Tegenwoordig is Docker de meest gebruikte tool voor het maken, implementeren en uitvoeren van applicaties met behulp van containers. Het stelt ons in staat om een applicatie te verpakken met alle onderdelen die het nodig heeft, zoals bibliotheken en andere afhankelijkheden, en het allemaal als één pakket te verzenden. Het kan worden beschouwd als een virtuele machine, maar in plaats van een heel virtueel besturingssysteem te creëren, stelt Docker applicaties in staat om dezelfde Linux-kernel te gebruiken als het systeem waarop ze draaien en vereist alleen dat applicaties worden geleverd met dingen die nog niet draaien op de hostcomputer. Dit geeft een aanzienlijke prestatieverbetering en verkleint de applicatie.
In het geval van Docker-afbeeldingen worden ze geleverd met een vooraf gedefinieerde OS-versie en worden de pakketten geïnstalleerd op een manier die is bepaald door de persoon die de afbeelding heeft gemaakt. Het is mogelijk dat u een ander besturingssysteem wilt gebruiken of dat u de pakketten op een andere manier wilt installeren. In deze gevallen moet u een schone OS Docker Image gebruiken en de software helemaal opnieuw installeren.
Replicatie is een veelvoorkomende functie in een database-omgeving, dus nadat u de TimescaleDB Docker-afbeeldingen hebt geïmplementeerd, moet u, als u een replicatie-installatie wilt configureren, dit handmatig doen vanuit de container, met behulp van een Docker-bestand of zelfs een script. Deze taak kan ingewikkeld zijn als je geen kennis van Docker hebt.
In deze blog zullen we zien hoe we TimescaleDB kunnen implementeren via Docker met behulp van een TimescaleDB Docker-image, en dan zullen we zien hoe we het helemaal opnieuw kunnen installeren met behulp van een CentOS Docker-image en ClusterControl.
TimescaleDB implementeren met een Docker-image
Laten we eerst eens kijken hoe u TimescaleDB implementeert met behulp van een Docker-image die beschikbaar is op Docker Hub.
$ docker search timescaledb
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
timescale/timescaledb An open-source time-series database optimize… 52We nemen het eerste resultaat. Dus we moeten deze afbeelding trekken:
$ docker pull timescale/timescaledbEn voer de nodecontainers uit die een lokale poort toewijzen aan de databasepoort in de container:
$ docker run -d --name timescaledb1 -p 7551:5432 timescale/timescaledb
$ docker run -d --name timescaledb2 -p 7552:5432 timescale/timescaledbNadat u deze opdrachten hebt uitgevoerd, zou u deze Docker-omgeving moeten hebben gemaakt:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6d3bfc75fe39 timescale/timescaledb "docker-entrypoint.s…" 15 minutes ago Up 15 minutes 0.0.0.0:7552->5432/tcp timescaledb2
748d5167041f timescale/timescaledb "docker-entrypoint.s…" 16 minutes ago Up 16 minutes 0.0.0.0:7551->5432/tcp timescaledb1Nu hebt u toegang tot elk knooppunt met de volgende opdrachten:
$ docker exec -ti [db-container] bash
$ su postgres
$ psql
psql (9.6.13)
Type "help" for help.
postgres=#Zoals u kunt zien, bevat deze Docker-afbeelding standaard een TimescaleDB 9.6-versie en is deze geïnstalleerd op Alpine Linux v3.9. U kunt een andere TimescaleDB-versie gebruiken door de tag te wijzigen:
$ docker pull timescale/timescaledb:latest-pg11Vervolgens kunt u een databasegebruiker maken, de configuratie wijzigen volgens uw vereisten of de replicatie tussen de knooppunten handmatig configureren.
TimescaleDB implementeren met ClusterControl
Laten we nu eens kijken hoe u TimescaleDB implementeert met Docker met behulp van een CentOS Docker Image (centos) en een ClusterControl Docker Image (meerdere negens/clustercontrol).
Eerst zullen we een ClusterControl Docker-container implementeren met de nieuwste versie, dus we moeten de Docker Image met verschillende negens/clustercontrol ophalen.
$ docker pull severalnines/clustercontrolVervolgens zullen we de ClusterControl-container uitvoeren en de poort 5000 publiceren om er toegang toe te krijgen.
$ docker run -d --name clustercontrol -p 5000:80 severalnines/clustercontrolNu kunnen we de gebruikersinterface van ClusterControl openen op https://[Docker_Host]:5000/clustercontrol en een standaard admin-gebruiker en -wachtwoord maken.
