In mijn vorige bericht had ik het over manieren om een reeks aaneengesloten getallen van 1 tot 1.000 te genereren. Nu wil ik het hebben over de volgende schaalniveaus:generatorsets van 50.000 en 1.000.000 getallen.
Een set van 50.000 nummers genereren
Toen ik aan deze serie begon, was ik oprecht benieuwd hoe de verschillende benaderingen zouden schalen naar grotere reeksen getallen. Aan de lage kant was ik een beetje verbijsterd toen ik ontdekte dat mijn favoriete aanpak - het gebruik van sys.all_objects – was niet de meest efficiënte methode. Maar hoe zouden deze verschillende technieken worden opgeschaald naar 50.000 rijen?
Getallentabel
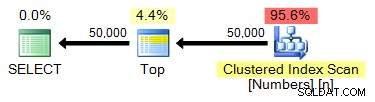
Aangezien we al een Numbers-tabel met 1.000.000 rijen hebben gemaakt, blijft deze zoekopdracht vrijwel identiek:
SELECT TOP (50000) n FROM dbo.Numbers ORDER BY n;
Plan:
spt_values
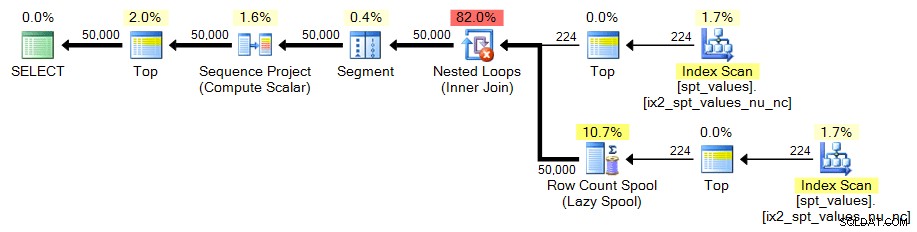
Aangezien er slechts ~ 2500 rijen zijn in spt_values , moeten we wat creatiever zijn als we het willen gebruiken als de bron van onze setgenerator. Een manier om een grotere tabel te simuleren is door CROSS JOIN het tegen zichzelf. Als we dat onbewerkt zouden doen, zouden we eindigen met ~ 2500 rijen in het kwadraat (meer dan 6 miljoen). Omdat we slechts 50.000 rijen nodig hebben, hebben we ongeveer 224 rijen in het kwadraat nodig. Dus we kunnen dit doen:
;WITH x AS ( SELECT TOP (224) number FROM [master]..spt_values ) SELECT TOP (50000) n = ROW_NUMBER() OVER (ORDER BY x.number) FROM x CROSS JOIN x AS y ORDER BY n;
Merk op dat dit gelijk is aan, maar beknopter is dan, deze variatie:
SELECT TOP (50000) n = ROW_NUMBER() OVER (ORDER BY x.number) FROM (SELECT TOP (224) number FROM [master]..spt_values) AS x CROSS JOIN (SELECT TOP (224) number FROM [master]..spt_values) AS y ORDER BY n;
In beide gevallen ziet het plan er als volgt uit:
sys.all_objects
Zoals spt_values , sys.all_objects voldoet op zichzelf niet helemaal aan onze vereiste van 50.000 rijen, dus we zullen een vergelijkbare CROSS JOIN moeten uitvoeren .
;;WITH x AS ( SELECT TOP (224) [object_id] FROM sys.all_objects ) SELECT TOP (50000) n = ROW_NUMBER() OVER (ORDER BY x.[object_id]) FROM x CROSS JOIN x AS y ORDER BY n;
Plan:

Gestapelde CTE's
We hoeven slechts een kleine aanpassing aan onze gestapelde CTE's aan te brengen om precies 50.000 rijen te krijgen:
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), -- 10
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b), -- 10*10
e3(n) AS (SELECT 1 FROM e2 CROSS JOIN e2 AS b), -- 100*100
e4(n) AS (SELECT 1 FROM e3 CROSS JOIN (SELECT TOP 5 n FROM e1) AS b) -- 5*10000
SELECT n = ROW_NUMBER() OVER (ORDER BY n) FROM e4 ORDER BY n; Plan:

Recursieve CTE's
Een nog minder substantiële wijziging is vereist om 50.000 rijen uit onze recursieve CTE te halen:verander de WHERE clausule in 50.000 en verander de MAXRECURSION optie op nul.
