Ik denk dat iedereen mijn mening over MERGE al kent en waarom ik er vanaf blijf. Maar hier is nog een (anti-)patroon dat ik overal zie wanneer mensen een upsert willen uitvoeren (update een rij als deze bestaat en voeg deze in als die niet bestaat):
IF EXISTS (SELECT 1 FROM dbo.t WHERE [key] = @key) BEGIN UPDATE dbo.t SET val = @val WHERE [key] = @key; END ELSE BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END
Dit ziet eruit als een vrij logische stroom die weerspiegelt hoe we hier in het echte leven over denken:
- Bestaat er al een rij voor deze sleutel?
- JA :OK, update die rij.
- NEE :OK, voeg het dan toe.
Maar dit is verspilling.
Het lokaliseren van de rij om te bevestigen dat deze bestaat, om deze vervolgens opnieuw te moeten lokaliseren om hem bij te werken, is twee keer zoveel werk voor niets. Zelfs als de sleutel is geïndexeerd (wat naar ik hoop altijd het geval is). Als ik deze logica in een stroomschema zou zetten en bij elke stap het type bewerking zou associëren dat in de database zou moeten gebeuren, zou ik dit hebben:
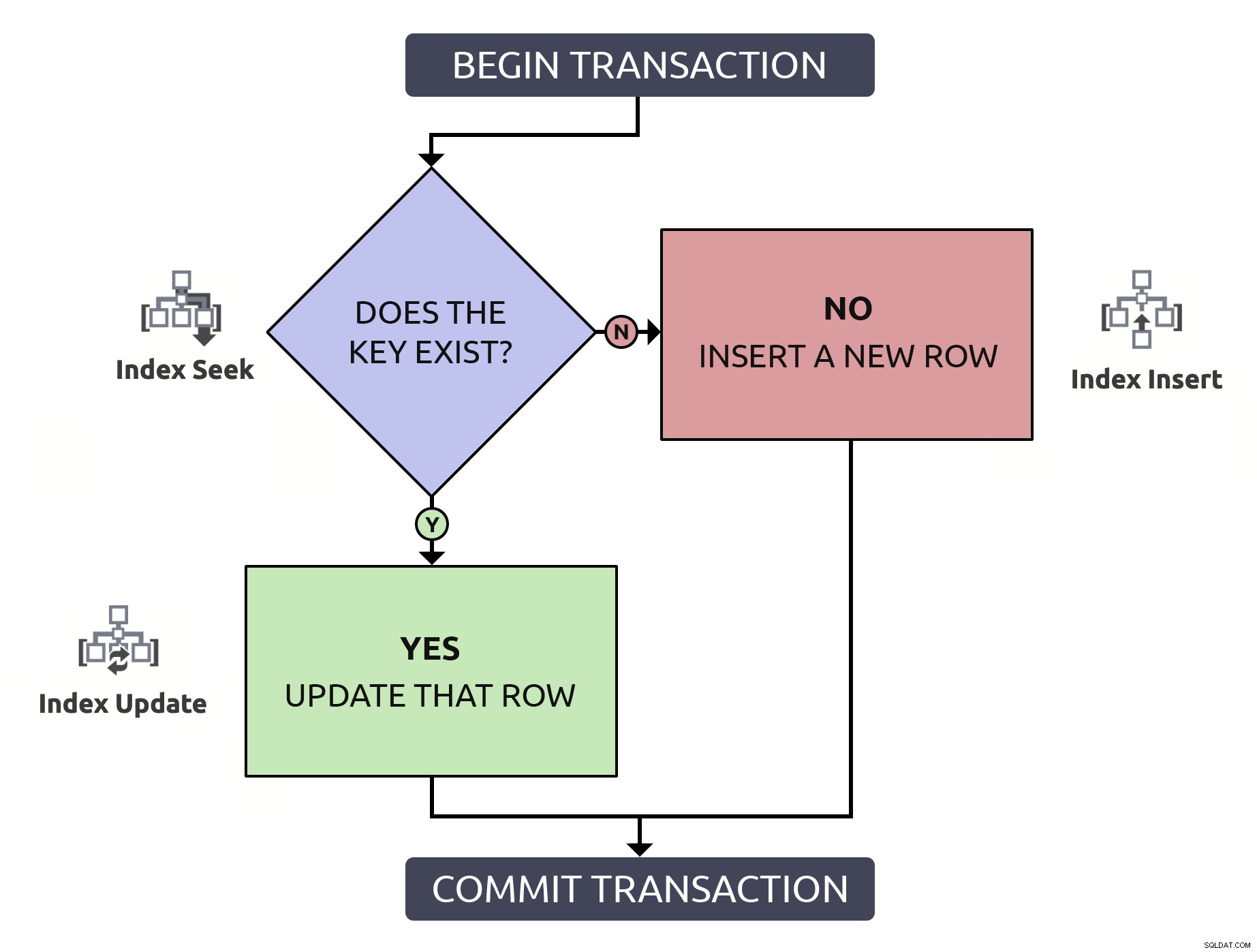 Merk op dat alle paden twee indexbewerkingen zullen ondergaan.
