In de vorige blogs hebben mijn collega's en ik je laten zien hoe je prestaties kunt bewaken, clusters kunt beheren en implementeren, back-ups kunt uitvoeren en zelfs automatische failover voor TimescaleDB kunt inschakelen.
In deze blog laten we u zien hoe u uw enkele TimescaleDB-instantie in slechts een paar eenvoudige stappen kunt schalen naar een cluster met meerdere knooppunten.
We beginnen met een gemeenschappelijke setup, een enkele node-instantie die op CentosOS draait. Het knooppunt is actief en wordt al gecontroleerd en beheerd door ClusterControl.
Als je wilt leren hoe je je TimescaleDB-instantie kunt implementeren of importeren, bekijk dan de blog van mijn collega Sebastian Insausti, "How to Easy Deploy TimescaleDB."
De opstelling ziet er als volgt uit...
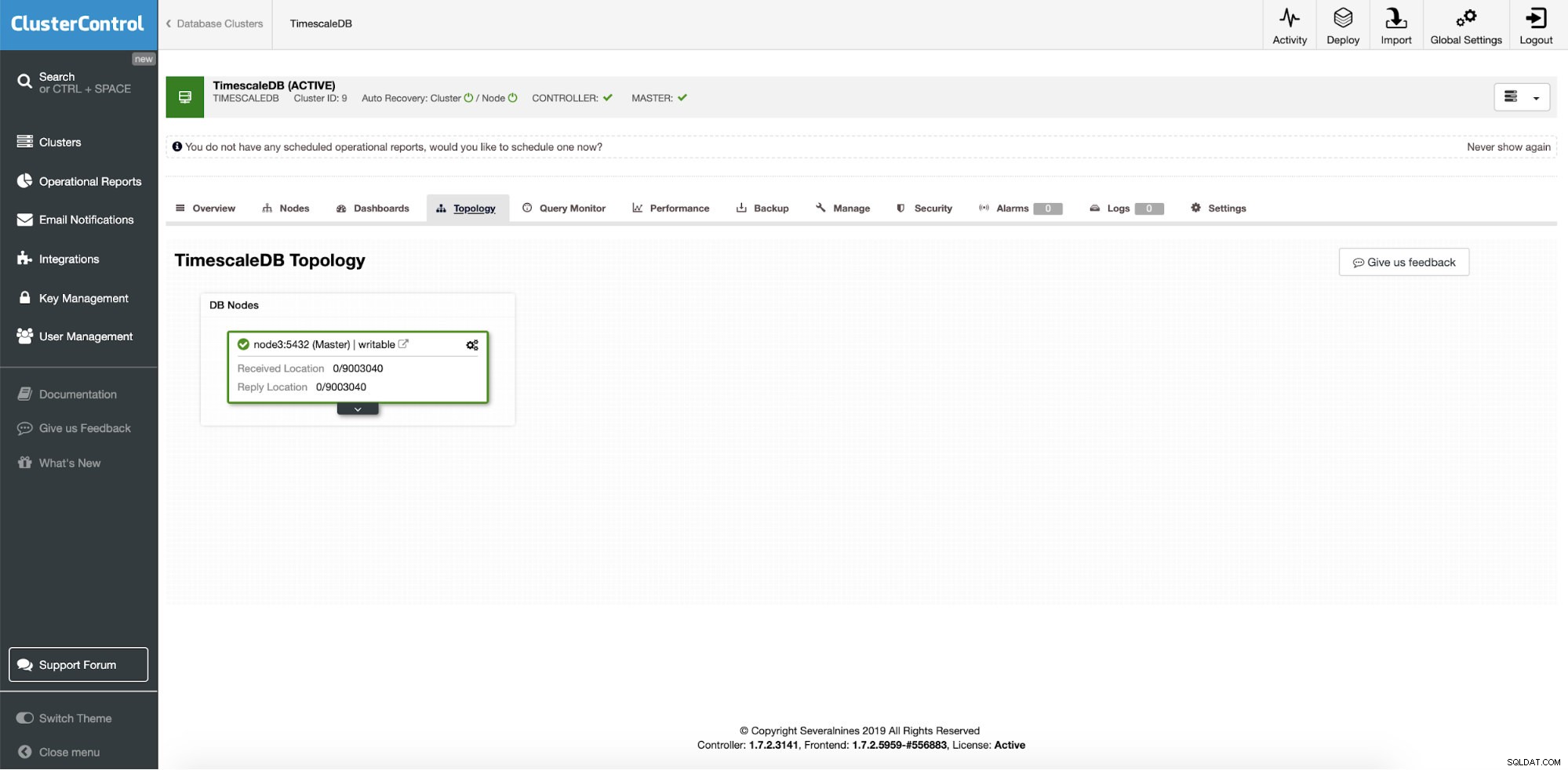 ClusterControl:TimescaleDB met één instantie
ClusterControl:TimescaleDB met één instantie Het is dus een enkele productie-instantie en we willen deze converteren naar een cluster zonder downtime. Ons belangrijkste doel is om leesbewerkingen van applicaties te schalen naar andere machines met een optie om ze te gebruiken als staging HA-servers bij het schrijven van servercrashes.
