In februari schreef ik een blogpost over Automatic Plan Correction in SQL Server, en in deze post wil ik het hebben over Automatic Index Management, het tweede onderdeel van de Automatic Tuning-functie. Automatisch indexbeheer is alleen beschikbaar in Azure SQL Database en staat momenteel niet op de planning om beschikbaar te zijn in de volgende release van SQL Server on-premises. Deze optie is onafhankelijk van Automatische plancorrectie ingeschakeld en zoals de naam al aangeeft, beheert het indexen in uw database. Het kan met name indexen maken die ontbreken, en het kan indexen verwijderen die niet worden gebruikt, en indexen die duplicaten zijn. Laten we eens kijken hoe dit gebeurt.
Onder de dekens
Automatisch indexbeheer vertrouwt op gegevens om zijn beslissing te nemen. Voor het maken van potentiële indexen gebruikt het informatie de ontbrekende index DMV en volgt deze deze in de loop van de tijd en combineert die gegevens met een intern model om het voordeel van de index te bepalen. Het gebruikt ook Query Store om te bepalen of de index voordelen biedt, dus het moet worden ingeschakeld voor de database, net als bij Automatische plancorrectie. Met betrekking tot het laten vallen van indexen worden gegevens uit de indexgebruik-DMV (sys.dm_db_index_usage_stats) en indexmetagegevens (bijv. aantal kolommen, kolomgegevenstypen) gebruikt.
Automatisch indexbeheer inschakelen
Zoals vermeld, moet Query Store zijn ingeschakeld voor de database. Dit kan in SSMS, met T-SQL en met REST API voor Azure SQL Database. Merk op dat Query Store standaard is ingeschakeld voor databases in Azure en sinds 2016 Q4.
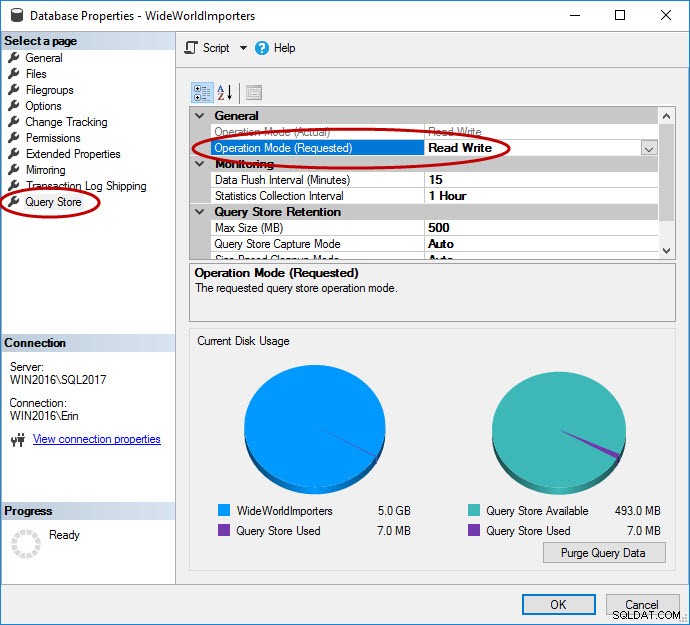
USE [master]; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE = ON; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE (OPERATION_MODE = READ_WRITE); GO
Zodra Query Store is ingeschakeld, kunt u de Azure Portal, T-SQL of EST API gebruiken om automatisch indexbeheer in Azure SQL Database in te schakelen (C# en PowerShell zijn in de maak).