Merk op dat alle paden twee indexbewerkingen zullen ondergaan.
Wat nog belangrijker is, prestaties terzijde, tenzij u zowel een expliciete transactie gebruikt als het isolatieniveau verhoogt, kunnen er meerdere dingen fout gaan als de rij nog niet bestaat:
- Als de sleutel bestaat en twee sessies proberen tegelijkertijd te updaten, zullen ze beiden succesvol worden geüpdatet (één zal "winnen"; de "verliezer" zal volgen met de verandering die blijft hangen, wat leidt tot een "verloren update"). Dit is op zich geen probleem, en dit is hoe we moeten verwachten dat een systeem met gelijktijdigheid werkt. Paul White praat hier meer in detail over de interne mechanica, en Martin Smith praat hier over enkele andere nuances.
- Als de sleutel niet bestaat, maar beide sessies slagen voor de bestaanscontrole op dezelfde manier, kan er van alles gebeuren wanneer ze allebei proberen in te voegen:
- impasse vanwege incompatibele sloten;
- fouten bij sleutelovertredingen dat had niet mogen gebeuren; of,
- dubbele sleutelwaarden invoegen als die kolom niet goed is beperkt.
Die laatste is de ergste, IMHO, omdat het degene is die mogelijk gegevens corrumpeert . Deadlocks en uitzonderingen kunnen eenvoudig worden afgehandeld met zaken als foutafhandeling, XACT_ABORT en probeer de logica opnieuw, afhankelijk van hoe vaak u botsingen verwacht. Maar als je in slaap wordt gesust door een gevoel van veiligheid dat de IF EXISTS check beschermt u tegen duplicaten (of sleutelovertredingen), dat is een verrassing die staat te gebeuren. Als u verwacht dat een kolom zich als een sleutel gedraagt, maakt u deze officieel en voegt u een beperking toe.
"Veel mensen zeggen..."
Dan Guzman sprak meer dan tien jaar geleden over racecondities in Conditional INSERT/UPDATE Race Condition en later in "UPSERT" Race Condition With MERGE.
Michael Swart heeft dit onderwerp ook meerdere keren behandeld:
- Mythbusting:gelijktijdige update/insert-oplossingen - waar hij erkende dat het verlaten van de oorspronkelijke logica en alleen het verhogen van het isolatieniveau sleutelovertredingen in impasses veranderde;
- Wees voorzichtig met de samenvoegverklaring – waar hij zijn enthousiasme over
MERGEcontroleerde; en, - Wat je moet vermijden als je MERGE wilt gebruiken - waar hij nogmaals bevestigde dat er nog steeds voldoende geldige redenen zijn om
MERGEte blijven vermijden .
Zorg ervoor dat je ook alle reacties op alle drie de berichten leest.
De oplossing
Ik heb veel impasses in mijn carrière opgelost door me simpelweg aan te passen aan het volgende patroon (gooi de overbodige cheque weg, stop de volgorde in een transactie en bescherm de eerste tafeltoegang met de juiste vergrendeling):
BEGIN TRANSACTION; UPDATE dbo.t WITH (UPDLOCK, SERIALIZABLE) SET val = @val WHERE [key] = @key; IF @@ROWCOUNT = 0 BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END COMMIT TRANSACTION;
Waarom hebben we twee hints nodig? Is UPDLOCK . niet genoeg?
UPDLOCKwordt gebruikt om te beschermen tegen conversie-impasses bij de instructie niveau (laat een andere sessie wachten in plaats van een slachtoffer aan te moedigen om het opnieuw te proberen).SERIALIZABLEwordt gebruikt om te beschermen tegen wijzigingen in de onderliggende gegevens gedurende de transactie (zorg ervoor dat een rij die niet bestaat niet blijft bestaan).
