Dit is het tweede deel in een serie over oplossingen voor de uitdaging voor het genereren van getallenreeksen. Vorige maand heb ik oplossingen behandeld die de rijen on-the-fly genereren met behulp van een tabelwaardeconstructor met rijen op basis van constanten. Er waren geen I/O-bewerkingen bij deze oplossingen betrokken. Deze maand richt ik me op oplossingen die een fysieke basistabel opvragen die u vooraf met rijen vult. Om deze reden zal ik, naast het rapporteren van het tijdprofiel van de oplossingen zoals ik vorige maand deed, ook het I/O-profiel van de nieuwe oplossingen rapporteren. Nogmaals bedankt aan Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason, John Nelson #2 en Ed Wagner voor het delen van jullie ideeën en opmerkingen.
Snelste oplossing tot nu toe
Laten we eerst even ter herinnering kijken naar de snelste oplossing uit het artikel van vorige maand, geïmplementeerd als een inline TVF genaamd dbo.GetNumsAlanCharlieItzikBatch.
Ik doe mijn tests in tempdb, waardoor IO- en TIME-statistieken worden ingeschakeld:
SET NOCOUNT ON; USE tempdb; SET STATISTICS IO, TIME ON;
De snelste oplossing van vorige maand past een join toe met een dummy-tabel die een columnstore-index heeft om batchverwerking te krijgen. Hier is de code om de dummy-tabel te maken:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
En hier is de code met de definitie van de dbo.GetNumsAlanCharlieItzikBatch-functie:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Vorige maand heb ik de volgende code gebruikt om de prestaties van de functie te testen met 100 miljoen rijen, nadat ik de resultaten negeren na uitvoering in SSMS had ingeschakeld om het retourneren van de uitvoerrijen te onderdrukken:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Dit zijn de tijdstatistieken die ik voor deze uitvoering heb gekregen:
CPU-tijd =16031 ms, verstreken tijd =17172 ms.Joe Obbish merkte terecht op dat deze test de weergave van sommige real-life scenario's zou kunnen missen, in die zin dat een groot deel van de runtime te wijten is aan asynchrone netwerk-I/O-wachttijden (ASYNC_NETWORK_IO wachttype). U kunt de hoogste wachttijden zien door naar de eigenschappenpagina van het hoofdknooppunt van het eigenlijke queryplan te kijken, of u kunt een uitgebreide gebeurtenissessie uitvoeren met wachtinformatie. Het feit dat u Resultaten negeren na uitvoering in SSMS inschakelt, verhindert niet dat SQL Server de resultaatrijen naar SSMS verzendt; het voorkomt gewoon dat SSMS ze afdrukt. De vraag is, hoe waarschijnlijk is het dat u in real-life scenario's grote resultatensets aan de klant zult retourneren, zelfs als u de functie gebruikt om een grote reeks getallen te produceren? Misschien schrijft u vaker de queryresultaten naar een tabel, of gebruikt u het resultaat van de functie als onderdeel van een query die uiteindelijk een kleine resultatenset oplevert. Je moet dit uitzoeken. Je zou de resultatenset in een tijdelijke tabel kunnen schrijven met behulp van de SELECT INTO-instructie, of je zou de truc van Alan Burstein kunnen gebruiken met een toewijzings-SELECT-instructie, die de waarde van de resultaatkolom aan een variabele toewijst.
Hier ziet u hoe u de laatste test zou wijzigen om de variabele toewijzingsoptie te gebruiken:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Dit zijn de tijdstatistieken die ik voor deze test heb gekregen:
CPU-tijd =8641 ms, verstreken tijd =8645 ms.Deze keer heeft de wachtinformatie geen asynchrone netwerk-I/O-wachten, en je kunt de aanzienlijke daling van de runtime zien.
Test de functie opnieuw, deze keer met bestellen:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Ik heb de volgende prestatiestatistieken voor deze uitvoering:
CPU-tijd =9360 ms, verstreken tijd =9551 ms.Bedenk dat er geen sorteeroperator nodig is in het plan voor deze query, aangezien de kolom n is gebaseerd op een uitdrukking die de volgorde behoudt met betrekking tot de kolom rownum. Dat is te danken aan Charli's constante vouwtruc, die ik vorige maand behandelde. De plannen voor beide zoekopdrachten - die zonder bestellen en die met bestellen zijn hetzelfde, dus de prestaties zijn meestal vergelijkbaar.
Afbeelding 1 vat de prestatiecijfers samen die ik heb gekregen voor de oplossingen van vorige maand, alleen deze keer met variabele toewijzing in de tests in plaats van de resultaten na uitvoering weg te gooien.
 Figuur 1:Prestatiesamenvatting tot nu toe met variabele toewijzing
Figuur 1:Prestatiesamenvatting tot nu toe met variabele toewijzing
Ik zal de variabele toewijzingstechniek gebruiken om de rest van de oplossingen te testen die ik in dit artikel zal presenteren. Zorg ervoor dat u uw tests aanpast aan uw werkelijke situatie, met behulp van variabele toewijzing, SELECT INTO, resultaten weggooien na uitvoering of een andere techniek.