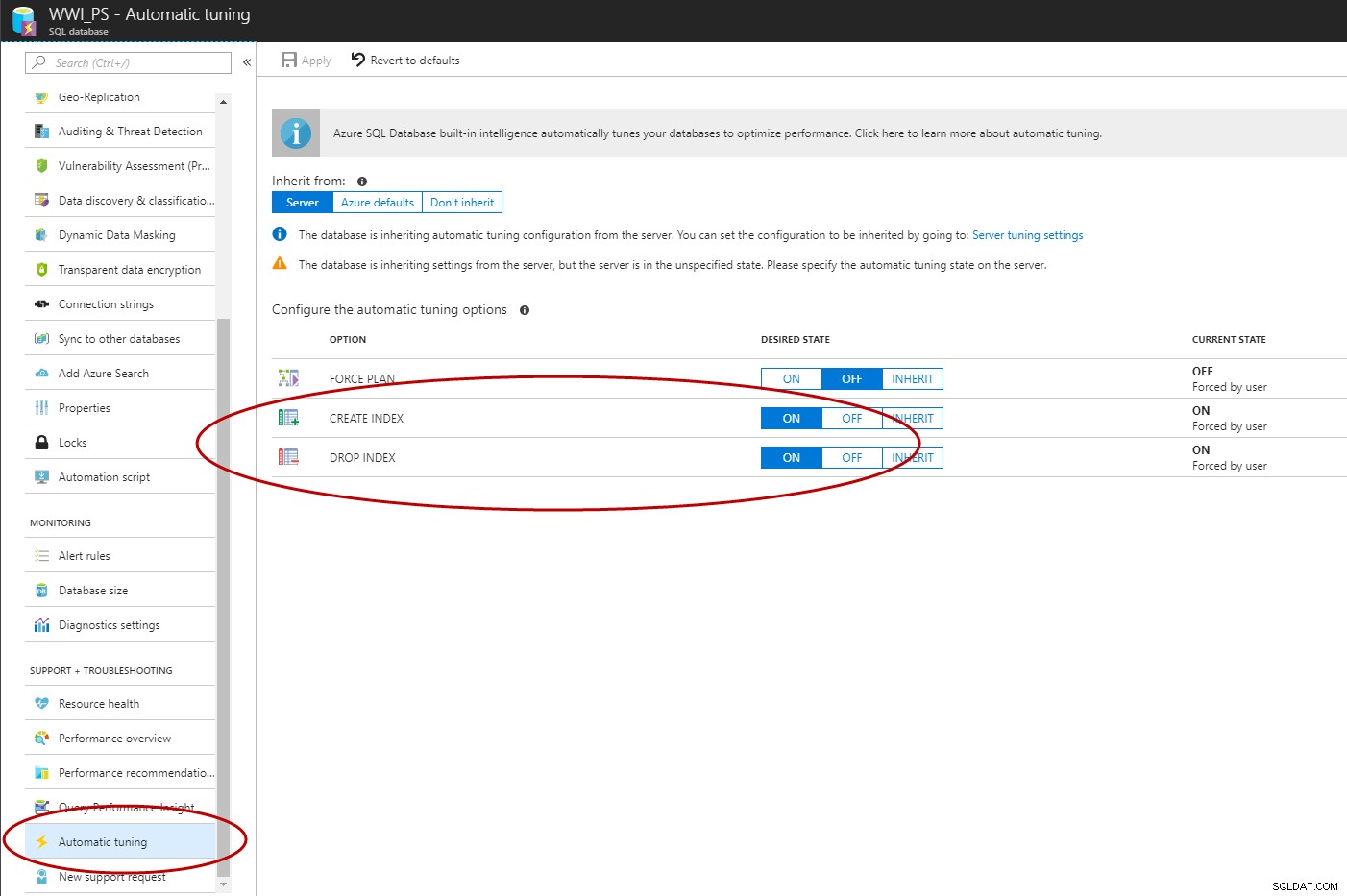
ALTER DATABASE [WWI_PS] SET AUTOMATIC_TUNING (CREATE_INDEX = ON, DROP_INDEX = ON); GO
Automatisch indexbeheer wordt in de nabije toekomst standaard ingeschakeld voor nieuwe data bases in Azure (https://azure.microsoft.com/en-us/blog/automatic-tuning-will-be-a-new-default/). Vanaf januari 2018 is Microsoft begonnen met de uitrol om Automatic Tuning in te schakelen voor Azure SQL-databases die dit nog niet hadden ingeschakeld, met meldingen naar beheerders zodat de optie desgewenst kan worden uitgeschakeld. Dit proces duurt enkele maanden, dus geen paniek als je nog geen melding hebt gekregen!
Hoe het werkt
Voor het maken van indexen is er momenteel een doorlopend venster van zeven (7) dagen* waarover de gegevens worden gevolgd, en het model heeft minimaal negen (9) uur* aan gegevens nodig om een index aan te bevelen, met 12 uur* aan gegevens in Query Store die als basislijn zullen worden gebruikt. Als is vastgesteld dat een index aanzienlijk voordeel zal opleveren, maakt SQL Server de index.
*Deze waarden kunnen in de toekomst veranderen, naarmate het model zich ontwikkelt.
Opmerking:op dit moment voegt het model aanbevelingen samen. Dat wil zeggen, als er meerdere indexen worden aanbevolen voor een tabel, maar er kan één index worden gemaakt om alle opties te dekken, dan kan die ene index momenteel worden gemaakt. Het model is momenteel echter niet intelligent genoeg om een aanbevolen index samen te voegen met een die al bestaat.
Nadat een index is gemaakt, controleert SQL Server of deze voordelen biedt met behulp van Query Store (deze moet dus zijn ingeschakeld voor de database). Het bewaakt de prestaties van elke query die de nieuwe index gebruikt en vergelijkt de CPU van de query voordat de index werd toegevoegd en bij gebruik van de index. Als er een regressie is in de queryprestaties als gevolg van de index, wordt de index teruggedraaid (verwijderd). SQL Server bewaakt de queryprestaties gedurende maximaal drie (3) dagen, of totdat 100% van de relevante werkbelasting is geanalyseerd. Als de index na die periode geen tekenen van regressie vertoont, zal hij de prestaties ervan niet opnieuw beoordelen.
