Wanneer we een opgeslagen procedure schrijven, willen we vaak dat deze zich op verschillende manieren gedraagt op basis van gebruikersinvoer. Laten we naar het volgende voorbeeld kijken:
CREATE PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC; GO
Deze opgeslagen procedure, die ik heb gemaakt in de AdventureWorks2017-database, heeft twee parameters:@CustomerID en @SortOrder. De eerste parameter, @CustomerID, is van invloed op de rijen die moeten worden geretourneerd. Als een specifieke klant-ID wordt doorgegeven aan de opgeslagen procedure, worden alle bestellingen (top 10) voor deze klant geretourneerd. Anders, als het NULL is, retourneert de opgeslagen procedure alle bestellingen (top 10), ongeacht de klant. De tweede parameter, @SortOrder, bepaalt hoe de gegevens worden gesorteerd:op OrderDate of op SalesOrderID. Merk op dat alleen de eerste 10 rijen worden geretourneerd volgens de sorteervolgorde.
Gebruikers kunnen het gedrag van de query dus op twee manieren beïnvloeden:welke rijen ze moeten retourneren en hoe ze moeten worden gesorteerd. Om preciezer te zijn, er zijn 4 verschillende gedragingen voor deze zoekopdracht:
- Geef de top 10 rijen terug voor alle klanten gesorteerd op OrderDate (het standaardgedrag)
- Retourneer de top 10 rijen voor een specifieke klant gesorteerd op OrderDate
- Retourneer de top 10 rijen voor alle klanten gesorteerd op SalesOrderID
- Retourneer de top 10 rijen voor een specifieke klant gesorteerd op SalesOrderID
Laten we de opgeslagen procedure testen met alle 4 de opties en het uitvoeringsplan en de statistische IO onderzoeken.
Retourneer de top 10 rijen voor alle klanten gesorteerd op orderdatum
Het volgende is de code om de opgeslagen procedure uit te voeren:
EXECUTE Sales.GetOrders; GO
Hier is het uitvoeringsplan:
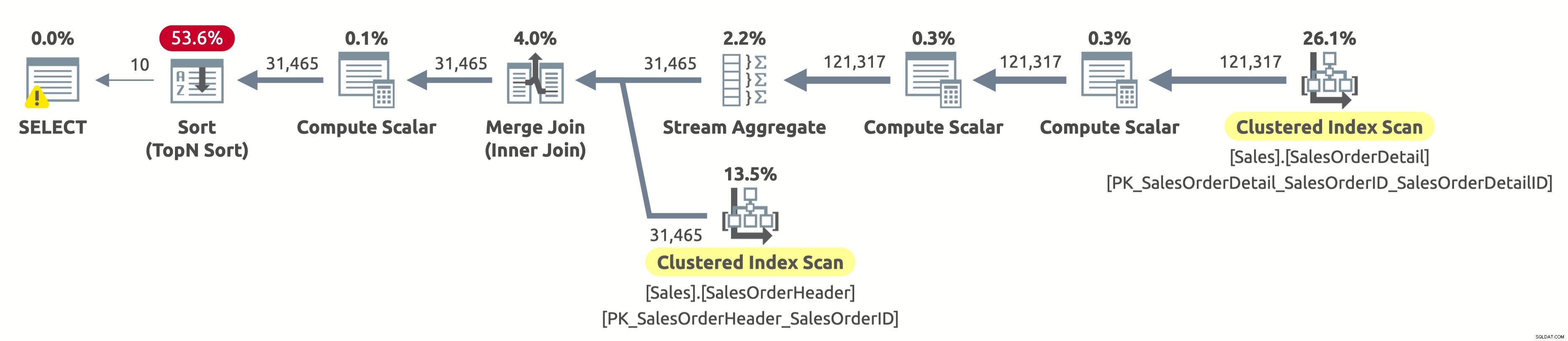
Omdat we niet op klant hebben gefilterd, moeten we de hele tabel scannen. De optimizer koos ervoor om beide tabellen te scannen met behulp van indexen op SalesOrderID, wat een efficiënte Stream Aggregate en een efficiënte Merge Join mogelijk maakte.
Als u de eigenschappen van de operator Clustered Index Scan in de tabel Sales.SalesOrderHeader controleert, vindt u het volgende predikaat:[AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] as [SalesOrders].[CustomerID]=[ @CustomerID] OF [@CustomerID] IS NULL. De queryprocessor moet dit predikaat evalueren voor elke rij in de tabel, wat niet erg efficiënt is omdat het altijd true zal opleveren.