Tip voor het forceren van seriële abonnementen zonder MAXDOP 1
Voordat ik nieuwe oplossingen presenteer, wilde ik alleen een kleine tip geven. Bedenk dat sommige oplossingen het beste presteren bij gebruik van een serieel abonnement. De voor de hand liggende manier om dit te forceren is met een MAXDOP 1-queryhint. En dat is de juiste weg als u soms parallellisme wilt inschakelen en soms niet. Maar wat als u altijd een serieel plan wilt forceren bij het gebruik van de functie, zij het een minder waarschijnlijk scenario?
Er is een truc om dit te bereiken. Het gebruik van een niet-inlineable scalaire UDF in de query is een parallellisme-remmer. Een van de scalaire UDF-inliningremmers roept een intrinsieke functie op die tijdsafhankelijk is, zoals SYSDATETIME. Dus hier is een voorbeeld voor een niet-inlineable scalaire UDF:
CREATE OR ALTER FUNCTION dbo.MySYSDATETIME() RETURNS DATETIME2 AS BEGIN RETURN SYSDATETIME(); END; GO
Een andere optie is om een UDF te definiëren met slechts een constante als de geretourneerde waarde, en de optie INLINE =OFF in de koptekst te gebruiken. Maar deze optie is alleen beschikbaar vanaf SQL Server 2019, die scalaire UDF-inlining introduceerde. Met de hierboven voorgestelde functie kunt u deze maken zoals deze is met oudere versies van SQL Server.
Wijzig vervolgens de definitie van de dbo.GetNumsAlanCharlieItzikBatch-functie om een dummy-aanroep naar dbo.MySYSDATETIME te hebben (definieer een kolom op basis daarvan, maar verwijs niet naar de kolom in de geretourneerde query), als volgt:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT
ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum,
dbo.MySYSDATETIME() AS dontinline
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO U kunt de prestatietest nu opnieuw uitvoeren zonder MAXDOP 1 op te geven en toch een serieel abonnement krijgen:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n;
Het is echter belangrijk om te benadrukken dat elke query die deze functie gebruikt, nu een serieel plan krijgt. Als er een kans is dat de functie wordt gebruikt in query's die baat hebben bij parallelle plannen, kun je deze truc beter niet gebruiken, en als je een serieel plan nodig hebt, gebruik dan gewoon MAXDOP 1.
Oplossing door Joe Obbish
De oplossing van Joe is behoorlijk creatief. Hier is zijn eigen beschrijving van de oplossing:
“Ik heb gekozen voor het maken van een geclusterde columnstore-index (CCI) met 134.217.728 rijen opeenvolgende gehele getallen. De functie verwijst maximaal 32 keer naar de tabel om alle rijen te krijgen die nodig zijn voor de resultatenset. Ik koos voor een CCI omdat de gegevens goed worden gecomprimeerd (minder dan 3 bytes per rij), je krijgt "gratis" batch-modus en eerdere ervaring suggereert dat het lezen van opeenvolgende nummers van een CCI sneller zal zijn dan ze via een andere methode te genereren. ”Zoals eerder vermeld, merkte Joe ook op dat mijn oorspronkelijke prestatietests aanzienlijk scheef waren vanwege de asynchrone netwerk-I/O-wachttijden die werden gegenereerd door de rijen naar SSMS te verzenden. Dus alle tests die ik hier zal uitvoeren, zullen het idee van Alan gebruiken met de variabele toewijzing. Zorg ervoor dat u uw tests aanpast op basis van wat het meest overeenkomt met uw werkelijke situatie.
Dit is de code die Joe gebruikte om de tabel dbo.GetNumsObbishTable te maken en deze te vullen met 134.217.728 rijen:
DROP TABLE IF EXISTS dbo.GetNumsObbishTable; CREATE TABLE dbo.GetNumsObbishTable (ID BIGINT NOT NULL, INDEX CCI CLUSTERED COLUMNSTORE); GO SET NOCOUNT ON; DECLARE @c INT = 0; WHILE @c < 128 BEGIN INSERT INTO dbo.GetNumsObbishTable SELECT TOP (1048576) @c * 1048576 - 1 + ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2 OPTION (MAXDOP 1); SET @c = @c + 1; END; GO
Het kostte deze code 1:04 minuten om op mijn computer te voltooien.
U kunt het ruimtegebruik van deze tabel controleren door de volgende code uit te voeren:
EXEC sys.sp_spaceused @objname = N'dbo.GetNumsObbishTable';
Ik heb ongeveer 350 MB aan ruimte gebruikt. In vergelijking met de andere oplossingen die ik in dit artikel zal presenteren, gebruikt deze aanzienlijk meer ruimte.
In de columnstore-architectuur van SQL Server is een rijgroep beperkt tot 2^20 =1.048.576 rijen. U kunt met de volgende code controleren hoeveel rijgroepen er voor deze tabel zijn gemaakt:
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.GetNumsObbishTable'); Ik heb 128 rijgroepen.
