Welnu, om uw vraag te beantwoorden waarom SQL Server dit doet, het antwoord is dat de query niet in een logische volgorde is gecompileerd, elke instructie wordt op zijn eigen verdienste gecompileerd, dus wanneer het queryplan voor uw select-instructie wordt gegenereerd, wordt de optimiser weet niet dat @val1 en @Val2 respectievelijk 'val1' en 'val2' worden.
Wanneer SQL Server de waarde niet kent, moet het een zo goed mogelijke schatting maken van hoe vaak die variabele in de tabel zal voorkomen, wat soms kan leiden tot suboptimale plannen. Mijn belangrijkste punt is dat dezelfde query met verschillende waarden verschillende plannen kan genereren. Stel je dit eenvoudige voorbeeld voor:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 991 1
FROM sys.all_objects a
UNION ALL
SELECT TOP 9 ROW_NUMBER() OVER(ORDER BY a.object_id) + 1
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Het enige dat ik hier heb gedaan, is een eenvoudige tabel maken en 1000 rijen toevoegen met waarden 1-10 voor de kolom val , maar 1 verschijnt 991 keer en de andere 9 slechts één keer. Het uitgangspunt is deze vraag:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 1;
Het zou efficiënter zijn om gewoon de hele tabel te scannen, dan de index te gebruiken voor een zoekopdracht en vervolgens 991 bladwijzerzoekopdrachten uit te voeren om de waarde voor Filler te krijgen , echter met slechts 1 rij de volgende vraag:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 2;
zal efficiënter zijn om een index te zoeken, en een enkele bladwijzer opzoeken om de waarde voor Filler te krijgen (en het uitvoeren van deze twee zoekopdrachten zal dit bevestigen)
Ik ben er vrij zeker van dat de grens voor het opzoeken en opzoeken van bladwijzers varieert, afhankelijk van de situatie, maar het is vrij laag. Met behulp van de voorbeeldtabel, met een beetje vallen en opstaan, ontdekte ik dat ik de Val . nodig had kolom om 38 rijen te hebben met de waarde 2 voordat de optimizer voor een volledige tabelscan ging over een indexzoekopdracht en bladwijzerzoekopdracht:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
DECLARE @I INT = 38;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP (991 - @i) 1
FROM sys.all_objects a
UNION ALL
SELECT TOP (@i) 2
FROM sys.all_objects a
UNION ALL
SELECT TOP 8 ROW_NUMBER() OVER(ORDER BY a.object_id) + 2
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
SELECT COUNT(Filler), COUNT(*)
FROM #T
WHERE Val = 2;
Dus voor dit voorbeeld is de limiet 3,7% van de overeenkomende rijen.
Aangezien de query niet weet hoeveel rijen overeenkomen wanneer u een variabele gebruikt, moet hij raden, en de eenvoudigste manier is door het totale aantal rijen te achterhalen en dit te delen door het totale aantal afzonderlijke waarden in de kolom, dus in dit voorbeeld het geschatte aantal rijen voor WHERE val = @Val is 1000 / 10 =100. Het eigenlijke algoritme is complexer dan dit, maar dit is bijvoorbeeld voldoende. Dus als we kijken naar het uitvoeringsplan voor:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
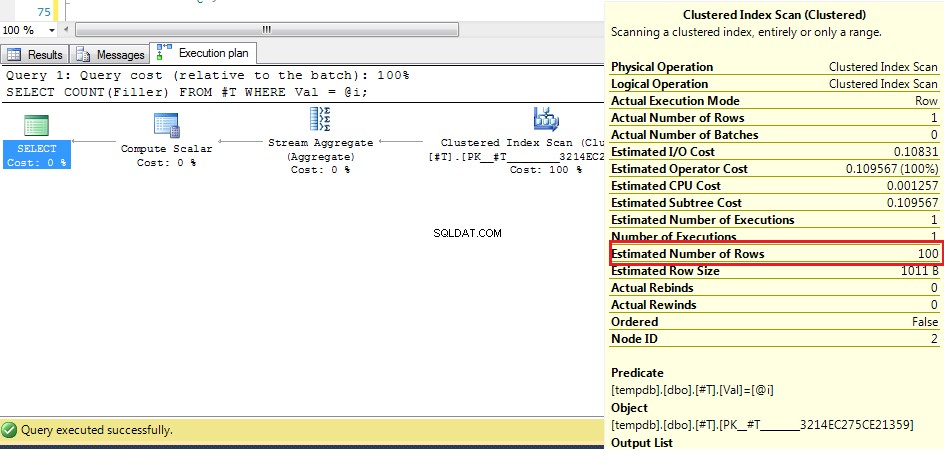
We kunnen hier (met de originele gegevens) zien dat het geschatte aantal rijen 100 is, maar het werkelijke aantal is 1. Uit de vorige stappen weten we dat met meer dan 38 rijen de optimizer zal kiezen voor een geclusterde indexscan over een index zoeken, dus aangezien de beste schatting voor het aantal rijen hoger is dan dit, is het plan voor een onbekende variabele een geclusterde indexscan.
