Tegenwoordig is replicatie een gegeven in een omgeving met hoge beschikbaarheid en fouttolerantie voor vrijwel elke databasetechnologie die u gebruikt. Het is een onderwerp dat we keer op keer hebben gezien, maar dat nooit oud wordt.
Als u TimescaleDB gebruikt, is streamingreplicatie het meest voorkomende type replicatie, maar hoe werkt het?
In deze blog gaan we enkele concepten met betrekking tot replicatie bespreken en richten we ons op streamingreplicatie voor TimescaleDB, een functionaliteit die is overgenomen van de onderliggende PostgreSQL-engine. Daarna zullen we zien hoe ClusterControl ons kan helpen om het te configureren.
Streamingreplicatie is dus gebaseerd op het verzenden van de WAL-records en het toepassen ervan op de standby-server. Laten we dus eerst eens kijken wat WAL is.
WAL
Write Ahead Log (WAL) is een standaardmethode om de gegevensintegriteit te waarborgen en wordt standaard automatisch ingeschakeld.
De WAL's zijn de REDO-logboeken in TimescaleDB. Maar wat zijn de REDO-logboeken?
REDO logs bevatten alle wijzigingen die in de database zijn aangebracht en worden gebruikt door replicatie, recovery, online backup en point in time recovery (PITR). Alle wijzigingen die niet zijn toegepast op de gegevenspagina's kunnen opnieuw worden gedaan vanuit de REDO-logboeken.
Het gebruik van WAL resulteert in een aanzienlijk verminderd aantal schijfschrijfbewerkingen, omdat alleen het logbestand naar schijf hoeft te worden gewist om te garanderen dat een transactie wordt doorgevoerd, in plaats van elk gegevensbestand dat door de transactie wordt gewijzigd.
Een WAL-record zal beetje bij beetje de wijzigingen in de gegevens specificeren. Elk WAL-record wordt toegevoegd aan een WAL-bestand. De invoegpositie is een Log Sequence Number (LSN) dat een byte-offset in de logs is en met elke nieuwe record toeneemt.
De WAL's worden opgeslagen in de map pg_wal, onder de gegevensmap. Deze bestanden hebben een standaardgrootte van 16 MB (de grootte kan worden gewijzigd door de --with-wal-segsize configure-optie te wijzigen bij het bouwen van de server). Ze hebben een unieke incrementele naam, in het volgende formaat:"00000001 00000000 00000000".
Het aantal WAL-bestanden in pg_wal hangt af van de waarde die is toegewezen aan de parameters min_wal_size en max_wal_size in het configuratiebestand postgresql.conf.
Een parameter die we moeten instellen bij het configureren van al onze TimescaleDB-installaties is de wal_level. Het bepaalt hoeveel informatie naar de WAL wordt geschreven. De standaardwaarde is minimaal, die alleen de informatie schrijft die nodig is om te herstellen van een crash of onmiddellijke afsluiting. Archive voegt logboekregistratie toe die vereist is voor WAL-archivering; hot_standby voegt verder informatie toe die nodig is om alleen-lezen query's uit te voeren op een standby-server; en tenslotte voegt logisch informatie toe die nodig is om logische decodering te ondersteunen. Deze parameter vereist een herstart, dus het kan moeilijk zijn om wijzigingen aan te brengen in actieve productiedatabases als we dat vergeten zijn.
Streaming-replicatie
Streamingreplicatie is gebaseerd op de verzendmethode voor logbestanden. De WAL-records worden direct van de ene databaseserver naar de andere verplaatst om te worden toegepast. We kunnen zeggen dat het een continue PITR is.
Deze overdracht wordt op twee verschillende manieren uitgevoerd, door WAL-records één bestand (WAL-segment) per keer over te dragen (bestandsgebaseerde verzending van logbestanden) en door WAL-records (een WAL-bestand is samengesteld uit WAL-records) on-the-fly (recordgebaseerd log shipping), tussen een master-server en een of meerdere slave-servers, zonder te wachten tot het WAL-bestand is gevuld.
In de praktijk zal een proces met de naam WAL-ontvanger, dat draait op de slave-server, verbinding maken met de master-server via een TCP/IP-verbinding. In de masterserver bestaat een ander proces, genaamd WAL-afzender, en is verantwoordelijk voor het verzenden van de WAL-registers naar de slave-server wanneer ze plaatsvinden.