De CentOS Official Docker Image wordt geleverd zonder SSH-service, dus we zullen het installeren en de verbinding vanaf het ClusterControl-knooppunt toestaan zonder wachtwoord met behulp van een SSH-sleutel.
$ docker search centos
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
centos The official build of CentOS. 5378 [OK]Dus we trekken de CentOS Official Docker Image.
$ docker pull centosEn dan zullen we twee knooppuntcontainers uitvoeren, timescale1 en timescale2, gekoppeld aan ClusterControl en we zullen een lokale poort toewijzen om verbinding te maken met de database (optioneel).
$ docker run -dt --privileged --name timescale1 -p 8551:5432 --link clustercontrol:clustercontrol centos /usr/sbin/init
$ docker run -dt --privileged --name timescale2 -p 8552:5432 --link clustercontrol:clustercontrol centos /usr/sbin/initOmdat we de SSH-service moeten installeren en configureren, moeten we de container uitvoeren met privileged en /usr/sbin/init-parameters om de service in de container te kunnen beheren.
Nadat we deze commando's hebben uitgevoerd, zouden we deze Docker-omgeving moeten hebben gemaakt:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
230686d8126e centos "/usr/sbin/init" 4 seconds ago Up 3 seconds 0.0.0.0:8552->5432/tcp timescale2
c0e7b245f7fe centos "/usr/sbin/init" 23 seconds ago Up 22 seconds 0.0.0.0:8551->5432/tcp timescale1
7eadb6bb72fb severalnines/clustercontrol "/entrypoint.sh" 2 weeks ago Up About an hour (healthy) 22/tcp, 443/tcp, 3306/tcp, 9500-9501/tcp, 9510-9511/tcp, 9999/tcp, 0.0.0.0:5000->80/tcp clustercontrolWe hebben toegang tot elk knooppunt met het volgende commando:
$ docker exec -ti [db-container] bashZoals we eerder vermeldden, moeten we de SSH-service installeren, dus laten we deze installeren, de root-toegang toestaan en het root-wachtwoord instellen voor elke databasecontainer:
$ docker exec -ti [db-container] yum update -y
$ docker exec -ti [db-container] yum install -y openssh-server openssh-clients
$ docker exec -it [db-container] sed -i 's|^#PermitRootLogin.*|PermitRootLogin yes|g' /etc/ssh/sshd_config
$ docker exec -it [db-container] systemctl start sshd
$ docker exec -it [db-container] passwdDe laatste stap is het instellen van de wachtwoordloze SSH voor alle databasecontainers. Hiervoor moeten we het IP-adres voor elk databaseknooppunt weten. Om dit te weten, kunnen we de volgende opdracht uitvoeren voor elk knooppunt:
$ docker inspect [db-container] |grep IPAddress
"IPAddress": "172.17.0.5",Koppel vervolgens aan de interactieve ClusterControl-containerconsole:
$ docker exec -it clustercontrol bashEn kopieer de SSH-sleutel naar alle databasecontainers:
$ ssh-copy-id 172.17.0.5Nu we de serverknooppunten in gebruik hebben, moeten we ons databasecluster implementeren. Om het op een makkelijke manier te doen gebruiken we ClusterControl.
Om een implementatie uit te voeren vanuit ClusterControl, opent u de ClusterControl-gebruikersinterface op https://[Docker_Host]:5000/clustercontrol, selecteert u vervolgens de optie "Deploy" en volgt u de instructies die verschijnen.
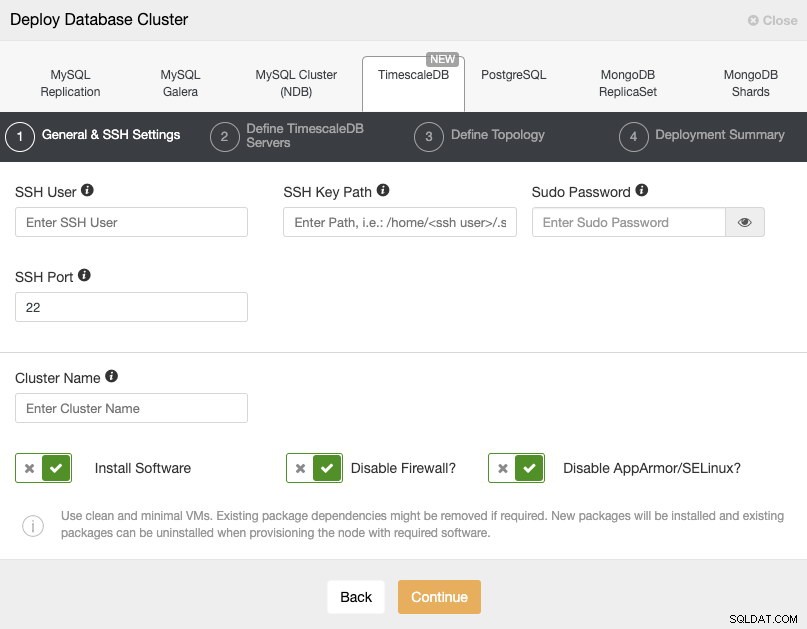
Bij het selecteren van TimescaleDB moeten we Gebruiker, Sleutel of Wachtwoord en poort specificeren om via SSH verbinding te maken met onze servers. We hebben ook een naam nodig voor ons nieuwe cluster en als we willen dat ClusterControl de bijbehorende software en configuraties voor ons installeert.