Om de theorie verder te bewijzen, als we de tabel maken met 1000 rijen getallen 1-27 gelijkmatig verdeeld (dus het geschatte aantal rijen is ongeveer 1000 / 27 =37.037)
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 27 ROW_NUMBER() OVER(ORDER BY a.object_id)
FROM sys.all_objects a;
INSERT #T (val)
SELECT TOP 973 t1.Val
FROM #T AS t1
CROSS JOIN #T AS t2
CROSS JOIN #T AS t3
ORDER BY t2.Val, t3.Val;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Voer vervolgens de query opnieuw uit, we krijgen een plan met een indexzoekopdracht:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
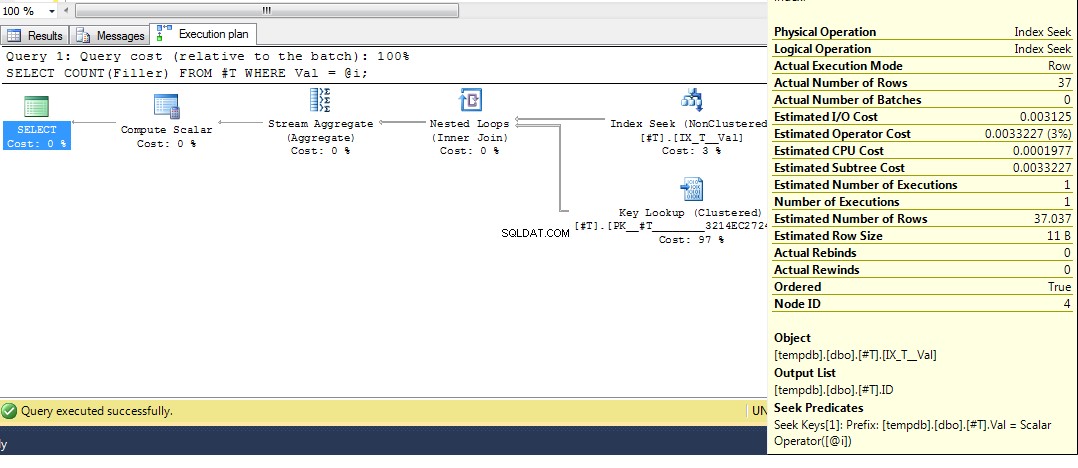
Dus hopelijk dekt dat vrij uitgebreid waarom je dat plan krijgt. Nu veronderstel ik dat de volgende vraag is hoe je een ander plan forceert, en het antwoord is, om de vraaghint te gebruiken OPTION (RECOMPILE) , om te forceren dat de query wordt gecompileerd tijdens de uitvoering wanneer de waarde van de parameter bekend is. Terugkeren naar de oorspronkelijke gegevens, waar het beste plan voor Val = 2 is een opzoeking, maar het gebruik van een variabele levert een plan op met een indexscan, we kunnen uitvoeren:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
GO
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i
OPTION (RECOMPILE);
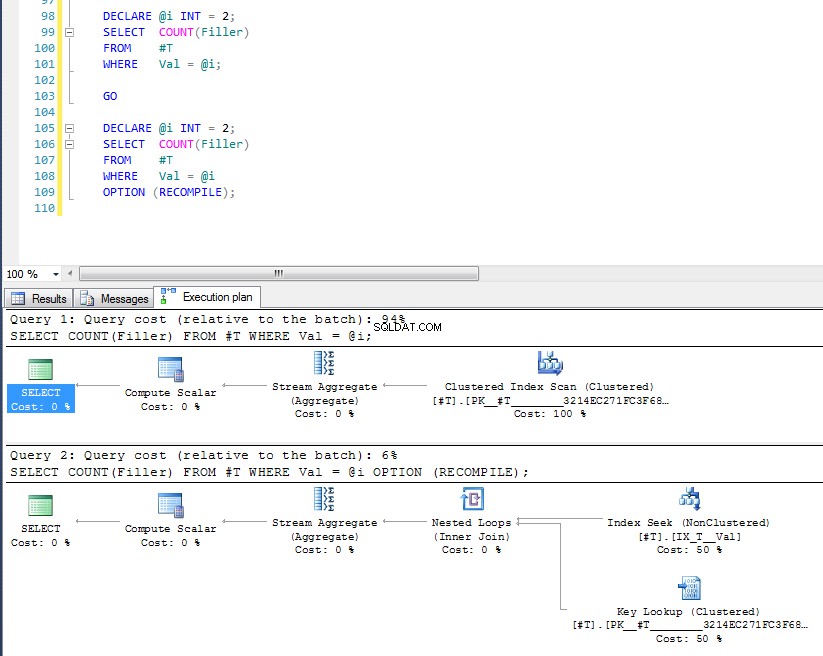
We kunnen zien dat de laatste de indexzoek- en sleutelzoekopdracht gebruikt, omdat het de waarde van variabele heeft gecontroleerd tijdens de uitvoeringstijd en het meest geschikte plan voor die specifieke waarde is gekozen. Het probleem met OPTION (RECOMPILE) is dat dit betekent dat u geen gebruik kunt maken van queryplannen in de cache, dus er zijn extra kosten verbonden aan het elke keer compileren van de query.