We moeten nog steeds alle gegevens sorteren op OrderDate om de eerste 10 rijen te retourneren. Als er een index op OrderDate was, zou de optimizer deze waarschijnlijk hebben gebruikt om alleen de eerste 10 rijen van Sales.SalesOrderHeader te scannen, maar er is geen dergelijke index, dus het plan lijkt goed gezien de beschikbare indexen.
Hier is de output van statistieken IO:
- Tabel 'SalesOrderHeader'. Scan telling 1, logische leest 689
- Tabel 'SalesOrderDetail'. Scan telling 1, logische leest 1248
Als je je afvraagt waarom er een waarschuwing staat op de SELECT-operator, dan is het een overdreven toekenningswaarschuwing. In dit geval is dat niet omdat er een probleem is met het uitvoeringsplan, maar omdat de queryprocessor 1.024 KB heeft aangevraagd (wat standaard het minimum is) en slechts 16 KB heeft gebruikt.
Soms is plancaching niet zo'n goed idee
Vervolgens willen we het scenario testen waarbij de top 10 rijen voor een specifieke klant worden geretourneerd, gesorteerd op OrderDate. Hieronder staat de code:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
Het uitvoeringsplan is precies hetzelfde als voorheen. Deze keer is het plan erg inefficiënt omdat het beide tabellen scant om slechts 3 bestellingen te retourneren. Er zijn veel betere manieren om deze zoekopdracht uit te voeren.
De reden is in dit geval plancaching. Het uitvoeringsplan is in de eerste uitvoering gegenereerd op basis van de parameterwaarden in die specifieke uitvoering - een methode die bekend staat als parametersnuiven. Dat plan is opgeslagen in de plancache voor hergebruik, en vanaf nu zal elke aanroep naar deze opgeslagen procedure hetzelfde plan opnieuw gebruiken.
Dit is een voorbeeld waarbij plancaching niet zo'n goed idee is. Vanwege de aard van deze opgeslagen procedure, die 4 verschillende gedragingen heeft, verwachten we voor elk gedrag een ander plan te krijgen. Maar we zitten met een enkel plan, dat alleen goed is voor een van de 4 opties, gebaseerd op de optie die in de eerste uitvoering is gebruikt.