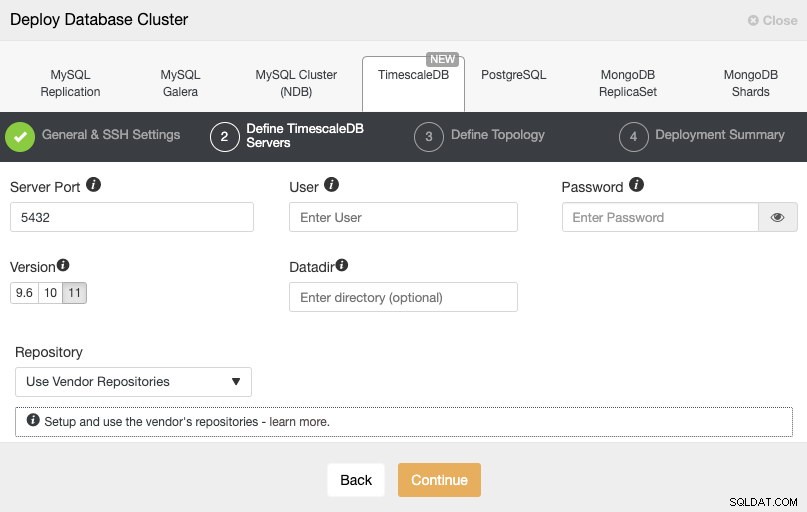
Na het instellen van de SSH-toegangsinformatie, moeten we de databasegebruiker, -versie en datadir (optioneel) definiëren. We kunnen ook specificeren welke repository we moeten gebruiken.
In de volgende stap moeten we onze servers toevoegen aan het cluster dat we gaan maken.
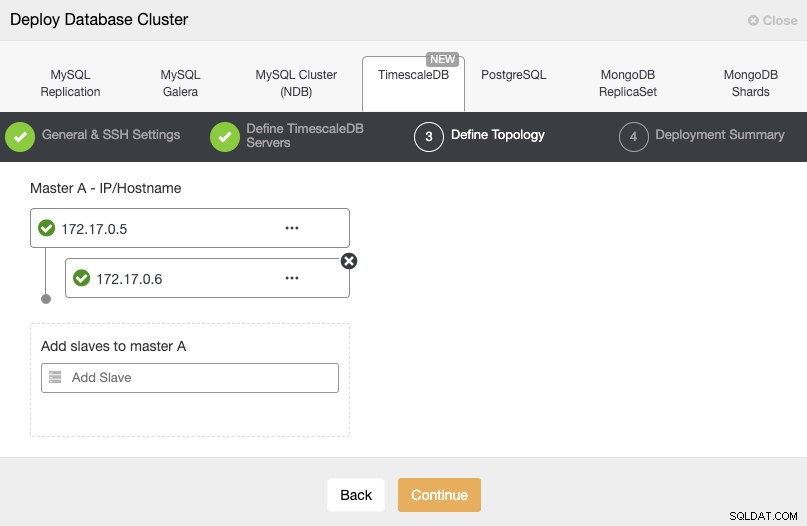
Hier moeten we het IP-adres gebruiken dat we eerder van elke container hebben gekregen.
In de laatste stap kunnen we kiezen of onze replicatie synchroon of asynchroon zal zijn.
We kunnen de status van het maken van ons nieuwe cluster volgen via de ClusterControl-activiteitenmonitor.