Meer nodes zouden ook de uitvaltijd voor applicatieonderhoud moeten verminderen. Zoals patching toegepast in de rollende herstartmodus - één knooppunt tegelijk gepatcht terwijl andere knooppunten databaseverbindingen bedienen.
De laatste vereiste is om één adres voor ons nieuwe cluster aan te maken, zodat onze nieuwe knooppunten vanaf één plek zichtbaar zijn voor de toepassing.

We kunnen ons actieplan samenvatten in twee grote stappen:
- Een replica toevoegen leest
- Installeer en configureer Haproxy
Een replica toevoegen leest
Als we naar clusteracties gaan en "Replicatieslave toevoegen" selecteren, kunnen we een nieuwe replica maken of een bestaande TimescaleDB-database als replica toevoegen.
 ClusterControl:replicatieslave toevoegen
ClusterControl:replicatieslave toevoegen 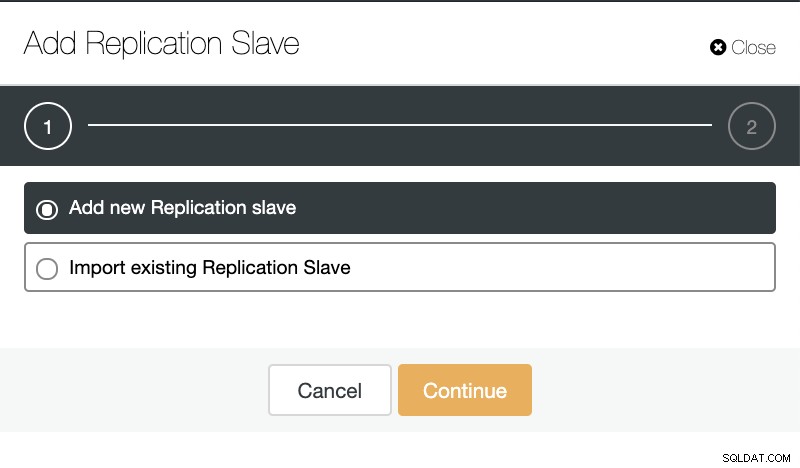 ClusterControl:nieuwe replicatieslave toevoegen, bestaande replicatieslave importeren
ClusterControl:nieuwe replicatieslave toevoegen, bestaande replicatieslave importeren Zoals je in de onderstaande afbeelding kunt zien, hoeven we alleen onze Master-server te kiezen, het IP-adres voor onze nieuwe slave-server en de databasepoort in te voeren.