Hier is de code met de definitie van de dbo.GetNumsObbish functie:
CREATE OR ALTER FUNCTION dbo.GetNumsObbish(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE AS RETURN SELECT @low + ID AS n FROM dbo.GetNumsObbishTable WHERE ID <= @high - @low UNION ALL SELECT @low + ID + CAST(134217728 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(134217728 AS BIGINT) AND ID <= @high - @low - CAST(134217728 AS BIGINT) UNION ALL SELECT @low + ID + CAST(268435456 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(268435456 AS BIGINT) AND ID <= @high - @low - CAST(268435456 AS BIGINT) UNION ALL SELECT @low + ID + CAST(402653184 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(402653184 AS BIGINT) AND ID <= @high - @low - CAST(402653184 AS BIGINT) UNION ALL SELECT @low + ID + CAST(536870912 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(536870912 AS BIGINT) AND ID <= @high - @low - CAST(536870912 AS BIGINT) UNION ALL SELECT @low + ID + CAST(671088640 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(671088640 AS BIGINT) AND ID <= @high - @low - CAST(671088640 AS BIGINT) UNION ALL SELECT @low + ID + CAST(805306368 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(805306368 AS BIGINT) AND ID <= @high - @low - CAST(805306368 AS BIGINT) UNION ALL SELECT @low + ID + CAST(939524096 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(939524096 AS BIGINT) AND ID <= @high - @low - CAST(939524096 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1073741824 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1073741824 AS BIGINT) AND ID <= @high - @low - CAST(1073741824 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1207959552 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1207959552 AS BIGINT) AND ID <= @high - @low - CAST(1207959552 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1342177280 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1342177280 AS BIGINT) AND ID <= @high - @low - CAST(1342177280 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1476395008 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1476395008 AS BIGINT) AND ID <= @high - @low - CAST(1476395008 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1610612736 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1610612736 AS BIGINT) AND ID <= @high - @low - CAST(1610612736 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1744830464 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1744830464 AS BIGINT) AND ID <= @high - @low - CAST(1744830464 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1879048192 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1879048192 AS BIGINT) AND ID <= @high - @low - CAST(1879048192 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2013265920 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2013265920 AS BIGINT) AND ID <= @high - @low - CAST(2013265920 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2147483648 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2147483648 AS BIGINT) AND ID <= @high - @low - CAST(2147483648 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2281701376 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2281701376 AS BIGINT) AND ID <= @high - @low - CAST(2281701376 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2415919104 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2415919104 AS BIGINT) AND ID <= @high - @low - CAST(2415919104 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2550136832 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2550136832 AS BIGINT) AND ID <= @high - @low - CAST(2550136832 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2684354560 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2684354560 AS BIGINT) AND ID <= @high - @low - CAST(2684354560 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2818572288 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2818572288 AS BIGINT) AND ID <= @high - @low - CAST(2818572288 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2952790016 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2952790016 AS BIGINT) AND ID <= @high - @low - CAST(2952790016 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3087007744 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3087007744 AS BIGINT) AND ID <= @high - @low - CAST(3087007744 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3221225472 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3221225472 AS BIGINT) AND ID <= @high - @low - CAST(3221225472 