Streamingreplicatie kan als volgt worden weergegeven:
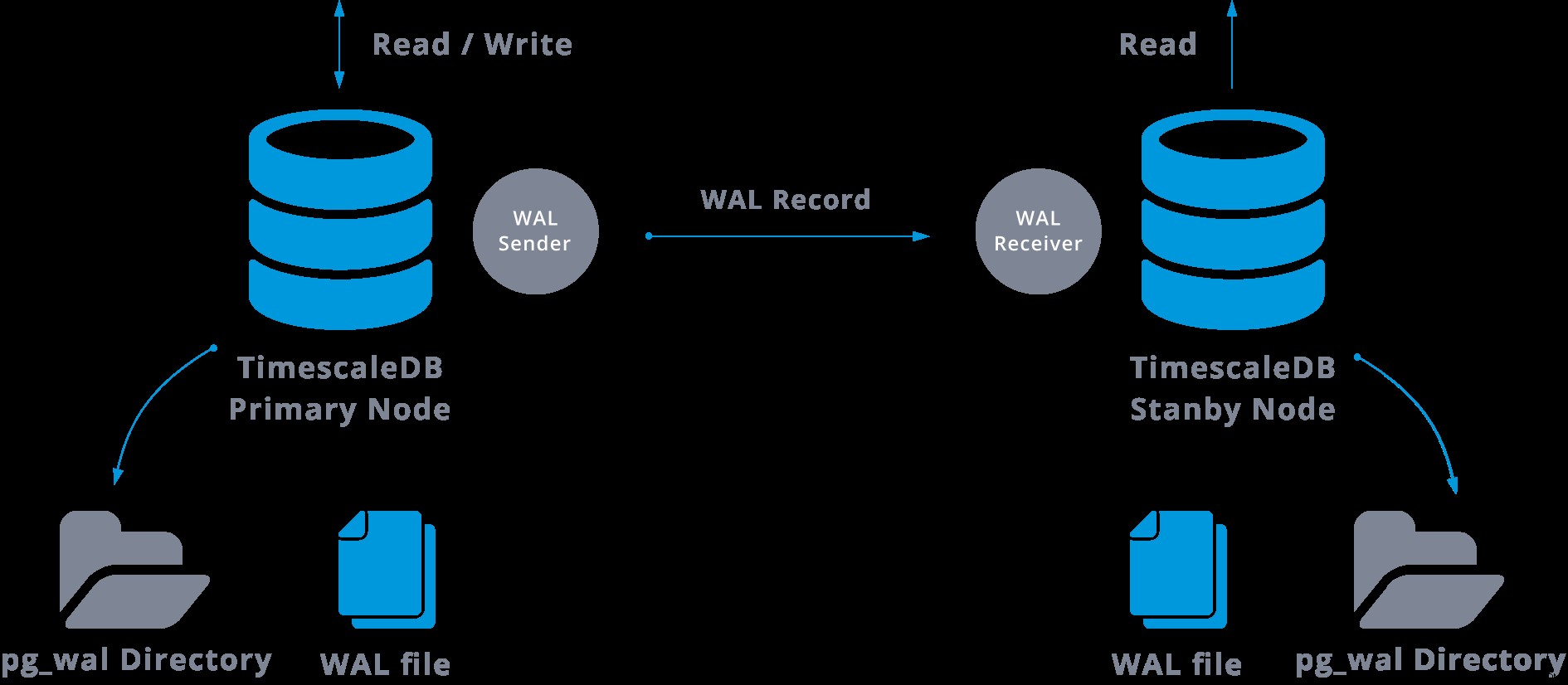
Door naar het bovenstaande diagram te kijken, kunnen we denken, wat gebeurt er als de communicatie tussen de WAL-zender en de WAL-ontvanger mislukt?
Bij het configureren van streamingreplicatie hebben we de optie om WAL-archivering in te schakelen.
Deze stap is eigenlijk niet verplicht, maar is uiterst belangrijk voor een robuuste replicatie-installatie, omdat het noodzakelijk is om te voorkomen dat de hoofdserver oude WAL-bestanden recycleert die nog niet op de slave zijn toegepast. Als dit gebeurt, moeten we de replica helemaal opnieuw maken.
