Vind je het leuk om strings te ontleden? Als dat zo is, is SQL SUBSTRING een van de onmisbare tekenreeksfuncties om te gebruiken. Het is een van die vaardigheden die een ontwikkelaar voor elke taal zou moeten hebben.
Dus, hoe doe je dat?
Belangrijke punten bij het ontleden van strings
Stel dat u nieuw bent in het parseren. Welke belangrijke punten moet je onthouden?
- Weet welke informatie in de tekenreeks is ingesloten.
- Verkrijg de exacte posities van elk stukje informatie in een string. Mogelijk moet u alle tekens in de tekenreeks tellen.
- Weet de grootte of lengte van elk informatiestuk in een string.
- Gebruik de juiste tekenreeksfunctie die elk stukje informatie in de tekenreeks gemakkelijk kan extraheren.
Als u al deze factoren kent, bent u voorbereid op het gebruik van SQL SUBSTRING() en het doorgeven van argumenten.
SQL SUBSTRING-syntaxis

De syntaxis van SQL SUBSTRING is als volgt:
SUBSTRING(tekenreeksuitdrukking, begin, lengte)
- tekenreeksuitdrukking – a letterlijke tekenreeks of een SQL-expressie die een tekenreeks retourneert.
- begin – een nummer waar de extractie begint. Het is ook 1-gebaseerd:het eerste teken in het tekenreeksexpressieargument moet beginnen met 1, niet 0. In SQL Server is het altijd een positief getal. In MySQL of Oracle kan het echter positief of negatief zijn. Indien negatief, begint het scannen vanaf het einde van de string.
- lengte – de lengte van de tekens die moeten worden geëxtraheerd. SQL Server vereist het. In MySQL of Oracle is het optioneel.
4 voorbeelden van SQL SUBSTRING
1. SQL SUBSTRING gebruiken om uit een letterlijke tekenreeks te extraheren
Laten we beginnen met een eenvoudig voorbeeld met een letterlijke tekenreeks. We gebruiken de naam van een beroemde Koreaanse meidengroep, BlackPink, en figuur 1 illustreert hoe SUBSTRING zal werken:

De onderstaande code laat zien hoe we het gaan extraheren:
-- extract 'black' from BlackPink (English)
SELECT SUBSTRING('BlackPink',1,5) AS result
Laten we nu ook eens kijken naar de resultatenset in Afbeelding 2:
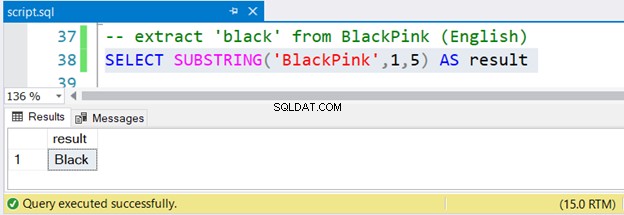
Is het niet gemakkelijk?
Zwart extraheren van BlackPink , begin je vanaf positie 1 en eindig je op positie 5. Sinds BlackPink is Koreaans, laten we kijken of SUBSTRING werkt op Unicode Koreaanse karakters.
(DISCLAIMER :Ik kan geen Koreaans spreken, lezen of schrijven, dus ik heb de Koreaanse vertaling van Wikipedia. Ik heb ook Google Translate gebruikt om te zien welke tekens overeenkomen met Zwart en Roze . Vergeef me als het verkeerd is. Toch hoop ik dat het punt dat ik probeer te verduidelijken komt і over)
Laten we de string in het Koreaans nemen (zie figuur 3). De gebruikte Koreaanse karakters vertaalt zich naar BlackPink:

Zie nu de onderstaande code. We extraheren twee tekens die overeenkomen met Zwart .
-- extract 'black' from BlackPink (Korean)
SELECT SUBSTRING(N'블랙핑크',1,2) AS result
Heb je de Koreaanse tekenreeks opgemerkt, voorafgegaan door N ? Het gebruikt Unicode-tekens en de SQL Server gaat uit van NVARCHAR en moet worden voorafgegaan door N . Dat is het enige verschil in de Engelse versie. Maar zal het wel goed lopen? Zie afbeelding 4:
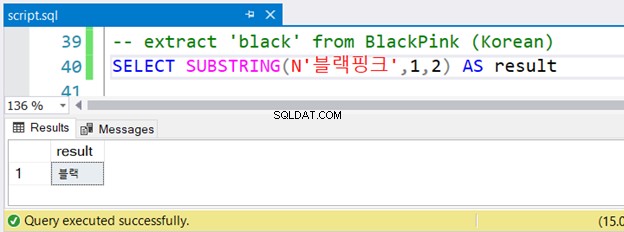
Het liep zonder fouten.
