Vorig jaar blogde Andy Mallon over het vergroten van een kolom van int naar bigint zonder uitvaltijd. (Waarom dit niet alleen metadata is in moderne versies van SQL Server is mij een raadsel, maar dat is een andere post.)
Wanneer we dit probleem behandelen, zijn het meestal brede en massieve tabellen (zowel in rijen als in omvang), en de kolom die we moeten wijzigen is de enige/leidende kolom in de clustersleutel. Er zijn meestal ook andere complicaties:inkomende externe sleutelbeperkingen, veel niet-geclusterde indexen en een drukke database die ultragevoelig is voor logactiviteit (omdat deze betrokken is bij het bijhouden van wijzigingen, replicatie, beschikbaarheidsgroepen of alle drie ).
Om deze reden moeten we een benadering volgen zoals Andy heeft geschetst, waarbij we een schaduwtabel bouwen met het nieuwe schema, triggers maken om beide kopieën synchroon te houden en vervolgens batches/aanvullen in het eigen tempo van dat team totdat ze klaar zijn om te wisselen in de kopie als de echte deal.
Maar ik ben lui!
Er zijn enkele gevallen waarin u de kolom direct kunt wijzigen, als u zich een klein venster van downtime/blokkering kunt veroorloven, en het een veel eenvoudigere handeling wordt. Vorige week deed zich zo'n geval voor, met een tafel van meer dan 1 TB, maar slechts 100.000 rijen. Bijna alle gegevens waren off-row (LOB), ze konden zich indien nodig een korte periode van downtime veroorloven, en ze waren van plan om het bijhouden van wijzigingen uit te schakelen en het toch opnieuw te configureren. Ervan overtuigd dat het opnieuw maken van de geclusterde PK de LOB-gegevens niet (veel) zou moeten raken, suggereerde ik dat dit een geval zou kunnen zijn waarin we de wijziging gewoon rechtstreeks kunnen toepassen.
In een geïsoleerd scenario (geen inkomende externe sleutels, geen extra indexen, geen activiteiten die afhankelijk zijn van de logboeklezer en geen zorgen over gelijktijdigheid), heb ik enkele tests samengesteld om in een vacuüm te zien wat deze verandering zou vereisen in termen van duur en impact op het transactielogboek. De belangrijkste vraag die ik van tevoren niet wist te beantwoorden, was:"Wat zijn de incrementele kosten van het bijwerken van tabellen op hun plaats wanneer er grote hoeveelheden niet-essentiële gegevens zijn?"
Ik ga proberen om veel in één post hier te verpakken. Ik heb veel getest en het hangt allemaal met elkaar samen, ook al zijn niet alle testscenario's op jou van toepassing. Heb geduld met me.
De tafels
Ik heb 6 tabellen gemaakt, inclusief een baseline die alleen had de sleutelkolom, één tabel met 4K in de rij opgeslagen en vervolgens vier tabellen met elk een varchar(max)-kolom gevuld met verschillende hoeveelheden stringgegevens (4K, 16K, 64K en 256K).