;WITH n(n) AS
(
SELECT 1
UNION ALL
SELECT n+1 FROM n WHERE n < 50000
)
SELECT n FROM n ORDER BY n
OPTION (MAXRECURSION 0); Plan:
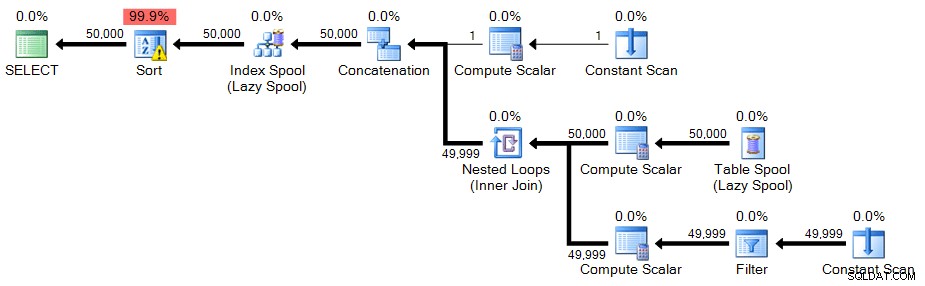
In dit geval is er een waarschuwingspictogram op de sortering - het blijkt dat op mijn systeem de sortering nodig is om naar tempdb te morsen. U ziet misschien geen lekkage op uw systeem, maar dit zou een waarschuwing moeten zijn over de middelen die nodig zijn voor deze techniek.
Prestaties
Net als bij de laatste reeks tests, zullen we elke techniek, inclusief de Numbers-tabel, vergelijken met zowel een koude als een warme cache, en zowel gecomprimeerd als ongecomprimeerd:
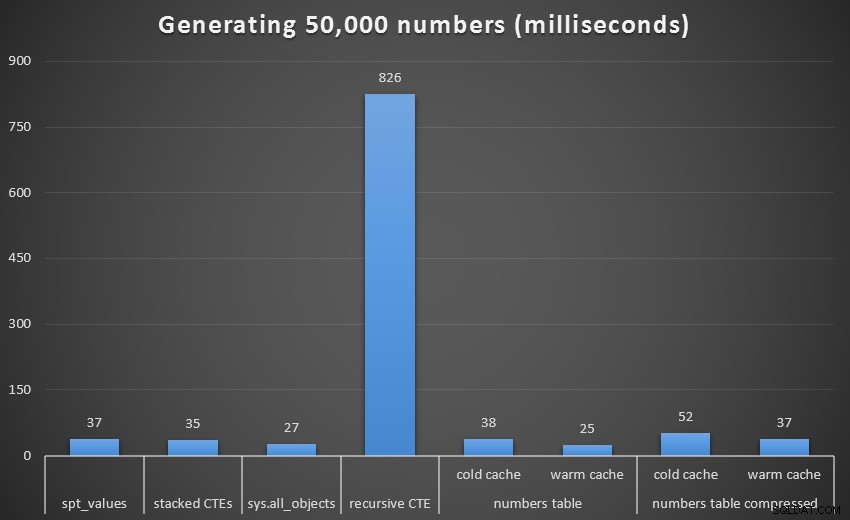
Runtime, in milliseconden, om 50.000 aaneengesloten getallen te genereren
Om een beter zicht te krijgen, laten we de recursieve CTE verwijderen, die een totale hond was in deze test en die de resultaten scheeftrekt:
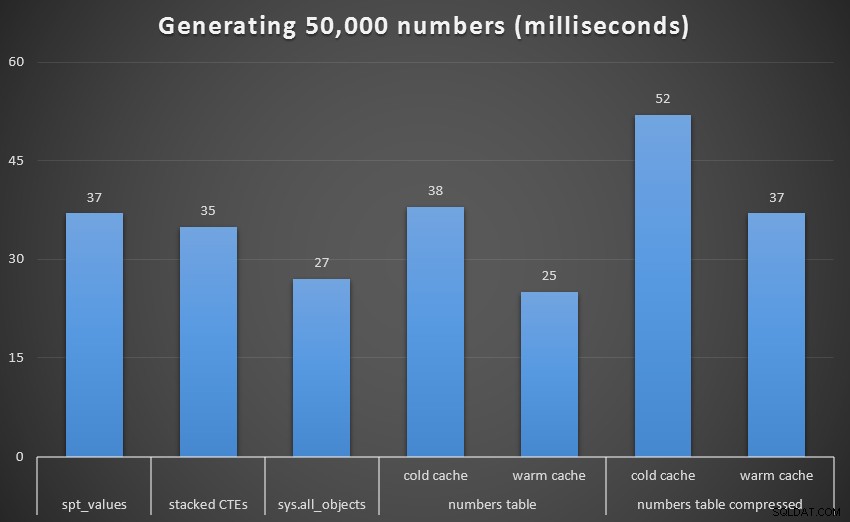
Runtime, in milliseconden, om 50.000 aaneengesloten getallen te genereren (exclusief recursieve CTE)
Bij 1.000 rijen was het verschil tussen gecomprimeerd en ongecomprimeerd marginaal, aangezien de zoekopdracht slechts 8 en 9 pagina's hoefde te lezen. Bij 50.000 rijen wordt de kloof een beetje groter:74 pagina's versus 113. De totale kosten van het decomprimeren van de gegevens lijken echter op te wegen tegen de besparingen in I/O. Dus bij 50.000 rijen lijkt een ongecomprimeerde getallentabel de meest efficiënte methode om een aaneengesloten verzameling af te leiden - hoewel het voordeel weliswaar marginaal is.