Begrijp dat als Automatic Index Management een index maakt en twee maanden later uw werklast verandert en het voordeel zou hebben van dezelfde index die eerder automatisch is gemaakt, maar met één extra kolom, SQL Server op dit moment een nieuwe index zal maken. Momenteel is er geen logica om een bestaande automatisch gemaakte index te wijzigen, maar die functionaliteit staat op de roadmap voor de functie.
Met betrekking tot het verwijderen van indexen, als een index gedurende 90 dagen geen zoekacties of scans heeft, maar wel onderhoudskosten heeft (wat betekent dat er invoegingen, updates of verwijderingen zijn), wordt deze verwijderd. Dubbele indexen worden ook verwijderd, ervan uitgaande dat ze een exact duplicaat zijn (en het schema wordt gebruikt om te bepalen of indexen precies hetzelfde zijn). Als er dubbele indexen zijn in termen van sleutelkolommen en opgenomen kolommen (indien relevant), maar een of meer ervan heeft een filter, dan zijn ze niet echt dubbel en worden er geen indexen verwijderd.
Ter referentie:er zijn twee keer zoveel DROP INDEX-aanbevelingen in Azure SQL Database als er CREATE INDEX-aanbevelingen zijn.
Wanneer u de DROP INDEX-optie inschakelt, verwijdert SQL Server door de gebruiker gemaakte indexen. Wanneer u de optie CREATE INDEX inschakelt, heeft SQL Server de mogelijkheid om automatisch indexen te maken en deze indexen ook te verwijderen (maar door de gebruiker gemaakte indexen worden niet verwijderd). Ten slotte worden indexen gemaakt en verwijderd tijdens daluren, zoals bepaald door DTU. Als de werkbelasting hoger is dan 80% DTU, wacht SQL Server met het maken of verwijderen van de index totdat de systeembelasting afneemt.
Ga ik SQL Server echt de controle geven?
Misschien. Mijn aanbeveling over deze functie vereist in eerste instantie een "vertrouwen maar verifiëren"-benadering.
Net als bij automatische plancorrectie is automatisch indexbeheer ontwikkeld met een aanzienlijke hoeveelheid gegevens die zijn vastgelegd uit bijna twee miljoen Azure SQL-databases. De functie Automatisch indexbeheer is sinds het eerste kwartaal van 2016 beschikbaar in Azure SQL Database, als onderdeel van Index Advisor.
De algoritmen die door de functie worden gebruikt, zijn geëvolueerd en blijven zich in de loop van de tijd ontwikkelen, naarmate meer databases deze gebruiken en meer gegevens worden vastgelegd en geanalyseerd. Er zijn momenteel echter enkele beperkingen.
- Indexaanbevelingen worden niet getoetst aan bestaande indexen, dus indexconsolidatie tussen nieuwe en bestaande indexen is momenteel niet beschikbaar.
- Als een index voordelen zou bieden voor een SELECT, is de overhead van wijzigingen als gevolg van INSERT's, UPDATE's en DELETE's niet bekend voordat ze worden gemaakt. SQL Server bewaakt deze overhead tijdens het verificatieproces, nadat de index is geïmplementeerd.
Er zijn voordelen aan automatisch indexbeheer die het vermelden waard zijn:
- Voor iedereen die een SQL Server-database moet beheren, maar geen DBA is, kunnen indexaanbevelingen zeer nuttig zijn.
- Indexaanbevelingen worden vastgelegd in de DMV sys.dm_db_tuning_recommendations, zelfs als de indexopties CREATE en DROP niet zijn ingeschakeld. Als u dus niet zeker weet welke wijzigingen SQL Server zou kunnen aanbrengen, kunt u bekijken wat er in de DMV is vastgelegd en vervolgens een beslissing nemen om de aanbeveling handmatig te implementeren.
Opmerking:als u de aanbeveling handmatig implementeert, voert SQL Server geen validatie uit. Als u de aanbeveling implementeert via de Portal (met behulp van de knop Toepassen) of REST API, wordt deze uitgevoerd alsof het een automatische actie is en wordt validatie uitgevoerd (en kan de index automatisch worden teruggedraaid als er een regressie is).
- De functie wordt steeds beter. Zoals ik al eerder zei, probeert Microsoft niet om DBA's of ontwikkelaars uit hun baan te coderen, het probeert het laaghangende fruit aan te pakken, zodat je meer tijd hebt voor de taken en projecten die niet intelligent kunnen worden geautomatiseerd.
Samenvatting
Als je niet klaar bent om de teugels van indexbeheer uit handen te geven, snap ik het. Maar als u minimaal een Azure SQL Database hebt, moet u de DMV sys.dm_db_tuning_recommendations regelmatig controleren om te zien wat SQL Server aanbeveelt, en dat te vergelijken met gegevens die u of uw externe bewakingsprogramma mogelijk over indexgebruik vastlegt. Wanneer was tenslotte de laatste keer dat u een volledige en grondige beoordeling van uw indexen deed om te begrijpen wat er ontbreekt, wat er echt wordt gebruikt en wat gewoon overhead in de database genereert?