CREATE TABLE dbo.withJustId
(
id int NOT NULL,
CONSTRAINT pk_withJustId PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withoutLob
(
id int NOT NULL,
extradata varchar(4000) NOT NULL DEFAULT (REPLICATE('x', 4000)),
CONSTRAINT pk_withoutLob PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withLob004
(
id int NOT NULL,
extradata varchar(max) NOT NULL DEFAULT (REPLICATE('x', 4000)),
CONSTRAINT pk_withLob004 PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withLob016
(
id int NOT NULL,
extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 16000)),
CONSTRAINT pk_withLob016 PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withLob064
(
id int NOT NULL,
extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 64000)),
CONSTRAINT pk_withLob064 PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withLob256
(
id int NOT NULL,
extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 256000)),
CONSTRAINT pk_withLob256 PRIMARY KEY CLUSTERED (id)
); Ik vulde elk met 100.000 rijen:
INSERT dbo.withJustId (id) SELECT TOP (100000) id = ROW_NUMBER() OVER (ORDER BY c1.name) FROM sys.all_columns AS c1 CROSS JOIN sys.all_objects; INSERT dbo.withoutLob (id) SELECT id FROM dbo.withJustId; INSERT dbo.withLob004 (id) SELECT id FROM dbo.withJustId; INSERT dbo.withLob016 (id) SELECT id FROM dbo.withJustId; INSERT dbo.withLob064 (id) SELECT id FROM dbo.withJustId; INSERT dbo.withLob256 (id) SELECT id FROM dbo.withJustId;
Ik erken dat het bovenstaande onrealistisch is; hoe vaak hebben we een tabel die slechts een identificatie + LOB-gegevens is? Ik heb de tests opnieuw uitgevoerd met deze extra vier kolommen om de niet-LOB-gegevenspagina's een beetje meer real-world inhoud te geven:
fill1 char(320) NOT NULL DEFAULT ('x'),
count1 int NOT NULL DEFAULT (0),
count2 int NOT NULL DEFAULT (0),