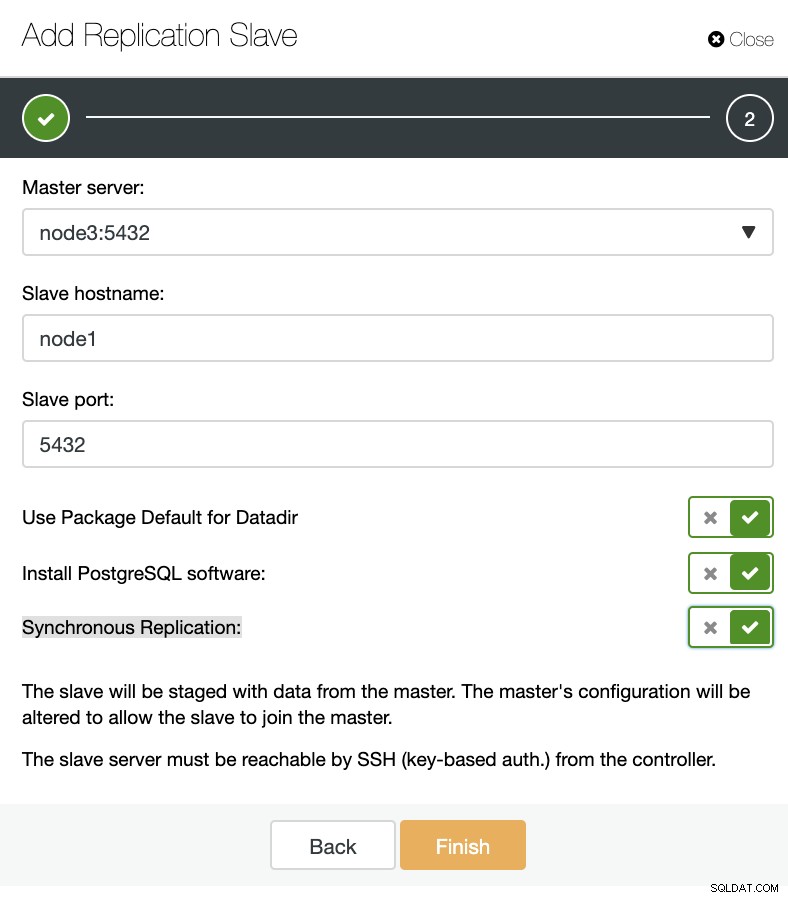 ClusterControl:replicatieslave toevoegen
ClusterControl:replicatieslave toevoegen Vervolgens kunnen we kiezen of we willen dat ClusterControl de software voor ons installeert en of de replicatieslave Synchroon of Asynchroon moet zijn. Wanneer u een bestaande slave-server importeert, kunt u de importoptie als volgt gebruiken:
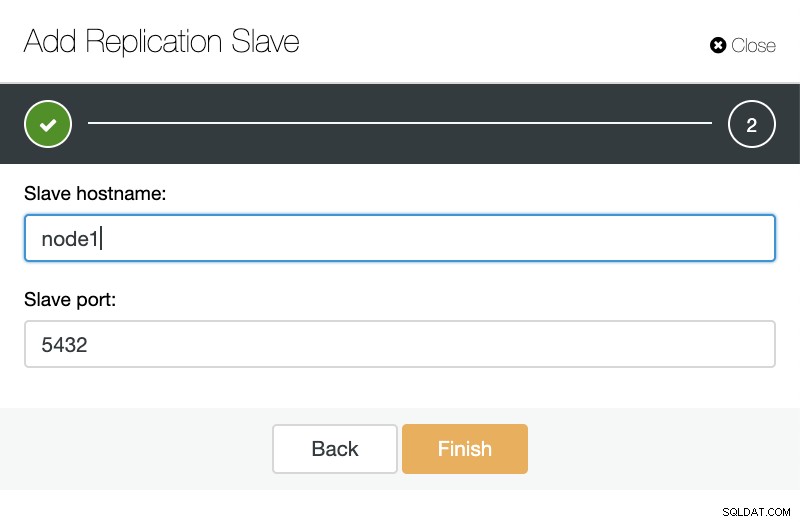 ClusterControl:replicatieslave importeren voor TimescaleDB
ClusterControl:replicatieslave importeren voor TimescaleDB In beide gevallen kunnen we zoveel replica's toevoegen als we willen. In ons voorbeeld zullen we twee knooppunten toevoegen. CusterControl zal een interne taak creëren en alle noodzakelijke stappen tegelijk uitvoeren.
 ClusterControl:lees-replica toevoegen
ClusterControl:lees-replica toevoegen Een Load Balancer toevoegen aan TimescaleDB
Op dit moment worden onze gegevens verdeeld over meerdere knooppunten of datacenters als u ervoor kiest om replicatieslave-knooppunten op een andere locatie toe te voegen. Het cluster wordt uitgeschaald met twee extra leesreplica-knooppunten.