Laten we het cachen van plannen voor deze opgeslagen procedure uitschakelen, zodat we het beste plan kunnen zien dat de optimizer kan bedenken voor elk van de andere 3 gedragingen. We doen dit door WITH RECOMPILE toe te voegen aan het EXECUTE-commando.
Retourneer de top 10 rijen voor een specifieke klant gesorteerd op orderdatum
Het volgende is de code om de top 10 rijen voor een specifieke klant te retourneren, gesorteerd op OrderDate:
EXECUTE Sales.GetOrders @CustomerID = 11006 WITH RECOMPILE; GO
Het volgende is het uitvoeringsplan:
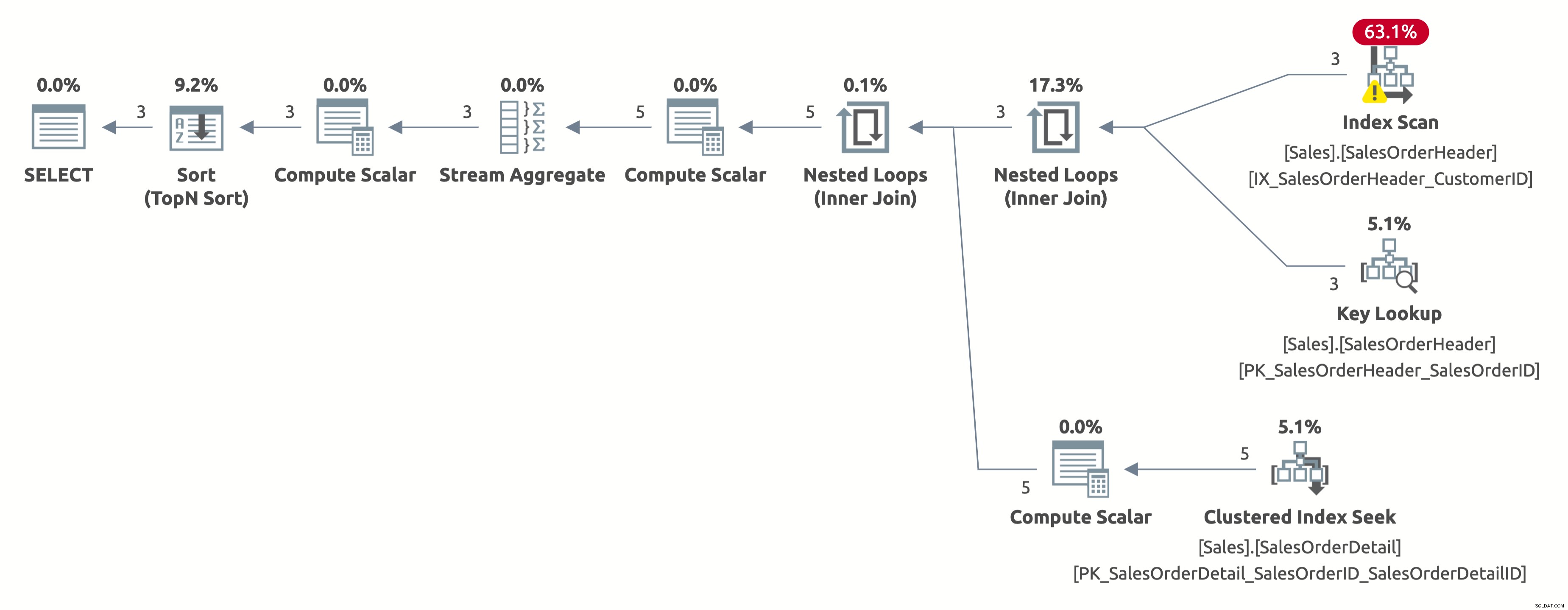
Deze keer krijgen we een beter plan, dat een index op CustomerID gebruikt. De optimizer schat correct 2,6 rijen voor CustomerID =11006 (het werkelijke aantal is 3). Maar merk op dat het een indexscan uitvoert in plaats van een indexzoekopdracht. Het kan geen indexzoekopdracht uitvoeren omdat het het volgende predikaat moet evalueren voor elke rij in de tabel:[AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] as [SalesOrders].[CustomerID]=[@CustomerID] ] OF [@CustomerID] IS NULL.
Hier is de output van statistieken IO:
- Tabel 'SalesOrderDetail'. Scan telling 3, logische leest 9
- Tabel 'SalesOrderHeader'. Scan telling 1, logische leest 66
Retourneer de top 10 rijen voor alle klanten gesorteerd op SalesOrderID
Het volgende is de code om de top 10 rijen te retourneren voor alle klanten gesorteerd op SalesOrderID:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
Het volgende is het uitvoeringsplan:
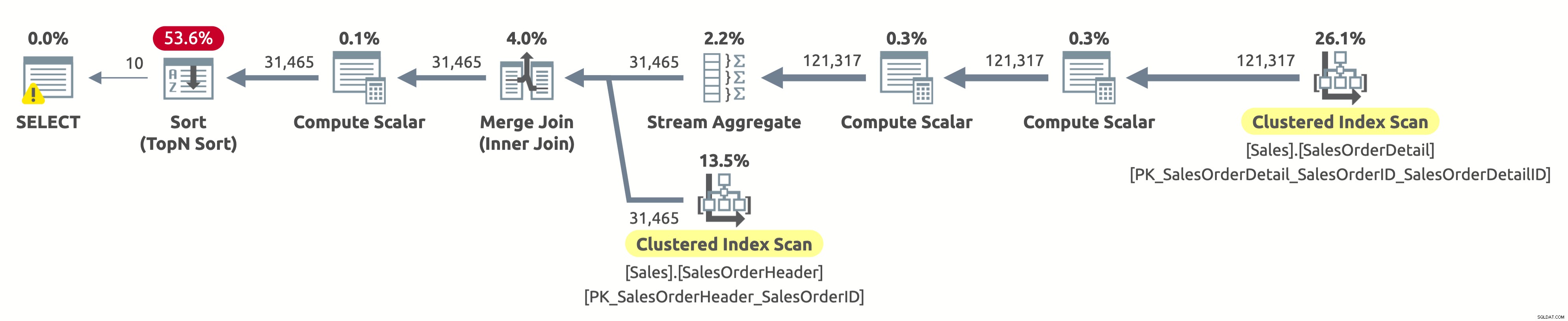
Hé, dit is hetzelfde uitvoeringsplan als bij de eerste optie. Maar deze keer klopt er iets niet. We weten al dat de geclusterde indexen op beide tabellen zijn gesorteerd op SalesOrderID. We weten ook dat het plan beide in de logische volgorde scant om de sorteervolgorde te behouden (de eigenschap Ordered is ingesteld op True). De operator Samenvoegen behoudt ook de sorteervolgorde. Omdat we nu vragen om het resultaat te sorteren op SalesOrderID, en het is al op die manier gesorteerd, waarom moeten we dan betalen voor een dure sorteeroperator?