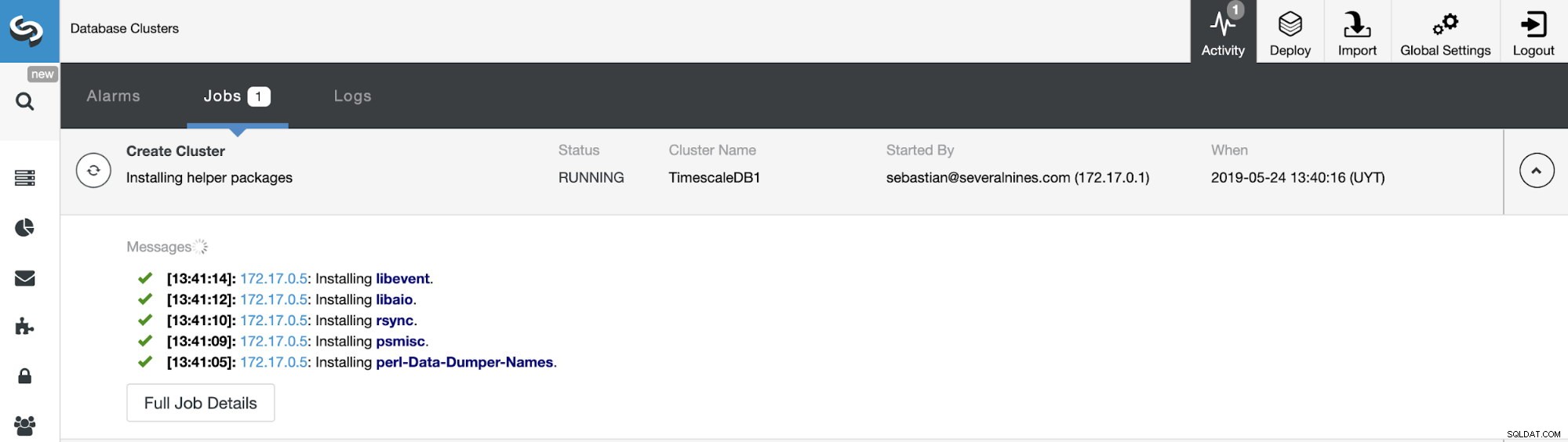
Zodra de taak is voltooid, kunnen we ons cluster zien in het hoofdscherm van ClusterControl.

Houd er rekening mee dat als u meer stand-by-knooppunten wilt toevoegen, u dit kunt doen vanuit de gebruikersinterface van ClusterControl in het menu Clusteracties.
Op dezelfde manier, als uw TimescaleDB-cluster op Docker draait en u wilt dat ClusterControl het beheert om alle functies van dit systeem te kunnen gebruiken, zoals monitoring, back-up, automatische failover en zelfs meer, kunt u eenvoudig de ClusterControl-container in hetzelfde Docker-netwerk als de databasecontainers. De enige vereiste is om ervoor te zorgen dat de doelcontainers SSH-gerelateerde pakketten hebben geïnstalleerd (openssh-server, openssh-clients). Sta vervolgens wachtwoordloze SSH van ClusterControl toe aan de databasecontainers. Als u klaar bent, gebruikt u de functie "Bestaande server/cluster importeren" en moet het cluster worden geïmporteerd in ClusterControl.
Een mogelijk probleem bij het uitvoeren van containers is het IP-adres of de hostnaamtoewijzing. Zonder een orkestratietool zoals Kubernetes kan het IP-adres of de hostnaam anders zijn als u de knooppunten stopt en nieuwe containers maakt voordat u deze opnieuw start. Je hebt een ander IP-adres voor de oude nodes en ClusterControl gaat ervan uit dat alle nodes draaien in een omgeving met een dedicated IP-adres of hostnaam, dus nadat het IP-adres is gewijzigd, moet je het cluster opnieuw importeren in ClusterControl. Er zijn veel tijdelijke oplossingen voor dit probleem. U kunt deze link gebruiken om Kubernetes met StatefulSet te gebruiken, of deze link om containers uit te voeren zonder orkestratietool.
Conclusie
Zoals we konden zien, zou de implementatie van TimescaleDB met Docker eenvoudig moeten zijn als u geen replicatie- of failover-omgeving wilt configureren en als u geen wijzigingen wilt aanbrengen in de OS-versie of de installatie van databasepakketten.
Met ClusterControl kunt u uw TimescaleDB-cluster importeren of implementeren met Docker door de OS-image te gebruiken die u verkiest, en tevens de bewakings- en beheertaken automatiseren, zoals back-up en automatische failover/herstel.