Bij het configureren van replicatie met continue archivering, beginnen we met een back-up en om de synchronisatiestatus met de master te bereiken, moeten we alle wijzigingen toepassen die in de WAL worden gehost en die na de back-up zijn gebeurd. Tijdens dit proces herstelt de standby eerst alle beschikbare WAL op de archieflocatie (gedaan door restore_command aan te roepen). De restore_command zal mislukken wanneer we het laatst gearchiveerde WAL-record bereiken, dus daarna gaat de standby in de pg_wal-directory kijken om te zien of de wijziging daar bestaat (dit is eigenlijk gemaakt om gegevensverlies te voorkomen wanneer de hoofdservers crashen en sommige wijzigingen die al naar de replica zijn verplaatst en daar zijn toegepast, zijn nog niet gearchiveerd).
Als dat niet lukt en het gevraagde record bestaat daar niet, dan zal het gaan communiceren met de master via streamingreplicatie.
Wanneer streaming-replicatie mislukt, gaat het terug naar stap 1 en worden de records uit het archief opnieuw hersteld. Deze lus van ophalen uit het archief, pg_wal, en via streaming-replicatie gaat door totdat de server wordt gestopt of een failover wordt geactiveerd door een triggerbestand.
Dit is een diagram van een dergelijke configuratie:
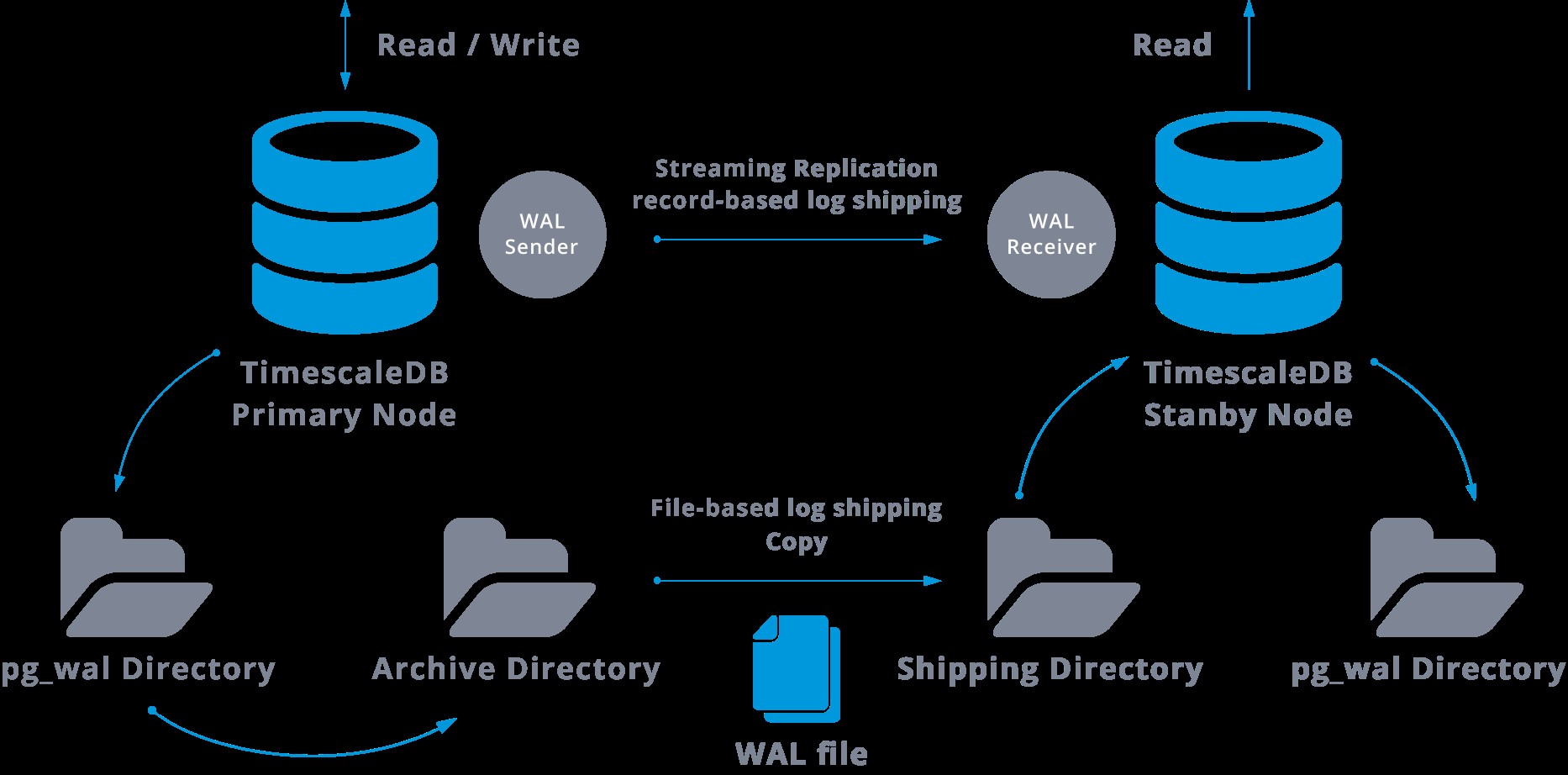
Streamingreplicatie is standaard asynchroon, dus op een bepaald moment kunnen we enkele transacties hebben die in de master kunnen worden vastgelegd en nog niet naar de standby-server kunnen worden gerepliceerd. Dit impliceert mogelijk gegevensverlies.
Er wordt echter verondersteld dat deze vertraging tussen de vastlegging en de impact van de wijzigingen in de replica erg klein is (enkele milliseconden), in de veronderstelling natuurlijk dat de replicaserver krachtig genoeg is om de belasting bij te houden.
Voor de gevallen waarin zelfs het risico van een klein gegevensverlies niet acceptabel is, kunnen we de synchrone replicatiefunctie gebruiken.
Bij synchrone replicatie wacht elke vastlegging van een schrijftransactie totdat de bevestiging is ontvangen dat de vastlegging is geschreven naar het vooruitschrijflogboek op schijf van zowel de primaire als de standby-server.