Welnu, als u de sorteeroperator aanvinkt, zult u merken dat deze de gegevens sorteert volgens Expr1004. En als u de Compute Scalar-operator rechts van de Sort-operator aanvinkt, zult u ontdekken dat Expr1004 als volgt is:

Het is geen mooi gezicht, ik weet het. Dit is de uitdrukking die we hebben in de ORDER BY-clausule van onze query. Het probleem is dat de optimizer deze expressie niet kan evalueren tijdens het compileren, dus moet hij deze tijdens runtime voor elke rij berekenen en vervolgens de hele recordset op basis daarvan sorteren.
De output van statistieken IO is net als in de eerste uitvoering:
- Tabel 'SalesOrderHeader'. Scan telling 1, logische leest 689
- Tabel 'SalesOrderDetail'. Scan telling 1, logische leest 1248
Retourneer de top 10 rijen voor een specifieke klant gesorteerd op SalesOrderID
Het volgende is de code om de top 10 rijen voor een specifieke klant te retourneren, gesorteerd op SalesOrderID:
EXECUTE Sales.GetOrders @CustomerID = 11006 , @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
Het uitvoeringsplan is hetzelfde als bij de tweede optie (retourneer top 10 rijen voor een specifieke klant gesorteerd op OrderDate). Het plan heeft dezelfde twee problemen, die we al hebben genoemd. Het eerste probleem is het uitvoeren van een indexscan in plaats van een indexzoekopdracht vanwege de uitdrukking in de WHERE-component. Het tweede probleem is het uitvoeren van een dure sortering vanwege de uitdrukking in de ORDER BY-component.
Dus, wat moeten we doen?
Laten we ons eerst herinneren waar we mee te maken hebben. We hebben parameters die de structuur van de query bepalen. Voor elke combinatie van parameterwaarden krijgen we een andere querystructuur. In het geval van de parameter @CustomerID zijn de twee verschillende gedragingen NULL of NOT NULL en hebben ze invloed op de WHERE-component. In het geval van de parameter @SortOrder zijn er twee mogelijke waarden, die van invloed zijn op de ORDER BY-component. Het resultaat is 4 mogelijke querystructuren, en we zouden graag voor elk een ander plan willen hebben.
Dan hebben we twee verschillende problemen. De eerste is plancaching. Er is slechts één plan voor de opgeslagen procedure en het wordt gegenereerd op basis van de parameterwaarden in de eerste uitvoering. Het tweede probleem is dat zelfs wanneer een nieuw plan wordt gegenereerd, het niet efficiënt is omdat de optimizer de "dynamische" expressies in de WHERE-component en in de ORDER BY-component niet kan evalueren tijdens het compileren.
We kunnen deze problemen op verschillende manieren proberen op te lossen:
- Gebruik een reeks IF-ELSE-instructies
- Splits de procedure op in afzonderlijke opgeslagen procedures
- Gebruik OPTIE (OPNIEUW COMPILEREN)
- Genereer de zoekopdracht dynamisch
Gebruik een reeks IF-ELSE-verklaringen
Het idee is simpel:in plaats van de "dynamische" uitdrukkingen in de WHERE-clausule en in de ORDER BY-clausule, kunnen we de uitvoering opsplitsen in 4 takken met behulp van IF-ELSE-instructies - één tak voor elk mogelijk gedrag.
Het volgende is bijvoorbeeld de code voor de eerste tak:
IF @CustomerID IS NULL AND @SortOrder = N'OrderDate' BEGIN SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID GROUP BY SalesOrders.SalesOrderID, SalesOrders.OrderDate, SalesOrders.DueDate, SalesOrders.[Status], SalesOrders.CustomerID ORDER BY SalesOrders.OrderDate ASC; END;
Deze aanpak kan helpen bij het genereren van betere plannen, maar heeft enkele beperkingen.
Ten eerste wordt de opgeslagen procedure behoorlijk lang en is het moeilijker om te schrijven, lezen en onderhouden. En dit is wanneer we slechts twee parameters hebben. Als we 3 parameters hadden, zouden we 8 takken hebben. Stel je voor dat je een kolom moet toevoegen aan de SELECT-component. U zou de kolom in 8 verschillende zoekopdrachten moeten toevoegen. Het wordt een onderhoudsnachtmerrie, met een hoog risico op menselijke fouten.
