Tijdreeksdatabases, zoals de naam al doet vermoeden, zijn ontworpen om gegevens op te slaan die met de tijd veranderen. Dit kunnen alle soorten gegevens zijn die in de loop van de tijd zijn verzameld. Het kunnen statistieken zijn die van sommige systemen zijn verzameld, en eigenlijk zijn alle trendingsystemen voorbeelden van tijdreeksgegevens.
We hebben verschillende soorten tijdreeksdatabases, welke moeten we gebruiken?
In deze blog zullen we zien wat de belangrijkste verschillen zijn tussen twee van de belangrijkste opties, TimescaleDB en InfluxDB.
InfluxDB
InfluxDB is gemaakt door InfluxData. Het is een aangepaste, open-source NoSQL-tijdreeksdatabase die is geschreven in Go. De datastore biedt een SQL-achtige taal om de gegevens op te vragen, genaamd InfluxQL, waardoor het voor de ontwikkelaars gemakkelijk is om in hun applicaties te integreren. Het heeft ook een nieuwe aangepaste zoektaal genaamd Flux, deze taal kan sommige taken gemakkelijker maken, maar er is altijd een leercurve bij het adopteren van een aangepaste zoektaal.
Dit is een voorbeeld van een Flux-query:
from(db:"testing")
|> range(start:-1h)
|> filter(fn: (r) => r._measurement == "cpu")
|> exponentialMovingAverage()In deze database heeft elke meting een tijdstempel en een bijbehorende set tags en een set velden. Het veld vertegenwoordigt de werkelijke meetwaarden, terwijl de tag de metadata vertegenwoordigt om de metingen te beschrijven. De veldgegevenstypen zijn beperkt tot floats, ints, strings en booleans en kunnen niet worden gewijzigd zonder de gegevens te herschrijven. De tagwaarden zijn geïndexeerd. Ze worden weergegeven als tekenreeksen en kunnen niet worden bijgewerkt.
InfluxDB is vrij eenvoudig om te beginnen, omdat u zich geen zorgen hoeft te maken over het maken van schema's of indexen. Het is echter vrij rigide en beperkt, zonder de mogelijkheid om extra indexen, indexen op doorlopende velden te maken, metadata achteraf bij te werken, gegevensvalidatie af te dwingen, enz.
Het is niet schemaloos. Er is een onderliggend schema dat automatisch wordt gemaakt op basis van de invoergegevens.
InfluxDB moet vanaf het begin verschillende tools implementeren voor fouttolerantie, zoals replicatie, hoge beschikbaarheid en back-up/herstel, en het is verantwoordelijk voor de betrouwbaarheid op de schijf. We zijn beperkt tot het gebruik van deze tools en veel van deze functies, zoals HA, zijn alleen beschikbaar in de enterprise-versie.
De InfluxDB-back-uptool kan een volledige of incrementele back-up uitvoeren en kan worden gebruikt voor herstel op een bepaald tijdstip.
InfluxDB biedt ook aanzienlijk betere compressie op schijf dan PostgreSQL en TimescaleDB.
TijdschaalDB
TimescaleDB is een open-source tijdreeksdatabase die is geoptimaliseerd voor snelle opname en complexe query's die volledige SQL ondersteunt. Het is gebaseerd op PostgreSQL en biedt het beste van NoSQL en relationele werelden voor tijdreeksgegevens.
Dit is een voorbeeld van een TimescaleDB-query:
SELECT time,
exponential_moving_average(value, 0.5) OVER (ORDER BY time)
FROM testing
WHERE measurement = cpu and time > now() - '1 hour';TimescaleDB, als een PostgreSQL-extensie, is een relationele database. Dit maakt het mogelijk om een korte leercurve te hebben voor nieuwe gebruikers en om tools zoals pg_dump of pg_backup voor back-up te erven, en tools met hoge beschikbaarheid, wat een voordeel is ten opzichte van andere tijdreeksdatabases. Het ondersteunt ook streaming-replicatie als de primaire replicatiemethode, die kan worden gebruikt in een configuratie met hoge beschikbaarheid. Op het gebied van failover en back-ups kunt u dit proces automatiseren door gebruik te maken van een extern systeem zoals ClusterControl.