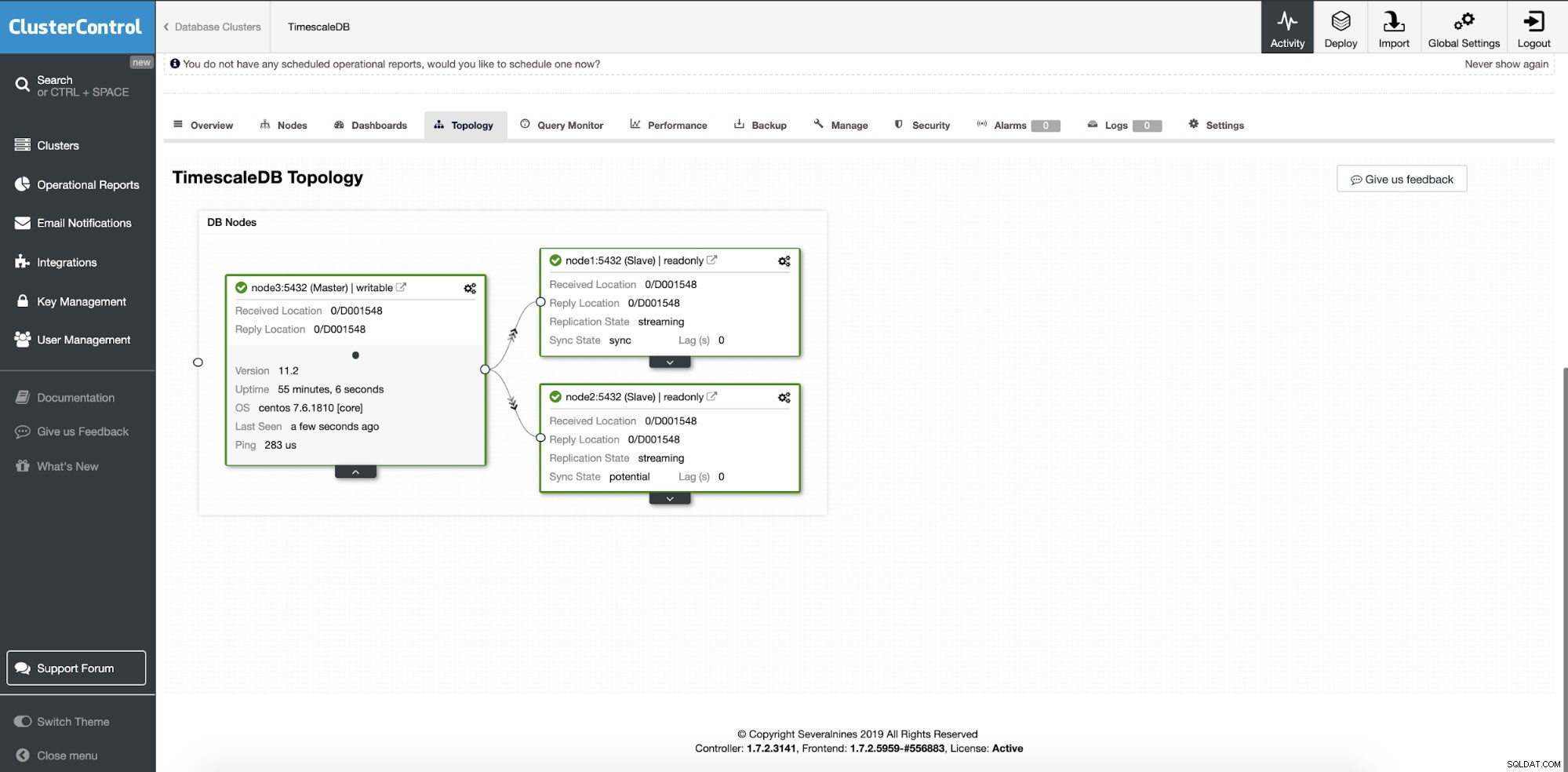 ClusterControl:twee knooppunten toegevoegd
ClusterControl:twee knooppunten toegevoegd De vraag is hoe de toepassing weet tot welk databaseknooppunt toegang moet worden verkregen? We zullen HAProxy en verschillende poorten gebruiken voor schrijf- en leesbewerkingen.
Kies in het TimescaleDB-cluster, contextmenu om load balancer toe te voegen.

Nu moeten we de locatie van de server opgeven waar Haproxy moet worden geïnstalleerd, welk beleid we willen gebruiken voor databaseverbindingen en welke knooppunten deel uitmaken van de Haproxy-configuratie.
