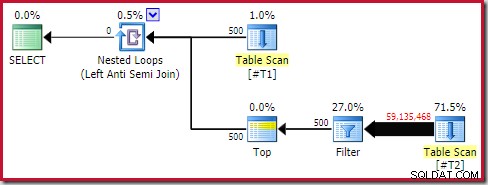
Let op het afzonderlijke filter, dat normaal gesproken als een resterend predikaat in de scan wordt geduwd. Dit is de reden voor het gebruik van de sql_variant data type; het voorkomt dat het predikaat wordt gepusht, waardoor het enorme aantal rijen uit de scan gemakkelijker te zien is.
Analyse
De reden voor de discrepantie komt neer op hoe de optimizer het aantal rijen schat dat het uit de tabelscan moet lezen om te voldoen aan het doel van één rij dat bij het filter is ingesteld. De simpele veronderstelling is dat waarden uniform zijn verdeeld in de tabel, dus om 1 van de 500 unieke waarden te vinden die aanwezig zijn, moet SQL Server 250.000 / 500 =500 rijen lezen. Meer dan 500 iteraties, dat komt neer op 250.000 rijen.
De uniformiteitsaanname van de optimizer is algemeen, maar werkt hier niet goed. Je kunt hier meer over lezen in A Row Goal Request van Joe Obbish, en stemmen op zijn suggestie op het Connect vervangingsfeedbackforum op Use More Than Density to Cost a Scan on the inner Side of a Nested Loop with TOP.
Mijn mening over dit specifieke aspect is dat de optimizer snel moet afstappen van een eenvoudige uniformiteitsaanname wanneer de operator zich aan de binnenzijde van een geneste lusverbinding bevindt (d.w.z. de geschatte terugspoeling plus rebinds is groter dan één). Het is één ding om aan te nemen dat we 500 rijen moeten lezen om een overeenkomst te vinden in de eerste iteratie van de lus. Om dit bij elke iteratie aan te nemen, lijkt het erg onwaarschijnlijk dat dit juist is; dit betekent dat de eerste 500 gevonden rijen een van elke afzonderlijke waarde moeten bevatten. In de praktijk is dit hoogst onwaarschijnlijk.
Een reeks ongelukkige gebeurtenissen
Ongeacht de manier waarop herhaalde Top-operators worden gekost, het lijkt mij dat de hele situatie in de eerste plaats moet worden vermeden . Bedenk hoe de Top in dit plan is gemaakt:
- De optimizer introduceerde een aan de binnenzijde onderscheiden aggregaat als prestatie-optimalisatie .
- Dit aggregaat biedt per definitie een sleutel in de join-kolom (het produceert uniciteit).
- Deze geconstrueerde sleutel biedt een doel voor de conversie van een join naar een apply.
- Het predikaat (selectie) dat aan de toepassing is gekoppeld, wordt voorbij het aggregaat gedrukt.
- Het aggregaat werkt nu gegarandeerd op één afzonderlijke waarde per iteratie (omdat het een correlatiewaarde is).
- Het aggregaat wordt vervangen door een Top (1).
Al deze transformaties zijn afzonderlijk geldig. Ze maken deel uit van de normale optimalisatiebewerkingen omdat er wordt gezocht naar een redelijk uitvoeringsplan. Helaas is de uitkomst hier dat het speculatieve aggregaat dat door de optimizer is geïntroduceerd, uiteindelijk wordt omgezet in een Top (1) met een bijbehorend rijdoel . Het rijdoel leidt tot onnauwkeurige kostenberekening op basis van de uniformiteitsaanname, en vervolgens tot de selectie van een plan waarvan het zeer onwaarschijnlijk is dat het goed zal presteren.
Nu zou men kunnen tegenwerpen dat het toepassen van anti-join toch een rijdoel zou hebben - zonder de bovenstaande transformatievolgorde. Het tegenargument is dat de optimizer niet zou overwegen transformatie van anti-join naar toepassen anti join (het rijdoel instellen) zonder het door de optimizer geïntroduceerde aggregaat dat de LASJNtoApply geeft regel iets om aan te binden. Daarnaast hebben we gezien (in deel drie) dat als de anti-join op kosten gebaseerde optimalisatie was ingevoerd als een toepassing (in plaats van een samenvoeging), er opnieuw geen rijdoel zou zijn. .
