Voor het eerst geïntroduceerd in SQL Server 2017 Enterprise Edition, een adaptieve join maakt een runtime-overgang mogelijk van een batch-modus hash-join naar een rij-modus gecorreleerde geneste loops geïndexeerde join (toepassen) tijdens runtime. Kortheidshalve verwijs ik naar een "gecorreleerde geneste loops geïndexeerde join" als een apply in de rest van dit artikel. Als je een opfriscursus nodig hebt over het verschil tussen geneste loops en solliciteren, bekijk dan mijn vorige artikel.
Of een adaptieve join overgaat van een hash-join om tijdens runtime toe te passen, hangt af van een waarde met het label Adaptive Threshold Rows op de Adaptive Join exploitant van het uitvoeringsplan. Dit artikel laat zien hoe een adaptieve join werkt, bevat details van de drempelberekening en behandelt de implicaties van enkele van de gemaakte ontwerpkeuzes.
Inleiding
Eén ding dat ik wil dat je in dit stuk in gedachten houdt, is een adaptieve join altijd wordt uitgevoerd als een hash-join in batchmodus. Dit geldt zelfs als het uitvoeringsplan aangeeft dat de adaptieve join verwacht te worden uitgevoerd als een rijmodus van toepassing is.
Zoals elke hash-join leest een adaptieve join alle rijen die beschikbaar zijn op de build-invoer en kopieert de vereiste gegevens naar een hash-tabel. De batchmodus-smaak van hash-join slaat deze rijen op in een geoptimaliseerde indeling en verdeelt ze met behulp van een of meer hash-functies. Zodra de build-invoer is verbruikt, is de hash-tabel volledig gevuld en gepartitioneerd, zodat de hash-join kan beginnen met het controleren van rijen aan de probe-zijde op overeenkomsten.
Dit is het punt waarop een adaptieve join de beslissing maakt om door te gaan met de batch-modus hash-join of om over te gaan naar een rij-modus. Als het aantal rijen in de hashtabel kleiner is dan de drempel waarde, de join verandert in een Apply; anders gaat de join verder als een hash-join door te beginnen met het lezen van rijen van de probe-invoer.
Als er een overgang naar een Apply-join plaatsvindt, worden de rijen die worden gebruikt om de hashtabel te vullen niet opnieuw in het uitvoeringsplan gelezen om de Apply-bewerking aan te sturen. In plaats daarvan een interne component die bekend staat als een adaptieve bufferlezer breidt de rijen uit die al zijn opgeslagen in de hash-tabel en maakt ze on-demand beschikbaar voor de buitenste invoer van de operator Apply. Er zijn kosten verbonden aan de adaptieve bufferlezer, maar deze zijn veel lager dan de kosten van het volledig terugspoelen van de build-invoer.
Een adaptieve deelname kiezen
Query-optimalisatie omvat een of meer fasen van logische verkenning en fysieke implementatie van alternatieven. In elke fase, wanneer de optimizer de fysieke opties verkent voor een logische join, kan het overwegen om zowel hash-join in batchmodus als in rijmodus toe te passen.
Als een van die fysieke samenvoegingsopties deel uitmaakt van de goedkoopste oplossing die in de huidige fase wordt gevonden—en het andere type join kan dezelfde vereiste logische eigenschappen leveren:de optimizer markeert de logische join-groep als mogelijk geschikt voor een adaptieve join. Zo niet, dan eindigt de overweging van een adaptieve join hier (en wordt er geen uitgebreide gebeurtenis voor adaptieve joins geactiveerd).
De normale werking van de optimizer betekent dat de goedkoopste oplossing die wordt gevonden slechts één van de fysieke join-opties bevat:hash of apply, afhankelijk van welke de laagste geschatte kosten had. Het volgende dat de optimizer doet, is het bouwen en kosten van een nieuwe implementatie van het type join dat niet was als goedkoopste gekozen.
Aangezien de huidige optimalisatiefase al is geëindigd met een gevonden goedkoopste oplossing, wordt voor de adaptieve join een speciale verkennings- en implementatieronde met één groep uitgevoerd. Ten slotte berekent de optimizer de adaptieve drempel .
Als een van de voorgaande werkzaamheden niet is gelukt, wordt de uitgebreide gebeurtenis adaptive_join_skiped met een reden geactiveerd.
