Dit is het dertiende en laatste deel in een serie over tabeluitdrukkingen. Deze maand vervolg ik de discussie die ik vorige maand begon over inline table-valued functions (iTVF's).
Vorige maand heb ik uitgelegd dat wanneer SQL Server iTVF's inline plaatst die worden opgevraagd met constanten als invoer, het standaard optimalisatie van parameterinbedding toepast. Inbedding van parameters betekent dat SQL Server parameterverwijzingen in de query vervangt door de letterlijke constante waarden van de huidige uitvoering, en vervolgens wordt de code met de constanten geoptimaliseerd. Dit proces maakt vereenvoudigingen mogelijk die kunnen resulteren in meer optimale queryplannen. Deze maand ga ik dieper in op het onderwerp en behandel ik specifieke gevallen voor dergelijke vereenvoudigingen zoals constant vouwen en dynamisch filteren en ordenen. Als je een opfriscursus nodig hebt over de optimalisatie van het insluiten van parameters, lees dan het artikel van vorige maand en het uitstekende artikel Parameter Sniffing, Embedding en RECOMPILE-opties van Paul White.
In mijn voorbeelden gebruik ik een voorbeelddatabase met de naam TSQLV5. U vindt het script dat het maakt en vult hier en het ER-diagram hier.
Constant vouwen
Tijdens de vroege stadia van het verwerken van query's evalueert SQL Server bepaalde expressies met constanten, en vouwt deze naar de resultaatconstanten. De uitdrukking 40 + 2 kan bijvoorbeeld worden gevouwen tot de constante 42. De regels voor vouwbare en niet-vouwbare uitdrukkingen vindt u hier onder "Constant vouwen en evaluatie van uitdrukkingen".
Wat interessant is met betrekking tot iTVF's, is dat dankzij optimalisatie van het inbedden van parameters, query's met iTVF's waarbij u constanten doorgeeft als invoer, onder de juiste omstandigheden kunnen profiteren van constant vouwen. Het kennen van de regels voor opvouwbare en niet-opvouwbare uitdrukkingen kan van invloed zijn op de manier waarop u uw iTVF's implementeert. In sommige gevallen kunt u door zeer subtiele wijzigingen in uw uitdrukkingen toe te passen, meer optimale plannen mogelijk maken met een beter gebruik van indexering.
Beschouw als voorbeeld de volgende implementatie van een iTVF genaamd Sales.MyOrders:
USE TSQLV5;
GO
CREATE OR ALTER FUNCTION Sales.MyOrders
( @add AS INT, @subtract AS INT )
RETURNS TABLE
AS
RETURN
SELECT orderid + @add - @subtract AS myorderid,
orderdate, custid, empid
FROM Sales.Orders;
GO Geef de volgende vraag met betrekking tot de iTVF (ik noem dit vraag 1):
SELECT myorderid, orderdate, custid, empid FROM Sales.MyOrders(1, 10248) ORDER BY myorderid;
Het plan voor Query 1 wordt getoond in figuur 1.
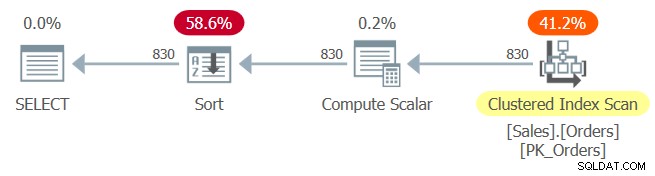 Figuur 1:Plan voor Query 1
Figuur 1:Plan voor Query 1
De geclusterde index PK_Orders is gedefinieerd met orderid als sleutel. Als hier constant vouwen had plaatsgevonden na het inbedden van parameters, zou de besteluitdrukking orderid + 1 – 10248 zijn gevouwen tot orderid – 10247. Deze uitdrukking zou zijn beschouwd als een ordebehoudende uitdrukking met betrekking tot orderid, en als zodanig zou de optimizer om te vertrouwen op indexvolgorde. Helaas is dat niet het geval, zoals blijkt uit de expliciete Sort-operator in het plan. Dus wat gebeurde er?
