Eerder in deze serie (Deel 1 | Deel 2) hebben we het gehad over het genereren van een reeks getallen met behulp van verschillende technieken. Hoewel interessant en nuttig in sommige scenario's, is een meer praktische toepassing het genereren van een reeks aaneengesloten datums; bijvoorbeeld een rapport waarin alle dagen van een maand moeten worden weergegeven, zelfs als er op sommige dagen geen transacties waren.
In een eerdere post heb ik al vermeld dat het makkelijk is om een reeks dagen af te leiden uit een reeks cijfers. Aangezien we al meerdere manieren hebben gevonden om een reeks getallen af te leiden, laten we eens kijken hoe de volgende stap eruitziet. Laten we heel eenvoudig beginnen en doen alsof we een rapport willen maken voor drie dagen, van 1 januari tot en met 3 januari, en een rij voor elke dag opnemen. De ouderwetse manier zou zijn om een #temp-tabel te maken, een lus te maken, een variabele te hebben die de huidige dag bevat, binnen de lus een rij in de #temp-tabel in te voegen tot het einde van het bereik, en dan de # te gebruiken temp table to outer join naar onze brongegevens. Dat is meer code dan ik hier wil presenteren, laat staan in productie nemen, onderhouden en waar collega's van leren.
Eenvoudig beginnen
Met een vastgestelde reeks getallen (ongeacht de methode die u kiest), wordt deze taak veel eenvoudiger. Voor dit voorbeeld kan ik complexe sequentiegeneratoren vervangen door een heel eenvoudige unie, aangezien ik maar drie dagen nodig heb. Ik ga ervoor zorgen dat deze set vier rijen bevat, zodat het ook gemakkelijk is om te demonstreren hoe je precies de serie kunt afsnijden die je nodig hebt.
Ten eerste hebben we een aantal variabelen om het begin en einde van het bereik waarin we geïnteresseerd zijn vast te houden:
DECLARE @s DATE = '2012-01-01', @e DATE = '2012-01-03';
Als we nu beginnen met alleen de eenvoudige seriegenerator, kan het er zo uitzien. Ik ga een ORDER BY toevoegen ook hier, voor de zekerheid, aangezien we nooit kunnen vertrouwen op aannames die we maken over de orde.
;WITH n(n) AS (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) SELECT n FROM n ORDER BY n; -- result: n ---- 1 2 3 4
Om dat om te zetten in een reeks datums, kunnen we eenvoudig DATEADD() . toepassen vanaf de startdatum:
;WITH n(n) AS (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) SELECT DATEADD(DAY, n, @s) FROM n ORDER BY n; -- result: ---- 2012-01-02 2012-01-03 2012-01-04 2012-01-05
Dit klopt nog steeds niet helemaal, aangezien ons assortiment op de 2e start in plaats van de 1e. Dus om onze startdatum als basis te gebruiken, moeten we onze set converteren van 1-gebaseerd naar 0-gebaseerd. We kunnen dat doen door 1:af te trekken:
;WITH n(n) AS (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) SELECT DATEADD(DAY, n-1, @s) FROM n ORDER BY n; -- result: ---- 2012-01-01 2012-01-02 2012-01-03 2012-01-04
Bijna daar! We hoeven alleen het resultaat van onze grotere seriebron te beperken, wat we kunnen doen door de DATEDIFF in te voeren , in dagen, tussen het begin en het einde van het bereik, naar een TOP operator – en dan 1 toe te voegen (sinds DATEDIFF rapporteert in wezen een bereik met een open einde).
;WITH n(n) AS (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) DATEADD(DAY, n-1, @s) FROM n ORDER BY n; -- result: ---- 2012-01-01 2012-01-02 2012-01-03
Echte gegevens toevoegen
Om nu te zien hoe we zouden deelnemen aan een andere tabel om een rapport af te leiden, kunnen we onze nieuwe query en outer join gewoon gebruiken tegen de brongegevens.
;WITH n(n) AS ( SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 ), d(OrderDate) AS ( SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) DATEADD(DAY, n-1, @s) FROM n ORDER BY n ) SELECT d.OrderDate, OrderCount = COUNT(o.SalesOrderID) FROM d LEFT OUTER JOIN Sales.SalesOrderHeader AS o ON o.OrderDate >= d.OrderDate AND o.OrderDate < DATEADD(DAY, 1, d.OrderDate) GROUP BY d.OrderDate ORDER BY d.OrderDate;
(Merk op dat we niet langer COUNT(*) kunnen zeggen , aangezien dit de linkerkant meet, wat altijd 1 zal zijn.)