Deze methode minimaliseert de kans op gegevensverlies, want om dat te laten gebeuren, moeten zowel de master als de standby tegelijkertijd uitvallen.
Het voor de hand liggende nadeel van deze configuratie is dat de responstijd voor elke schrijftransactie toeneemt, omdat we moeten wachten tot alle partijen hebben gereageerd. Dus de tijd voor een commit is minimaal de heen- en terugreis tussen de master en de replica. Alleen-lezen transacties worden hierdoor niet beïnvloed.
Om synchrone replicatie in te stellen, moeten we voor elk van de standby-servers een applicatienaam specificeren in de primary_conninfo van het recovery.conf-bestand:primary_conninfo ='...aplication_name=slaveX' .
We moeten ook de lijst specificeren van de standby-servers die zullen deelnemen aan de synchrone replicatie:synchronous_standby_name ='slaveX,slaveY'.
We kunnen een of meerdere synchrone servers instellen, en deze parameter specificeert ook welke methode (EERSTE en WELKE) synchrone standbys moet kiezen uit de vermelde.
Om TimescaleDB te implementeren met streaming-replicatie-instellingen (synchroon of asynchroon), kunnen we ClusterControl gebruiken, zoals we hier kunnen zien.
Nadat we onze replicatie hebben geconfigureerd en deze actief is, hebben we enkele extra functies nodig voor monitoring en back-upbeheer. ClusterControl stelt ons in staat om back-ups/retentie van ons TimescaleDB-cluster vanaf dezelfde plaats te bewaken en te beheren zonder enige externe tool.
Hoe u streamingreplicatie op TimescaleDB configureert
Het instellen van streamingreplicatie is een taak waarvoor enkele stappen grondig moeten worden gevolgd. Als je het handmatig wilt configureren, kun je onze blog over dit onderwerp volgen.
U kunt echter uw huidige TimescaleDB op ClusterControl implementeren of importeren en vervolgens kunt u met een paar klikken streamingreplicatie configureren. Laten we eens kijken hoe we het kunnen doen.
Voor deze taak gaan we ervan uit dat uw TimescaleDB-cluster wordt beheerd door ClusterControl. Ga naar ClusterControl -> Cluster selecteren -> Clusteracties -> Replicatieslave toevoegen.
