Ik heb de laatste tijd veel gesprekken gehad over soorten workloads, met name om te begrijpen of een workload geparametriseerd, ad-hoc of een combinatie is. Het is een van de dingen waar we naar kijken tijdens een gezondheidsaudit, en Kimberly heeft een geweldige vraag vanuit haar Plan-cache en optimalisatie voor adhoc-workloads die deel uitmaken van onze toolkit. Ik heb de onderstaande query gekopieerd en als je deze nog nooit eerder in een van je productieomgevingen hebt uitgevoerd, moet je zeker wat tijd vinden om dit te doen.
SELECT objtype AS [CacheType],
COUNT_BIG(*) AS [Total Plans],
SUM(CAST(size_in_bytes AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs],
AVG(usecounts) AS [Avg Use Count],
SUM(CAST((CASE WHEN usecounts = 1 THEN size_in_bytes
ELSE 0
END) AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs – USE Count 1],
SUM(CASE WHEN usecounts = 1 THEN 1
ELSE 0
END) AS [Total Plans – USE Count 1]
FROM sys.dm_exec_cached_plans
GROUP BY objtype
ORDER BY [Total MBs – USE Count 1] DESC; Als ik deze query op een productieomgeving uitvoer, krijgen we mogelijk de volgende uitvoer:
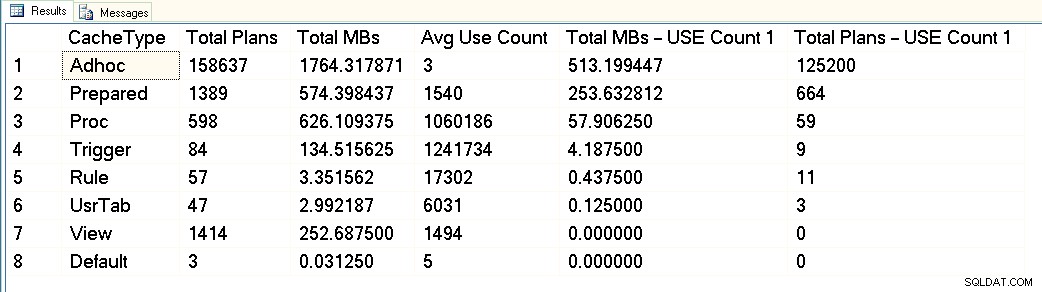
Op deze schermafbeelding kun je zien dat we in totaal ongeveer 3 GB hebben gereserveerd voor de plancache, en daarvan is 1,7 GB voor de plannen van meer dan 158.000 ad-hocquery's. Van die 1,7 GB wordt ongeveer 500 MB gebruikt voor 125.000 abonnementen die EEN uitvoeren alleen tijd. Ongeveer 1 GB van de plancache is voor voorbereide en procedureplannen, en ze nemen slechts ongeveer 300 MB aan ruimte in beslag. Maar let op het gemiddelde gebruik - ruim 1 miljoen voor procedures. Als ik naar deze uitvoer kijk, zou ik deze werklast als gemengd categoriseren - sommige geparametriseerde zoekopdrachten, sommige adhoc.
De blogpost van Kimberly bespreekt opties voor het beheren van een plancache gevuld met veel adhoc-query's. Plancache-bloat is slechts één probleem waarmee je te maken hebt als je een adhoc-werklast hebt, en in dit bericht wil ik het effect onderzoeken dat het kan hebben op de CPU als gevolg van alle compilaties die moeten plaatsvinden. Wanneer een query wordt uitgevoerd in SQL Server, wordt deze gecompileerd en geoptimaliseerd, en er is overhead aan dit proces verbonden, wat zich vaak manifesteert als CPU-kosten. Zodra een queryplan in de cache is opgeslagen, kan het opnieuw worden gebruikt. Query's die zijn geparametriseerd, kunnen uiteindelijk een plan hergebruiken dat al in de cache staat, omdat de querytekst precies hetzelfde is. Wanneer een adhoc-query wordt uitgevoerd, wordt het plan in de cache alleen opnieuw gebruikt als het de exacte heeft dezelfde tekst en invoerwaarde(n) .