Een andere manier om dit te schrijven zou zijn:
;WITH d(OrderDate) AS
(
SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) DATEADD(DAY, n-1, @s)
FROM
(
SELECT 1 UNION ALL SELECT 2 UNION ALL
SELECT 3 UNION ALL SELECT 4
) AS n(n) ORDER BY n
)
SELECT
d.OrderDate,
OrderCount = COUNT(o.SalesOrderID)
FROM d
LEFT OUTER JOIN Sales.SalesOrderHeader AS o
ON o.OrderDate >= d.OrderDate
AND o.OrderDate < DATEADD(DAY, 1, d.OrderDate)
GROUP BY d.OrderDate
ORDER BY d.OrderDate;
Dit zou het gemakkelijker moeten maken om je voor te stellen hoe je de leidende CTE zou vervangen door het genereren van een datumreeks van elke bron die je kiest. We zullen die doornemen (met uitzondering van de recursieve CTE-aanpak, die alleen diende om grafieken scheef te trekken), met behulp van AdventureWorks2012, maar we zullen de SalesOrderHeaderEnlarged gebruiken tabel die ik heb gemaakt op basis van dit script door Jonathan Kehayias. Ik heb een index toegevoegd om te helpen met deze specifieke vraag:
CREATE INDEX d_so ON Sales.SalesOrderHeaderEnlarged(OrderDate);
Houd er ook rekening mee dat ik een willekeurig datumbereik kies waarvan ik weet dat het bestaat in de tabel.
Getallentabel
;WITH d(OrderDate) AS ( SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) DATEADD(DAY, n-1, @s) FROM dbo.Numbers ORDER BY n ) SELECT d.OrderDate, OrderCount = COUNT(s.SalesOrderID) FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s ON s.OrderDate >= @s AND s.OrderDate <= @e AND CONVERT(DATE, s.OrderDate) = d.OrderDate WHERE d.OrderDate >= @s AND d.OrderDate <= @e GROUP BY d.OrderDate ORDER BY d.OrderDate;
Plan (klik om te vergroten):
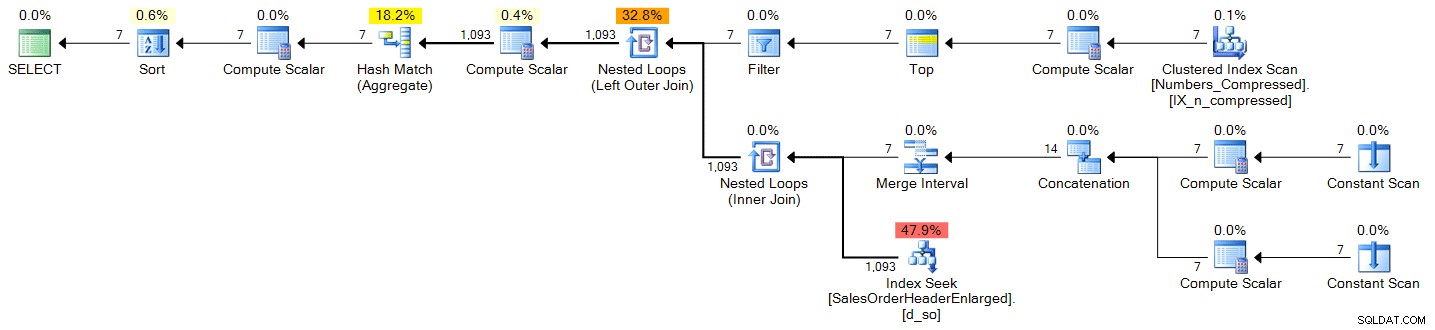
spt_values
