
Veel te vaak zie ik mensen klagen over hoe hun transactielogboek hun harde schijf overnam. Vaak blijkt dat ze een grote wisbewerking uitvoerden, zoals het opschonen of archiveren van gegevens, in één grote transactie.
Ik wilde een aantal tests uitvoeren om de impact, zowel op de duur als op het transactielogboek, te laten zien van het uitvoeren van dezelfde gegevensbewerking in brokken versus een enkele transactie. Ik heb een database gemaakt en deze gevuld met een grote tabel SalesOrderDetailEnlarged ,
Nadat ik de tabel had ingevuld, maakte ik een back-up van de database, maakte een back-up van het logboek en voerde een DBCC SHRINKFILE uit (don't shoot me) zodat de impact op het logbestand kan worden vastgesteld vanaf een baseline (goed wetende dat deze bewerkingen * ervoor zullen zorgen dat het transactielogboek groeit).
Ik heb met opzet een mechanische schijf gebruikt in plaats van een SSD. Hoewel we misschien een meer populaire trend gaan zien om naar SSD over te stappen, is dit nog niet op een voldoende grote schaal gebeurd; in veel gevallen is het nog steeds te duur om dit te doen op grote opslagapparaten.
De testen
Dus vervolgens moest ik bepalen wat ik wilde testen voor de grootste impact. Omdat ik gisteren met een collega in discussie was over het verwijderen van gegevens in brokken, koos ik voor verwijderen. En aangezien de geclusterde index in deze tabel op SalesOrderID staat, , ik wilde dat niet gebruiken - dat zou te gemakkelijk zijn (en zou zeer zelden overeenkomen met de manier waarop verwijderingen in het echte leven worden afgehandeld). Dus besloot ik in plaats daarvan te gaan voor een reeks ProductID waarden, die ervoor zouden zorgen dat ik een groot aantal pagina's zou raken en veel logboekregistratie zou vereisen. Met de volgende zoekopdracht heb ik bepaald welke producten ik moest verwijderen:
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
Dit leverde de volgende resultaten op:
ProductID ProductCount --------- ------------ 870 187520 712 135280 873 134160
Dit zou 456.960 rijen (ongeveer 10% van de tabel) verwijderen, verspreid over veel bestellingen. Dit is geen realistische wijziging in deze context, omdat het zal knoeien met vooraf berekende ordertotalen, en je kunt een product niet echt verwijderen uit een bestelling die al is verzonden. Maar als we een database gebruiken die we allemaal kennen en waar we van houden, is het analoog aan bijvoorbeeld het verwijderen van een gebruiker van een forumsite en ook het verwijderen van al hun berichten - een echt scenario dat ik in het wild heb gezien.
Dus een test zou zijn om de volgende, eenmalige verwijdering uit te voeren:
DELETE dbo.SalesOrderDetailEnlarged WHERE ProductID IN (712, 870, 873);
Ik weet dat dit een enorme scan zal vereisen en een enorme tol zal eisen van het transactielogboek. Dat is een beetje het punt. :-)
Terwijl dat aan de gang was, heb ik een ander script samengesteld dat deze verwijdering in stukjes zal uitvoeren:25.000, 50.000, 75.000 en 100.000 rijen tegelijk. Elke chunk wordt in zijn eigen transactie vastgelegd (zodat als je het script moet stoppen, je dat kunt, en alle voorgaande chunks al zijn vastgelegd, in plaats van opnieuw te moeten beginnen), en zal, afhankelijk van het herstelmodel, worden gevolgd door ofwel een CHECKPOINT of een BACKUP LOG om de voortdurende impact op het transactielogboek te minimaliseren. (Ik zal ook testen zonder deze bewerkingen.) Het ziet er ongeveer zo uit (ik ga me niet druk maken over foutafhandeling en andere aardigheden voor deze test, maar je zou niet zo arrogant moeten zijn):
SET NOCOUNT ON;
DECLARE @r INT;
SET @r = 1;
WHILE @r > 0
BEGIN
BEGIN TRANSACTION;
DELETE TOP (100000) -- this will change
dbo.SalesOrderDetailEnlarged
WHERE ProductID IN (712, 870, 873);
SET @r = @@ROWCOUNT;
COMMIT TRANSACTION;
-- CHECKPOINT; -- if simple
-- BACKUP LOG ... -- if full
END
Natuurlijk zou ik na elke test de originele back-up van de database herstellen WITH REPLACE, RECOVERY , stel het herstelmodel dienovereenkomstig in en voer de volgende test uit.