Als de adaptieve join-verwerking is gelukt, wordt een Concat operator wordt toegevoegd aan het interne plan boven de hash en alternatieven toepassen met de adaptieve bufferlezer en eventuele vereiste batch-/rijmodusadapters. Houd er rekening mee dat slechts één van de join-alternatieven tijdens runtime wordt uitgevoerd, afhankelijk van het aantal daadwerkelijk aangetroffen rijen in vergelijking met de adaptieve drempel.
De Concat operator en individuele hash/apply-alternatieven worden normaal gesproken niet weergegeven in het definitieve uitvoeringsplan. In plaats daarvan krijgen we een enkele Adaptive Join exploitant. Dit is slechts een presentatiebeslissing:de Concat en joins zijn nog steeds aanwezig in de code die wordt uitgevoerd door de SQL Server-uitvoeringsengine. U kunt meer details hierover vinden in de secties Bijlage en Verwante literatuur van dit artikel.
De adaptieve drempel
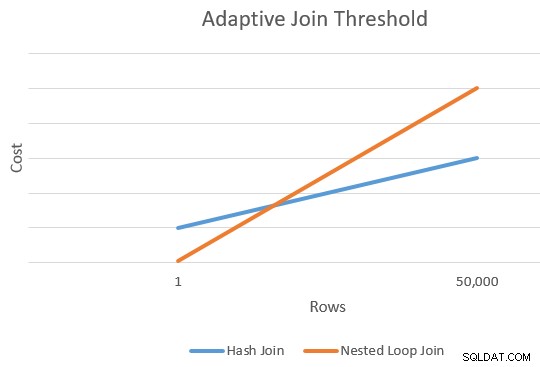
Een toepassing is over het algemeen goedkoper dan een hash-join voor een kleiner aantal rijrijen. De hash-join heeft extra opstartkosten om de hash-tabel te bouwen, maar lagere kosten per rij wanneer deze begint te zoeken naar overeenkomsten.
Er is over het algemeen een punt waarop de geschatte kosten van een toepassing en een hash-join gelijk zullen zijn. Dit idee werd mooi geïllustreerd door Joe Sack in zijn artikel, Introducing Batch Mode Adaptive Joins:
De drempel berekenen
Op dit punt heeft de optimizer een enkele schatting voor het aantal rijen dat de build-invoer van de hash-join binnenkomt en alternatieven toepast. Het heeft ook de geschatte kosten van de hash en de operators als geheel.
Dit geeft ons een enkel punt op de uiterste rechterrand van de oranje en blauwe lijnen in het bovenstaande diagram. De optimizer heeft een ander referentiepunt nodig voor elk join-type, zodat het "de lijnen kan tekenen" en het snijpunt kan vinden (het tekent niet letterlijk lijnen, maar je snapt het idee).
Om een tweede punt voor de lijnen te vinden, vraagt de optimizer de twee joins om een nieuwe kostenraming te maken op basis van een andere (en hypothetische) invoerkardinaliteit. Als de eerste kardinaliteitsschatting meer dan 100 rijen was, wordt de joins gevraagd om de nieuwe kosten voor één rij te schatten. Als de oorspronkelijke kardinaliteit kleiner dan of gelijk aan 100 rijen was, is het tweede punt gebaseerd op een invoerkardinaliteit van 10.000 rijen (dus er is voldoende bereik om te extrapoleren).
Het resultaat is in ieder geval twee verschillende kosten en rijtellingen voor elk jointype, waardoor de lijnen kunnen worden 'getekend'.
De kruisingsformule
Het vinden van het snijpunt van twee lijnen op basis van twee punten voor elke lijn is een probleem met verschillende bekende oplossingen. SQL Server gebruikt er een op basis van determinanten zoals beschreven op Wikipedia:
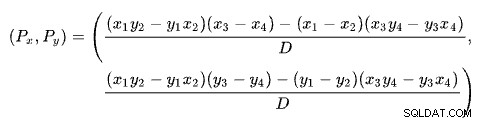
waar:
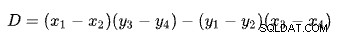
De eerste regel wordt bepaald door de punten (x1 , y1 ) en (x2 , y2 ). De tweede regel wordt gegeven door de punten (x3 , y3 ) en (x4 , y4 ). De kruising is bij (Px , Pj ).