Het is iets meer code, maar het is 1000% veiliger, en zelfs in het slechtste case (de rij bestaat nog niet), doet het hetzelfde als het antipatroon. In het beste geval, als u een reeds bestaande rij bijwerkt, is het efficiënter om die rij slechts één keer te vinden. Door deze logica te combineren met de bewerkingen op hoog niveau die in de database zouden moeten plaatsvinden, is het iets eenvoudiger:
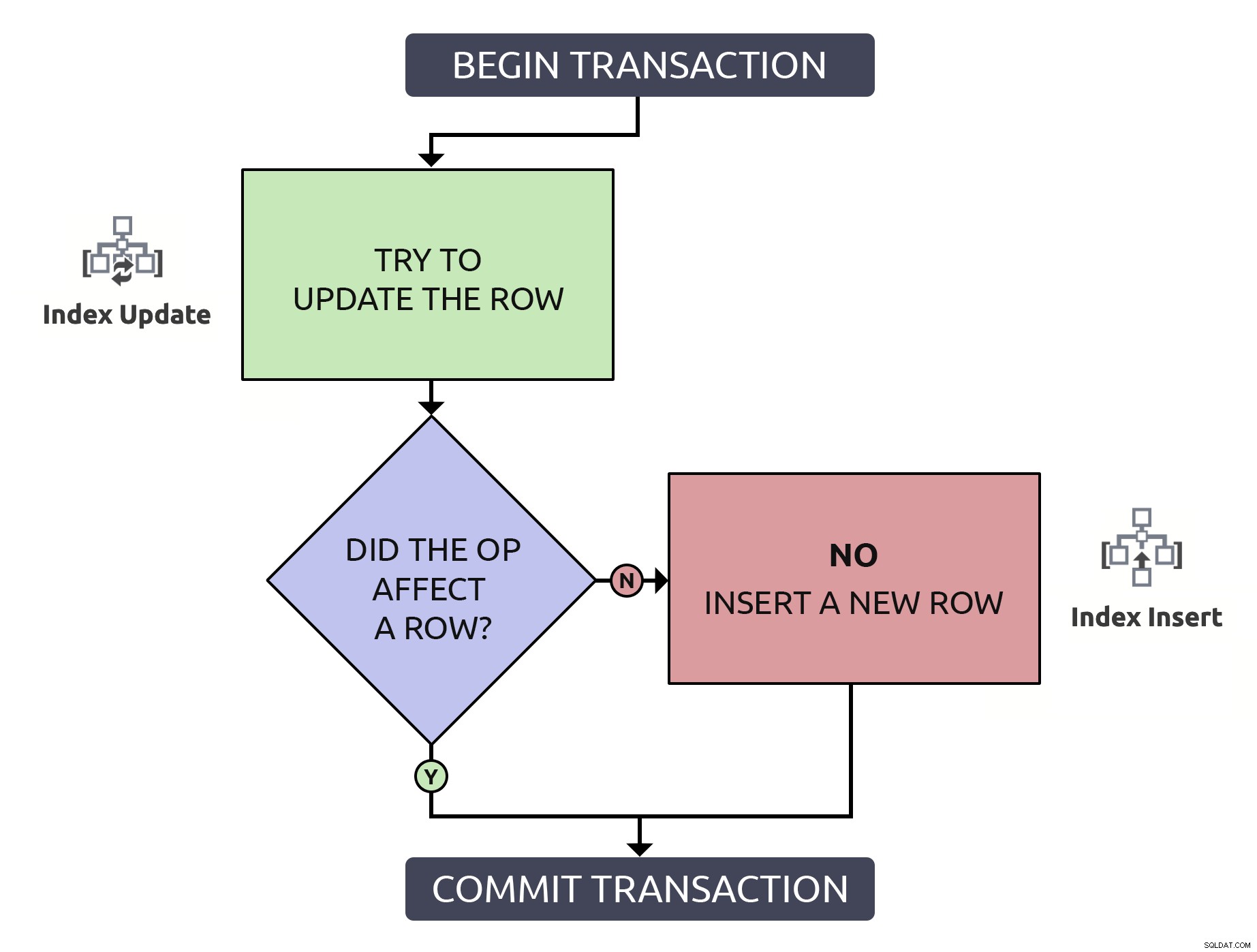 In dit geval leidt één pad slechts tot één indexbewerking.
In dit geval leidt één pad slechts tot één indexbewerking.
Maar nogmaals, prestaties terzijde:
- Als de sleutel bestaat en twee sessies proberen deze tegelijkertijd bij te werken, zullen ze beiden om de beurt de rij updaten , zoals voorheen.
