Wat doet indexeren?
Indexeren is de manier om een ongeordende tabel in een volgorde te krijgen die de efficiëntie van de zoekopdracht tijdens het zoeken maximaliseert.
Wanneer een tabel niet-geïndexeerd is, zal de volgorde van de rijen waarschijnlijk niet waarneembaar zijn door de zoekopdracht als op enigerlei wijze geoptimaliseerd, en uw zoekopdracht zal daarom lineair door de rijen moeten zoeken. Met andere woorden, de zoekopdrachten zullen elke rij moeten doorzoeken om de rijen te vinden die aan de voorwaarden voldoen. Zoals u zich kunt voorstellen, kan dit lang duren. Door elke rij heen kijken is niet erg efficiënt.
De onderstaande tabel vertegenwoordigt bijvoorbeeld een tabel in een fictieve gegevensbron, die volledig ongeordend is.
| company_id | eenheid | eenheidskosten |
|---|---|---|
| 10 | 12 | 1,15 |
| 12 | 12 | 1,05 |
| 14 | 18 | 1.31 |
| 18 | 18 | 1.34 |
| 11 | 24 | 1,15 |
| 16 | 12 | 1.31 |
| 10 | 12 | 1,15 |
| 12 | 24 | 1.3 |
| 18 | 6 | 1.34 |
| 18 | 12 | 1.35 |
| 14 | 12 | 1,95 |
| 21 | 18 | 1.36 |
| 12 | 12 | 1,05 |
| 20 | 6 | 1.31 |
| 18 | 18 | 1.34 |
| 11 | 24 | 1,15 |
| 14 | 24 | 1,05 |
Als we de volgende query zouden uitvoeren:
SELECT
company_id,
units,
unit_cost
FROM
index_test
WHERE
company_id = 18
De database zou alle 17 rijen moeten doorzoeken in de volgorde waarin ze in de tabel staan, van boven naar beneden, één voor één. Dus om te zoeken naar alle mogelijke instanties van de company_id nummer 18, de database moet door de hele tabel kijken voor alle verschijningen van 18 in de company_id kolom.