Kortom, het rijdoel in het uiteindelijke plan is volledig kunstmatig en heeft geen basis in de oorspronkelijke queryspecificatie. Het probleem met het doel Top en rij is een neveneffect van dit meer fundamentele aspect.
Oplossingen
Er zijn veel mogelijke oplossingen voor dit probleem. Als u een van de stappen in de bovenstaande optimalisatievolgorde verwijdert, zorgt u ervoor dat de optimizer geen toepassingsanti-join-implementatie produceert met drastisch (en kunstmatig) lagere kosten. Hopelijk wordt dit probleem eerder vroeger dan later opgelost in SQL Server.
In de tussentijd is mijn advies om op te passen voor het anti-join anti-patroon. Zorg ervoor dat de binnenkant van een toepassings-anti-join altijd een efficiënt toegangspad heeft voor alle runtime-omstandigheden. Als dit niet mogelijk is, moet u wellicht hints gebruiken, rijdoelen uitschakelen, een plangids gebruiken of een querystore-plan afdwingen om stabiele prestaties te krijgen van anti-joinquery's.
Seriesamenvatting
We hebben in de vier afleveringen veel besproken, dus hier is een samenvatting op hoog niveau:
- Deel 1 – Rijdoelen stellen en identificeren
- Querysyntaxis bepaalt niet de aanwezigheid of afwezigheid van een rijdoel.
- Een rijdoel wordt alleen ingesteld als het doel lager is dan de normale schatting.
- Fysieke Top-operators (inclusief die geïntroduceerd door de optimizer) voegen een rijdoel toe aan hun substructuur.
- Een
FASTofSET ROWCOUNTstatement stelt een rijdoel aan de basis van het plan. - Semi-join en anti-join mei voeg een rijdoel toe.
- SQL Server 2017 CU3 voegt het showplan-kenmerk toe EstimateRowsWithoutRowGoal voor operators die worden beïnvloed door een rijdoel
- Informatie over rijdoelen kan worden onthuld door ongedocumenteerde traceervlaggen 8607 en 8612.
- Deel 2 – Semi-joins
- Het is niet mogelijk om een semi-join direct in T-SQL uit te drukken, dus gebruiken we indirecte syntaxis, b.v.
IN,EXISTS, ofINTERSECT. - Deze syntaxis worden geparseerd in een boomstructuur die een toepassing (gecorreleerde join) bevat.
- De optimizer probeert de toepassing om te zetten in een reguliere join (niet altijd mogelijk).
- Hash, merge en reguliere geneste loops semi-join stellen geen rijdoel in.
- Semi-join toepassen stelt altijd een rijdoel in.
- Semi-join toepassen is te herkennen aan de externe verwijzingen op de join-operator voor geneste lussen.
- Semi-joint toepassen gebruikt geen Bovenste (1)-operator aan de binnenkant.
- Deel 3 – Anti-joins
- Ook geparseerd in een toepassing, met een poging om dat te herschrijven als een join (niet altijd mogelijk).
- Hash, merge en reguliere geneste loops anti-join stellen geen rijdoel in.
- Anti-join toepassen stelt niet altijd een rijdoel vast.
- Alleen regels voor optimalisatie op basis van kosten (CBO) die anti-join transformeren om een rijdoel toe te passen.
- De anti-join moet CBO invoeren als een join (niet van toepassing). Anders kan de join om transformatie toe te passen niet plaatsvinden.
- Om CBO als join in te voeren, moet de pre-CBO-herschrijving van Apply naar Join zijn geslaagd.
- CBO onderzoekt alleen het herschrijven van een anti-join naar een aanvraag in veelbelovende gevallen.
- Pre-CBO-vereenvoudigingen kunnen worden bekeken met ongedocumenteerde traceervlag 8621.
- Deel 4 – Anti-join anti-patroon
- De optimizer stelt alleen een rijdoel in voor het toepassen van anti-join als daar een veelbelovende reden voor is.
- Helaas voegen meerdere interacterende optimalisatietransformaties een Top (1)-operator toe aan de binnenkant van een anti-join toepassen.
- De Top-operator is overbodig; het is niet vereist voor correctheid of efficiëntie.
- De Top stelt altijd een rijdoel vast (in tegenstelling tot het solliciteren, waarvoor een goede reden nodig is).
- Het ongerechtvaardigde rijdoel kan leiden tot extreem slechte prestaties.
- Pas op voor een potentieel dure onderboom onder de kunstmatige Top (1).