DECLARE @s DATE = '2006-10-23', @e DATE = '2006-10-29'; ;WITH d(OrderDate) AS ( SELECT DATEADD(DAY, n-1, @s) FROM (SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) ROW_NUMBER() OVER (ORDER BY Number) FROM master..spt_values) AS x(n) ) SELECT d.OrderDate, OrderCount = COUNT(s.SalesOrderID) FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s ON s.OrderDate >= @s AND s.OrderDate <= @e AND CONVERT(DATE, s.OrderDate) = d.OrderDate WHERE d.OrderDate >= @s AND d.OrderDate <= @e GROUP BY d.OrderDate ORDER BY d.OrderDate;
Plan (klik om te vergroten):
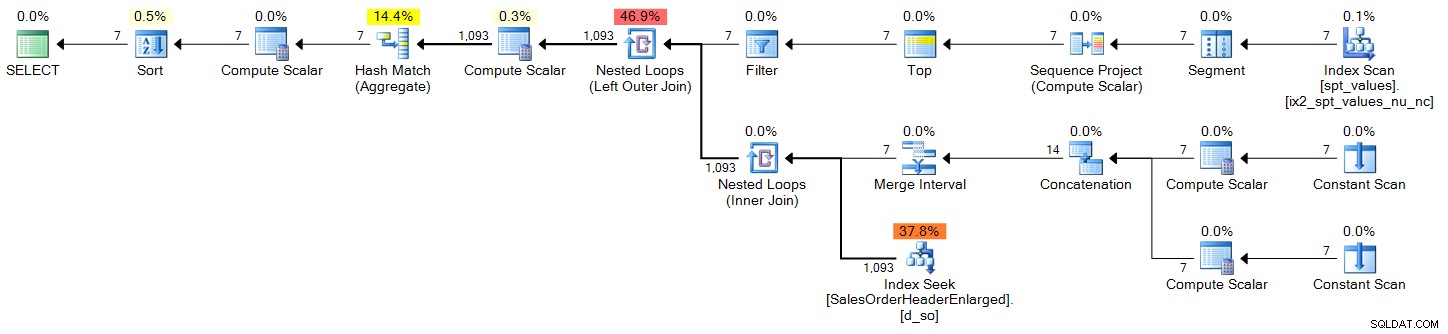
sys.all_objects
DECLARE @s DATE = '2006-10-23', @e DATE = '2006-10-29'; ;WITH d(OrderDate) AS ( SELECT DATEADD(DAY, n-1, @s) FROM (SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) ROW_NUMBER() OVER (ORDER BY [object_id]) FROM sys.all_objects) AS x(n) ) SELECT d.OrderDate, OrderCount = COUNT(s.SalesOrderID) FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s ON s.OrderDate >= @s AND s.OrderDate <= @e AND CONVERT(DATE, s.OrderDate) = d.OrderDate WHERE d.OrderDate >= @s AND d.OrderDate <= @e GROUP BY d.OrderDate ORDER BY d.OrderDate;
Plan (klik om te vergroten):
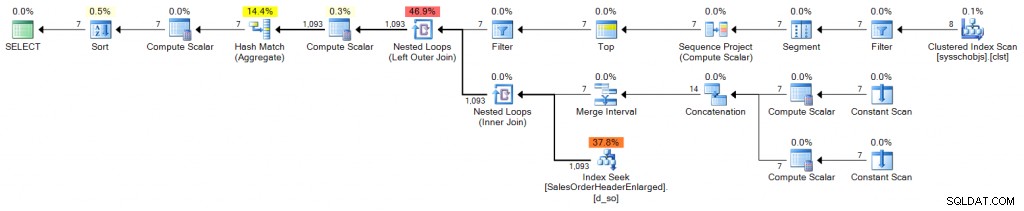
Gestapelde CTE's
DECLARE @s DATE = '2006-10-23', @e DATE = '2006-10-29';
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
),
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b),
d(OrderDate) AS
(
SELECT TOP (DATEDIFF(DAY, @s, @e) + 1)
d = DATEADD(DAY, ROW_NUMBER() OVER (ORDER BY n)-1, @s)
FROM e2
)
SELECT
d.OrderDate,
OrderCount = COUNT(s.SalesOrderID)
FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s
ON s.OrderDate >= @s AND s.OrderDate <= @e
AND d.OrderDate = CONVERT(DATE, s.OrderDate)
WHERE d.OrderDate >= @s AND d.OrderDate <= @e