Constante vouwregels zijn kieskeurig. De uitdrukking kolom1 + constant1 – constant2 wordt van links naar rechts geëvalueerd voor constante vouwdoeleinden. Het eerste deel, kolom1 + constant1 is niet gevouwen. Laten we deze uitdrukking1 noemen. Het volgende deel dat wordt geëvalueerd, wordt behandeld als expression1 – constant2, dat ook niet wordt gevouwen. Zonder vouwen wordt een uitdrukking in de vorm kolom1 + constant1 – constant2 niet beschouwd als volgordebehoud met betrekking tot kolom1, en kan daarom niet vertrouwen op indexvolgorde, zelfs als u een ondersteunende index op kolom1 hebt. Evenzo is de uitdrukking constant1 + column1 – constant2 niet constant opvouwbaar. De uitdrukking constant1 – constant2 + column1 is echter opvouwbaar. Meer specifiek wordt het eerste deel constant1 – constant2 gevouwen tot een enkele constante (laten we het constant3 noemen), wat resulteert in de uitdrukking constant3 + column1. Deze uitdrukking wordt beschouwd als een ordebehoudende uitdrukking met betrekking tot kolom1. Dus zolang u ervoor zorgt dat u uw uitdrukking schrijft met het laatste formulier, kunt u de optimizer inschakelen om te vertrouwen op indexvolgorde.
Overweeg de volgende query's (ik zal ernaar verwijzen als Query 2, Query 3 en Query 4), en kijk voordat u naar de queryplannen kijkt of u kunt zien welke expliciete sortering in het plan inhoudt en welke niet:
-- Query 2 SELECT orderid + 1 - 10248 AS myorderid, orderdate, custid, empid FROM Sales.Orders ORDER BY myorderid; -- Query 3 SELECT 1 + orderid - 10248 AS myorderid, orderdate, custid, empid FROM Sales.Orders ORDER BY myorderid; -- Query 4 SELECT 1 - 10248 + orderid AS myorderid, orderdate, custid, empid FROM Sales.Orders ORDER BY myorderid;
Bekijk nu de plannen voor deze zoekopdrachten zoals weergegeven in figuur 2.
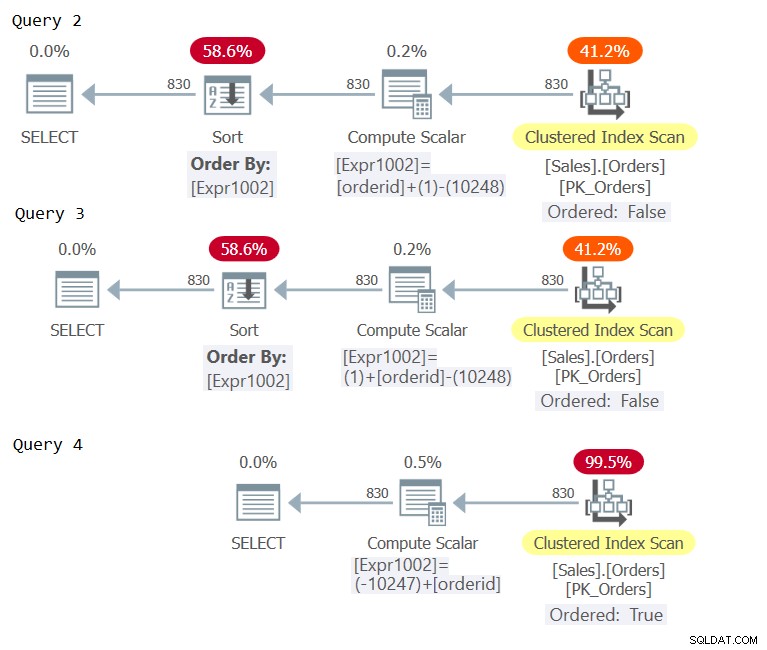 Figuur 2:Plannen voor Query 2, Query 3 en Query 4
Figuur 2:Plannen voor Query 2, Query 3 en Query 4
Bekijk de Compute Scalar-operators in de drie plannen. Alleen het plan voor Query 4 had constant vouwen, wat resulteerde in een ordeningsuitdrukking die als ordebehoudend wordt beschouwd met betrekking tot orderid, waarbij expliciete sortering wordt vermeden.
Als u dit aspect van constant vouwen begrijpt, kunt u de iTVF eenvoudig repareren door de uitdrukking orderid + @add – @subtract te wijzigen in @add – @subtract + orderid, zoals:
CREATE OR ALTER FUNCTION Sales.MyOrders
( @add AS INT, @subtract AS INT )
RETURNS TABLE
AS
RETURN
SELECT @add - @subtract + orderid AS myorderid,
orderdate, custid, empid
FROM Sales.Orders;
GO Vraag de functie opnieuw op (ik noem dit Query 5):
SELECT myorderid, orderdate, custid, empid FROM Sales.MyOrders(1, 10248) ORDER BY myorderid;
Het plan voor deze zoekopdracht wordt getoond in figuur 3.
