Dataprofessionals maken niet altijd gebruik van databases met een optimaal ontwerp. Soms zijn de dingen die je aan het huilen maken dingen die we onszelf hebben aangedaan, omdat het op dat moment goede ideeën leken. Soms zijn ze vanwege toepassingen van derden. Soms zijn ze gewoon ouder dan jij.
Degene waar ik aan denk in dit bericht is wanneer je datetime (of datetime2 of beter nog, datetimeoffset) kolom eigenlijk twee kolommen is - één voor de datum en één voor de tijd. (Als je weer een aparte kolom hebt voor de offset, dan zal ik je de volgende keer dat ik je zie een knuffel geven, want je hebt waarschijnlijk met allerlei soorten pijn te maken gehad.)
Ik deed een enquête op Twitter en ontdekte dat dit een heel reëel probleem is dat ongeveer de helft van jullie van tijd tot tijd met datum en tijd te maken heeft.
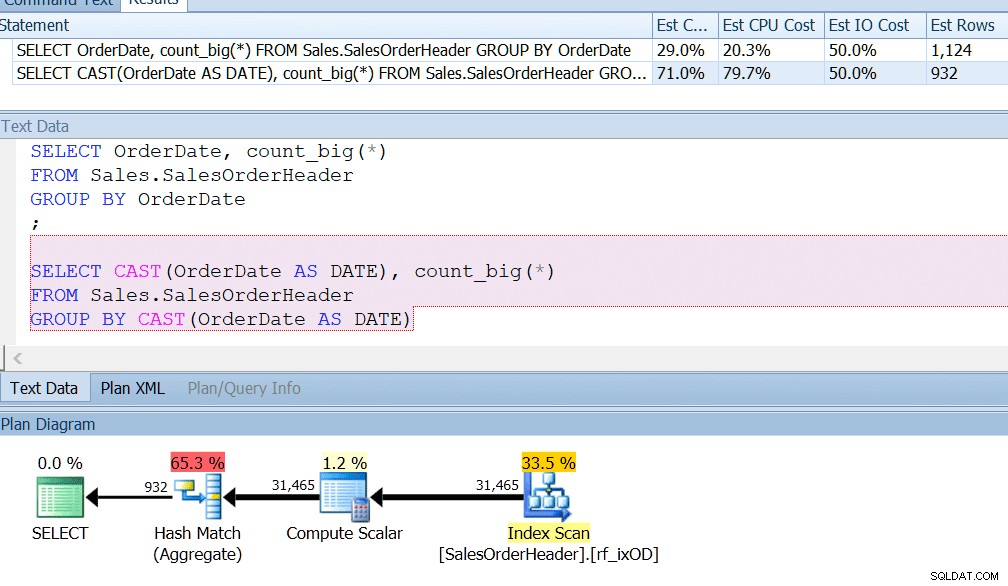
AdventureWorks doet dit bijna - als u in de tabel Sales.SalesOrderHeader kijkt, ziet u een datetime-kolom met de naam OrderDate, die altijd exacte datums bevat. Ik wed dat als je een rapportontwikkelaar bent bij AdventureWorks, je waarschijnlijk vragen hebt geschreven die zoeken naar het aantal bestellingen op een bepaalde dag, met behulp van GROUP BY OrderDate, of iets dergelijks. Zelfs als je wist dat dit een datetime-kolom was en het potentieel had om ook een tijd buiten middernacht op te slaan, zou je nog steeds GROUP BY OrderDate zeggen, alleen maar om een index correct te gebruiken. GROUP BY CAST (OrderDate AS DATE) voldoet gewoon niet.
Ik heb een index op de OrderDate, zoals je zou doen als je die kolom regelmatig zou opvragen, en ik kan zien dat groepering op CAST (OrderDate AS DATE) ongeveer vier keer slechter is vanuit een CPU-perspectief.
Dus ik begrijp waarom je graag je column zou willen bevragen alsof het een datum is, gewoon wetende dat je een wereld van pijn zult hebben als het gebruik van die kolom verandert. Misschien los je dit op door een beperking op tafel te leggen. Misschien steek je gewoon je kop in het zand.