GROUP BY d.OrderDate
ORDER BY d.OrderDate; Plan (klik om te vergroten):
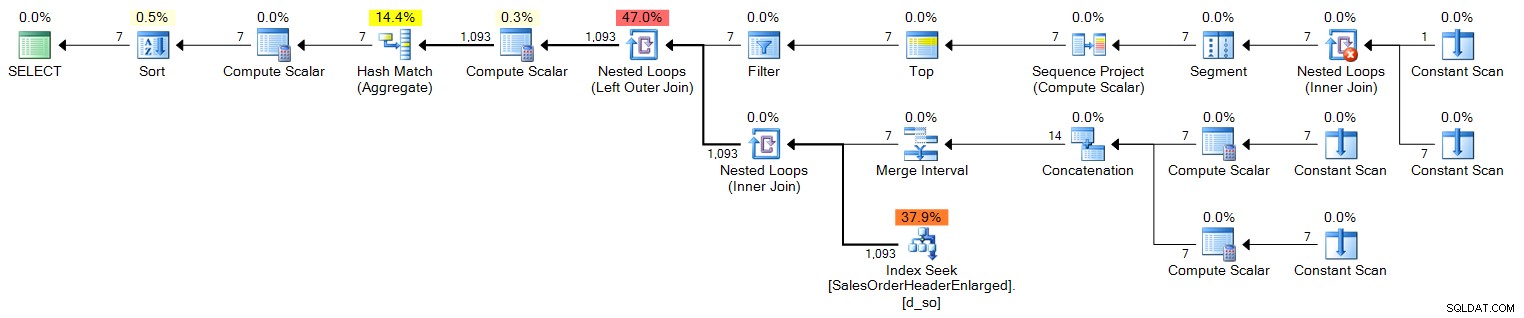
Nu, voor een jaar lang, zal dit niet genoeg zijn, omdat het slechts 100 rijen produceert. Een jaar lang zouden we 366 rijen moeten bestrijken (om rekening te houden met mogelijke schrikkeljaren), dus het zou er als volgt uitzien:
DECLARE @s DATE = '2006-10-23', @e DATE = '2007-10-22';
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
),
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b),
e3(n) AS (SELECT 1 FROM e2 CROSS JOIN (SELECT TOP (37) n FROM e2) AS b),
d(OrderDate) AS
(
SELECT TOP (DATEDIFF(DAY, @s, @e) + 1)
d = DATEADD(DAY, ROW_NUMBER() OVER (ORDER BY N)-1, @s)
FROM e3
)
SELECT
d.OrderDate,
OrderCount = COUNT(s.SalesOrderID)
FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s
ON s.OrderDate >= @s AND s.OrderDate <= @e
AND d.OrderDate = CONVERT(DATE, s.OrderDate)
WHERE d.OrderDate >= @s AND d.OrderDate <= @e
GROUP BY d.OrderDate
ORDER BY d.OrderDate; Plan (klik om te vergroten):
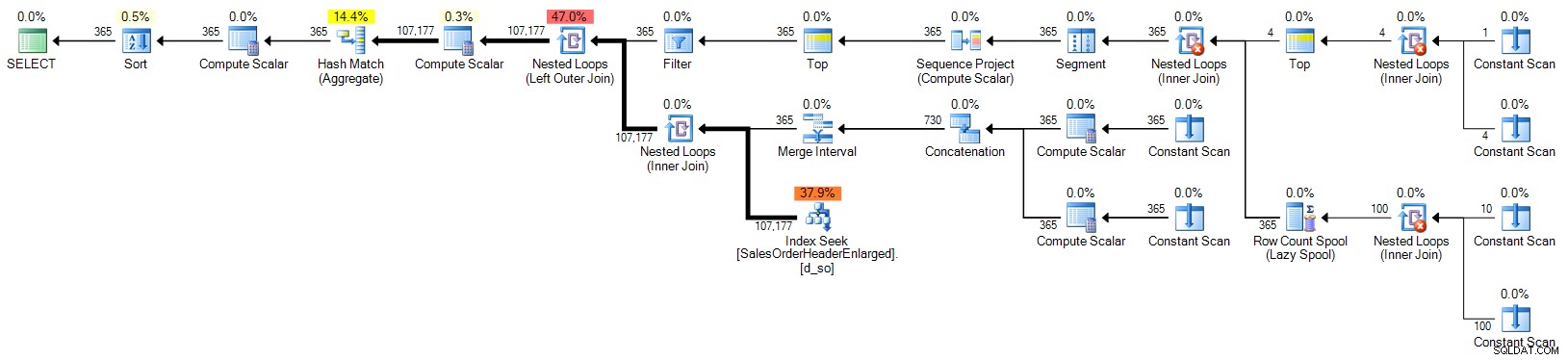
Kalendertabel
Dit is een nieuwe waar we in de vorige twee berichten niet veel over hebben gesproken. Als u voor veel zoekopdrachten datumreeksen gebruikt, kunt u overwegen om zowel een Numbers-tabel als een Calendar-tabel te gebruiken. Hetzelfde argument geldt over hoeveel ruimte echt nodig is en hoe snel toegang zal zijn wanneer de tabel vaak wordt opgevraagd. Om bijvoorbeeld 30 jaar aan datums op te slaan, zijn er minder dan 11.000 rijen nodig (het exacte aantal hangt af van het aantal schrikkeljaren dat u overspant) en neemt het slechts 200 KB in beslag. Ja, je leest het goed:200 kilobytes . (En gecomprimeerd, het is slechts 136 KB.)