Een set van 1.000.000 nummers genereren
Hoewel ik me niet veel gevallen kan voorstellen waarin je zo'n grote aaneengesloten reeks getallen nodig hebt, wilde ik het voor de volledigheid opnemen, en omdat ik een aantal interessante observaties op deze schaal heb gedaan.
Getallentabel
Geen verrassingen hier, onze vraag is nu:
SELECT TOP 1000000 n FROM dbo.Numbers ORDER BY n;
De TOP is niet strikt noodzakelijk, maar dat is alleen omdat we weten dat onze Numbers-tabel en onze gewenste uitvoer hetzelfde aantal rijen hebben. Het plan is nog steeds vrij gelijkaardig aan eerdere tests:
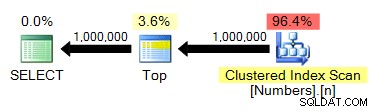
spt_values
Om een CROSS JOIN te krijgen dat 1.000.000 rijen oplevert, moeten we 1.000 rijen in het kwadraat nemen:
;WITH x AS ( SELECT TOP (1000) number FROM [master]..spt_values ) SELECT n = ROW_NUMBER() OVER (ORDER BY x.number) FROM x CROSS JOIN x AS y ORDER BY n;
Plan:
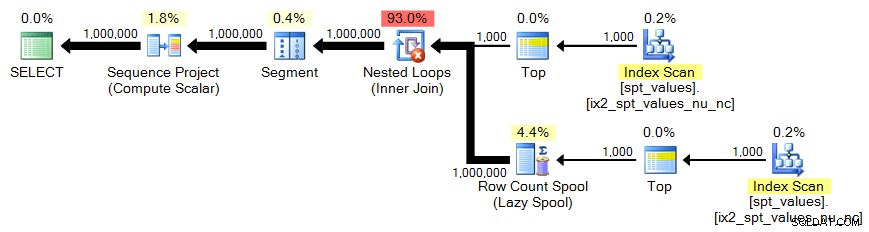
sys.all_objects
Nogmaals, we hebben het kruisproduct van 1.000 rijen nodig:
;WITH x AS ( SELECT TOP (1000) [object_id] FROM sys.all_objects ) SELECT n = ROW_NUMBER() OVER (ORDER BY x.[object_id]) FROM x CROSS JOIN x AS y ORDER BY n;
Plan:

Gestapelde CTE's
Voor de gestapelde CTE hebben we alleen een iets andere combinatie nodig van CROSS JOIN s om naar 1.000.000 rijen te gaan:
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), -- 10