En wanneer iemand langskomt en zegt:"Weet je, we moeten ook de tijd opslaan dat bestellingen plaatsvinden", denk dan aan alle code die aanneemt dat OrderDate gewoon een datum is, en bedenk dat je een aparte kolom hebt met de naam OrderTime (gegevenstype van tijd, alstublieft) de meest verstandige optie is. Ik begrijp. Het is niet ideaal, maar het werkt zonder al te veel dingen kapot te maken.
Op dit moment raad ik u aan om OrderDateTime te maken, wat een berekende kolom zou zijn die de twee verbindt (wat u zou moeten doen door het aantal dagen sinds dag 0 toe te voegen aan CAST (OrderDate als datetime2), in plaats van te proberen de tijd toe te voegen aan datum, die over het algemeen een stuk rommeliger is). En index dan OrderDateTime, want dat zou verstandig zijn.
Maar heel vaak zul je merken dat je datum en tijd als afzonderlijke kolommen hebt, met in principe niets dat je eraan kunt doen. U kunt geen berekende kolom toevoegen, omdat het een toepassing van derden is en u niet weet wat er zou kunnen breken. Weet je zeker dat ze nooit SELECT * doen? Op een dag hoop ik dat ze ons kolommen laten toevoegen en verbergen, maar voorlopig loop je zeker het risico dingen te breken.
En weet je, zelfs msdb doet dit. Het zijn beide gehele getallen. En het is vanwege achterwaartse compatibiliteit, neem ik aan. Maar ik betwijfel of je overweegt een berekende kolom toe te voegen aan een tabel in msdb.
Dus hoe vragen we dit? Laten we aannemen dat we de vermeldingen willen vinden die binnen een bepaald datum/tijdbereik vielen?
Laten we wat experimenteren.
Laten we eerst een tabel maken met 3 miljoen rijen en de kolommen indexeren waar we om geven.
select identity(int,1,1) as ID, OrderDate,
dateadd(minute, abs(checksum(newid())) % (60 * 24), cast('00:00' as time)) as OrderTime
into dbo.Sales3M
from Sales.SalesOrderHeader
cross apply (select top 100 * from master..spt_values) v;
create index ixDateTime on dbo.Sales3M (OrderDate, OrderTime) include (ID); (Ik had daar een geclusterde index van kunnen maken, maar ik denk dat een niet-geclusterde index meer typerend is voor uw omgeving.)
Onze gegevens zien er als volgt uit en ik wil rijen vinden tussen bijvoorbeeld 2 augustus 2011 om 8:30 uur en 5 augustus 2011 om 21:30 uur.
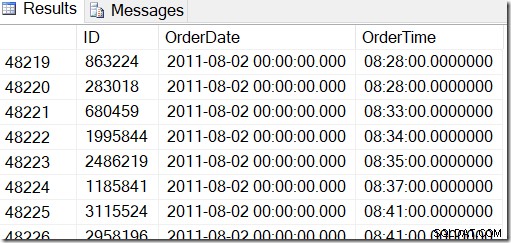
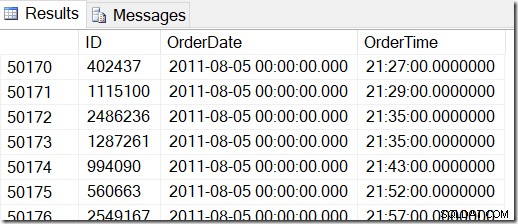
Door de gegevens te bekijken, kan ik zien dat ik alle rijen tussen 48221 en 50171 wil. Dat zijn 50171-48221+1=1951 rijen (de +1 is omdat het een inclusief bereik is). Dit helpt me er zeker van te zijn dat mijn resultaten correct zijn. Je zou waarschijnlijk hetzelfde hebben op je computer, maar niet exact, omdat ik willekeurige waarden heb gebruikt bij het genereren van mijn tabel.
Ik weet dat ik niet zomaar iets als dit kan doen:
select * from dbo.Sales3M where OrderDate between '20110802' and '20110805' and OrderTime between '8:30' and '21:30';
...omdat dit niet iets omvat dat op de 4e van de ene op de andere dag is gebeurd. Dit geeft me 1268 rijen - duidelijk niet goed.