Om een kalendertabel met 30 jaar aan gegevens te genereren, ervan uitgaande dat u er al van overtuigd bent dat het hebben van een Numbers-tabel een goede zaak is, kunnen we dit doen:
DECLARE @s DATE = '2005-07-01'; -- earliest year in SalesOrderHeader DECLARE @e DATE = DATEADD(DAY, -1, DATEADD(YEAR, 30, @s)); SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) d = CONVERT(DATE, DATEADD(DAY, n-1, @s)) INTO dbo.Calendar FROM dbo.Numbers ORDER BY n; CREATE UNIQUE CLUSTERED INDEX d ON dbo.Calendar(d);
Om die kalendertabel nu te gebruiken in onze verkooprapportquery, kunnen we een veel eenvoudigere query schrijven:
DECLARE @s DATE = '2006-10-23', @e DATE = '2006-10-29'; SELECT OrderDate = c.d, OrderCount = COUNT(s.SalesOrderID) FROM dbo.Calendar AS c LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s ON s.OrderDate >= @s AND s.OrderDate <= @e AND c.d = CONVERT(DATE, s.OrderDate) WHERE c.d >= @s AND c.d <= @e GROUP BY c.d ORDER BY c.d;
Plan (klik om te vergroten):

Prestaties
Ik maakte zowel gecomprimeerde als niet-gecomprimeerde kopieën van de tabellen Numbers en Calendar en testte een bereik van één week, één maand en een jaar. Ik heb ook zoekopdrachten uitgevoerd met koude cache en warme cache, maar dat bleek grotendeels inconsequent te zijn.
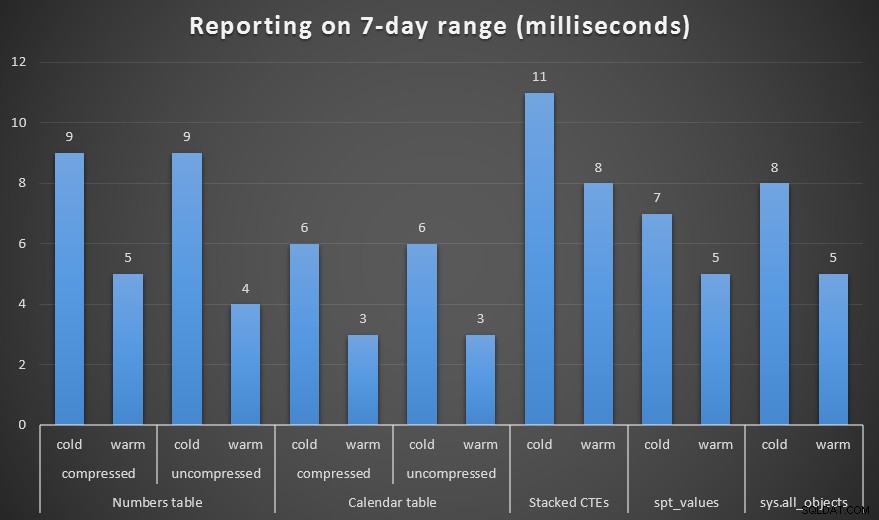
Duur, in milliseconden, om een bereik van een week te genereren
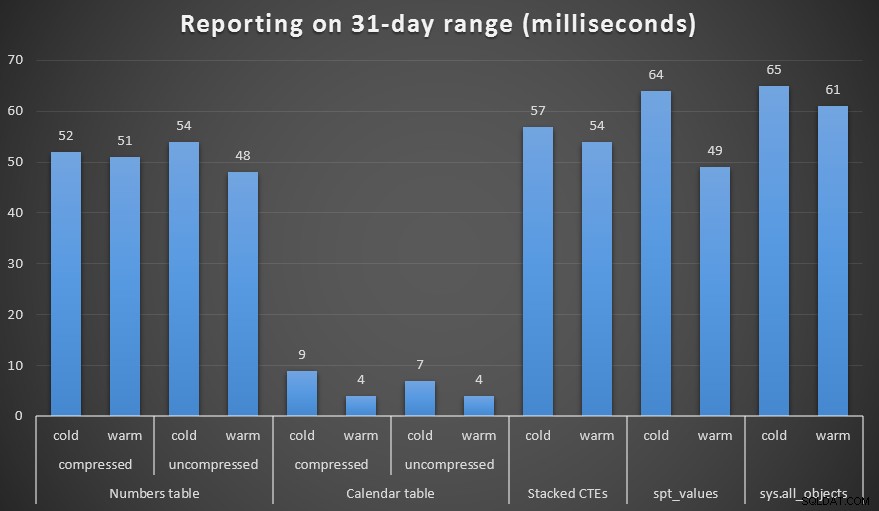
Duur, in milliseconden, om een bereik van een maand te genereren
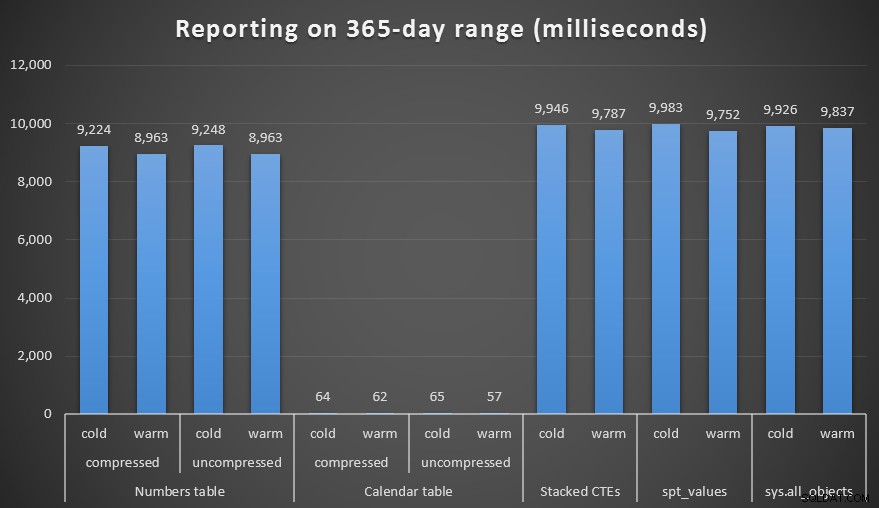
Duur, in milliseconden, om een bereik van een jaar te genereren