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3355443200 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3355443200 AS BIGINT) AND ID <= @high - @low - CAST(3355443200 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3489660928 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3489660928 AS BIGINT) AND ID <= @high - @low - CAST(3489660928 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3623878656 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3623878656 AS BIGINT) AND ID <= @high - @low - CAST(3623878656 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3758096384 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3758096384 AS BIGINT) AND ID <= @high - @low - CAST(3758096384 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3892314112 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3892314112 AS BIGINT) AND ID <= @high - @low - CAST(3892314112 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4026531840 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4026531840 AS BIGINT) AND ID <= @high - @low - CAST(4026531840 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4160749568 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4160749568 AS BIGINT) AND ID <= @high - @low - CAST(4160749568 AS BIGINT); GO
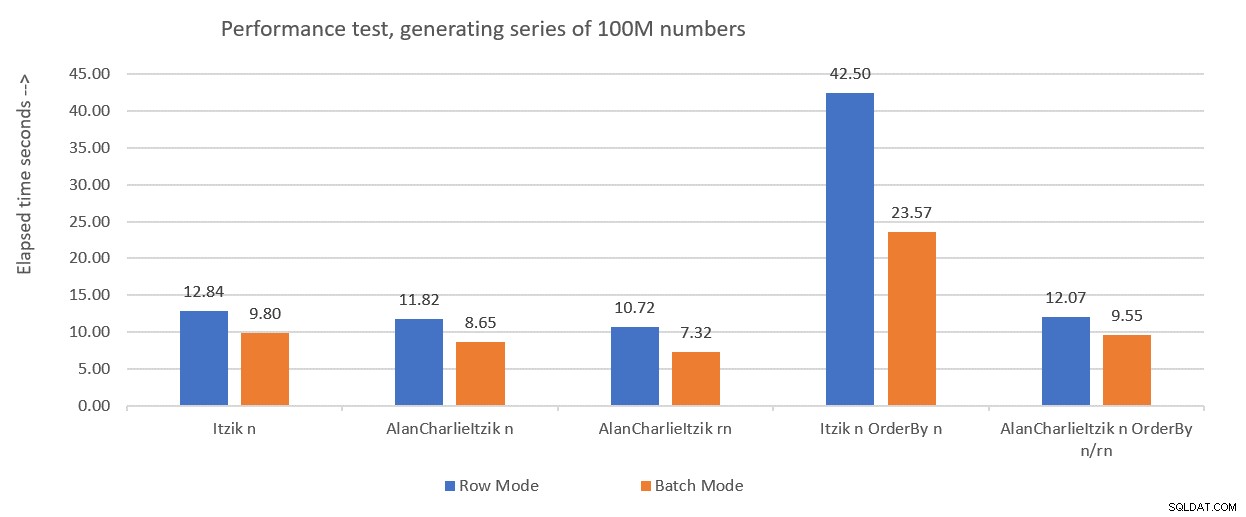
De 32 afzonderlijke query's genereren de onsamenhangende subbereiken van 134.217.728 gehele getallen die, wanneer verenigd, het volledige ononderbroken bereik 1 tot en met 4.294.967.296 produceren. Wat echt slim is aan deze oplossing, zijn de WHERE-filterpredikaten die de afzonderlijke zoekopdrachten gebruiken. Bedenk dat wanneer SQL Server een inline TVF verwerkt, het eerst parameterinsluiting toepast, waarbij de parameters worden vervangen door de invoerconstanten. SQL Server kan vervolgens de query's optimaliseren die subbereiken produceren die het invoerbereik niet kruisen. Wanneer u bijvoorbeeld het invoerbereik 1 tot 100.000.000 aanvraagt, is alleen de eerste query relevant en wordt de rest geoptimaliseerd. Het plan omvat dan in dit geval een verwijzing naar slechts één exemplaar van de tabel. Dat is behoorlijk briljant!
Laten we de prestaties van de functie testen met het bereik van 1 tot 100.000.000:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000);
Het plan voor deze zoekopdracht wordt getoond in figuur 2.
 Figuur 2:Plan voor dbo.GetNumsObbish, 100 miljoen rijen, ongeordend
Figuur 2:Plan voor dbo.GetNumsObbish, 100 miljoen rijen, ongeordend
Merk op dat er inderdaad maar één verwijzing naar de CCI van de tabel nodig is in dit plan.
Ik heb de volgende tijdstatistieken voor deze uitvoering:
Dat is behoorlijk indrukwekkend, en veel sneller dan al het andere dat ik heb getest.
Dit zijn de I/O-statistieken die ik voor deze uitvoering heb gekregen:
Tabel 'GetNumsObbishTable'. Aantal scans 1, logische leest 0, fysieke leest 0, paginaserver leest 0, read-ahead leest 0, pageserver read-ahead leest 0, lob logische leest 32928 , fysieke lob leest 0, lob page server leest 0, lob read-ahead leest 0, lob page server read-ahead leest 0.Tabel 'GetNumsObbishTable'. Segment leest 96 , segment 32 overgeslagen.
Het I/O-profiel van deze oplossing is een van de nadelen in vergelijking met de andere, waarbij meer dan 30K lob logische leesbewerkingen nodig zijn voor deze uitvoering.
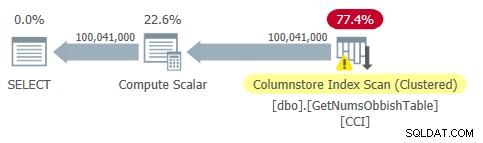
Als u wilt zien dat wanneer u meerdere subbereiken van 134.217.728 gehele getallen kruist, het plan meerdere verwijzingen naar de tabel omvat, voert u een query uit op de functie met het bereik 1 tot 400.000.000, bijvoorbeeld:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 400000000);
Het plan voor deze uitvoering is weergegeven in figuur 3.
 Figuur 3:Plan voor dbo.GetNumsObbish, 400 miljoen rijen, ongeordend
Figuur 3:Plan voor dbo.GetNumsObbish, 400 miljoen rijen, ongeordend
Het gevraagde bereik overschreed drie subbereiken van 134.217.728 gehele getallen, vandaar dat het plan drie verwijzingen naar de CCI van de tabel toont.
Dit zijn de tijdstatistieken die ik voor deze uitvoering heb gekregen:
CPU-tijd =20610 ms, verstreken tijd =20628 ms.En hier zijn de I/O-statistieken:
Tabel 'GetNumsObbishTable'. Aantal scans 3, logische waarden 0, fysieke waarden 0, paginaserver leest 0, read-ahead leest 0, pageserver read-ahead leest 0, lob logische leest 131026 , fysieke lob leest 0, lob page server leest 0, lob read-ahead leest 0, lob page server read-ahead leest 0.Tabel 'GetNumsObbishTable'. Segment leest 382 , segment overgeslagen 2.