Een optie is om de kolommen te combineren:
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30';
Dit geeft de juiste resultaten. Het doet. Het is gewoon dat dit volledig niet-sargable is en ons een scan geeft over alle rijen in onze tabel. Op onze 3 miljoen rijen kan het enkele seconden duren om dit uit te voeren.
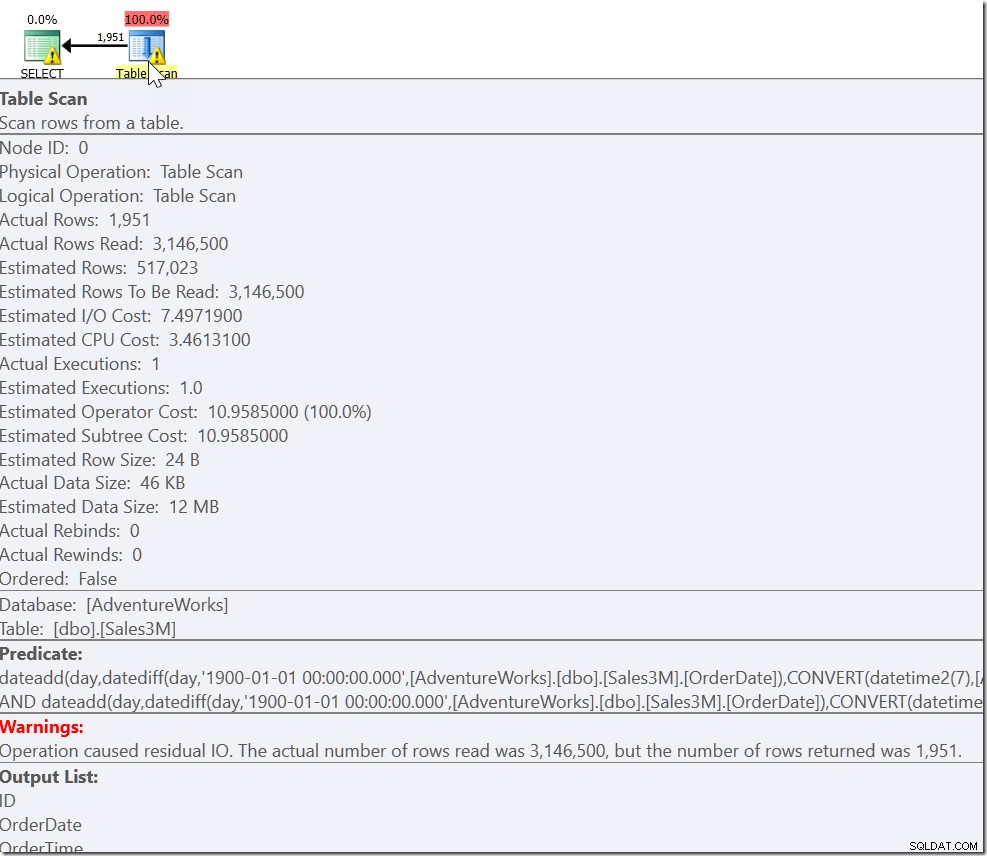
Ons probleem is dat we een gewoon geval hebben en twee speciale gevallen. We weten dat elke rij die voldoet aan OrderDate> '20110802' AND OrderDate <'20110805' er een is die we willen. Maar we hebben ook elke rij nodig die op of na 8:30 uur is op 20110802 en op of vóór 21:30 uur op 20110805. En dat leidt ons naar:
select * from dbo.Sales3M where (OrderDate > '20110802' and OrderDate < '20110805') or (OrderDate = '20110802' and OrderTime >= '8:30') or (OrderDate = '20110805' and OrderTime <= '21:30');
OF is verschrikkelijk, ik weet het. Het kan ook leiden tot scans, hoewel niet noodzakelijk. Hier zie ik drie Index Seeks, aaneengeschakeld en vervolgens gecontroleerd op uniciteit. De Query Optimizer realiseert zich duidelijk dat het niet twee keer dezelfde rij moet retourneren, maar realiseert zich niet dat de drie voorwaarden elkaar uitsluiten. En eigenlijk, als je dit binnen een dag op een bereik zou doen, zou je de verkeerde resultaten krijgen.