Ons schema heeft het aantal rijen op de x-as en de geschatte kosten op de y-as. We zijn geïnteresseerd in het aantal rijen waar de lijnen elkaar kruisen. Dit wordt gegeven door de formule voor Px . Als we de geschatte kosten op het kruispunt wilden weten, zou het Py . zijn .
Voor Px rijen, zouden de geschatte kosten van de toepassings- en hash-join-oplossingen gelijk zijn. Dit is de adaptieve drempel die we nodig hebben.
Een uitgewerkt voorbeeld
Hier is een voorbeeld van het gebruik van de voorbeelddatabase AdventureWorks2017 en de volgende indexeringstruc van Itzik Ben-Gan om onvoorwaardelijke aandacht te krijgen voor uitvoering in batchmodus:
-- Itzik's trick
CREATE NONCLUSTERED COLUMNSTORE INDEX BatchMode
ON Sales.SalesOrderHeader (SalesOrderID)
WHERE SalesOrderID = -1
AND SalesOrderID = -2;
-- Test query
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
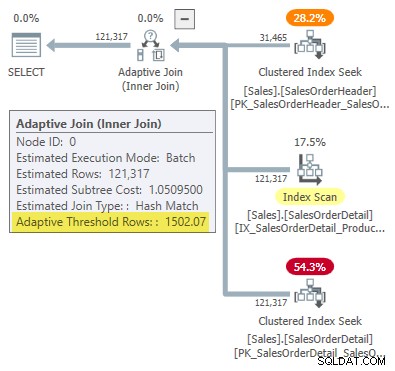
WHERE SOH.SalesOrderID <= 75123; Het uitvoeringsplan toont een adaptieve join met een drempel van 1502,07 rijen:
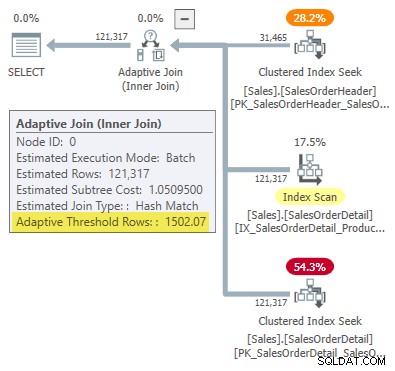
Het geschatte aantal rijen dat de adaptieve join aanstuurt, is 31.465 .
Deelnemen aan kosten
In dit vereenvoudigde geval kunnen we geschatte subboomkosten voor de hash vinden en join-alternatieven toepassen met behulp van hints:
-- Hash
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (HASH JOIN, MAXDOP 1);

-- Apply
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (LOOP JOIN, MAXDOP 1);
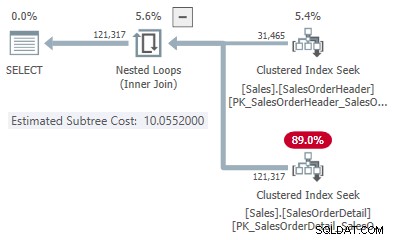
Dit geeft ons één punt op de lijn voor elk jointype:
- 31.465 rijen
- Hash kost 1.05083
- Kosten toepassen 10.0552
Het tweede punt op de lijn
Aangezien het geschatte aantal rijen meer dan 100 is, zijn de tweede referentiepunten afkomstig van speciale interne schattingen op basis van één join-invoerrij. Helaas is er geen gemakkelijke manier om de exacte kostencijfers voor deze interne berekening te verkrijgen (ik zal hier binnenkort meer over vertellen).
Voor nu zal ik u alleen de kostencijfers laten zien (met de volledige interne precisie in plaats van de zes significante cijfers die worden gepresenteerd in uitvoeringsplannen):
- Eén rij (interne berekening)
- Hash kost 0.999027422729
- Kosten toepassen 0,547927305023
- 31.465 rijen
- Hash kost 1.05082787359
- Kosten toepassen 10.0552890166
Zoals verwacht is de Apply-join goedkoper dan de hash voor een kleine invoerkardinaliteit, maar veel duurder voor de verwachte kardinaliteit van 31.465 rijen.