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b), -- 10*10
e3(n) AS (SELECT 1 FROM e1 CROSS JOIN e2 AS b), -- 10*100
e4(n) AS (SELECT 1 FROM e3 CROSS JOIN e3 AS b) -- 1000*1000
SELECT n = ROW_NUMBER() OVER (ORDER BY n) FROM e4 ORDER BY n; Plan:

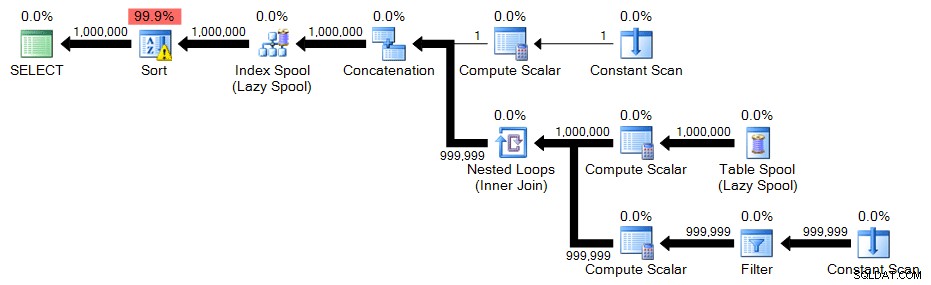
Bij deze rijgrootte kunt u zien dat de gestapelde CTE-oplossing parallel loopt. Dus ik draaide ook een versie met MAXDOP 1 om een soortgelijke planvorm te krijgen als voorheen, en om te zien of parallellisme echt helpt:

Recursieve CTE
De recursieve CTE heeft opnieuw slechts een kleine wijziging; alleen de WHERE clausule moet veranderen:
;WITH n(n) AS
(
SELECT 1
UNION ALL
SELECT n+1 FROM n WHERE n < 1000000
)
SELECT n FROM n ORDER BY n
OPTION (MAXRECURSION 0); Plan:
Prestaties
Wederom zien we dat de prestaties van de recursieve CTE verschrikkelijk zijn:
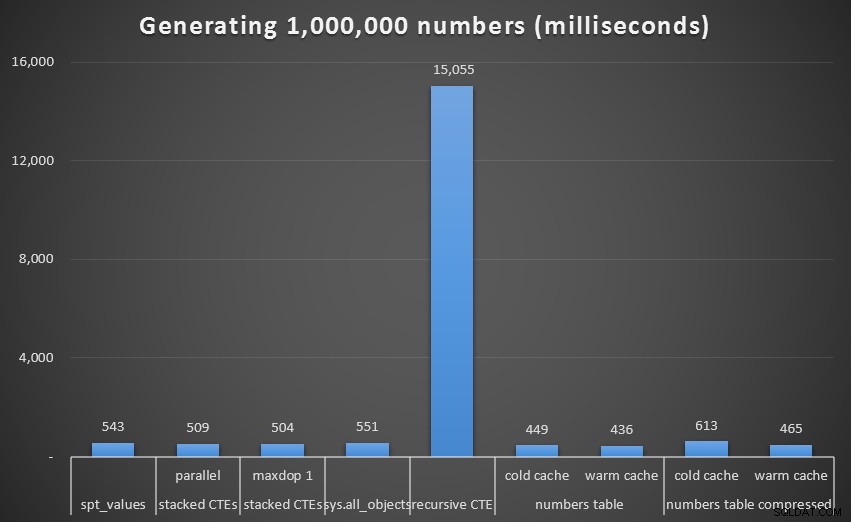
Runtime, in milliseconden, om 1.000.000 aaneengesloten getallen te genereren
Als we die uitbijter uit de grafiek verwijderen, krijgen we een beter beeld van de prestaties:
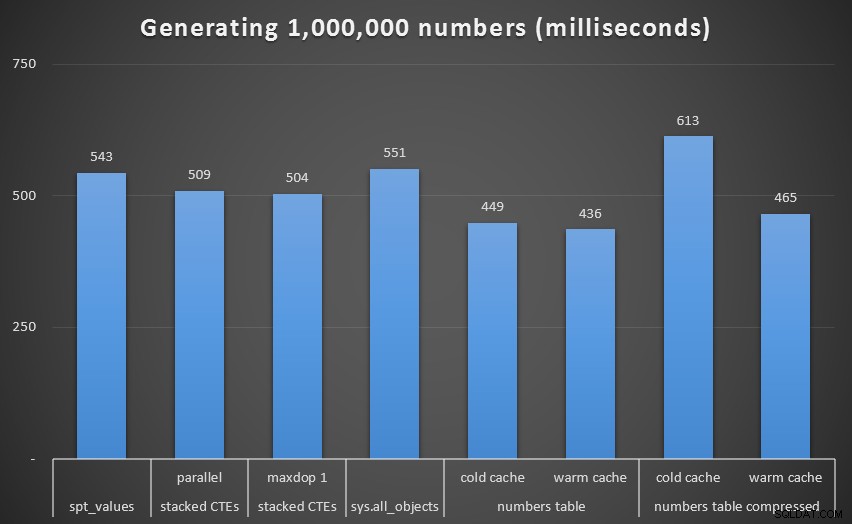
Runtime, in milliseconden, om 1.000.000 aaneengesloten getallen te genereren (exclusief recursieve CTE)
Hoewel we opnieuw de ongecomprimeerde Numbers-tabel (in ieder geval met een warme cache) als winnaar zien, is het verschil zelfs op deze schaal niet zo opmerkelijk.
Wordt vervolgd…