dt datetime2 NOT NULL DEFAULT sysutcdatetime(), Deze tabellen zijn slechts iets groter in termen van totale omvang, maar de proportionele toename van de hoeveelheid niet-LOB-gegevens (niet geïllustreerd in deze grafiek) is het grote maar verborgen verschil:
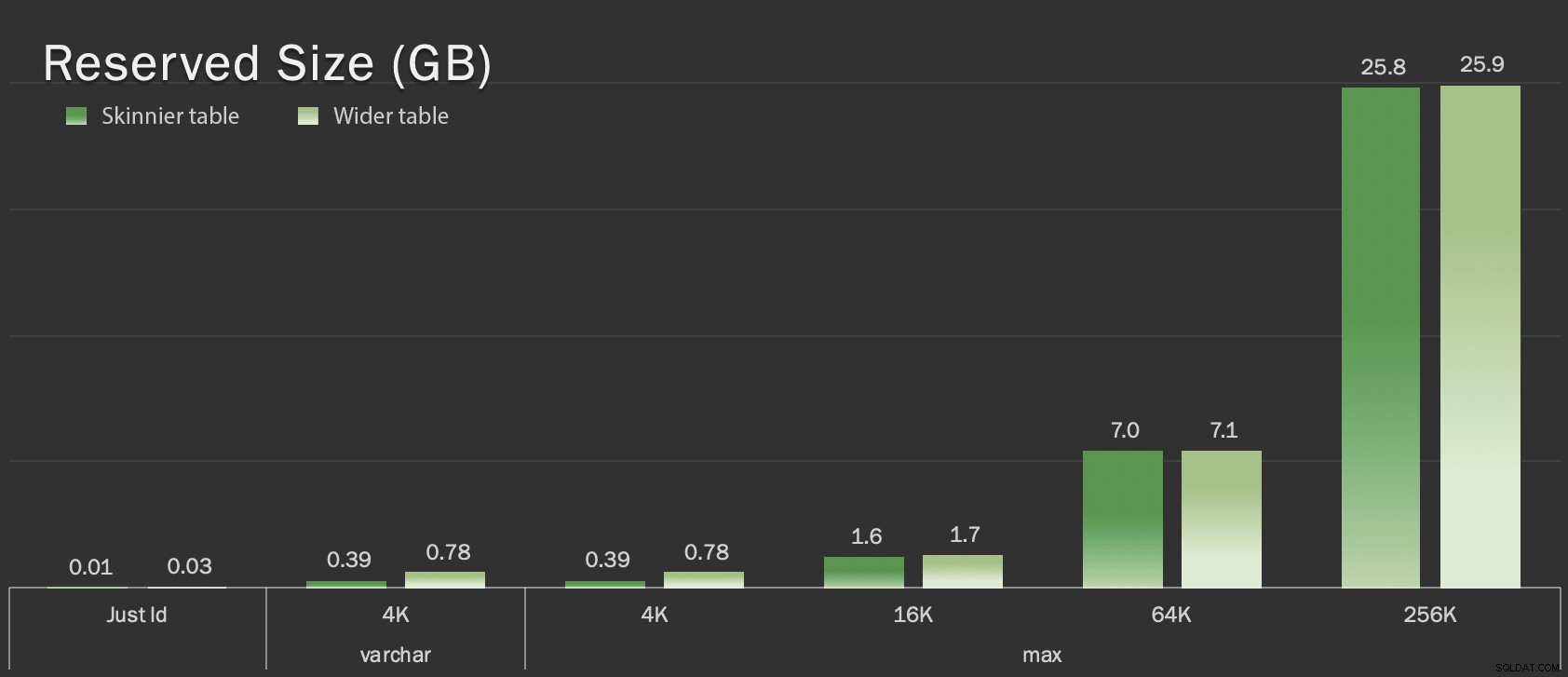 Gereserveerde grootte van tabellen, in GB
Gereserveerde grootte van tabellen, in GB
De testen
Vervolgens heb ik de loggegevens getimed en verzameld voor elk van deze bewerkingen (met en zonder ONLINE = ON ) tegen elke variatie van de tafel:
ALTER TABLE dbo.<name> DROP CONSTRAINT pk_<name>; ALTER TABLE dbo.<name> ALTER COLUMN id bigint NOT NULL; -- WITH (ONLINE = ON); ALTER TABLE dbo.<name> ADD CONSTRAINT pk_<name> PRIMARY KEY CLUSTERED (id);
In werkelijkheid gebruikte ik dynamische SQL om al deze tests te genereren, zodat ik niet voor elke test handmatig met scripts moest spelen.
In een ander bericht zal ik de dynamische SQL delen die ik heb gebruikt om die tests te genereren, en de timings bij elke stap verzamelen.
Ter vergelijking heb ik ook Andy's methode getest (zij het zonder batching, en alleen op de magere versie van de tabel):
CREATE TABLE dbo.<name>_copy ( id bigint NOT NULL -- <, extradata column when relevant > CONSTRAINT pk_copy_<name> PRIMARY KEY CLUSTERED (id)); INSERT dbo.<name>_copy SELECT * FROM dbo.<name>; EXEC sys.sp_rename N'dbo.<name>', N'dbo.<name>_old', N'OBJECT'; EXEC sys.sp_rename N'dbo.<name>_copy', N'dbo.<name>', N'OBJECT';
Ik sloeg de bredere tafels hier over; Ik wilde de complexiteit van het coderen en meten van batchbewerkingen niet introduceren. Het voor de hand liggende pijnpunt hier is dat, in tegenstelling tot het wijzigen van de kolom op zijn plaats, je met de schaduwmethode elke afzonderlijke byte van die LOB-gegevens moet kopiëren. Batching kan de grote impact van het proberen om dat in een enkele transactie te doen minimaliseren, maar al dat geschuifel zal uiteindelijk downstream opnieuw moeten worden gedaan. Batching bij de bron kan niet volledig bepalen hoeveel pijn dat zal doen op de bestemming.