Ten tweede hebben we tot op zekere hoogte nog steeds het probleem van plancaching en parametersniffing. Dit komt omdat in de eerste uitvoering de optimizer een plan gaat genereren voor alle vier de query's op basis van de parameterwaarden in die uitvoering. Laten we zeggen dat de eerste uitvoering de standaardwaarden voor de parameters gaat gebruiken. In het bijzonder is de waarde van @CustomerID NULL. Alle zoekopdrachten worden geoptimaliseerd op basis van die waarde, inclusief de zoekopdracht met de WHERE-component (SalesOrders.CustomerID =@CustomerID). De optimizer gaat 0 rijen schatten voor deze zoekopdrachten. Laten we nu zeggen dat de tweede uitvoering een niet-null-waarde gaat gebruiken voor @CustomerID. Het in de cache opgeslagen plan, dat 0 rijen schat, wordt gebruikt, ook al heeft de klant mogelijk veel bestellingen in de tabel.
De procedure opsplitsen in afzonderlijk opgeslagen procedures
In plaats van 4 branches binnen dezelfde opgeslagen procedure, kunnen we 4 afzonderlijke opgeslagen procedures maken, elk met de relevante parameters en de bijbehorende query. Vervolgens kunnen we de toepassing herschrijven om te beslissen welke opgeslagen procedure moet worden uitgevoerd volgens het gewenste gedrag. Of, als we willen dat het transparant is voor de toepassing, kunnen we de oorspronkelijke opgeslagen procedure herschrijven om te beslissen welke procedure moet worden uitgevoerd op basis van de parameterwaarden. We gaan dezelfde IF-ELSE-instructies gebruiken, maar in plaats van een query in elke vertakking uit te voeren, zullen we een afzonderlijke opgeslagen procedure uitvoeren.
Het voordeel is dat we het plancaching-probleem oplossen omdat elke opgeslagen procedure nu zijn eigen plan heeft, en het plan voor elke opgeslagen procedure zal in de eerste uitvoering worden gegenereerd op basis van parameter-sniffing.
Maar we hebben nog steeds het onderhoudsprobleem. Sommige mensen zeggen misschien dat het nu nog erger is, omdat we meerdere opgeslagen procedures moeten onderhouden. Nogmaals, als we het aantal parameters verhogen tot 3, zouden we eindigen met 8 verschillende opgeslagen procedures.
Gebruik OPTIE (HERCOMPIEREN)
OPTIE (RECOMPILE) werkt als magie. Je hoeft alleen maar de woorden te zeggen (of ze aan de vraag toe te voegen), en magie gebeurt. Echt, het lost zoveel problemen op omdat het de query tijdens runtime compileert, en het doet dit voor elke uitvoering.
Maar je moet voorzichtig zijn, want je weet wat ze zeggen:"Met grote macht komt grote verantwoordelijkheid." Als u OPTION (RECOMPILE) gebruikt in een query die heel vaak wordt uitgevoerd op een druk OLTP-systeem, zou u het systeem kunnen doden omdat de server bij elke uitvoering een nieuw plan moet compileren en genereren, waarbij veel CPU-bronnen worden gebruikt. Dit is echt gevaarlijk. Als de query echter maar af en toe wordt uitgevoerd, laten we zeggen eens in de paar minuten, dan is het waarschijnlijk veilig. Maar test altijd de impact in uw specifieke omgeving.