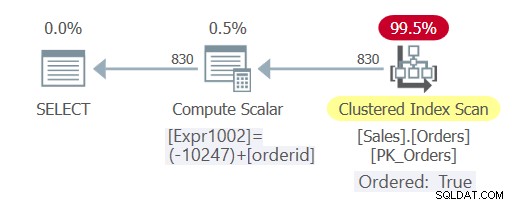 Figuur 3:Plan voor Query 5
Figuur 3:Plan voor Query 5
Zoals je kunt zien, ondervond de query deze keer constant vouwen en kon de optimizer vertrouwen op indexvolgorde, waardoor expliciete sortering werd vermeden.
Ik heb een eenvoudig voorbeeld gebruikt om deze optimalisatietechniek te demonstreren, en daarom lijkt het misschien een beetje gekunsteld. Een praktische toepassing van deze techniek vindt u in het artikel Number series generator challenge solutions – Part 1.
Dynamisch filteren/bestellen
Vorige maand heb ik het verschil behandeld tussen de manier waarop SQL Server een query optimaliseert in een iTVF en dezelfde query in een opgeslagen procedure. SQL Server past doorgaans standaard optimalisatie van parameterinsluiting toe voor een query met een iTVF met constanten als invoer, maar optimaliseert de geparametriseerde vorm van een query in een opgeslagen procedure. Als u echter OPTION(RECOMPILE) toevoegt aan de query in de opgeslagen procedure, past SQL Server in dit geval doorgaans ook optimalisatie van parameterinsluiting toe. De voordelen in de iTVF-zaak zijn onder meer het feit dat u het bij een query kunt betrekken, en zolang u herhaalde constante invoer doorgeeft, is er de mogelijkheid om een eerder in de cache opgeslagen plan opnieuw te gebruiken. Met een opgeslagen procedure kunt u deze niet in een query betrekken, en als u OPTION (RECOMPILE) toevoegt om optimalisatie van het insluiten van parameters te krijgen, is er geen mogelijkheid voor hergebruik van plannen. De opgeslagen procedure biedt veel meer flexibiliteit met betrekking tot de code-elementen die u kunt gebruiken.
Laten we eens kijken hoe dit allemaal uitpakt in een klassieke taak voor het inbedden en bestellen van parameters. Hieronder volgt een vereenvoudigde opgeslagen procedure die dynamische filtering en sortering toepast, vergelijkbaar met degene die Paul in zijn artikel gebruikte:
CREATE OR ALTER PROCEDURE HR.GetEmpsP @lastnamepattern AS NVARCHAR(50), @sort AS TINYINT AS SET NOCOUNT ON; SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL ORDER BY CASE WHEN @sort = 1 THEN empid END, CASE WHEN @sort = 2 THEN firstname END, CASE WHEN @sort = 3 THEN lastname END; GO
Merk op dat de huidige implementatie van de opgeslagen procedure OPTION(RECOMPILE) niet bevat in de query.
Overweeg de volgende uitvoering van de opgeslagen procedure:
EXEC HR.GetEmpsP @lastnamepattern = N'D%', @sort = 3;
Het plan voor deze uitvoering is weergegeven in figuur 4.
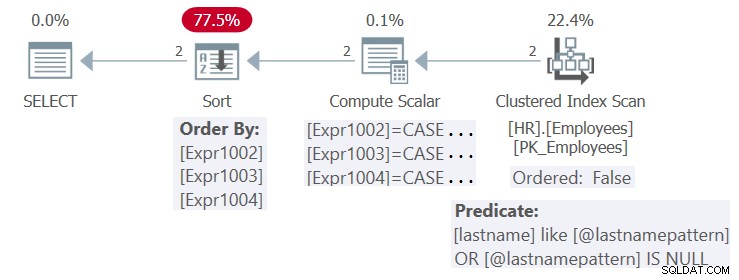 Figuur 4:Procedureplan HR.GetEmpsP
Figuur 4:Procedureplan HR.GetEmpsP
Er is een index gedefinieerd in de kolom achternaam. Theoretisch zou de index met de huidige invoer nuttig kunnen zijn voor zowel de filter- (met een zoekfunctie) als de ordeningsbehoefte (met een geordende:echte bereikscan) van de zoekopdracht. Aangezien SQL Server echter standaard de geparametriseerde vorm van de query optimaliseert en geen parameterinsluiting toepast, past het niet de vereenvoudigingen toe die nodig zijn om te kunnen profiteren van de index voor zowel filter- als besteldoeleinden. Het plan is dus herbruikbaar, maar niet optimaal.