Aanvulling
Paul White (blog | @SQL_Kiwi) wees erop dat je de Numbers-tabel kunt dwingen een veel efficiënter plan te maken met de volgende query:
SELECT OrderDate = DATEADD(DAY, n, 0), OrderCount = COUNT(s.SalesOrderID) FROM dbo.Numbers AS n LEFT OUTER JOIN Sales.SalesOrderHeader AS s ON s.OrderDate >= CONVERT(DATETIME, @s) AND s.OrderDate < DATEADD(DAY, 1, CONVERT(DATETIME, @e)) AND DATEDIFF(DAY, 0, OrderDate) = n WHERE n.n >= DATEDIFF(DAY, 0, @s) AND n.n <= DATEDIFF(DAY, 0, @e) GROUP BY n ORDER BY n;
Op dit moment ga ik niet alle prestatietests opnieuw uitvoeren (oefening voor de lezer!), maar ik ga ervan uit dat het betere of vergelijkbare timings zal genereren. Toch denk ik dat een kalendertafel handig is om te hebben, zelfs als het niet strikt noodzakelijk is.
Conclusie
De resultaten spreken voor zich. Voor het genereren van een reeks getallen wint de getallentabelbenadering, maar slechts marginaal - zelfs bij 1.000.000 rijen. En voor een reeks datums, aan de onderkant, zul je niet veel verschil zien tussen de verschillende technieken. Het is echter vrij duidelijk dat naarmate je datumbereik groter wordt, vooral wanneer je te maken hebt met een grote brontabel, de kalendertabel echt zijn waarde laat zien - vooral gezien de geringe geheugenvoetafdruk. Zelfs met het maffe metrische systeem van Canada is 60 milliseconden veel beter dan ongeveer 10 *seconden* toen het slechts 200 KB op schijf kostte.
Ik hoop dat je genoten hebt van deze kleine serie; het is een onderwerp dat ik al eeuwenlang opnieuw wil bekijken.
[ Deel 1 | Deel 2 | Deel 3 ]