In ons geval, ervan uitgaande dat we OPTION (RECOMPILE) veilig kunnen gebruiken, hoeven we alleen de magische woorden aan het einde van onze zoekopdracht toe te voegen, zoals hieronder weergegeven:
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC OPTION (RECOMPILE); GO
Laten we nu de magie in actie zien. Het volgende is bijvoorbeeld het plan voor het tweede gedrag:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
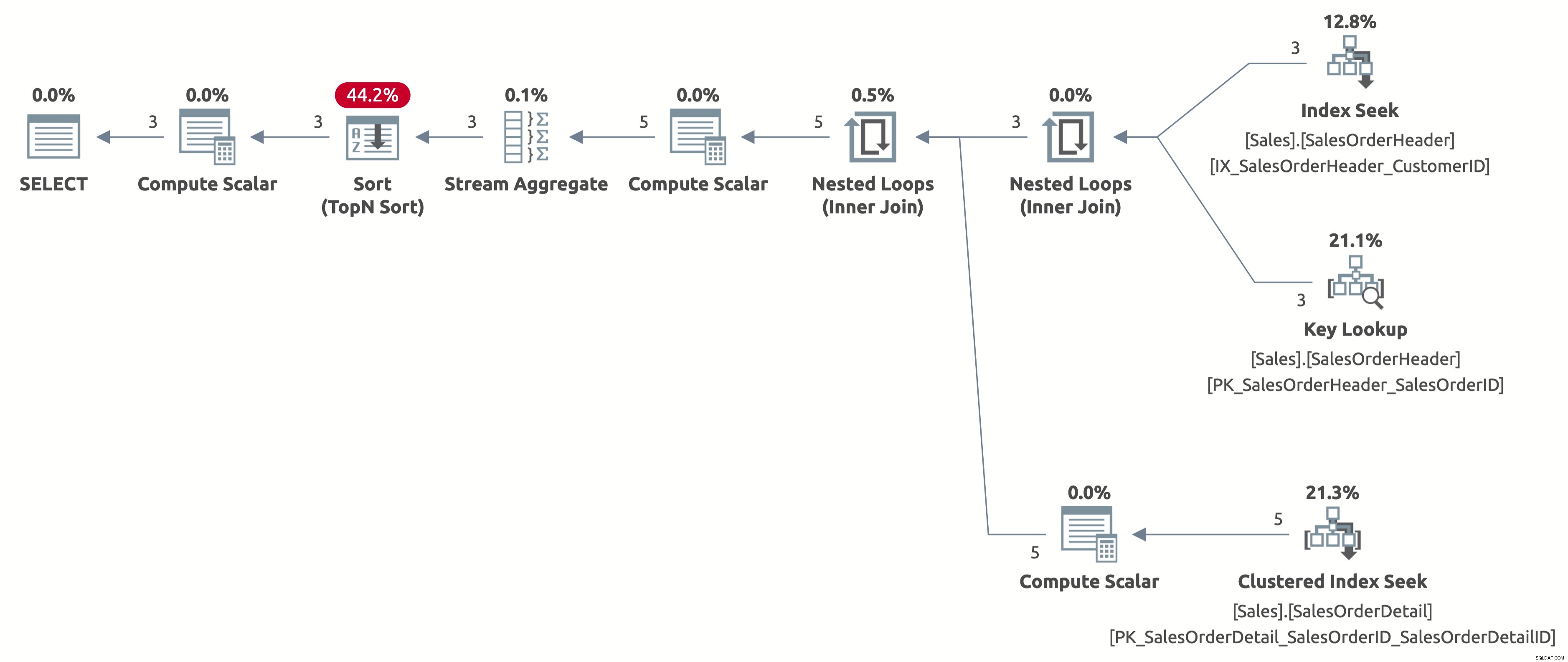
Nu krijgen we een efficiënte indexzoekopdracht met een correcte schatting van 2,6 rijen. We moeten nog steeds sorteren op OrderDate, maar nu is de sortering direct op Order Date en hoeven we de CASE-expressie in de ORDER BY-component niet meer te berekenen. Dit is het best mogelijke plan voor dit zoekgedrag op basis van de beschikbare indexen.
Hier is de output van statistieken IO:
- Tabel 'SalesOrderDetail'. Scan telling 3, logische leest 9
- Tabel 'SalesOrderHeader'. Scan telling 1, logische leest 11
De reden dat OPTIE (HERCOMPIEREN) in dit geval zo efficiënt is, is dat het precies de twee problemen oplost die we hier hebben. Onthoud dat het eerste probleem plancaching is. OPTION (RECOMPILE) elimineert dit probleem helemaal omdat het de query elke keer opnieuw compileert. Het tweede probleem is het onvermogen van de optimizer om de complexe expressie in de WHERE-component en in de ORDER BY-component te evalueren tijdens het compileren. Aangezien OPTION (RECOMPILE) tijdens runtime plaatsvindt, wordt het probleem opgelost. Omdat de optimizer tijdens runtime veel meer informatie heeft in vergelijking met de compileertijd, en het maakt het verschil.