Deze keer resulteerde de uitvoering van de query in meer dan 130K lob logische reads.
Als je de I/O-kosten kunt dragen en de nummerreeksen niet geordend hoeft te verwerken, is dit een geweldige oplossing. Als u de reeks echter op volgorde moet verwerken, resulteert deze oplossing in een sorteeroperator in het plan. Hier is een test om het bestelde resultaat op te vragen:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000) ORDER BY n;
Het plan voor deze uitvoering is weergegeven in figuur 4.
 Figuur 4:Plan voor dbo.GetNumsObbish, 100 miljoen rijen, besteld
Figuur 4:Plan voor dbo.GetNumsObbish, 100 miljoen rijen, besteld
Dit zijn de tijdstatistieken die ik voor deze uitvoering heb gekregen:
CPU-tijd =44516 ms, verstreken tijd =34836 ms.Zoals je kunt zien, zijn de prestaties aanzienlijk verslechterd, waarbij de runtime met een orde van grootte toenam als gevolg van de expliciete sortering.
Dit zijn de I/O-statistieken die ik voor deze uitvoering heb gekregen:
Tabel 'GetNumsObbishTable'. Aantal scans 4, logische waarden 0, fysieke waarden 0, paginaserver leest 0, read-ahead leest 0, pageserver read-ahead leest 0, lob logische leest 32928 , fysieke lob leest 0, lob page server leest 0, lob read-ahead leest 0, lob page server read-ahead leest 0.Tabel 'GetNumsObbishTable'. Segment leest 96 , segment 32 overgeslagen.
Tafel 'Werktafel'. Aantal scans 0, logische waarden 0, fysieke waarden 0, paginaserver leest 0, read-ahead leest 0, pageserver read-ahead leest 0, lob logische leest 0, lob fysieke leest 0, lob pageserver leest 0, lob read- vooruit leest 0, lob page server read-ahead leest 0.
Merk op dat een werktabel verscheen in de uitvoer van STATISTICS IO. Dat komt omdat een sort mogelijk naar tempdb kan gaan, in welk geval het een werktabel zou gebruiken. Deze uitvoering is niet gemorst, daarom zijn de cijfers allemaal nullen in dit bericht.
Oplossing door John Nelson #2, Dave, Joe, Alan, Charlie, Itzik
John Nelson #2 heeft een oplossing gepost die gewoon mooi is in zijn eenvoud. Bovendien bevat het ideeën en suggesties van de andere oplossingen van Dave, Joe, Alan, Charlie en mijzelf.
Net als bij Joe's oplossing, besloot John een CCI te gebruiken om een hoog niveau van compressie en "gratis" batchverwerking te krijgen. Alleen John besloot de tabel te vullen met 4B-rijen met een dummy NULL-markering in een bitkolom, en de ROW_NUMBER-functie de getallen te laten genereren. Omdat de opgeslagen waarden allemaal hetzelfde zijn, heb je bij compressie van herhalende waarden aanzienlijk minder ruimte nodig, wat resulteert in aanzienlijk minder I/O's in vergelijking met de oplossing van Joe. Columnstore-compressie kan zeer goed met herhalende waarden omgaan, omdat het elke opeenvolgende sectie binnen het kolomsegment van een rijgroep slechts één keer kan vertegenwoordigen, samen met het aantal opeenvolgend herhalende voorvallen. Aangezien alle rijen dezelfde waarde hebben (de NULL-markering), hebt u in theorie slechts één exemplaar per rijgroep nodig. Met 4B-rijen zou u moeten eindigen met 4.096 rijgroepen. Elk zou een segment met één kolom moeten hebben, met zeer weinig ruimtegebruik.
Hier is de code om de tabel te maken en te vullen, geïmplementeerd als een CCI met archiefcompressie:
DROP TABLE IF EXISTS dbo.NullBits4B;
CREATE TABLE dbo.NullBits4B
(
b BIT NULL,
INDEX cc_NullBits4B CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B),
nulls(b) AS (SELECT A.b FROM L2 AS A CROSS JOIN L2 AS B)
INSERT INTO dbo.NullBits4B WITH (TABLOCK) (b)
SELECT b FROM nulls;
GO Het belangrijkste nadeel van deze oplossing is de tijd die nodig is om deze tabel te vullen. Het kostte deze code 12:32 minuten om op mijn machine te voltooien wanneer parallellisme werd toegestaan, en 15:17 minuten bij het forceren van een serieel plan.