Instellen
Voor onze tests zullen we een willekeurige tekenreeks in TSQL genereren en deze samenvoegen tot een query, zodat elke uitvoering een andere letterlijke waarde heeft. Ik heb dit verpakt in een opgeslagen procedure die de query aanroept met behulp van Dynamic String Execution (EXEC @QueryString), dus het gedraagt zich als een adhoc-instructie. Door het vanuit een opgeslagen procedure aan te roepen, kunnen we het een bekend aantal keren uitvoeren.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DBCC FREEPROCCACHE;
GO
EXEC dbo.[RandomSelects] @NumRows = 10;
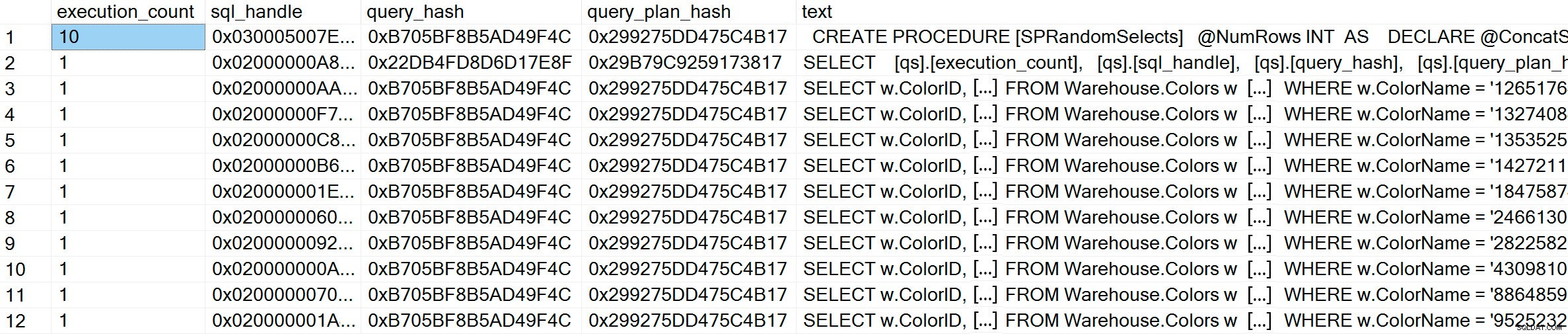
GO Als we na het uitvoeren de plancache controleren, kunnen we zien dat we 10 unieke vermeldingen hebben, elk met een uitvoeringsaantal van 1 (zoom in op de afbeelding indien nodig om de unieke waarden voor het predikaat te zien):
SELECT [qs].[execution_count], [qs].[sql_handle], [qs].[query_hash], [qs].[query_plan_hash], [st].[text] FROM sys.dm_exec_query_stats AS [qs] CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st] CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp] WHERE [st].[text] LIKE '%Warehouse%' ORDER BY [st].[text], [qs].[execution_count] DESC; GO

Nu maken we een bijna identieke opgeslagen procedure die dezelfde query uitvoert, maar geparametriseerd:
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = @ConcatString;
SELECT @RowLoop = @RowLoop + 1;
END
GO
EXEC dbo.[SPRandomSelects] @NumRows = 10;
GO In de plancache zien we, naast de 10 adhoc-query's, één item voor de geparametriseerde query die 10 keer is uitgevoerd. Omdat de invoer geparametriseerd is, is de vraagtekst, zelfs als er enorm verschillende strings aan de parameter worden doorgegeven, precies hetzelfde:
Testen
Nu we begrijpen wat er in de plancache gebeurt, gaan we meer belasting creëren. We zullen een opdrachtregelbestand gebruiken dat hetzelfde .sql-bestand op 10 verschillende threads aanroept, waarbij elk bestand de opgeslagen procedure 10.000 keer aanroept. We wissen de plancache voordat we beginnen, en leggen het totale CPU-percentage en SQL-compilaties/sec vast met PerfMon terwijl de scripts worden uitgevoerd.
Inhoud van Adhoc.sql-bestand:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 10000;
Inhoud van het geparametriseerde.sql-bestand:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 10000;
Voorbeeld opdrachtbestand (bekeken in Kladblok) dat het .sql-bestand aanroept:
Voorbeeldopdrachtbestand (bekeken in Kladblok) dat 10 threads maakt, die elk het Run_Adhoc.cmd-bestand aanroepen:
Nadat we elke reeks query's in totaal 100.000 keer hebben uitgevoerd, zien we het volgende als we naar de plancache kijken:

Er zijn meer dan 10.000 ad-hocplannen in de plancache. Je vraagt je misschien af waarom er geen plan is voor alle 100.000 adhoc-query's die zijn uitgevoerd, en dat dit te maken heeft met hoe de plancache werkt (de grootte is gebaseerd op het beschikbare geheugen, wanneer ongebruikte plannen opraken, enz.). Wat cruciaal is, is dat zo er zijn veel adhoc-plannen, vergeleken met wat we zien voor de rest van de cachetypen.