2. SQL SUBSTRING gebruiken in MySQL met een negatief startargument
Het hebben van een negatief startargument werkt niet in SQL Server. Maar we kunnen hier een voorbeeld van hebben met MySQL. Laten we deze keer Roze . extraheren van BlackPink . Hier is de code:
-- Extract 'Pink' from BlackPink using MySQL Substring (English)
select substring('BlackPink',-4,4) as result;
Laten we nu het resultaat hebben in Afbeelding 5:
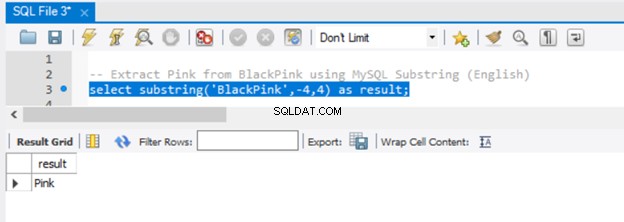
Omdat we -4 hebben doorgegeven aan de startparameter, begon de extractie vanaf het einde van de string, met 4 tekens achteruit. Gebruik de functie RIGHT() om hetzelfde resultaat te bereiken in SQL Server.
Unicode-tekens werken ook met MySQL SUBSTRING, zoals je kunt zien in figuur 6:
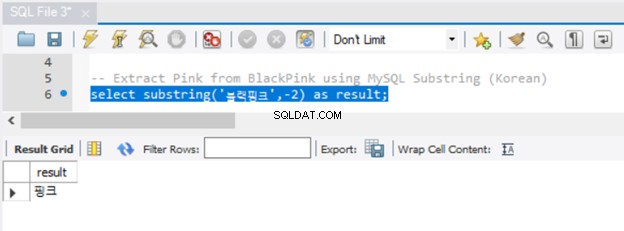
Het werkte prima. Maar is het je opgevallen dat we de string niet vooraf hoeven te laten gaan aan een N? Merk ook op dat er verschillende manieren zijn om een substring in MySQL te krijgen. Je hebt SUBSTRING al gezien. De equivalente functies in MySQL zijn SUBSTR() en MID().
3. Substrings ontleden met variabele start- en lengteargumenten
Helaas gebruiken niet alle string-extracties vaste start- en lengteargumenten. In een dergelijk geval hebt u CHARINDEX nodig om de positie te krijgen van een tekenreeks waarop u zich richt. Laten we een voorbeeld geven:
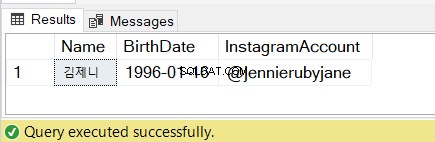
DECLARE @lineString NVARCHAR(30) = N'김제니 01/16/example@sqldat.com'
DECLARE @name NVARCHAR(5)
DECLARE @bday DATE
DECLARE @instagram VARCHAR(20)
SET @name = SUBSTRING(@lineString,1,CHARINDEX('@',@lineString)-11)
SET @bday = SUBSTRING(@lineString,CHARINDEX('@',@lineString)-10,10)
SET @instagram = SUBSTRING(@lineString,CHARINDEX('@',@lineString),30)
SELECT @name AS [Name], @bday AS [BirthDate], @instagram AS [InstagramAccount]
In de bovenstaande code moet je een naam in het Koreaans, de geboortedatum en het Instagram-account extraheren.
We beginnen met het definiëren van drie variabelen om die stukjes informatie vast te houden. Daarna kunnen we de string ontleden en de resultaten aan elke variabele toewijzen.
U denkt misschien dat het eenvoudiger is om vaste starts en lengtes te hebben. Bovendien kunnen we het lokaliseren door de karakters handmatig te tellen. Maar wat als je er veel van op tafel hebt staan?
Dit is onze analyse:
- Het enige vaste item in de string is de @ karakter in het Instagram-account. We kunnen zijn positie in de string krijgen met CHARINDEX. Vervolgens gebruiken we die positie om het begin en de lengtes van de rest te krijgen.
- De geboortedatum heeft een vast formaat met MM/dd/jjjj met 10 tekens.
- Om de naam te extraheren, beginnen we bij 1. Aangezien de geboortedatum 10 tekens heeft plus de @ teken, kunt u naar het eindteken van de naam in de tekenreeks gaan. Vanuit de positie van de @ karakter, we gaan 11 karakters terug. De SUBSTRING(@lineString,1,CHARINDEX(‘@’,@lineString)-11) is de juiste keuze.