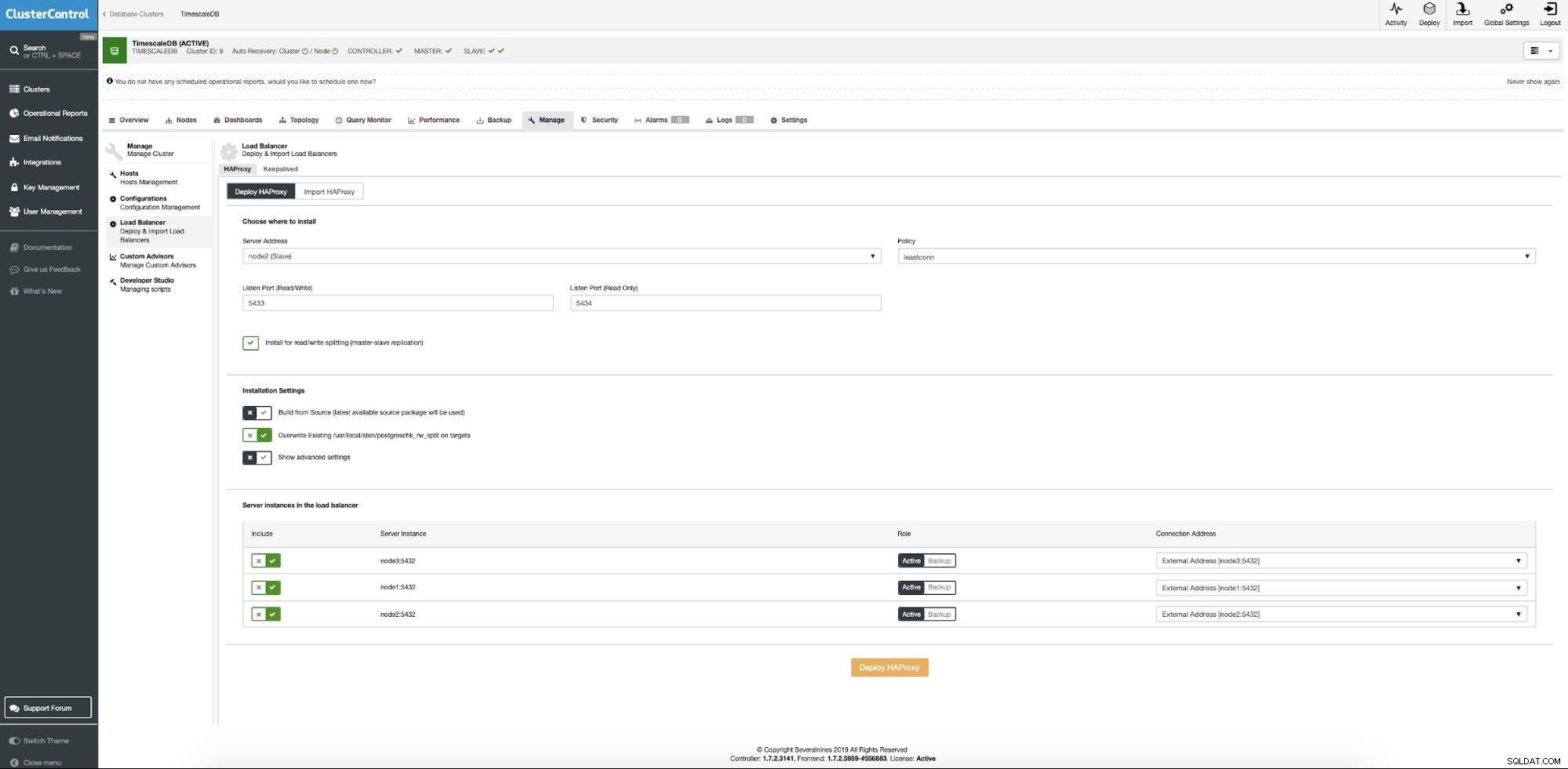
Wanneer alles is ingesteld, drukt u op de knop Implementeren. Na een paar minuten zouden we onze clusterconfiguratie gereed moeten hebben. ClusterControl zorgt voor alle vereisten en configuraties om load balancer te implementeren.
Na een succesvolle implementatie kunnen we de topologie van ons nieuwe cluster zien; met load balancing en extra leesknooppunten. Met meer knooppunten aan boord, schakelt ClusterControl automatisch automatisch herstel in. Op deze manier start de failover-operatie vanzelf wanneer de master-node uitvalt.