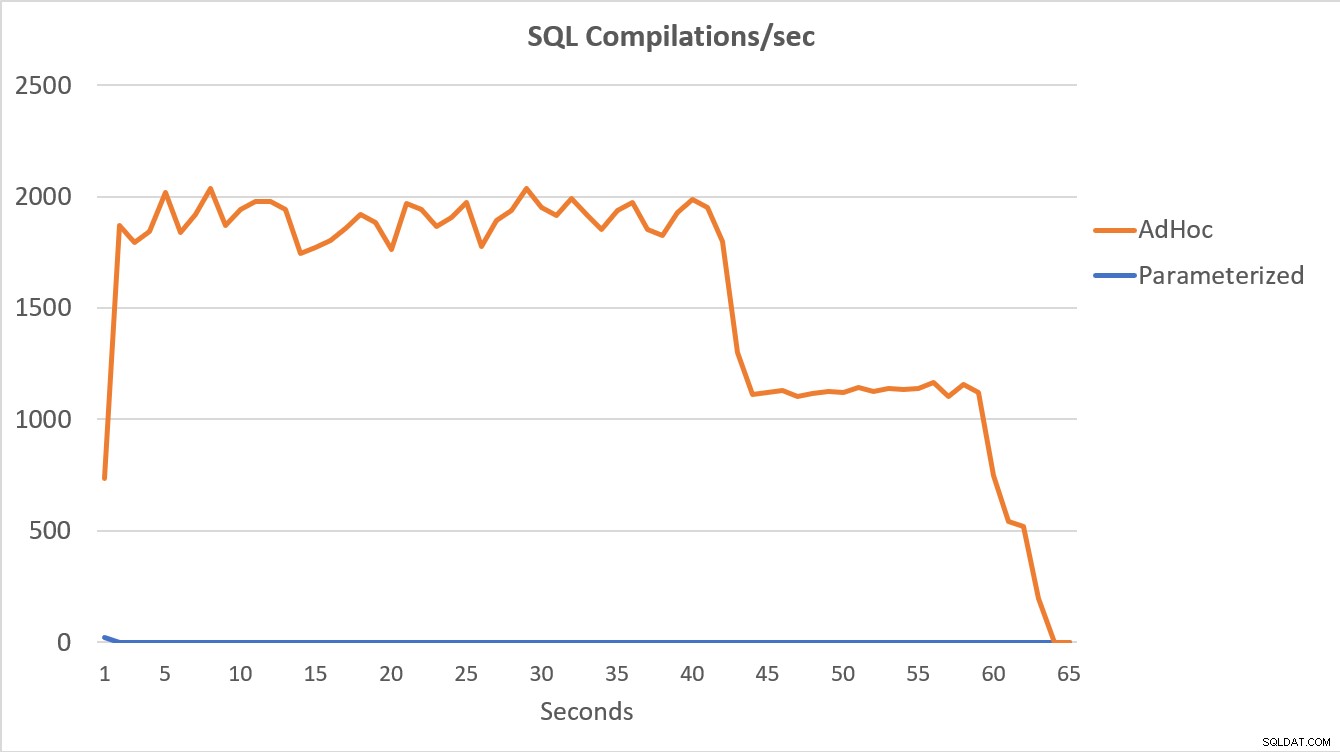
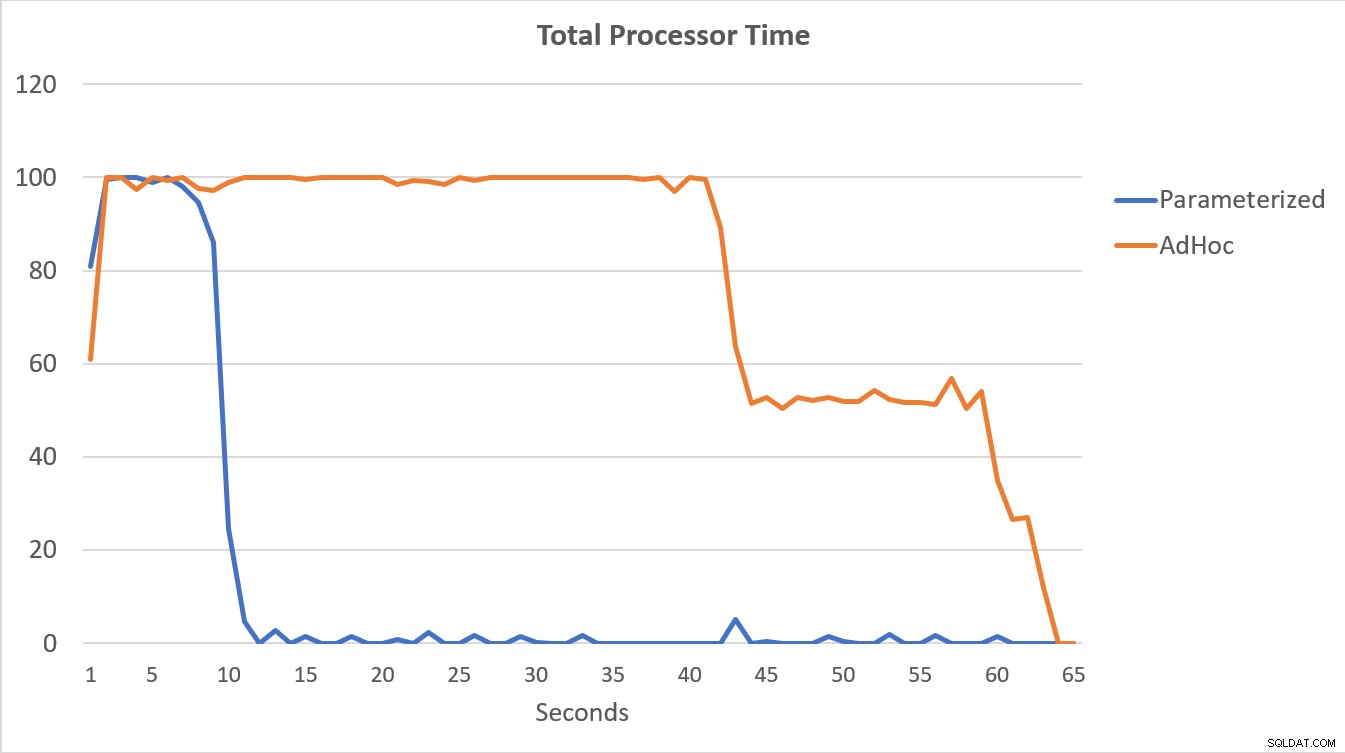
De PerfMon-gegevens, hieronder weergegeven, zijn het meest veelzeggend. De uitvoering van de 100.000 geparametriseerde zoekopdrachten voltooid in minder dan 15 seconden, en er was een kleine piek in Compilaties/sec aan het begin, die nauwelijks merkbaar is in de grafiek. Hetzelfde aantal adhoc-uitvoeringen duurde iets meer dan 60 seconden om te voltooien, met compilaties/sec piekte bijna 2000 voordat ze dichter bij 1000 daalden rond de 45 seconden, met een CPU voor het grootste deel van de tijd dichtbij of op 100%.
Samenvatting
Onze test was uiterst eenvoudig in die zin dat we slechts variaties voor één . hebben ingediend adhoc-query, terwijl we in een productieomgeving honderden of duizenden verschillende variaties kunnen hebben voor honderden of duizenden van verschillende ad-hocvragen. De prestatie-impact van deze adhoc-query's is niet alleen de opgeblazenheid van de plancache die optreedt, maar kijk naar de plancache is een geweldige plek om te beginnen als u niet bekend bent met het type werkbelasting dat u heeft. Een groot aantal adhoc-query's kan compilaties en dus CPU stimuleren, wat soms kan worden gemaskeerd door meer hardware toe te voegen, maar er kan absoluut een punt komen waarop CPU een bottleneck wordt. Als u denkt dat dit een probleem of potentieel probleem is in uw omgeving, kijk dan welke ad-hocquery's het vaakst worden uitgevoerd en welke opties u hebt om ze te parametreren. Begrijp me niet verkeerd:er zijn mogelijke problemen met geparametriseerde query's (bijv. Planstabiliteit als gevolg van scheeftrekking van gegevens), en dat is een ander probleem dat u mogelijk moet oplossen. Ongeacht uw werklast, is het belangrijk om te begrijpen dat er zelden een "set it and forget it" -methode is voor codering, configuratie, onderhoud, enz. SQL Server-oplossingen zijn levende, ademende entiteiten die altijd veranderen en voortdurend zorgen en voeden voor betrouwbaar presteren. Een van de taken van een DBA is om op de hoogte te blijven van die verandering en de prestaties zo goed mogelijk te beheren - of het nu gaat om adhoc-uitdagingen of geparametriseerde prestatie-uitdagingen.