De snijpuntberekening
Als u deze kardinaliteits- en kostennummers in de formule voor lijnkruising invoegt, krijgt u het volgende:
-- Hash points (x = cardinality; y = cost)
DECLARE
@x1 float = 1,
@y1 float = 0.999027422729,
@x2 float = 31465,
@y2 float = 1.05082787359;
-- Apply points (x = cardinality; y = cost)
DECLARE
@x3 float = 1,
@y3 float = 0.547927305023,
@x4 float = 31465,
@y4 float = 10.0552890166;
-- Formula:
SELECT Threshold =
(
(@x1 * @y2 - @y1 * @x2) * (@x3 - @x4) -
(@x1 - @x2) * (@x3 * @y4 - @y3 * @x4)
)
/
(
(@x1 - @x2) * (@y3 - @y4) -
(@y1 - @y2) * (@x3 - @x4)
);
-- Returns 1502.06521571273 Afgerond op zes significante cijfers, komt dit resultaat overeen met de 1502,07 rijen getoond in het adaptieve join-uitvoeringsplan:
Defect of ontwerp?
Onthoud dat SQL Server vier punten nodig heeft om het aantal rijen versus kostenlijnen te "tekenen" om de drempel voor adaptieve joins te vinden. In het huidige geval betekent dit het vinden van kostenramingen voor de cardinaliteiten van één rij en 31.465 rijen voor zowel Apply- als hash-join-implementaties.
De optimizer roept een routine aan met de naam sqllang!CuNewJoinEstimate om deze vier kosten voor een adaptieve join te berekenen. Helaas zijn er geen traceervlaggen of uitgebreide gebeurtenissen om een handig overzicht van deze activiteit te geven. De normale traceervlaggen die worden gebruikt om het gedrag van de optimalisatie en de weergavekosten te onderzoeken, werken hier niet (zie de bijlage als u geïnteresseerd bent in meer details).
De enige manier om de kostenramingen van één rij te verkrijgen, is door een foutopsporingsprogramma toe te voegen en een onderbrekingspunt in te stellen na de vierde aanroep van CuNewJoinEstimate in de code voor sqllang!CardSolveForSwitch . Ik heb WinDbg gebruikt om deze call-stack op SQL Server 2019 CU12 te verkrijgen:

Op dit punt in de code worden zwevende-kommakosten met dubbele precisie opgeslagen in vier geheugenlocaties waarnaar wordt verwezen door adressen op rsp+b0 , rsp+d0 , rsp+30 , en rsp+28 (waar rsp is een CPU-register en offsets zijn in hexadecimaal):

De getoonde kostennummers van de operatorsubstructuur komen overeen met de getallen die worden gebruikt in de berekeningsformule voor adaptieve join-drempels.
Over die kostenramingen op één rij
Het is u misschien opgevallen dat de geschatte kosten van de substructuur voor de joins van één rij vrij hoog lijken voor de hoeveelheid werk die gepaard gaat met het samenvoegen van één rij:
- Eén rij
- Hash kost 0.999027422729
- Kosten toepassen 0,547927305023
Als u invoeruitvoeringsplannen met één rij probeert te maken voor de hash-join en voorbeelden toepast, ziet u veel lagere geschatte subboomkosten bij de samenvoeging dan hierboven weergegeven. Evenzo zal het uitvoeren van de oorspronkelijke zoekopdracht met een rijdoel van één (of het aantal verwachte rijen met samengevoegde uitvoer voor een invoer van één rij) ook een geschatte kosten opleveren manier lager dan weergegeven.
De reden is de CuNewJoinEstimate routine schat de één-rij geval op een manier waarvan ik denk dat de meeste mensen het niet intuïtief zouden vinden.
De uiteindelijke kosten bestaan uit drie hoofdcomponenten:
- De substructuurkosten voor de invoerinvoer
- De lokale kosten van de deelname
- De subboom van de sondeinvoer kost
Item 2 en 3 zijn afhankelijk van het type join. Voor een hash-join nemen ze de kosten voor hun rekening van het lezen van alle rijen van de probe-invoer, het matchen (of niet) met de ene rij in de hashtabel en het doorgeven van de resultaten aan de volgende operator. Voor een toepassing dekken de kosten één zoekactie op de lagere invoer voor de join, de interne kosten van de join zelf en het terugsturen van de overeenkomende rijen naar de bovenliggende operator.
Niets van dit alles is ongebruikelijk of verrassend.