Om te zien hoe dingen veranderen met optimalisatie van het insluiten van parameters, wijzigt u de opgeslagen procedurequery door OPTION(RECOMPILE) toe te voegen, zoals:
CREATE OR ALTER PROCEDURE HR.GetEmpsP @lastnamepattern AS NVARCHAR(50), @sort AS TINYINT AS SET NOCOUNT ON; SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL ORDER BY CASE WHEN @sort = 1 THEN empid END, CASE WHEN @sort = 2 THEN firstname END, CASE WHEN @sort = 3 THEN lastname END OPTION(RECOMPILE); GO
Voer de opgeslagen procedure opnieuw uit met dezelfde invoer die u eerder gebruikte:
EXEC HR.GetEmpsP @lastnamepattern = N'D%', @sort = 3;
Het plan voor deze uitvoering wordt getoond in figuur 5.
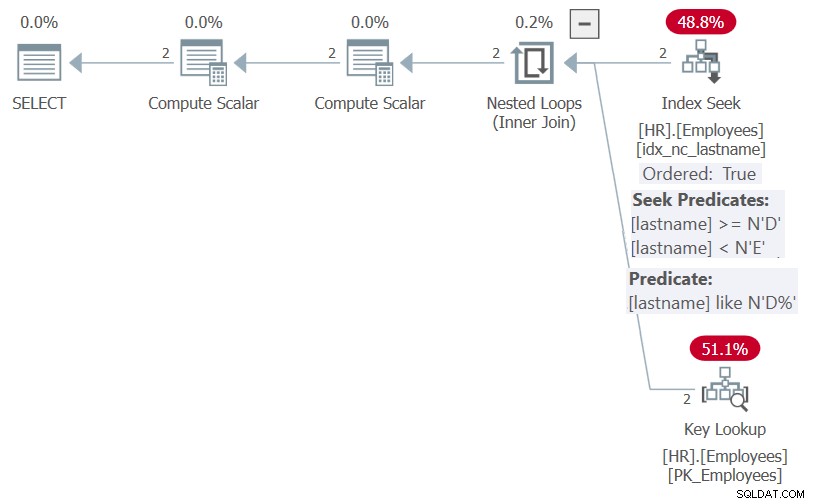 Figuur 5:Procedureplan HR.GetEmpsP met OPTION(HERCOMPILE)
Figuur 5:Procedureplan HR.GetEmpsP met OPTION(HERCOMPILE)
Zoals u kunt zien, kon SQL Server dankzij optimalisatie van parameterinsluiting het filterpredikaat vereenvoudigen tot het sargable predikaat achternaam LIKE N'D%', en de bestellijst tot NULL, NULL, achternaam. Beide elementen zouden baat kunnen hebben bij de index op achternaam, en daarom toont het plan een zoekactie in de index en geen expliciete sortering.
Theoretisch verwacht je een vergelijkbare vereenvoudiging als je de query in een iTVF implementeert, en dus vergelijkbare optimalisatievoordelen, maar met de mogelijkheid om plannen in de cache opnieuw te gebruiken wanneer dezelfde invoerwaarden opnieuw worden gebruikt. Dus, laten we proberen...
Hier is een poging om dezelfde zoekopdracht in een iTVF te implementeren (voer deze code nog niet uit):
CREATE OR ALTER FUNCTION HR.GetEmpsF
(
@lastnamepattern AS NVARCHAR(50),
@sort AS TINYINT
)
RETURNS TABLE
AS
RETURN
SELECT empid, firstname, lastname
FROM HR.Employees
WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL
ORDER BY
CASE WHEN @sort = 1 THEN empid END,
CASE WHEN @sort = 2 THEN firstname END,
CASE WHEN @sort = 3 THEN lastname END;
GO Ziet u een probleem met deze implementatie voordat u probeert deze code uit te voeren? Onthoud dat ik aan het begin van deze serie heb uitgelegd dat een tabeluitdrukking een tabel is. De hoofdtekst van een tabel is een set (of multiset) rijen en heeft als zodanig geen volgorde. Daarom kan een query die als tabelexpressie wordt gebruikt, normaal gesproken geen ORDER BY-component hebben. Als u deze code probeert uit te voeren, krijgt u inderdaad de volgende foutmelding:
Msg 1033, Level 15, State 1, Procedure GetEmps, Line 16 [Batch Start Line 128]De ORDER BY-clausule is ongeldig in views, inline-functies, afgeleide tabellen, subquery's en algemene tabelexpressies, tenzij TOP, OFFSET of FOR XML is ook opgegeven.