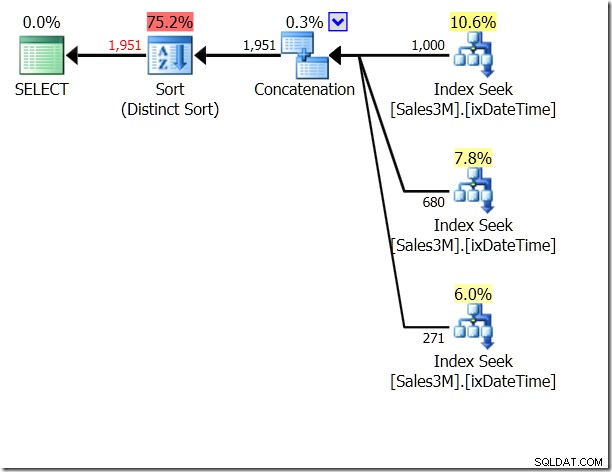
We zouden hiervoor UNION ALL kunnen gebruiken, wat zou betekenen dat de QO er niet om zou geven of de voorwaarden elkaar uitsluiten. Dit geeft ons drie Zoekopdrachten die aaneengeschakeld zijn - dat is best goed.
select * from dbo.Sales3M where (OrderDate > '20110802' and OrderDate < '20110805') union all select * from dbo.Sales3M where (OrderDate = '20110802' and OrderTime >= '8:30') union all select * from dbo.Sales3M where (OrderDate = '20110805' and OrderTime <= '21:30');

Maar het zijn nog steeds drie zoekt. Statistieken IO vertelt me dat het 20 reads op mijn machine zijn.

Als ik nu aan sargabiliteit denk, denk ik niet alleen aan het vermijden van het plaatsen van indexkolommen in uitdrukkingen, ik denk ook aan wat iets zou kunnen helpen lijken overdraagbaar.
Neem bijvoorbeeld WHERE LastName LIKE 'Far%'. Als ik naar het plan hiervoor kijk, zie ik een Seek, met een Seek-predikaat zoekt elke naam van Ver tot (maar niet inclusief) FaS. En dan is er nog een residuaal predikaat dat de LIKE-voorwaarde controleert. Dit is niet omdat de QO van mening is dat LIKE sargable is. Als dat zo was, zou het LIKE kunnen gebruiken in het Seek-predicaat. Het is omdat het weet dat alles waaraan wordt voldaan door die LIKE-voorwaarde binnen dat bereik moet liggen.