Dit zal alleen maar meer en meer tijd in beslag nemen naarmate de tafel groter wordt. Naarmate de verfijning van de gegevens toeneemt, zou er uiteindelijk kunnen gebeuren dat een tabel met een miljard rijen wordt samengevoegd met een andere tabel met een miljard rijen; de zoekopdracht moet nu twee keer zoveel rijen doorzoeken die twee keer zoveel tijd kosten.
Je kunt zien hoe dit problematisch wordt in onze altijd met gegevens verzadigde wereld. Tabellen worden groter en zoeken neemt toe in uitvoeringstijd.
Het opvragen van een niet-geïndexeerde tabel, indien visueel gepresenteerd, zou er als volgt uitzien:
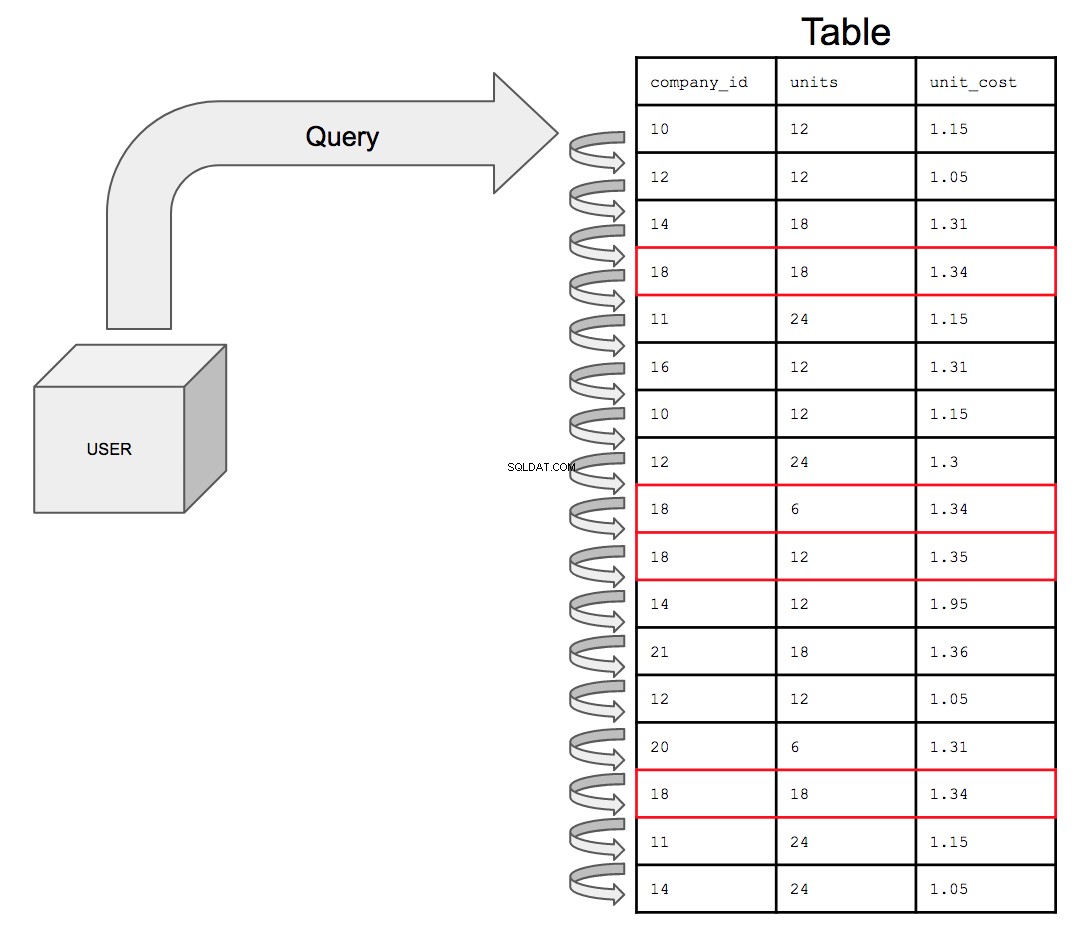
Wat indexering doet, is dat de kolom waarin de zoekvoorwaarden zich bevinden in een gesorteerde volgorde worden geplaatst om te helpen bij het optimaliseren van de zoekopdrachtprestaties.
Met een index op de company_id kolom, zou de tabel er in wezen als volgt uit zien:
| company_id | eenheid | eenheidskosten |
|---|---|---|
| 10 | 12 | 1,15 |
| 10 | 12 | 1,15 |
| 11 | 24 | 1,15 |
| 11 | 24 | 1,15 |
| 12 | 12 | 1,05 |
| 12 | 24 | 1.3 |
| 12 | 12 | 1,05 |
| 14 | 18 | 1.31 |
| 14 | 12 | 1,95 |
| 14 | 24 | 1,05 |
| 16 | 12 | 1.31 |
| 18 | 18 | 1.34 |
| 18 | 6 | 1.34 |
| 18 | 12 | 1.35 |
| 18 | 18 | 1.34 |
| 20 | 6 | 1.31 |
| 21 | 18 | 1.36 |
Nu kan de database zoeken naar company_id nummer 18 en retourneer alle gevraagde kolommen voor die rij en ga vervolgens naar de volgende rij. Als de comapny_id . van de volgende rij nummer ook 18 is, dan worden alle kolommen geretourneerd die in de query zijn gevraagd. Als de company_id . van de volgende rij 20 is, weet de zoekopdracht te stoppen met zoeken en wordt de zoekopdracht voltooid.
Hoe werkt indexeren?