De resultaten
De uitkomst van de eerste test was niet erg verrassend. Om de verwijdering in een enkele instructie uit te voeren, duurde het 42 seconden in zijn geheel en 43 seconden in eenvoudig. In beide gevallen groeide het logboek tot 579 MB.
De volgende reeks tests had een paar verrassingen voor mij. Een daarvan is dat, hoewel deze chunking-methoden de impact op het logbestand aanzienlijk verminderden, slechts een paar combinaties qua duur in de buurt kwamen en geen enkele was echt sneller. Een andere is dat chunking bij volledig herstel (zonder een logback-up tussen de stappen uit te voeren) over het algemeen beter presteerde dan vergelijkbare bewerkingen bij eenvoudig herstel. Dit zijn de resultaten voor duur en logimpact:
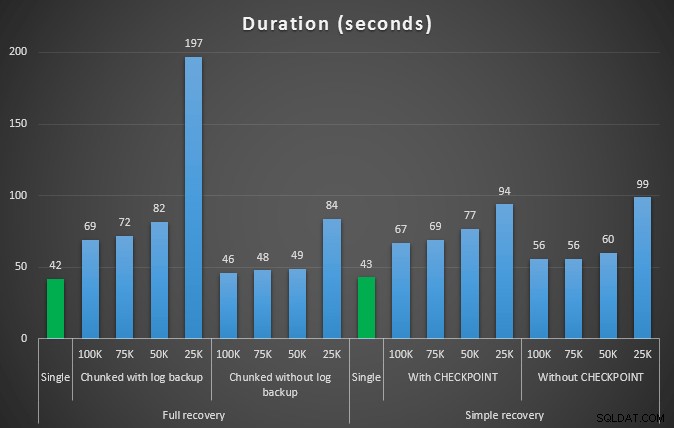
Duur, in seconden, van verschillende verwijderbewerkingen waarbij 457K rijen worden verwijderd
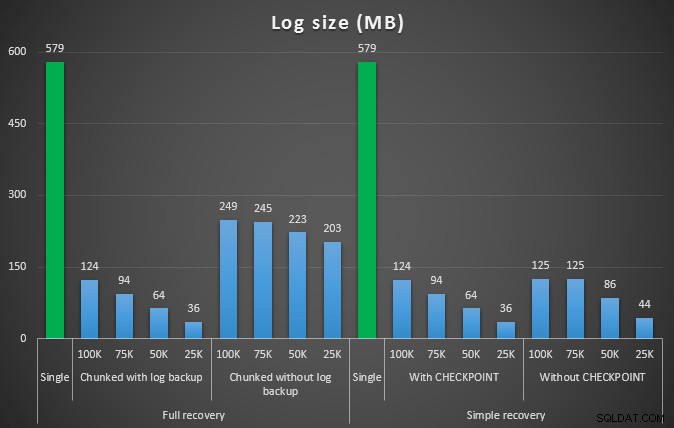
Loggrootte, in MB, na verschillende verwijderbewerkingen waarbij 457K rijen zijn verwijderd
Nogmaals, in het algemeen, terwijl de loggrootte aanzienlijk wordt verminderd, wordt de duur verlengd. U kunt dit type schaal gebruiken om te bepalen of het belangrijker is om de impact op de schijfruimte te verminderen of om de hoeveelheid tijd die eraan wordt besteed te minimaliseren. Voor een kleine treffer in duur (en de meeste van deze processen worden tenslotte op de achtergrond uitgevoerd), kunt u een aanzienlijke besparing hebben (tot 94%, in deze tests) in het gebruik van logruimte.
Merk op dat ik geen van deze tests heb geprobeerd met compressie ingeschakeld (mogelijk een toekomstige test!) deze vreselijke omgeving.
Maar wat als ik meer gegevens heb?