De kostenverrassing
De verrassing komt van de bouwkant van de join (item 1 in de lijst). Je zou kunnen verwachten dat het optimalisatieprogramma een ingewikkelde berekening maakt om de reeds berekende subboomkosten voor 31.465 rijen terug te brengen tot één gemiddelde rij, of iets dergelijks.
In feite gebruiken zowel hash- als pas schattingen voor joins op één rij gewoon de hele substructuurkosten voor de originele kardinaliteitsschatting van 31.465 rijen. In ons lopende voorbeeld is deze 'subboom' de 0.54456 kosten van de batch-modus geclusterde index zoeken op de koptabel:
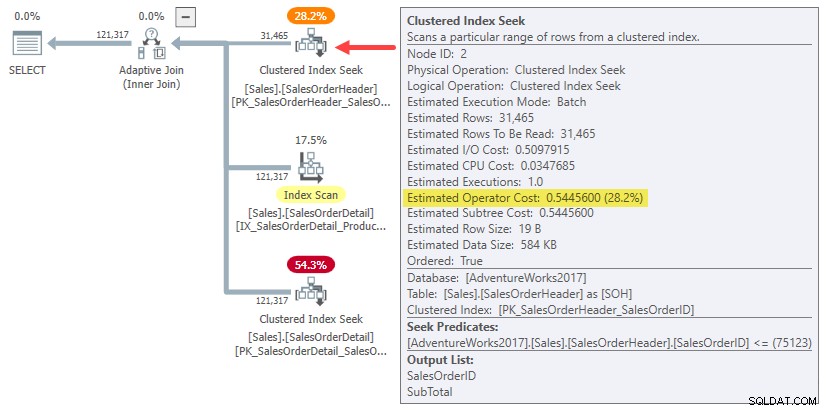
Voor alle duidelijkheid:de geschatte kosten aan de bouwzijde voor de alternatieven voor samenvoegen met één rij gebruiken invoerkosten die zijn berekend voor 31.465 rijen. Dat zou je een beetje vreemd moeten vinden.
Ter herinnering:de kosten voor één rij berekend door CuNewJoinEstimate waren als volgt:
- Eén rij
- Hash kost 0.999027422729
- Kosten toepassen 0,547927305023
U kunt zien dat de totale aanvraagkosten (~0,54793) worden gedomineerd door de 0,54456 substructuurkosten aan de bouwzijde, met een klein extra bedrag voor de enkele zoekactie aan de binnenkant, het verwerken van het kleine aantal resulterende rijen binnen de join en deze door te geven aan de bovenliggende operator.
De geschatte kosten voor een hash-join van één rij zijn hoger omdat de testzijde van het plan bestaat uit een volledige indexscan, waarbij alle resulterende rijen door de join moeten. De totale kosten van de hash-join met één rij zijn iets lager dan de oorspronkelijke kosten van 1.05095 voor het voorbeeld van 31.465 rijen, omdat er nu maar één rij in de hashtabel is.
Implicaties
Je zou verwachten dat een schatting van een join voor één rij gedeeltelijk is gebaseerd op de kosten van het leveren van één rij aan de drijvende join-invoer. Zoals we hebben gezien, is dit niet het geval voor een adaptieve join:zowel de toepassings- als de hash-alternatieven worden opgezadeld met de volledige geschatte kosten voor 31.465 rijen. De rest van de join kost ongeveer evenveel als je zou verwachten voor een build-input van één rij.
Deze intuïtief vreemde opstelling is de reden waarom het moeilijk (misschien onmogelijk) is om een uitvoeringsplan te tonen dat de berekende kosten weerspiegelt. We zouden een plan moeten maken dat 31.465 rijen levert aan de bovenste join-invoer, maar de join zelf en de interne invoer kost alsof er maar één rij aanwezig is. Een moeilijke vraag.
Het effect van dit alles is dat het meest linkse punt op ons diagram met de snijdende lijnen langs de y-as omhoog komt. Dit heeft invloed op de helling van de lijn en dus op het snijpunt.