In TimescaleDB wordt elke tijdreeksmeting vastgelegd in een eigen rij, met een tijdveld gevolgd door een willekeurig aantal andere velden, die kunnen bestaan uit floats, ints, strings, booleans, arrays, JSON-blobs, geospatiale dimensies, datum/tijd/ tijdstempels, valuta's, binaire gegevens en meer.
U kunt indexen maken op elk veld (standaardindexen) of meerdere velden (samengestelde indexen), of op uitdrukkingen zoals functies, of zelfs een index beperken tot een subset van rijen (gedeeltelijke index). Elk van deze velden kan worden gebruikt als een externe sleutel voor secundaire tabellen, die vervolgens aanvullende metadata kunnen opslaan.
Op deze manier moet je een schema kiezen en beslissen welke indexen je nodig hebt voor je systeem.
Prestaties
Als we het hebben over prestaties, kunnen we de geweldige TimescaleDB-vergelijkingsblog bekijken. Daar heb je een gedetailleerde prestatievergelijking tussen beide databases met grafieken en statistieken. Laten we enkele van de belangrijkste informatie van deze blog bekijken.
Invoegingen
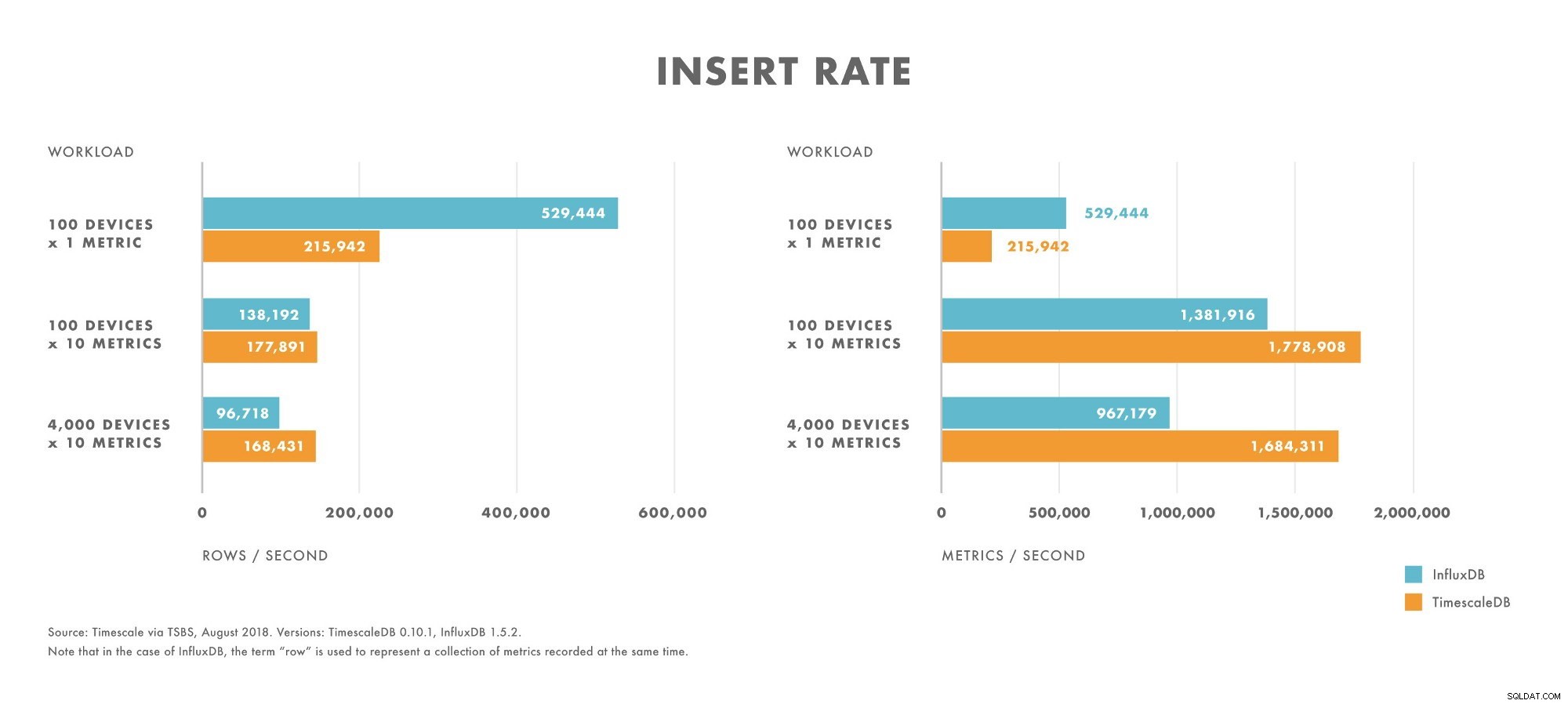