Nu we een handvol benaderingen voor het genereren van een reeks getallen grondig hebben onderzocht, gaan we verder met datums. In de laatste post van deze serie zullen we de constructie van een datumbereik als een set doornemen, inclusief het gebruik van een kalendertabel, en een paar gebruiksgevallen waarbij dit handig kan zijn.
[ Deel 1 | Deel 2 | Deel 3 ]
Bijlage:Rijtellingen
Mogelijk probeert u niet een exact aantal rijen te genereren; misschien wilt u in plaats daarvan gewoon een eenvoudige manier om veel rijen te genereren. Het volgende is een lijst met combinaties van catalogusweergaven die u verschillende rijtellingen opleveren als u gewoon SELECT zonder een WHERE clausule. Merk op dat deze aantallen afhangen van of je een RTM of een servicepack hebt (aangezien sommige systeemobjecten wel worden toegevoegd of gewijzigd), en ook of je een lege database hebt.
| Bron | Rij telt | ||
|---|---|---|---|
| SQL Server 2008 R2 | SQL Server 2012 | SQL Server 2014 | |
| master..spt_values | 2.508 | 2.515 | 2.519 |
| master..spt_values CROSS JOIN master..spt_values | 6.290.064 | 6.325.225 | 6.345.361 |
| sys.all_objects | 1.990 | 2.089 | 2.165 |
| sys.all_columns | 5.157 | 7.276 | 8.560 |
| sys.all_objects CROSS JOIN sys.all_objects | 3.960.100 | 4.363.921 | 4.687.225 |
| sys.all_objects CROSS JOIN sys.all_columns | 10.262.430 | 15.199.564 | 18.532.400 |
| sys.all_columns CROSS JOIN sys.all_columns | 26.594.649 | 52,940,176 | 73,273.600 |
Tabel 1:Aantal rijen voor verschillende zoekopdrachten in catalogusweergave