In werkelijkheid herschikt de databasetabel zichzelf niet elke keer dat de queryvoorwaarden veranderen om de queryprestaties te optimaliseren:dat zou onrealistisch zijn. Wat er in werkelijkheid gebeurt, is dat de index ervoor zorgt dat de database een gegevensstructuur creëert. Het type datastructuur is zeer waarschijnlijk een B-Tree. Hoewel de voordelen van de B-Tree talrijk zijn, is het belangrijkste voordeel voor onze doeleinden dat het sorteerbaar is. Wanneer de gegevensstructuur op volgorde is gesorteerd, wordt onze zoektocht efficiënter om de voor de hand liggende redenen die we hierboven hebben aangegeven.
Wanneer de index een gegevensstructuur op een specifieke kolom creëert, is het belangrijk op te merken dat er geen andere kolom in de gegevensstructuur is opgeslagen. Onze gegevensstructuur voor de bovenstaande tabel bevat alleen de company_id nummers. Eenheden en unit_cost wordt niet vastgehouden in de gegevensstructuur.
Hoe weet de database welke andere velden in de tabel moeten worden geretourneerd?
Database-indexen zullen ook verwijzingen opslaan die eenvoudigweg referentie-informatie zijn voor de locatie van de aanvullende informatie in het geheugen. In principe bevat de index de company_id en het thuisadres van die specifieke rij op de geheugenschijf. De index ziet er in werkelijkheid als volgt uit:
| company_id | aanwijzer |
|---|---|
| 10 | _123 |
| 10 | _129 |
| 11 | _127 |
| 11 | _138 |
| 12 | _124 |
| 12 | _130 |
| 12 | _135 |
| 14 | _125 |
| 14 | _131 |
| 14 | _133 |
| 16 | _128 |
| 18 | _126 |
| 18 | _131 |
| 18 | _132 |
| 18 | _137 |
| 20 | _136 |
| 21 | _134 |
Met die index kan de zoekopdracht alleen zoeken naar de rijen in de company_id kolom met 18 en vervolgens met behulp van de aanwijzer naar de tabel gaan om de specifieke rij te vinden waar die aanwijzer zich bevindt. De query kan dan in de tabel gaan om de velden op te halen voor de gevraagde kolommen voor de rijen die aan de voorwaarden voldoen.
Als de zoekopdracht visueel zou worden weergegeven, zou deze er als volgt uitzien:
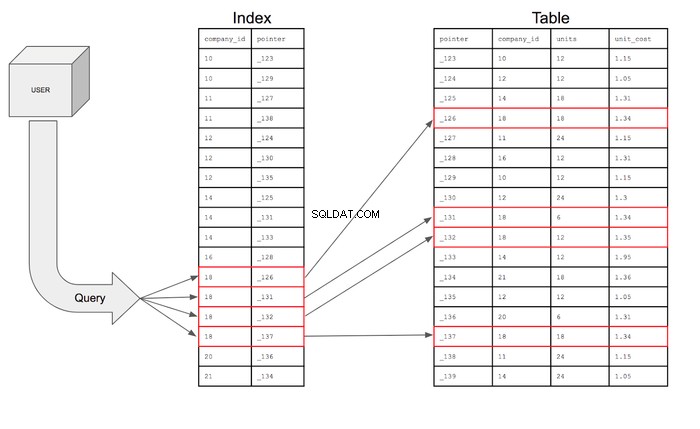
Samenvatting
- Indexeren voegt een gegevensstructuur toe met kolommen voor de zoekvoorwaarden en een aanwijzer
- De aanwijzer is het adres op de geheugenschijf van de rij met de rest van de informatie
- De indexgegevensstructuur is gesorteerd om de query-efficiëntie te optimaliseren
- De query zoekt naar de specifieke rij in de index; de index verwijst naar de aanwijzer die de rest van de informatie zal vinden.
- De index vermindert het aantal rijen dat de zoekopdracht moet doorzoeken van 17 naar 4.