- Als de sleutel niet bestaat, zal één sessie "winnen" en de rij invoegen . De ander zal moeten wachten totdat de vergrendelingen worden vrijgegeven om zelfs te controleren op bestaan, en worden gedwongen om te updaten.
In beide gevallen verliest de schrijver die de race heeft gewonnen zijn gegevens aan alles wat de "verliezer" daarna heeft bijgewerkt.
Houd er rekening mee dat de algehele doorvoer op een zeer gelijktijdig systeem misschien lijden, maar dat is een afweging die je bereid moet zijn te maken. Dat je veel deadlock-slachtoffers of fouten bij het overtreden van sleutels krijgt, maar ze snel gebeuren, is geen goede prestatiemaatstaf. Sommige mensen zouden graag zien dat alle blokkeringen uit alle scenario's worden verwijderd, maar een deel daarvan is blokkering die u absoluut wilt voor gegevensintegriteit.
Maar wat als een update minder waarschijnlijk is?
Het is duidelijk dat de bovenstaande oplossing optimaliseert voor updates en ervan uitgaat dat een sleutel waarnaar u probeert te schrijven al minstens zo vaak in de tabel voorkomt als niet. Als u liever optimaliseert voor inserts, wetende of gissen dat inserts waarschijnlijker zijn dan updates, kunt u de logica omdraaien en toch een veilige upsert-bewerking hebben:
BEGIN TRANSACTION;
INSERT dbo.t([key], val)
SELECT @key, @val
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.t WITH (UPDLOCK, SERIALIZABLE)
WHERE [key] = @key
);
IF @@ROWCOUNT = 0
BEGIN
UPDATE dbo.t SET val = @val WHERE [key] = @key;
END
COMMIT TRANSACTION; Er is ook de "gewoon doen"-benadering, waarbij je blindelings invoegt en botsingen uitzonderingen laat maken voor de beller:
BEGIN TRANSACTION; BEGIN TRY INSERT dbo.t([key], val) VALUES(@key, @val); END TRY BEGIN CATCH UPDATE dbo.t SET val = @val WHERE [key] = @key; END CATCH COMMIT TRANSACTION;
De kosten van die uitzonderingen zullen vaak opwegen tegen de kosten van eerst controleren; je zult het moeten proberen met een ongeveer nauwkeurige schatting van de hit / miss-snelheid. Ik heb hier en hier over geschreven.
Hoe zit het met het opwaarderen van meerdere rijen?
Het bovenstaande gaat over beslissingen voor het invoegen/bijwerken van singletons, maar Justin Pealing vroeg wat te doen als je meerdere rijen verwerkt zonder te weten welke ervan al bestaan?
Ervan uitgaande dat u een reeks rijen verzendt met behulp van zoiets als een tabelwaardeparameter, zou u bijwerken met behulp van een join en vervolgens invoegen met NOT EXISTS, maar het patroon zou nog steeds gelijk zijn aan de eerste benadering hierboven:
CREATE PROCEDURE dbo.UpsertTheThings
@tvp dbo.TableType READONLY
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE t WITH (UPDLOCK, SERIALIZABLE)
SET val = tvp.val
FROM dbo.t AS t
INNER JOIN @tvp AS tvp
ON t.[key] = tvp.[key];
INSERT dbo.t([key], val)
SELECT [key], val FROM @tvp AS tvp
WHERE NOT EXISTS (SELECT 1 FROM dbo.t WHERE [key] = tvp.[key]);
COMMIT TRANSACTION;
END Als je meerdere rijen op een andere manier dan een TVP (XML, door komma's gescheiden lijst, voodoo) bij elkaar krijgt, plaats ze dan eerst in een tabelvorm en voeg je bij wat dat ook is. Zorg ervoor dat u in dit scenario niet eerst optimaliseert voor invoegingen, anders kunt u sommige rijen mogelijk twee keer bijwerken.
Conclusie
Deze upsert-patronen zijn superieur aan degene die ik maar al te vaak zie, en ik hoop dat je ze gaat gebruiken. Ik zal naar dit bericht verwijzen elke keer dat ik de IF EXISTS . zie patroon in het wild. En, hey, nog een shoutout naar Paul White (sql.kiwi | @SQK_Kiwi), omdat hij zo uitstekend is in het gemakkelijk begrijpen en uitleggen van harde concepten.
En als je vindt dat je moet gebruik MERGE , alsjeblieft niet @ mij; ofwel heb je een goede reden (misschien heb je wat obscure MERGE nodig) -alleen functionaliteit), of u nam de bovenstaande links niet serieus.