Een ander praktisch effect is dat de berekende adaptieve join-drempel nu afhankelijk is van de oorspronkelijke kardinaliteitsschatting bij de hash-build-invoer, zoals opgemerkt door Joe Obbish in zijn blogpost uit 2017. Als we bijvoorbeeld de WHERE clausule in de testquery naar SOH.SalesOrderID <= 55000 , de adaptieve drempel verlaagt van 1502.07 naar 1259.8 zonder de queryplan-hash te wijzigen. Zelfde abonnement, andere drempel.
Dit komt omdat, zoals we hebben gezien, de interne kostenraming in één rij afhangt van de inputkosten voor het bouwen voor de oorspronkelijke kardinaliteitsschatting. Dit betekent dat verschillende initiële schattingen aan de bouwzijde een andere "boost" op de y-as zullen geven dan de schatting met één rij. Op zijn beurt zal de lijn een andere helling en een ander snijpunt hebben.
Intuïtie zou suggereren dat de schatting van één rij voor dezelfde join altijd dezelfde waarde moet geven, ongeacht de andere kardinaliteitsschatting op de lijn (gezien exact dezelfde join met dezelfde eigenschappen en rijgroottes een bijna lineaire relatie heeft tussen het rijden rijen en kosten). Dit is niet het geval voor een adaptieve join.
Door ontwerp?
Ik kan je met enig vertrouwen vertellen wat SQL Server doet bij het berekenen van de adaptieve join-drempel. Ik heb geen speciaal inzicht in waarom het doet het op deze manier.
Toch zijn er enkele redenen om aan te nemen dat deze regeling opzettelijk is en tot stand is gekomen na zorgvuldige overweging en feedback van testen. De rest van dit gedeelte behandelt enkele van mijn gedachten over dit aspect.
Een adaptieve join is geen directe keuze tussen een hash-join in de normale toepassing en batchmodus. Een adaptieve join begint altijd met het volledig vullen van de hashtabel. Pas als dit werk is voltooid, wordt de beslissing genomen om al dan niet over te stappen op een toepassingsimplementatie.
Tegen die tijd hebben we al potentieel aanzienlijke kosten gemaakt door de hash-join in het geheugen te vullen en te partitioneren. Dit maakt misschien niet veel uit voor het geval van één rij, maar het wordt steeds belangrijker naarmate de kardinaliteit toeneemt. De onverwachte "boost" kan een manier zijn om deze realiteit in de berekening op te nemen met behoud van redelijke rekenkosten.
Het kostenmodel van SQL Server is al lang een beetje bevooroordeeld tegen geneste loops join, misschien wel met enige rechtvaardiging. Zelfs de ideale geïndexeerde toepassing kan in de praktijk traag zijn als de benodigde gegevens zich niet al in het geheugen bevinden en het I/O-subsysteem niet flash is, vooral met een enigszins willekeurig toegangspatroon. Beperkte hoeveelheden geheugen en trage I/O zullen bijvoorbeeld niet geheel onbekend zijn voor gebruikers van lagere cloudgebaseerde database-engines.
Het is mogelijk dat praktische tests in dergelijke omgevingen hebben aangetoond dat een intuïtief geprijsde adaptieve join te snel kon worden omgezet in een aanvraag. Theorie is soms alleen goed in theorie.
Toch is de huidige situatie niet ideaal; het cachen van een plan op basis van een ongebruikelijk lage kardinaliteitsschatting zal leiden tot een adaptieve join die veel terughoudender is om over te schakelen naar een toepassing dan bij een grotere initiële schatting. Dit is een variant van het parametergevoeligheidsprobleem, maar het zal voor velen van ons een nieuwe overweging van dit type zijn.
Nu is het ook mogelijk het gebruik van de substructuurkosten van de volledige build-invoer voor het meest linkse punt van de kruisende kostenlijnen is gewoon een niet-gecorrigeerde fout of onoplettendheid. Ik heb het gevoel dat de huidige implementatie waarschijnlijk een opzettelijk praktisch compromis is, maar je hebt iemand nodig met toegang tot de ontwerpdocumenten en broncode om het zeker te weten.
Samenvatting
Met een adaptieve join kan SQL Server overgaan van een hash-join in batchmodus naar een toepassing nadat de hashtabel volledig is gevuld. Het neemt deze beslissing door het aantal rijen in de hashtabel te vergelijken met een vooraf berekende adaptieve drempel.