Merk op dat u zou kunnen werken aan het optimaliseren van de gegevensbelasting. John testte bijvoorbeeld een oplossing die de rijen laadde met 32 gelijktijdige verbindingen met OSTRESS.EXE, elk met 128 invoegrondes van 2^20 rijen (max. rijgroepgrootte). Deze oplossing bracht de laadtijd van John naar een derde. Dit is de code die John gebruikte:
ostress -S(local)\YourSQLInstance -E -dtempdb -n32 -r128 -Q"MET L0 AS (SELECTEER CAST(NULL AS BIT) AS b FROM (VALUES(1),(1),(1),(1) ,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1) AS D(b)), L1 AS (SELECTEER A.b VAN L0 ALS EEN CROSS JOIN L0 AS B), L2 AS (SELECT A.b VAN L1 AS A CROSS JOIN L1 AS B), nulls(b) AS (SELECTEER A.b VAN L2 AS A CROSS JOIN L2 AS B) INSERT INTO dbo.NullBits4B(b) SELECT TOP (1048576) b FROM nulls OPTION (MAXDOP 1);"Toch is de laadtijd in minuten. Het goede nieuws is dat u deze gegevensbelasting maar één keer hoeft uit te voeren.
Het goede nieuws is de kleine hoeveelheid ruimte die de tafel nodig heeft. Gebruik de volgende code om het ruimtegebruik te controleren:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits4B';
Ik heb 1,64 MB. Dat is verbazingwekkend gezien het feit dat de tabel 4B rijen heeft!
Gebruik de volgende code om te controleren hoeveel rijgroepen zijn gemaakt:
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits4B'); Zoals verwacht is het aantal rijgroepen 4.096.
De functiedefinitie dbo.GetNumsJohn2DaveObbishAlanCharlieItzik wordt dan vrij eenvoudig:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits4B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO
Zoals u kunt zien, gebruikt een eenvoudige query op de tabel de functie ROW_NUMBER om de basisrijnummers (rijnummerkolom) te berekenen, en vervolgens gebruikt de buitenste query dezelfde expressies als in dbo.GetNumsAlanCharlieItzikBatch om rn, op en n te berekenen. Ook hier zijn zowel rn als n volgordebehoud met betrekking tot rownum.
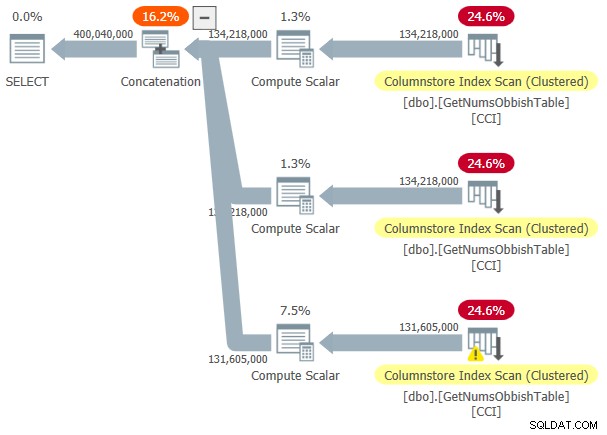
Laten we de prestaties van de functie testen:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000);
Ik heb het plan weergegeven in figuur 5 voor deze uitvoering.
 Figuur 5:Plan voor dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Figuur 5:Plan voor dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Dit zijn de tijdstatistieken die ik voor deze test heb gekregen:
CPU-tijd =7593 ms, verstreken tijd =7590 ms.
Zoals je kunt zien, is de uitvoeringstijd niet zo snel als bij Joe's oplossing, maar het is nog steeds sneller dan alle andere oplossingen die ik heb getest.
Hier zijn de I/O-statistieken die ik voor deze test heb gekregen:
Tabel 'NullBits4B'. Segment leest 96 , segment overgeslagen 0
Merk op dat de I/O-vereisten aanzienlijk lager zijn dan bij de oplossing van Joe.
Het andere mooie van deze oplossing is dat wanneer u de bestelde nummerreeksen moet verwerken, u niets extra betaalt. Dat komt omdat het niet resulteert in een expliciete sorteerbewerking in het plan, ongeacht of u het resultaat rangschikt op rn of n.
Hier is een test om dit aan te tonen:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000) ORDER BY n;
U krijgt hetzelfde abonnement als eerder getoond in figuur 5.
Dit zijn de tijdstatistieken die ik voor deze test heb gekregen;
CPU-tijd =7578 ms, verstreken tijd =7582 ms.En hier zijn de I/O-statistieken:
Tabel 'NullBits4B'. Aantal scans 1, logische leest 0, fysieke leest 0, paginaserver leest 0, read-ahead leest 0, pageserver read-ahead leest 0, lob logische leest 194 , fysieke lob leest 0, lob page server leest 0, lob read-ahead leest 0, lob page server read-ahead leest 0.Tabel 'NullBits4B'. Segment leest 96 , segment 0 overgeslagen.
Ze zijn in principe hetzelfde als in de test zonder de volgorde.