De resultaten
De eerste resultaten die ik ga laten zien, zijn slechts de gemiddelde duur voor in-place wijzigingen, voor alle 12 tafelconfiguraties, en met en zonder ONLINE = ON :
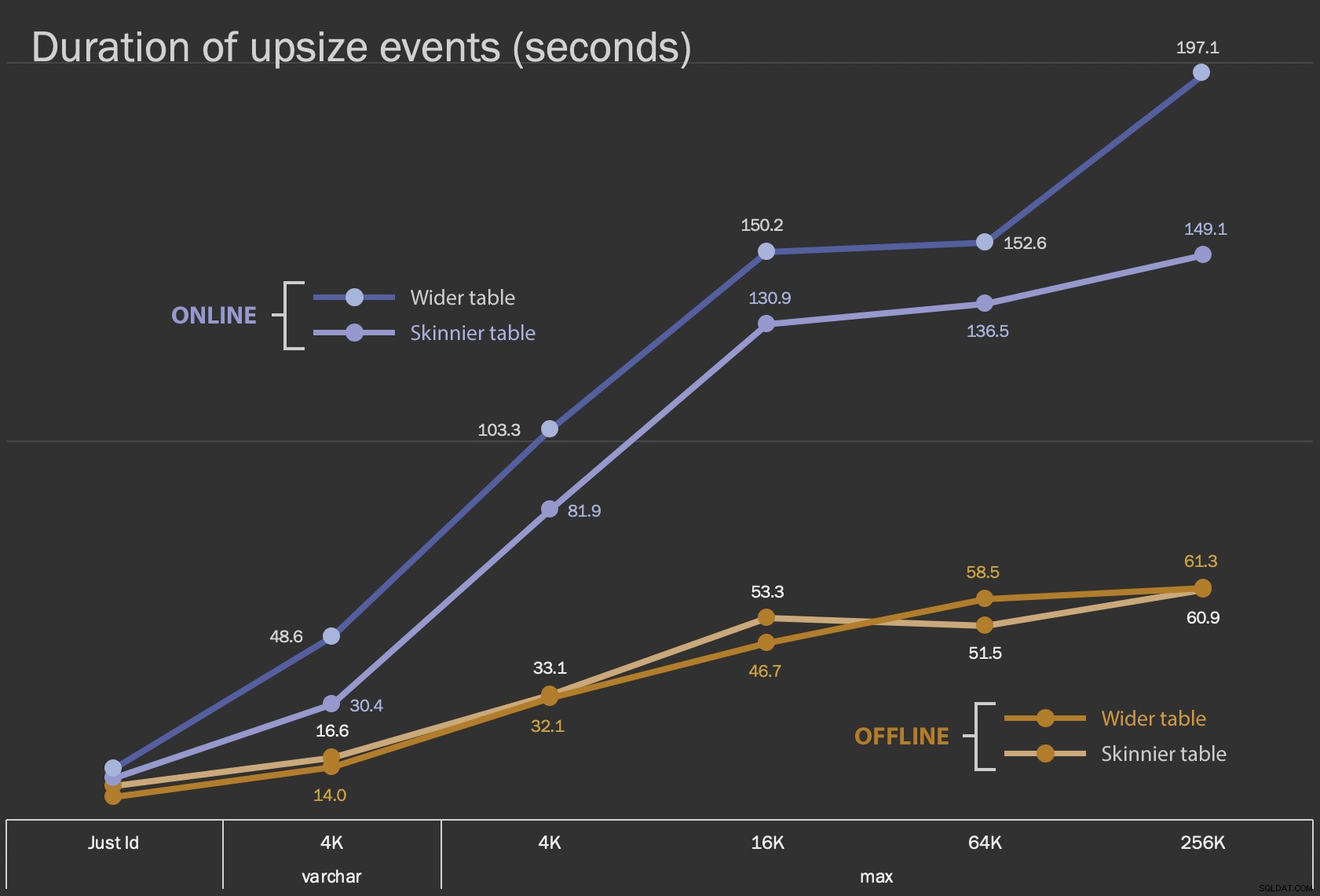 Duur, in seconden, van het ter plaatse wijzigen van de kolom
Duur, in seconden, van het ter plaatse wijzigen van de kolom
Dit uitvoeren als een online bewerking kost meer tijd (200 seconden in het ergste geval), maar blokkeert gebruikers niet. Het lijkt samen met de grootte toe te nemen, maar niet helemaal lineair. Het offline uitvoeren van deze bewerking veroorzaakt blokkering, maar is veel sneller en verandert niet zo drastisch als de tafel groter wordt (zelfs bij de grootste grootte gebeurde dit nog steeds in ongeveer een minuut).