- Om de geboortedatum te krijgen, passen we dezelfde logica toe. Krijg de positie van de @ teken en verplaats 10 tekens achteruit om de startwaarde van de geboortedatum te krijgen. 10 is een vaste lengte. SUBSTRING(@lineString,CHARINDEX(‘@’,@lineString)-10,10) is hoe u de geboortedatum kunt krijgen.
- Ten slotte is het eenvoudig om een Instagram-account te krijgen. Begin vanaf de positie van de @ teken met behulp van CHARINDEX. Opmerking:30 is de gebruikersnaamlimiet voor Instagram.
Bekijk de resultaten in figuur 7:
4. SQL SUBSTRING gebruiken in een SELECT-instructie
Je kunt SUBSTRING ook gebruiken in de SELECT-instructie, maar eerst hebben we werkgegevens nodig. Hier is de code:
SELECT
CAST(P.LastName AS CHAR(50))
+ CAST(P.FirstName AS CHAR(50))
+ CAST(ISNULL(P.MiddleName,'') AS CHAR(50))
+ CAST(ea.EmailAddress AS CHAR(50))
+ CAST(a.City AS CHAR(30))
+ CAST(a.PostalCode AS CHAR(15)) AS line
INTO PersonContacts
FROM Person.Person p
INNER JOIN Person.EmailAddress ea
ON P.BusinessEntityID = ea.BusinessEntityID
INNER JOIN Person.BusinessEntityAddress bea
ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Person.Address a
ON bea.AddressID = a.AddressID
De bovenstaande code maakt een lange reeks met de naam, het e-mailadres, de stad en de postcode. We willen het ook opslaan in Persoonscontacten tafel.
Laten we nu de code hebben om te reverse-engineeren met SUBSTRING:
SELECT
TRIM(SUBSTRING(line,1,50)) AS [LastName]
,TRIM(SUBSTRING(line,51,50)) AS [FirstName]
,TRIM(SUBSTRING(line,101,50)) AS [MiddleName]
,TRIM(SUBSTRING(line,151,50)) AS [EmailAddress]
,TRIM(SUBSTRING(line,201,30)) AS [City]
,TRIM(SUBSTRING(line,231,15)) AS [PostalCode]
FROM PersonContacts pc
ORDER BY LastName, FirstName
Omdat we kolommen met een vaste grootte hebben gebruikt, is het niet nodig om CHARINDEX te gebruiken.
SQL SUBSTRING gebruiken in een WHERE-clausule - een prestatieval?
Het is waar. Niemand kan je ervan weerhouden SUBSTRING te gebruiken in een WHERE-clausule. Het is een geldige syntaxis. Maar wat als het prestatieproblemen veroorzaakt?
Daarom bewijzen we het met een voorbeeld en bespreken we hoe we dit probleem kunnen oplossen. Maar laten we eerst onze gegevens voorbereiden:
USE AdventureWorks
GO
SELECT * INTO SalesOrders FROM Sales.SalesOrderHeader soh
Ik kan de SalesOrderHeader niet verknoeien tafel, dus heb ik het naar een andere tafel gedumpt. Vervolgens maakte ik de SalesOrderID in de nieuwe SalesOrders tabel een primaire sleutel.
Nu zijn we klaar voor de query. Ik gebruik dbForge Studio voor SQL Server met Queryprofileringsmodus AAN om de zoekopdrachten te analyseren.
SELECT
so.SalesOrderID
,so.OrderDate
,so.CustomerID
,so.AccountNumber
FROM SalesOrders so
WHERE SUBSTRING(so.AccountNumber,4,4) = '4030'
Zoals je ziet, werkt de bovenstaande query prima. Kijk nu naar het Query Profile Plan-diagram in Afbeelding 8:
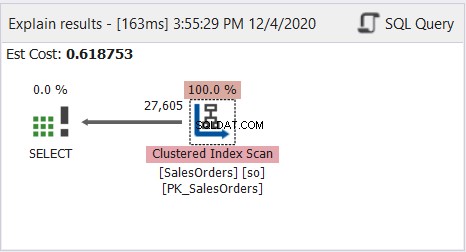
Het plandiagram ziet er eenvoudig uit, maar laten we eens kijken naar de eigenschappen van het knooppunt Clustered Index Scan. We hebben in het bijzonder de Runtime-informatie nodig:
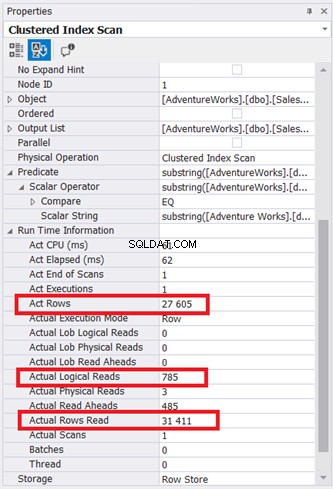
Afbeelding 9 toont 785 * 8KB pagina's gelezen door de database-engine. Merk ook op dat de werkelijke rijen lezen 31.411 is. Het is het totale aantal rijen in de tabel. De query leverde echter slechts 27.605 werkelijke rijen op.