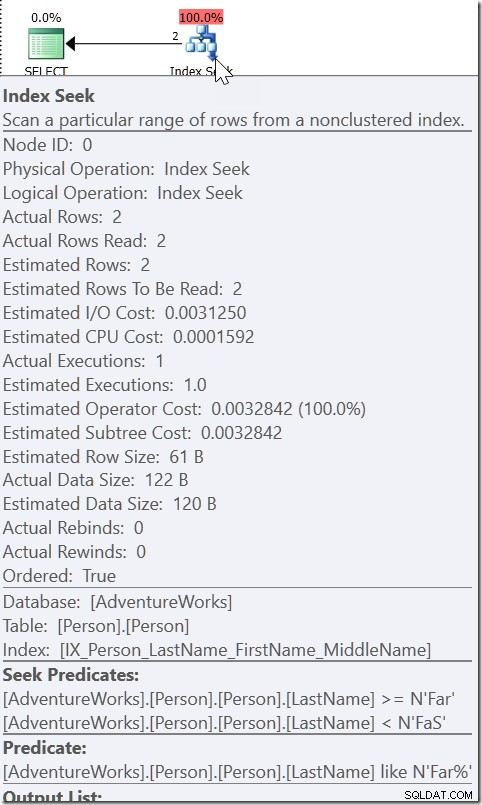
Neem WHERE CAST(OrderDate AS DATE) ='20110805'
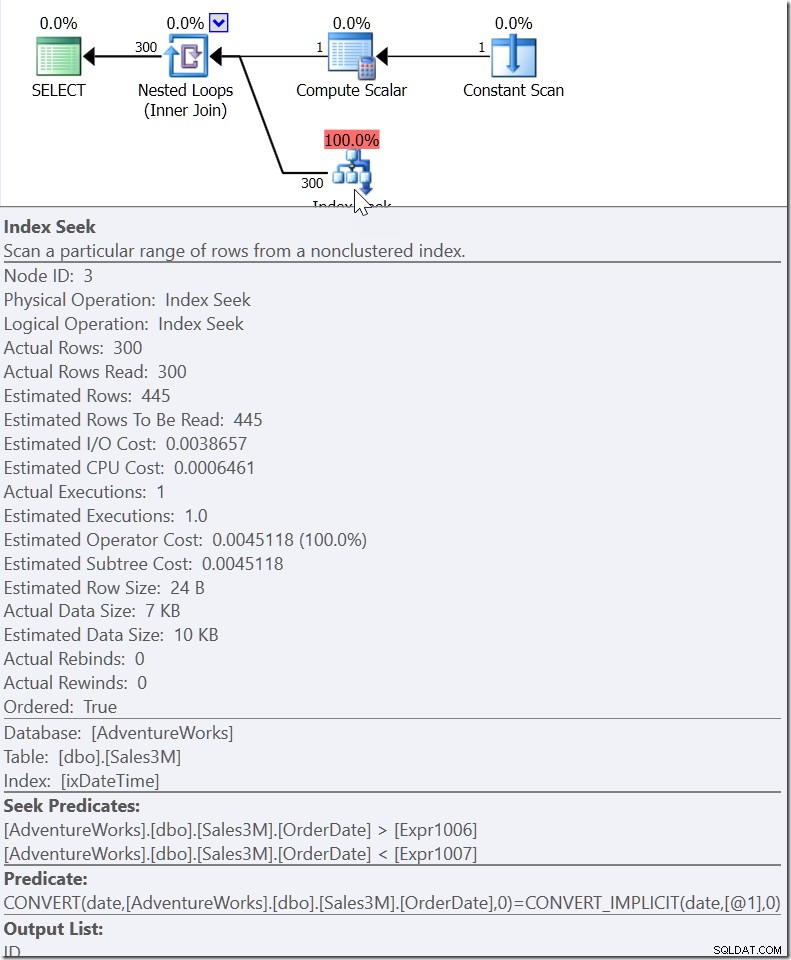
Hier zien we een Seek Predikaat dat zoekt naar OrderDate-waarden tussen twee waarden die elders in het plan zijn uitgewerkt, maar een bereik creëert waarin de juiste waarden moeten bestaan. Dit is niet>=20110805 00:00 en <20110806 00:00 (wat ik er van zou hebben gemaakt), het is iets anders. De waarde voor het begin van dit bereik moet kleiner zijn dan 20110805 00:00, want het is>, niet>=. Alles wat we echt kunnen zeggen is dat wanneer iemand binnen Microsoft implementeerde hoe de QO op dit soort predikaat zou moeten reageren, ze het voldoende informatie gaven om te komen met wat ik een "helperpredikaat" noem.
Nu zou ik graag willen dat Microsoft meer functies sargable zou maken, maar dat specifieke verzoek was Closed lang voordat Connect met pensioen ging.
Maar misschien bedoel ik dat ze meer helperpredikaten maken.
Het probleem met helperpredikaten is dat ze vrijwel zeker meer rijen lezen dan je wilt. Maar het is nog steeds veel beter dan door de hele index te kijken.
Ik weet dat alle rijen die ik wil retourneren OrderDate hebben tussen 20110802 en 20110805. Er zijn er alleen die ik niet wil.