Laten we nu eens kijken wat er gebeurt als we het derde gedrag proberen:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
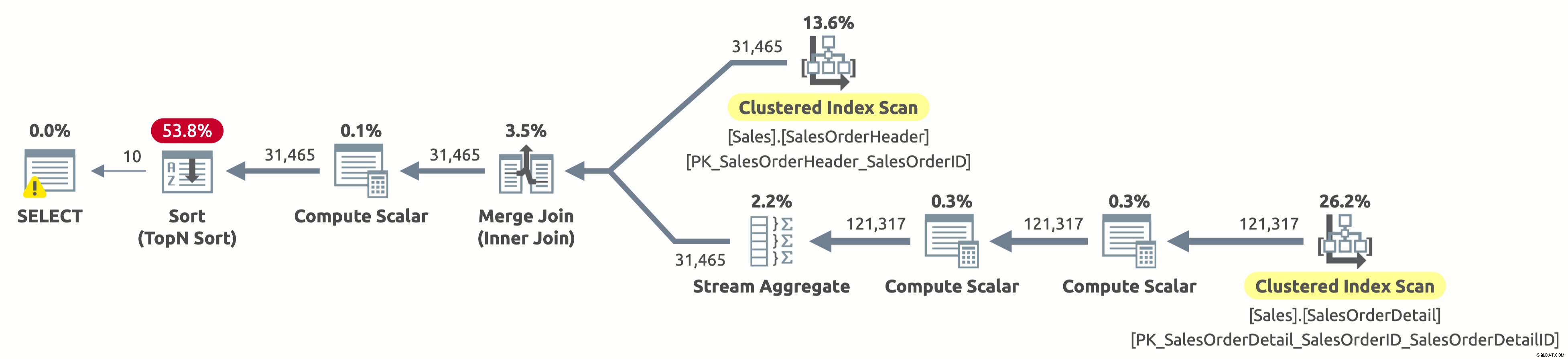
Houston we hebben een probleem. Het plan scant nog steeds beide tabellen volledig en sorteert vervolgens alles, in plaats van alleen de eerste 10 rijen van Sales.SalesOrderHeader te scannen en de sortering helemaal te vermijden. Wat is er gebeurd?
Dit is een interessante "case", en het heeft te maken met de CASE-expressie in de ORDER BY-component. De CASE-expressie evalueert een lijst met voorwaarden en retourneert een van de resultaatexpressies. Maar de resultaatexpressies kunnen verschillende gegevenstypen hebben. Dus, wat zou het gegevenstype zijn van de hele CASE-expressie? Welnu, de CASE-expressie retourneert altijd het gegevenstype met de hoogste prioriteit. In ons geval heeft de kolom OrderDate het datatype DATETIME, terwijl de kolom SalesOrderID het datatype INT heeft. Het datatype DATETIME heeft een hogere prioriteit, dus de CASE-expressie retourneert altijd DATETIME.
Dit betekent dat als we willen sorteren op SalesOrderID, de CASE-expressie eerst impliciet de waarde van SalesOrderID moet converteren naar DATETIME voor elke rij voordat deze wordt gesorteerd. Zie de Compute Scalar-operator rechts van de Sort-operator in het bovenstaande plan? Dat is precies wat het doet.
Dit is op zich al een probleem en het laat zien hoe gevaarlijk het kan zijn om verschillende gegevenstypen in één CASE-expressie te combineren.
We kunnen dit probleem omzeilen door de ORDER BY-clausule op andere manieren te herschrijven, maar het zou de code nog lelijker en moeilijker te lezen en te onderhouden maken. Dus ik ga niet die kant op.
Laten we in plaats daarvan de volgende methode proberen...
Genereer de query dynamisch
Aangezien het ons doel is om 4 verschillende querystructuren binnen een enkele query te genereren, kan dynamische SQL in dit geval erg handig zijn. Het idee is om de query dynamisch te bouwen op basis van de parameterwaarden. Op deze manier kunnen we de 4 verschillende querystructuren in één code bouwen, zonder dat we 4 exemplaren van de query hoeven te onderhouden. Elke querystructuur wordt één keer gecompileerd, wanneer deze voor het eerst wordt uitgevoerd, en krijgt het beste plan omdat het geen complexe expressies bevat.
Deze oplossing lijkt erg op de oplossing met meerdere opgeslagen procedures, maar in plaats van 8 opgeslagen procedures voor 3 parameters te onderhouden, onderhouden we slechts één enkele code die de query dynamisch opbouwt.
Ik weet het, dynamische SQL is ook lelijk en kan soms behoorlijk moeilijk te onderhouden zijn, maar ik denk dat het nog steeds gemakkelijker is dan het onderhouden van meerdere opgeslagen procedures, en het schaalt niet exponentieel naarmate het aantal parameters toeneemt.