De hele tabel is gelezen met behulp van de geclusterde index als referentie.
Waarom?
Het punt is dat de SQL Server moet weten of 4030 is een substring van een Rekeningnummer. Het moet elk record lezen en evalueren. Gooi de rijen weg die niet gelijk zijn en retourneer de rijen die we nodig hebben. Het klaart de klus, maar niet snel genoeg.
Wat kunnen we doen om het sneller te laten werken?
Vermijd SUBSTRING in de WHERE-clausule en bereik sneller hetzelfde resultaat
Wat we nu willen, is hetzelfde resultaat krijgen zonder SUBSTRING in de WHERE-component te gebruiken. Volg de onderstaande stappen:
- Wijzig de tabel door een berekende kolom toe te voegen met een SUBSTRING(AccountNumber, 4,4) formule. Laten we het AccountCategory noemen bij gebrek aan een betere term.
- Maak een niet-geclusterde index voor de nieuwe AccountCategory kolom. Voeg de OrderDate toe , Accountnummer , en Klant-ID kolommen.
Dat is het.
We wijzigen de WHERE-component van de query om de nieuwe AccountCategory aan te passen kolom:
SET STATISTICS IO ON
SELECT
so.SalesOrderID
,so.OrderDate
,so.CustomerID
,so.AccountNumber
FROM SalesOrders so
WHERE so.AccountCategory = '4030'
SET STATISTICS IO OFF
Er is geen SUBSTRING in de WHERE-component. Laten we nu het plandiagram eens bekijken:
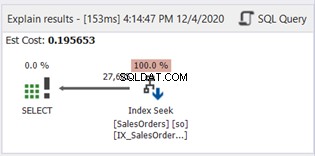
De Index Scan is vervangen door Index Seek. Merk ook op dat de SQL Server de nieuwe index op de berekende kolom heeft gebruikt. Zijn er ook veranderingen in logische reads en daadwerkelijke reads? Zie afbeelding 11:
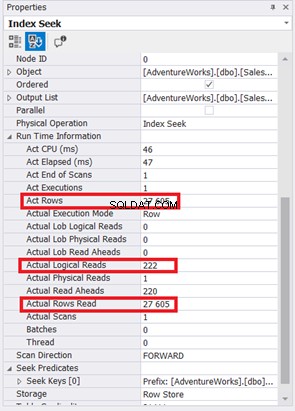
Het terugbrengen van 785 naar 222 logische uitlezingen is een grote verbetering, meer dan drie keer minder dan de oorspronkelijke logische uitlezingen. Het minimaliseerde ook Actual Rows Read tot alleen die rijen die we nodig hebben.
Het gebruik van SUBSTRING in de WHERE-component is dus niet goed voor de prestaties, en het geldt voor elke andere scalaire functie die in de WHERE-component wordt gebruikt.
Conclusie
- Ontwikkelaars kunnen het ontleden van strings niet vermijden. Er zal op de een of andere manier behoefte aan zijn.
- Bij het ontleden van strings is het essentieel om de informatie in de string, de posities van elk stukje informatie en hun grootte of lengte te kennen.
- Een van de parseerfuncties is SQL SUBSTRING. Het heeft alleen de string nodig om te ontleden, de positie om de extractie te starten en de lengte van de string om te extraheren.
- SUBSTRING kan verschillend gedrag vertonen tussen SQL-smaken zoals SQL Server, MySQL en Oracle.
- Je kunt SUBSTRING gebruiken met letterlijke tekenreeksen en tekenreeksen in tabelkolommen.
- We gebruikten ook SUBSTRING met Unicode-tekens.
- Het gebruik van SUBSTRING of een andere scalaire functie in de WHERE-component kan de queryprestaties verminderen. Los dit op met een geïndexeerde berekende kolom.
Als je dit bericht nuttig vindt, deel het dan op je favoriete sociale-mediaplatforms of deel je je reactie hieronder?