Het vergelijken van deze in-place operaties met de swap-and-drop-operatie is moeilijk met behulp van een lijndiagram vanwege het enorme schaalverschil. In plaats daarvan ga ik een horizontaal staafdiagram tonen voor de duur van elke tabelconfiguratie. Als het opnieuw maken sneller gaat, schilder ik de achtergrond van die rij groen; wanneer het langzamer is (of tussen de offline en online methoden valt), is dat waarschijnlijk niet nodig, maar ik zal de achtergrond van die rij rood schilderen.
| LOB-grootte | Benadering | Tabelconfiguratie | Duur (seconden) | ||
|---|---|---|---|
| Just Id | ALTER Offline | Magere tafel (10 MB) | 8.8 |
| Bredere tabel (30 MB) | 6.3 | ||
| ALTER Online | Magere tafel | 11.0 | |
| Bredere tabel | 13.6 | ||
| Hermaak | Magere tafel | 3.4 | |
| varchar 4K | Offline | Magere tafel (390 MB) | 16.6 |
| Bredere tabel (780 MB) | 14.0 | ||
| Online | Magere tafel | 30,4 | |
| Bredere tabel | 48.6 | ||
| Recreate | Magere tafel | 1.290,0 | |
| max 4k | Offline | Magere tafel (390 MB) | 33.1 |
| Bredere tabel (780 MB) | 32,1 | ||
| Online | Magere tafel | 81.9 | |
| Bredere tabel | 103,3 | ||
| Hermaak | Magere tafel | 28.9 | |
| max 16k | Offline | Magere tafel (1,6 GB) | 53,3 |
| Bredere tabel (1,7 GB) | 46,7 | ||
| Online | Magere tafel | 130.9 | |
| Bredere tabel | 150.2 | ||
| Recreate | Magere tafel | 81.8 | |
| max 64k | Offline | Magere tafel (7,0 GB) | 51,5 |
| Bredere tabel (7,1 GB) | 58.5 | ||
| Online | Magere tafel | 136.5 | |
| Bredere tabel | 152.6 | ||
| Recreate | Magere tafel | 226.5 | |
| max 256k | Offline | Magere tafel (25,8 GB) | 60,9 |
| Bredere tabel (25,9 GB) | 61.3 | ||
| Online | Magere tafel | 149,1 | |
| Bredere tabel | 197.1 | ||
| Recreate | Magere tafel | 1.576,7 | |
Dit is een oneerlijke schok bij Andy's methode, omdat je - in de echte wereld - die hele operatie niet in één keer zou uitvoeren. Kortheidshalve heb ik hier het gebruik van transactielogboeken niet weergegeven, maar het zou gemakkelijker zijn om dat ook te controleren door batching in een zij-aan-zij-bewerking. Hoewel zijn aanpak meer werk vooraf vereist, is het een stuk veiliger in termen van downtime en/of blokkering. Maar u kunt zien dat in gevallen waarin u veel off-row gegevens heeft en u zich een korte storing kunt veroorloven, het direct wijzigen van de kolom een stuk minder pijnlijk is. "Te groot om ter plaatse te veranderen" is subjectief en kan verschillende resultaten opleveren, afhankelijk van wat "groot" betekent. Voordat u tot een aanpak overgaat, kan het zinvol zijn om de wijziging te toetsen aan een redelijke kopie, omdat de interne bewerking een acceptabele afweging kan zijn.
Conclusie
Ik heb dit niet geschreven om met Andy in discussie te gaan. De aanpak in de originele post is degelijk, 100% betrouwbaar en we gebruiken het de hele tijd. Wanneer brute kracht echter wordt gewaardeerd boven chirurgische precisie, en vooral als u een stukje downtime kunt nemen, kan de eenvoudigere benadering voor bepaalde tafelvormen waardevol zijn.