Het volgende is de code:
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS DECLARE @Command AS NVARCHAR(MAX); SET @Command = N' SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID ' + CASE WHEN @CustomerID IS NULL THEN N'' ELSE N'WHERE SalesOrders.CustomerID = @pCustomerID ' END + N'GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY ' + CASE @SortOrder WHEN N'OrderDate' THEN N'SalesOrders.OrderDate' WHEN N'SalesOrderID' THEN N'SalesOrders.SalesOrderID' END + N' ASC; '; EXECUTE sys.sp_executesql @stmt = @Command , @params = N'@pCustomerID AS INT' , @pCustomerID = @CustomerID; GO
Merk op dat ik nog steeds een interne parameter voor de klant-ID gebruik, en ik voer de dynamische code uit met sys.sp_executesql om de parameterwaarde door te geven. Dit is om twee redenen belangrijk. Ten eerste om meerdere compilaties van dezelfde querystructuur voor verschillende waarden van @CustomerID te vermijden. Ten tweede, om SQL-injectie te voorkomen.
Als u de opgeslagen procedure nu probeert uit te voeren met verschillende parameterwaarden, zult u zien dat elk querygedrag of elke querystructuur het beste uitvoeringsplan krijgt en dat elk van de vier plannen slechts één keer wordt gecompileerd.
Als voorbeeld is het volgende het plan voor het derde gedrag:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
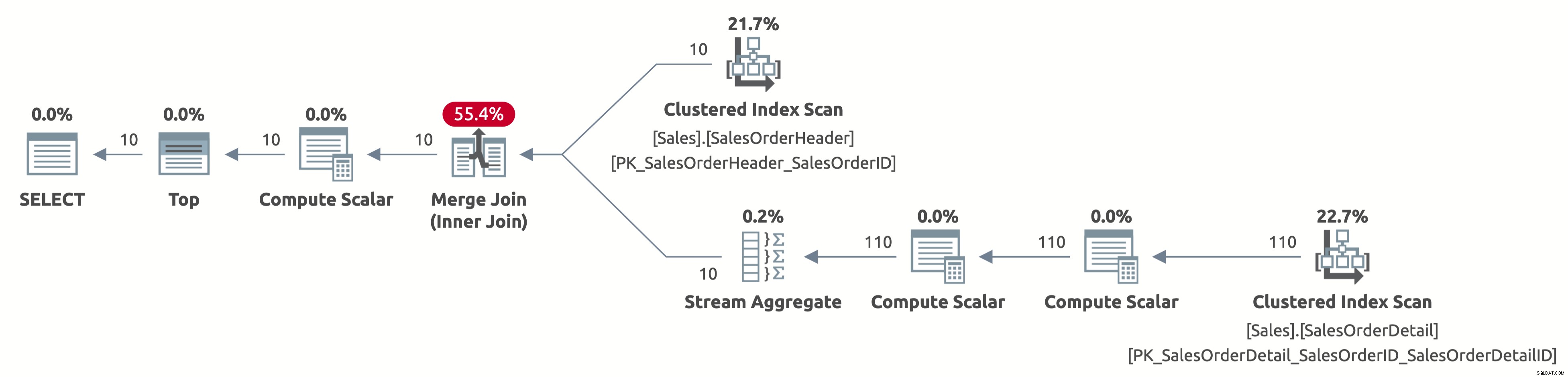
Nu scannen we alleen de eerste 10 rijen uit de tabel Sales.SalesOrderHeader en scannen we ook alleen de eerste 110 rijen uit de tabel Sales.SalesOrderDetail. Bovendien is er geen sorteeroperator omdat de gegevens al zijn gesorteerd op SalesOrderID.
Hier is de output van statistieken IO:
- Tabel 'SalesOrderDetail'. Scan telling 1, logische leest 4
- Tabel 'SalesOrderHeader'. Scan telling 1, logische leest 3
Conclusie
Wanneer u parameters gebruikt om de structuur van uw query te wijzigen, gebruik dan geen complexe expressies binnen de query om het verwachte gedrag af te leiden. In de meeste gevallen zal dit leiden tot slechte prestaties, en met goede redenen. De eerste reden is dat het plan wordt gegenereerd op basis van de eerste uitvoering en dat vervolgens alle volgende uitvoeringen hetzelfde plan hergebruiken, wat alleen geschikt is voor één querystructuur. De tweede reden is dat de optimizer beperkt is in zijn vermogen om die complexe expressies tijdens het compileren te evalueren.
Er zijn verschillende manieren om deze problemen op te lossen, en we hebben ze in dit artikel onderzocht. In de meeste gevallen zou de beste methode zijn om de query dynamisch op te bouwen op basis van de parameterwaarden. Op die manier wordt elke zoekstructuur één keer samengesteld met het best mogelijke plan.
Wanneer u de query maakt met dynamische SQL, zorg er dan voor dat u waar nodig parameters gebruikt en controleer of uw code veilig is.