De drempel wordt berekend door te voorspellen waar de kosten van toepassing en hash-join gelijk zijn. Om dit punt te vinden, maakt SQL Server een tweede schatting van de interne join-kosten voor een andere build-invoerkardinaliteit - normaal gesproken één rij.
Verrassend genoeg omvatten de geschatte kosten voor de schatting van één rij de volledige substructuurkosten aan de buildzijde voor de oorspronkelijke kardinaliteitsschatting (niet geschaald naar één rij). Dit betekent dat de drempelwaarde afhangt van de oorspronkelijke kardinaliteitsschatting bij de build-ingang.
Bijgevolg kan een adaptieve join een onverwacht lage drempelwaarde hebben, wat betekent dat het veel minder waarschijnlijk is dat de adaptieve join overgaat van een hash-join. Het is onduidelijk of dit gedrag inherent is aan het ontwerp.
Gerelateerde lectuur
- Introductie van Batch Mode Adaptive Joins door Joe Sack
- Inzicht in adaptieve joins in de productdocumentatie
- Adaptive Join Internals door Dima Pilugin
- Hoe werken adaptieve joins in batchmodus? over Stack Exchange voor databasebeheerders door Erik Darling
- Een adaptieve join-regressie door Joe Obbish
- Als u adaptieve joins wilt, heeft u bredere indexen nodig en is groter beter? door Erik Darling
- Parameter Sniffing:Adaptive Joins door Brent Ozar
- Vraag en antwoord over intelligente queryverwerking door Joe Sack
Bijlage
Dit gedeelte behandelt een aantal adaptieve join-aspecten die moeilijk op een natuurlijke manier in de hoofdtekst konden worden opgenomen.
Het uitgebreide adaptieve plan
Je zou kunnen proberen naar een visuele weergave van het interne plan te kijken met behulp van ongedocumenteerde traceringsvlag 9415, zoals geleverd door Dima Pilugin in zijn uitstekende adaptieve join internals-artikel dat hierboven is gelinkt. Als deze vlag actief is, wordt het adaptieve deelnameplan voor ons lopende voorbeeld het volgende:
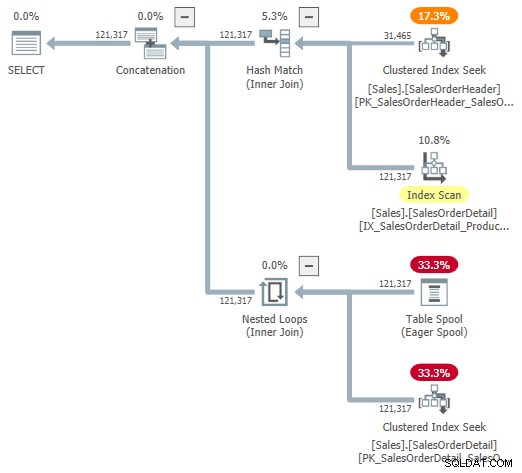
Dit is een nuttige weergave om het begrip te vergemakkelijken, maar het is niet helemaal nauwkeurig, volledig of consistent. De Table Spool bestaat bijvoorbeeld niet, het is een standaardweergave voor de adaptieve bufferlezer rijen rechtstreeks uit de hash-tabel in batchmodus lezen.
De eigenschappen van de operator en kardinaliteitsschattingen zijn ook een beetje overal. De uitvoer van de adaptieve bufferlezer ("spool") moet 31.465 rijen zijn, niet 121.317. De kosten van de substructuur van de aanvraag worden ten onrechte beperkt door de kosten van de bovenliggende operator. Dit is normaal voor showplan, maar het heeft geen zin in een adaptieve join-context.
Er zijn ook andere inconsistenties - te veel om op te noemen - maar dat kan gebeuren met niet-gedocumenteerde traceervlaggen. Het hierboven getoonde uitgebreide plan is niet bedoeld voor gebruik door eindgebruikers, dus misschien is het niet helemaal verrassend. De boodschap hier is om niet te veel te vertrouwen op de getallen en eigenschappen die in deze ongedocumenteerde vorm worden getoond.
Ik moet ook vermelden dat de voltooide standaard adaptieve join-planoperator niet geheel zonder zijn eigen consistentieproblemen is. Deze komen vrijwel uitsluitend voort uit de verborgen details.