Natuurlijk, zoals de fout zegt, zal SQL Server een uitzondering maken als u een filterelement zoals TOP of OFFSET-FETCH gebruikt, dat vertrouwt op de ORDER BY-component om het bestelaspect van het filter te definiëren. Maar zelfs als u dankzij deze uitzondering een ORDER BY-component in de inner query opneemt, krijgt u nog steeds geen garantie voor de volgorde van het resultaat in een outer query ten opzichte van de tabelexpressie, tenzij deze zijn eigen ORDER BY-component heeft .
Als je de query nog steeds in een iTVF wilt implementeren, kun je de innerlijke query het dynamische filtergedeelte laten afhandelen, maar niet de dynamische volgorde, zoals:
CREATE OR ALTER FUNCTION HR.GetEmpsF ( @lastnamepattern AS NVARCHAR(50) ) RETURNS TABLE AS RETURN SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL; GO
Natuurlijk kunt u de buitenste query elke specifieke bestelbehoefte laten afhandelen, zoals in de volgende code (ik noem dit Query 6):
SELECT empid, firstname, lastname FROM HR.GetEmpsF(N'D%') ORDER BY lastname;
Het plan voor deze query wordt getoond in figuur 6.
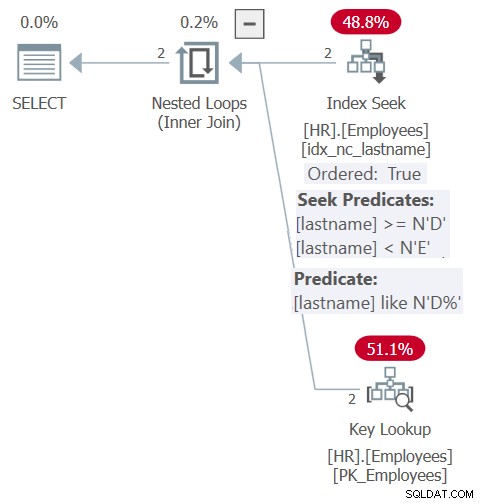 Figuur 6:Plan voor Query 6
Figuur 6:Plan voor Query 6
Dankzij inlining en inbedding van parameters is het plan vergelijkbaar met het plan dat eerder is getoond voor de opgeslagen procedurequery in figuur 5. Het plan vertrouwt efficiënt op de index voor zowel filter- als besteldoeleinden. U krijgt echter niet de flexibiliteit van de dynamische bestelinvoer zoals u had met de opgeslagen procedure. Je moet expliciet zijn met de volgorde in de ORDER BY-component in de query tegen de functie.
Het volgende voorbeeld heeft een query op de functie zonder filtering en zonder bestelvereisten (ik noem dit Query 7):
SELECT empid, firstname, lastname FROM HR.GetEmpsF(NULL);
Het plan voor deze query wordt getoond in figuur 7.
 Figuur 7:Plan voor Query 7
Figuur 7:Plan voor Query 7
Na inlining en het insluiten van parameters wordt de query vereenvoudigd, zodat er geen filterpredikaat en geen volgorde meer is, en wordt geoptimaliseerd met een volledige ongeordende scan van de geclusterde index.
Voer ten slotte een query uit op de functie met N'D%' als het invoerpatroon voor het filteren van de achternaam en rangschik het resultaat in de kolom voornaam (ik noem dit Query 8):
SELECT empid, firstname, lastname FROM HR.GetEmpsF(N'D%') ORDER BY firstname;
Het plan voor deze zoekopdracht wordt getoond in figuur 8.