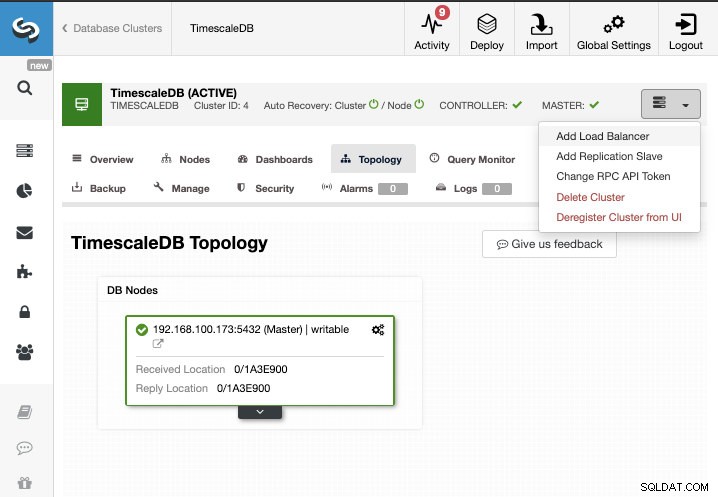
We kunnen een nieuwe replicatieslave maken (stand-by) of we kunnen een bestaande importeren. In dit geval maken we een nieuwe.
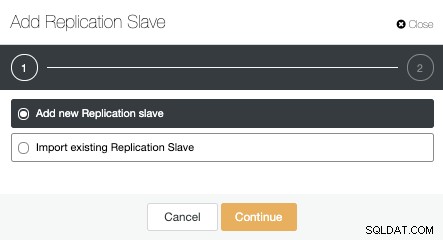
Nu moeten we het hoofdknooppunt selecteren, het IP-adres of de hostnaam voor de nieuwe standby-server en de databasepoort toevoegen. We kunnen ook specificeren of we willen dat ClusterControl de software installeert en of we synchrone of asynchrone streamingreplicatie willen configureren.
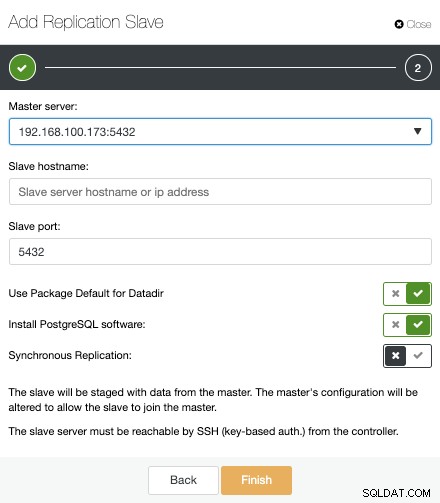
Dat is alles. We hoeven alleen maar te wachten tot ClusterControl de klus heeft geklaard. We kunnen de status volgen vanuit het gedeelte Activiteit.
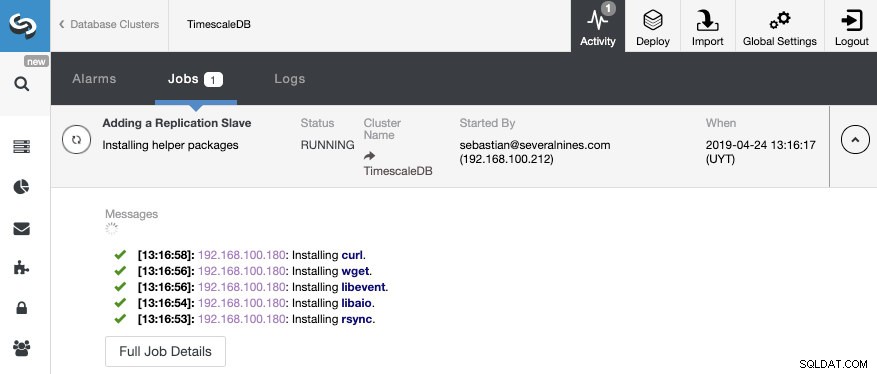
Nadat de taak is voltooid, moeten we de streamingreplicatie hebben geconfigureerd en kunnen we de nieuwe topologie controleren in het gedeelte ClusterControl Topologieweergave.