Oplossing 2 door John Nelson #2, Dave Mason, Joe Obbish, Alan, Charlie, Itzik
De oplossing van John is snel en eenvoudig. Dat is fantastisch. Het enige nadeel is de laadtijd. Soms is dit geen probleem, omdat het laden maar één keer gebeurt. Maar als het een probleem is, kunt u de tabel vullen met 102.400 rijen in plaats van 4B-rijen, en een cross-join gebruiken tussen twee instanties van de tabel en een TOP-filter om het gewenste maximum van 4B-rijen te genereren. Merk op dat om 4B-rijen te krijgen, het voldoende zou zijn om de tabel te vullen met 65.536 rijen en dan een cross-join toe te passen; om de gegevens echter onmiddellijk te laten comprimeren - in plaats van te worden geladen in een op rowstore gebaseerde delta store - moet u de tabel laden met een minimum van 102.400 rijen.
Hier is de code om de tabel te maken en te vullen:
DROP TABLE IF EXISTS dbo.NullBits102400;
GO
CREATE TABLE dbo.NullBits102400
(
b BIT NULL,
INDEX cc_NullBits102400 CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
nulls(b) AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B CROSS JOIN L1 AS C)
INSERT INTO dbo.NullBits102400 WITH (TABLOCK) (b)
SELECT TOP(102400) b FROM nulls;
GO De laadtijd is verwaarloosbaar — 43 ms op mijn machine.
Controleer de grootte van de tabel op schijf:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits102400';
Ik heb 56 KB ruimte nodig voor de gegevens.
Controleer het aantal rijgroepen, hun status (gecomprimeerd of open) en hun grootte:
SELECT state_description, total_rows, size_in_bytes
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits102400'); Ik kreeg de volgende uitvoer:
state_description total_rows size_in_bytes ------------------ ----------- -------------- COMPRESSED 102400 293
Hier is slechts één rijgroep nodig; het is gecomprimeerd en de grootte is een verwaarloosbare 293 bytes.
Als u de tabel vult met één rij minder (102.399), krijgt u een op rowstore gebaseerde niet-gecomprimeerde open delta store. In een dergelijk geval rapporteert sp_spaceused een gegevensgrootte op schijf van meer dan 1 MB, en sys.column_store_row_groups rapporteert de volgende informatie:
state_description total_rows size_in_bytes ------------------ ----------- -------------- OPEN 102399 1499136
Zorg er dus voor dat je de tabel vult met 102.400 rijen!
Hier is de definitie van de functie dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits102400 AS A
CROSS JOIN dbo.NullBits102400 AS B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Let’s test the function's performance:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
I got the plan shown in Figure 6 for this execution.
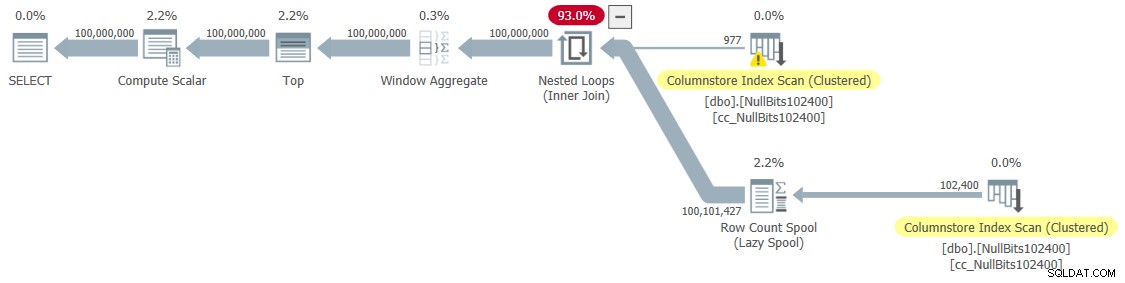 Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
I got the following time statistics for this test:
CPU time =9188 ms, elapsed time =9188 ms.As you can see, the execution time increased by ~ 26%. It’s still pretty fast, but not as fast as the single-table solution. So that’s a tradeoff that you’ll need to evaluate.
I got the following I/O stats for this test:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Table 'NullBits102400'. Segment reads 2, segment skipped 0.
The I/O profile of this solution is excellent.
Let’s add order to the test:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
You get the same plan as shown earlier in Figure 6 since there’s no explicit sorting needed.
I got the following time statistics for this test:
CPU time =9140 ms, elapsed time =9237 ms.And the following I/O stats:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Table 'NullBits102400'. Segment reads 2, segment skipped 0.
Again, the numbers are very similar to the test without the ordering.
Performance summary
Figure 7 has a summary of the time statistics for the different solutions.