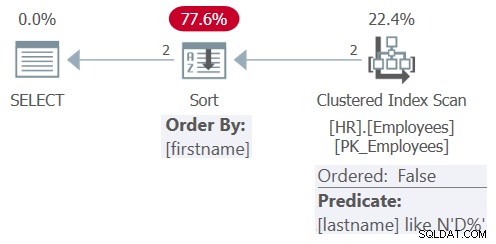 Figuur 8:Plan voor Query 8
Figuur 8:Plan voor Query 8
Na vereenvoudiging heeft de query alleen betrekking op het filterpredikaat achternaam LIKE N'D%' en het bestelelement voornaam. Deze keer kiest de optimizer ervoor om een ongeordende scan van de geclusterde index toe te passen, met het resterende predikaat achternaam LIKE N'D%', gevolgd door expliciete sortering. Het heeft ervoor gekozen om geen zoekactie in de index op achternaam toe te passen omdat de index niet dekkend is, de tabel zo klein is en de indexvolgorde niet gunstig is voor de huidige behoeften voor het bestellen van zoekopdrachten. Er is ook geen index gedefinieerd in de kolom voornaam, dus er moet toch een expliciete sortering worden toegepast.
Conclusie
De standaard parameter-inbeddingsoptimalisatie van iTVF's kan ook resulteren in constant vouwen, waardoor meer optimale plannen mogelijk zijn. U moet echter rekening houden met constante vouwregels om te bepalen hoe u uw uitdrukkingen het beste kunt formuleren.
Het implementeren van logica in een iTVF heeft voor- en nadelen in vergelijking met het implementeren van logica in een opgeslagen procedure. Als u niet geïnteresseerd bent in optimalisatie van het insluiten van parameters, kan de standaard geparametriseerde query-optimalisatie van opgeslagen procedures resulteren in een meer optimaal plancaching- en hergebruikgedrag. In gevallen waarin u geïnteresseerd bent in optimalisatie van het insluiten van parameters, krijgt u dit meestal standaard bij iTVF's. Om deze optimalisatie met opgeslagen procedures te krijgen, moet u de RECOMPILE-queryoptie toevoegen, maar dan krijgt u geen hergebruik van het plan. Met iTVF's kunt u in ieder geval hergebruik van plannen krijgen, op voorwaarde dat dezelfde parameterwaarden worden herhaald. Aan de andere kant heb je minder flexibiliteit met de query-elementen die je in een iTVF kunt gebruiken; u mag bijvoorbeeld geen ORDER BY-component voor presentaties hebben.
Terug naar de hele serie over tabeluitdrukkingen, ik vind het onderwerp super belangrijk voor databasebeoefenaars. De meer complete serie omvat de subserie op de nummerreeksgenerator, die is geïmplementeerd als een iTVF. In totaal omvat de serie de volgende 19 delen:
- Grondbeginselen van tabeluitdrukkingen, deel 1
- Grondbeginselen van tabeluitdrukkingen, deel 2 – Afgeleide tabellen, logische overwegingen
- Grondbeginselen van tabeluitdrukkingen, deel 3 – Afgeleide tabellen, overwegingen voor optimalisatie
- Grondbeginselen van tabeluitdrukkingen, deel 4 – Afgeleide tabellen, overwegingen voor optimalisatie, vervolg
- Grondbeginselen van tabeluitdrukkingen, deel 5 – CTE's, logische overwegingen
- Grondbeginselen van tabeluitdrukkingen, deel 6 – Recursieve CTE's
- Grondbeginselen van tabeluitdrukkingen, deel 7 – CTE's, overwegingen voor optimalisatie
- Grondbeginselen van tabeluitdrukkingen, deel 8 – CTE's, optimalisatieoverwegingen vervolg
- Grondbeginselen van tabeluitdrukkingen, deel 9 – Weergaven, vergeleken met afgeleide tabellen en CTE's
- Grondbeginselen van tabeluitdrukkingen, deel 10 – Weergaven, SELECT * en DDL-wijzigingen
- Grondbeginselen van tabeluitdrukkingen, deel 11 – Aanzichten, overwegingen bij wijzigingen
- Grondbeginselen van tabeluitdrukkingen, deel 12 – Inline tabelwaardige functies
- Grondbeginselen van tabeluitdrukkingen, deel 13 – Inline tabelwaardige functies, vervolg
- De uitdaging is begonnen! Community-oproep voor het maken van de snelste nummerreeksgenerator
- Uitdagingsoplossingen voor generatorreeksen - deel 1
- Oplossingen voor generatoruitdagingen voor nummerreeksen - Deel 2
- Uitdagingsoplossingen voor generatorreeksen - deel 3
- Uitdagingsoplossingen voor generatorreeksen - deel 4
- Oplossingen voor het genereren van uitdagingen voor nummerreeksen - Deel 5