De weergegeven adaptieve join-eigenschappen zijn bijvoorbeeld afkomstig van een combinatie van de onderliggende Concat , Hash Join , en Toepassen exploitanten. U kunt een adaptieve join-rapportage in batchmodus zien voor geneste loops-joins (wat onmogelijk is), en de weergegeven verstreken tijd wordt daadwerkelijk gekopieerd van de verborgen Concat , niet de specifieke join die tijdens runtime werd uitgevoerd.
De gebruikelijke verdachten
We kunnen haal wat nuttige informatie uit de soorten ongedocumenteerde traceervlaggen die normaal worden gebruikt om naar optimalisatie-uitvoer te kijken. Bijvoorbeeld:
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (
QUERYTRACEON 3604,
QUERYTRACEON 8607,
QUERYTRACEON 8612); Uitvoer (zwaar bewerkt voor leesbaarheid):
*** Uitvoerstructuur:***PhyOp_ExecutionModeAdapter(BatchToRow) Card=121317 Kosten=1.05095
- PhyOp_Concat (batch) Kaart=121317 Kosten=1,05325
- PhyOp_HashJoinx_jtInner (batch) Card=121317 Kosten=1.05083
- PhyOp_Range Sales.SalesOrderHeader Card=31465 Kosten=0.54456
- PhyOp_Filter(batch) Kaart=121317 Kosten=0.397185
- PhyOp_Range Sales.SalesOrderDetail Card=121317 Kosten=0.338953
- PhyOp_ExecutionModeAdapter(RowToBatch) Card=121317 Kosten=10.0798
- PhyOp_Apply Card=121317 Kosten=10.0553
- PhyOp_ExecutionModeAdapter(BatchToRow) Kaart=31465 Kosten=0,544623
- PhyOp_Range Sales.SalesOrderHeader Card=31465 Kosten=0.54456 [** 3 **]
- PhyOp_Filter Card=3.85562 Kosten=9.00356
- PhyOp_Range Sales.SalesOrderDetail Card=3.85562 Kosten=8.94533
- PhyOp_ExecutionModeAdapter(BatchToRow) Kaart=31465 Kosten=0,544623
- PhyOp_Apply Card=121317 Kosten=10.0553
Dit geeft enig inzicht in de geschatte kosten voor het geval van volledige kardinaliteit met hash en past alternatieven toe zonder aparte queries te schrijven en hints te gebruiken. Zoals vermeld in de hoofdtekst, zijn deze traceervlaggen niet effectief binnen CuNewJoinEstimate , dus we kunnen op deze manier de herhaalde berekeningen voor het geval van 31.465 rijen of de details voor de schattingen van één rij niet direct zien.
Samenvoegen join en rijmodus hash join
Adaptieve joins bieden alleen een overgang van hash-join in batchmodus naar rijmodus van toepassing. Voor de redenen waarom hash-join in rijmodus niet wordt ondersteund, raadpleegt u de Q&A over intelligente queryverwerking in de sectie Gerelateerd lezen. Kortom, men dacht dat hash-joins in rijmodus te gevoelig zouden zijn voor prestatieregressie.
Overschakelen naar een samenvoeging in de rijmodus zou een andere optie zijn, maar de optimizer houdt hier momenteel geen rekening mee. Zoals ik het begrijp, is het onwaarschijnlijk dat het in de toekomst in deze richting zal worden uitgebreid.
Sommige overwegingen zijn hetzelfde als voor hash-joins in de rijmodus. Bovendien zijn merge-joinplannen minder gemakkelijk uitwisselbaar met hash-join, zelfs als we ons beperken tot geïndexeerde merge-join (geen expliciete sortering).
Er is ook een veel groter onderscheid tussen hash en apply dan tussen hash en merge. Zowel hash als merge zijn geschikt voor grotere inputs, en Apply is beter geschikt voor kleinere inputs. Samenvoegen is niet zo gemakkelijk te parallelliseren als hash-join en schaalt niet zo goed als het aantal threads toeneemt.
Gezien de motivatie voor adaptieve joins is om beter om te gaan met aanzienlijk variërende invoergroottes - en alleen hash-join ondersteunt batchmodusverwerking - de keuze van batch-hash versus rijtoepassing is de meest natuurlijke. Ten slotte zou het hebben van drie adaptieve join-keuzes de drempelberekening aanzienlijk compliceren voor mogelijk weinig winst.