- Voor workloads met een zeer lage kardinaliteit (bijvoorbeeld 100 apparaten) presteert InfluxDB beter dan TimescaleDB.
- Naarmate de kardinaliteit toeneemt, nemen de prestaties van InfluxDB-inserts sneller af dan op TimescaleDB.
- Voor workloads met een matige tot hoge kardinaliteit (bijvoorbeeld 100 apparaten die 10 statistieken verzenden), presteert TimescaleDB beter dan InfluxDB.

Leeslatentie
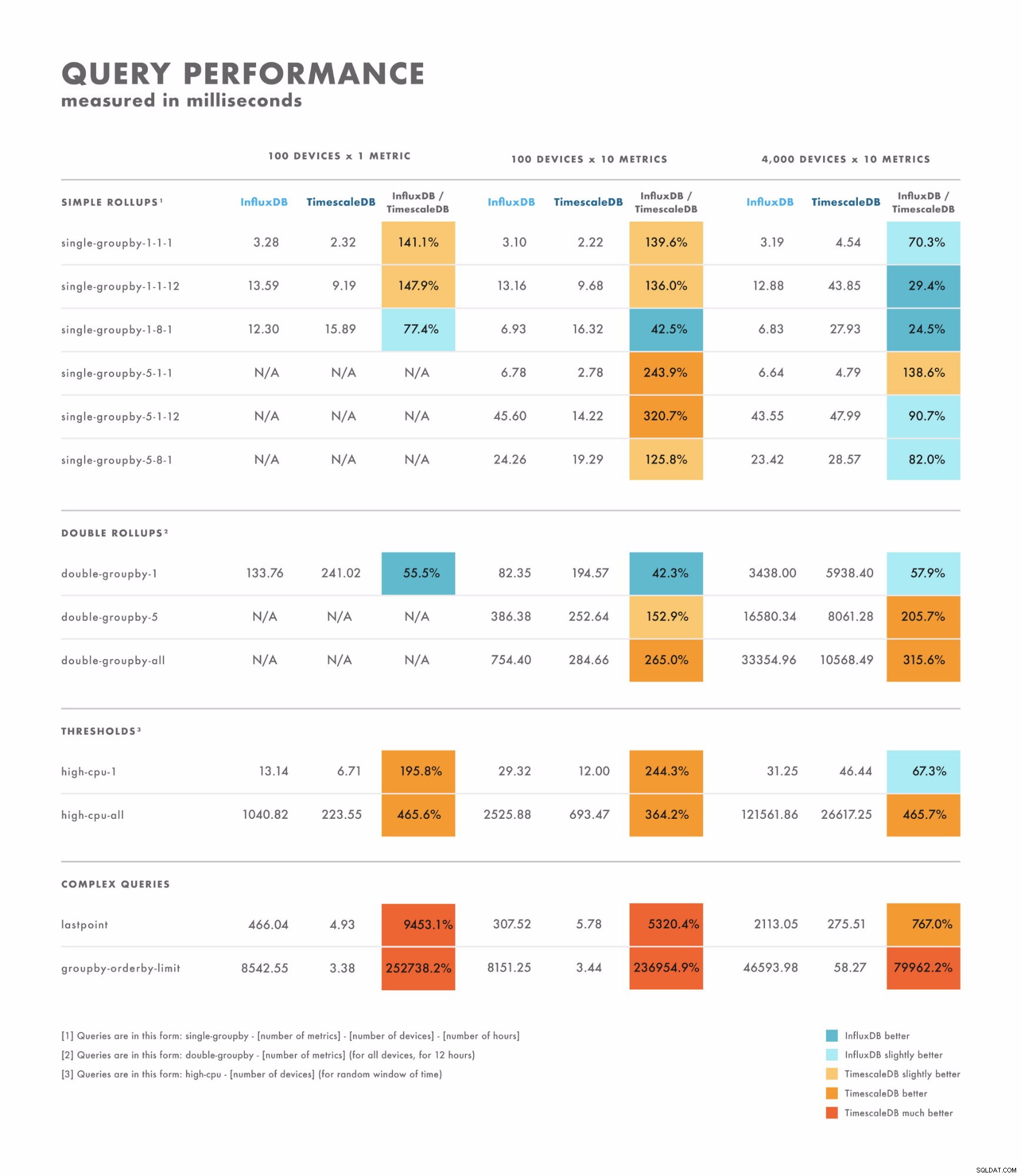
- Voor eenvoudige zoekopdrachten variëren de resultaten nogal:bij sommige is de ene database duidelijk beter dan de andere, terwijl andere afhankelijk zijn van de kardinaliteit van uw dataset. Het verschil ligt hier vaak in het bereik van enkele milliseconden tot dubbele cijfers.
- Voor complexe query's presteert TimescaleDB aanzienlijk beter dan InfluxDB en ondersteunt het een breder scala aan querytypen. Het verschil ligt hier vaak in het bereik van seconden tot tientallen seconden.
- Met dat in gedachten is de beste manier om goed te testen, te benchmarken met behulp van de zoekopdrachten die u wilt uitvoeren.
Stabiliteitsproblemen
- InfluxDB heeft stabiliteits- en prestatieproblemen bij hoge (100K+) kardinaliteiten.
Conclusie
Als uw gegevens passen in het InfluxDB-gegevensmodel en u verwacht niet dat dit in de toekomst zal veranderen, moet u overwegen om InfluxDB te gebruiken, aangezien dit model gemakkelijker is om mee aan de slag te gaan en zoals de meeste databases die een kolomgeoriënteerde benadering gebruiken, biedt betere compressie op schijf dan PostgreSQL en TimescaleDB.
Het relationele model is echter veelzijdiger en biedt meer functionaliteit, flexibiliteit en controle dan het InfluxDB-model. Dit is vooral belangrijk naarmate uw toepassing evolueert. En bij het plannen van uw systeem moet u rekening houden met zowel de huidige als toekomstige behoeften.
In deze blog konden we een korte vergelijking zien tussen TimescaleDB en InfluxDB, en we zouden kunnen zeggen dat TimescaleDB als een PostgreSQL-extensie er behoorlijk volwassen en rijk aan functies uitziet, omdat het veel van PostgreSQL erft. Maar je kunt je eigen beslissing nemen op basis van de voor- en nadelen die eerder in deze blog zijn genoemd, en ervoor zorgen dat je je eigen werklast benchmarkt. Veel succes in deze nieuwe tijdreeksdatabasewereld!