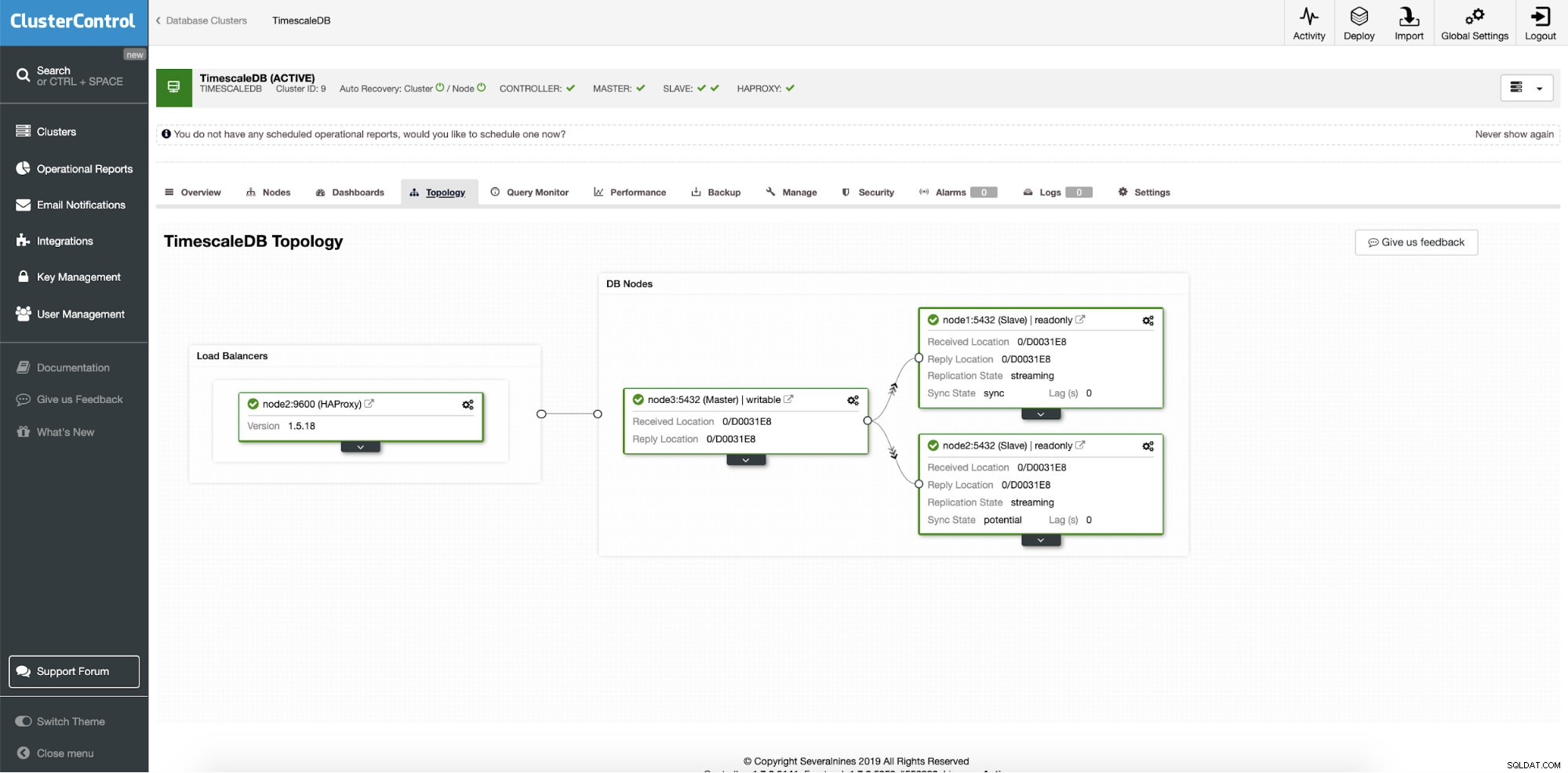 ClusterControl:definitieve topologie
ClusterControl:definitieve topologie Conclusie
TimescaleDB is een open-source database die is uitgevonden om SQL schaalbaar te maken voor tijdreeksgegevens. Het hebben van een geautomatiseerde manier om hun cluster uit te breiden is een sleutel tot het bereiken van prestaties en efficiëntie. Zoals we hierboven hebben gezien, kunt u TimescaleDB nu gemakkelijk schalen door ClusterControl te gebruiken.