Ik zou ze gewoon kunnen verwijderen, en dit zou geldig zijn:
select * from dbo.Sales3M where OrderDate between '20110802' and '20110805' and not (OrderDate = '20110802' and OrderTime < '8:30') and not (OrderDate = '20110805' and OrderTime > '21:30');
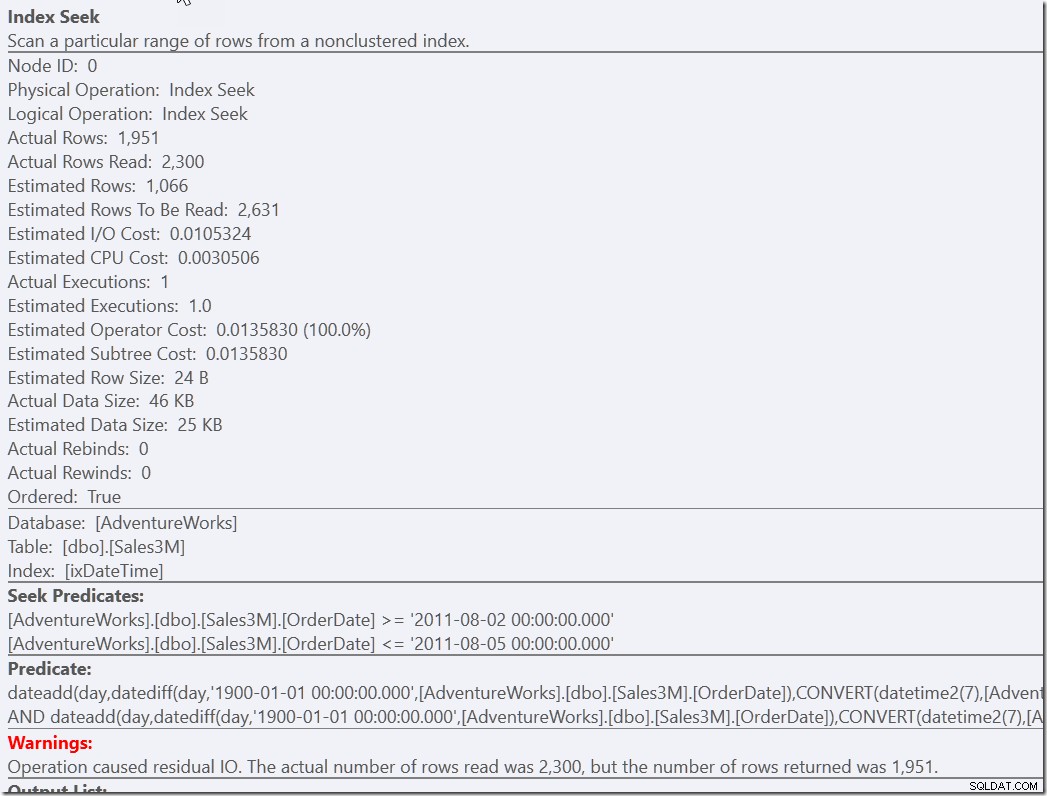
Maar ik heb het gevoel dat dit een oplossing is die enige denkkracht vereist om te bedenken. Minder moeite aan de kant van de ontwikkelaar is om simpelweg een helper-predikaat te geven aan onze correct-maar-langzame versie.
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30' and OrderDate between '20110802' and '20110805';
Beide query's vinden de 2300 rijen die op de juiste dagen staan en moeten vervolgens al die rijen vergelijken met de andere predikaten. De ene moet de twee NIET-voorwaarden controleren, de andere moet wat typeconversie en wiskunde doen. Maar beide zijn veel sneller dan wat we eerder hadden, en doen een enkele Seek (13 leest). Natuurlijk krijg ik waarschuwingen over een inefficiënte RangeScan, maar dit heeft mijn voorkeur boven drie efficiënte.
In sommige opzichten is het grootste probleem met dit laatste voorbeeld dat een goedbedoelende persoon zou zien dat het helperpredikaat overbodig was en het zou kunnen verwijderen. Dit is het geval met alle helperpredikaten. Dus plaats een reactie.
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30' /* This next predicate is just a helper to improve performance */ and OrderDate between '20110802' and '20110805';
Als je iets hebt dat niet in een mooi sargable predikaat past, werk er dan een uit en zoek uit wat je ervan moet uitsluiten. Misschien bedenk je wel een leukere oplossing.
@rob_farley