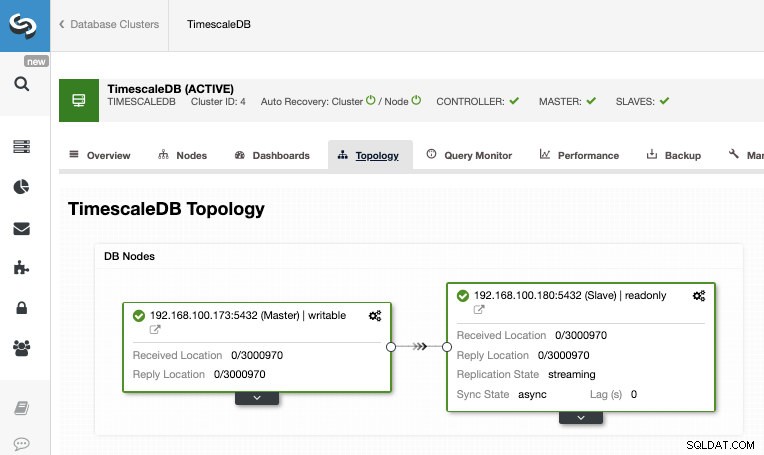
Door ClusterControl te gebruiken, kunt u ook verschillende beheertaken op uw TimescaleDB uitvoeren, zoals back-up, monitor en waarschuwing, automatische failover, nodes toevoegen, load balancers toevoegen en nog veel meer.
Failover
Zoals we konden zien, gebruikt TimescaleDB een stroom van write-ahead log (WAL)-records om de standby-databases gesynchroniseerd te houden. Als de hoofdserver uitvalt, bevat de stand-by bijna alle gegevens van de hoofdserver en kan snel de nieuwe hoofddatabaseserver worden gemaakt. Dit kan synchroon of asynchroon zijn en kan alleen voor de hele databaseserver.
Om een hoge beschikbaarheid effectief te garanderen, is het niet voldoende om een master-standby-architectuur te hebben. We moeten ook een of andere automatische vorm van failover inschakelen, dus als er iets mislukt, kunnen we de kleinst mogelijke vertraging hebben bij het hervatten van de normale functionaliteit.
TimescaleDB bevat geen automatisch failover-mechanisme om fouten in de masterdatabase te identificeren en de slave op de hoogte te stellen om eigenaar te worden, dus dat vereist wat werk aan de kant van de DBA. Je hebt ook maar één server die werkt, dus de master-standby-architectuur moet opnieuw worden gemaakt, zodat we teruggaan naar dezelfde normale situatie die we hadden vóór het probleem.
ClusterControl bevat een automatische failover-functie voor TimescaleDB om de gemiddelde reparatietijd (MTTR) in uw omgeving met hoge beschikbaarheid te verbeteren. In geval van een storing zal ClusterControl de meest geavanceerde slave tot master promoveren en de resterende slave(s) opnieuw configureren om verbinding te maken met de nieuwe master. HAProxy kan ook automatisch worden ingezet om applicaties een enkel database-eindpunt aan te bieden, zodat ze niet worden beïnvloed door een wijziging van de masterserver.
Beperkingen
Gerelateerde bronnen ClusterControl voor TimescaleDB Hoe u TimescaleDB eenvoudig kunt implementeren PostgreSQL Streaming Replication - a Deep DiveWe hebben enkele bekende beperkingen bij het gebruik van streamingreplicatie:
- We kunnen niet repliceren naar een andere versie of architectuur
- We kunnen niets veranderen op de standby-server
- We hebben niet veel details over wat we kunnen repliceren
Om deze beperkingen te omzeilen, hebben we dus de functie voor logische replicatie. Als u meer wilt weten over dit replicatietype, kunt u de volgende blog raadplegen.
Conclusie
Een master-standby-topologie heeft veel verschillende toepassingen, zoals analyse, back-up, hoge beschikbaarheid, failover. In ieder geval is het noodzakelijk om te begrijpen hoe de streamingreplicatie werkt op TimescaleDB. Het is ook handig om een systeem te hebben om het hele cluster te beheren en om u de mogelijkheid te geven om deze topologie op een gemakkelijke manier te creëren. In deze blog hebben we gezien hoe we dit kunnen bereiken door ClusterControl te gebruiken, en hebben we enkele basisconcepten over streamingreplicatie besproken.