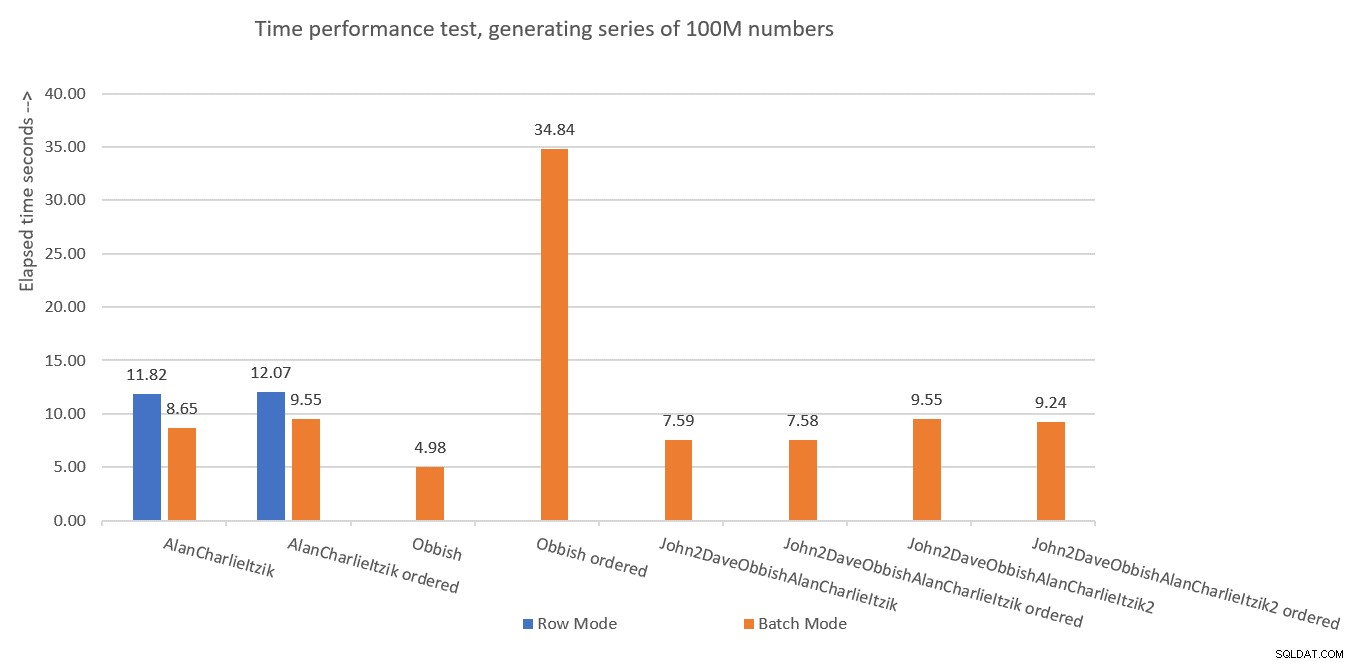 Figure 7:Time performance summary of solutions
Figure 7:Time performance summary of solutions
Figure 8 has a summary of the I/O statistics.
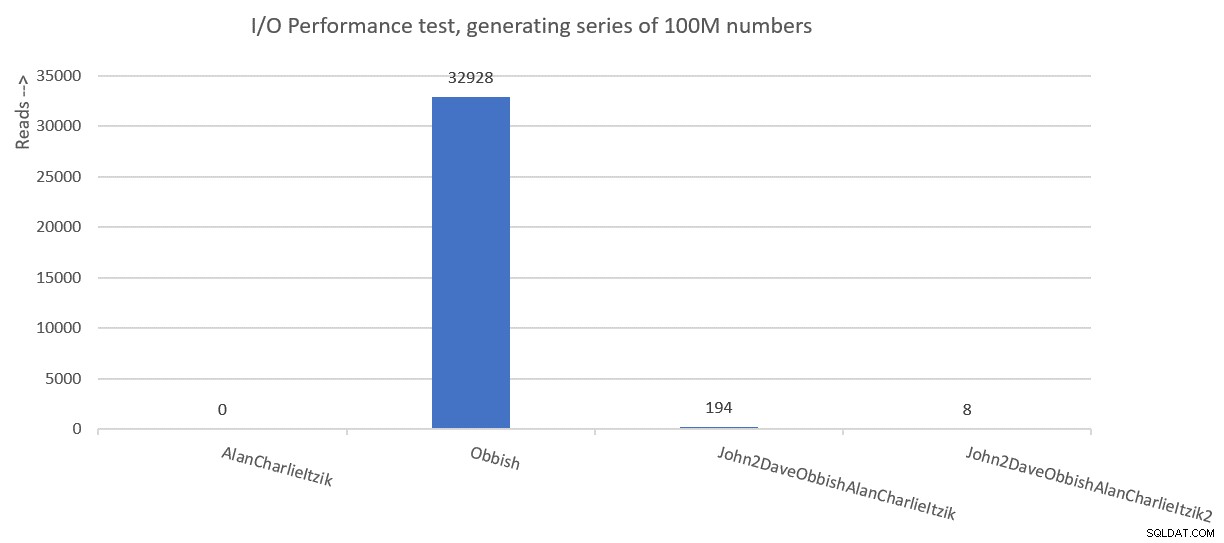 Figure 8:I/O performance summary of solutions
Figure 8:I/O performance summary of solutions
Thanks to all of you who posted ideas and suggestions in effort to create a fast number series generator. It’s a great learning experience!
We’re not done yet. Next month I’ll continue exploring additional solutions.