Vervolgens dacht ik dat ik dit op een iets grotere database moest testen. Dus maakte ik een andere database en maakte een nieuwe, grotere kopie van dbo.SalesOrderDetailEnlarged . Ongeveer tien keer groter zelfs. Deze keer in plaats van een primaire sleutel op SalesOrderID, SalesorderDetailID , Ik heb er net een geclusterde index van gemaakt (om duplicaten mogelijk te maken), en heb het op deze manier ingevuld:
SELECT c.*
INTO dbo.SalesOrderDetailReallyReallyEnlarged
FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged AS c
CROSS JOIN
(
SELECT TOP 10 Number FROM master..spt_values
) AS x;
CREATE CLUSTERED INDEX so ON dbo.SalesOrderDetailReallyReallyEnlarged
(SalesOrderID,SalesOrderDetailID);
-- I also made this index non-unique:
CREATE NONCLUSTERED INDEX rg ON dbo.SalesOrderDetailReallyReallyEnlarged(rowguid);
CREATE NONCLUSTERED INDEX p ON dbo.SalesOrderDetailReallyReallyEnlarged(ProductID); Vanwege schijfruimtebeperkingen moest ik voor deze test de VM van mijn laptop verlaten (en koos ik een 40-core box, met 128 GB RAM, die toevallig quasi-inactief was :-)), en nog steeds het was geenszins een snel proces. Het invullen van de tabel en het maken van de indexen duurde ongeveer 24 minuten.
De tabel heeft 48,5 miljoen rijen en neemt 7,9 GB aan schijf in beslag (4,9 GB aan gegevens en 2,9 GB aan index).
Deze keer mijn vraag om een goede set kandidaat ProductID te bepalen waarden om te verwijderen:
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailReallyReallyEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
Leverde de volgende resultaten op:
ProductID ProductCount --------- ------------ 870 1828320 712 1318980 873 1308060
Dus we gaan 4.455.360 rijen verwijderen, iets minder dan 10% van de tabel. Volgens een soortgelijk patroon als bij de bovenstaande test, gaan we alles in één keer verwijderen en vervolgens in stukjes van 500.000, 250.000 en 100.000 rijen.
Resultaten:
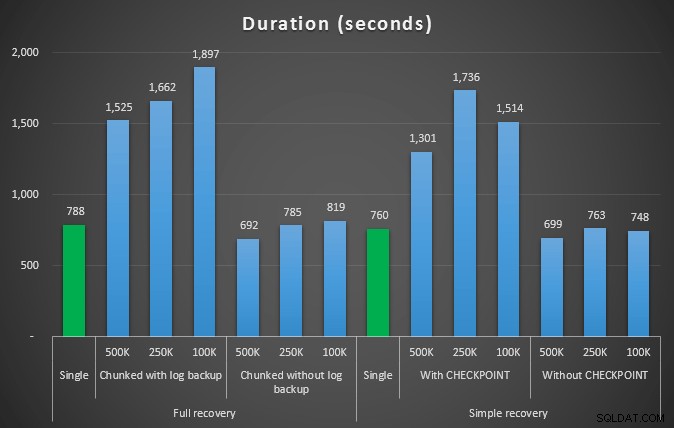 Duur, in seconden, van verschillende verwijderbewerkingen waarbij 4,5 mm rijen worden verwijderd
Duur, in seconden, van verschillende verwijderbewerkingen waarbij 4,5 mm rijen worden verwijderd
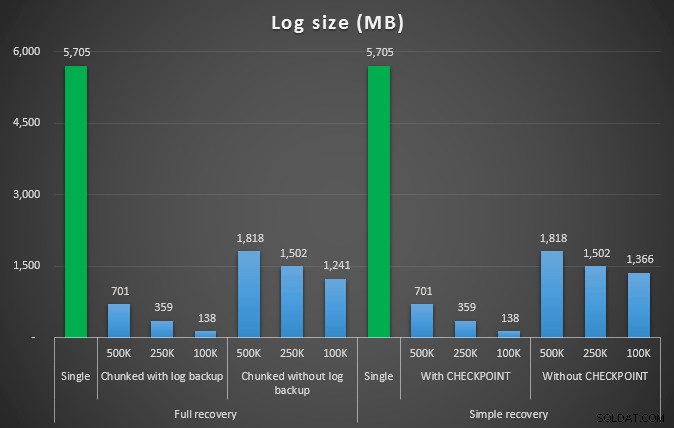 Loggrootte, in MB, na verschillende verwijderbewerkingen waarbij 4,5 MM rijen worden verwijderd
Loggrootte, in MB, na verschillende verwijderbewerkingen waarbij 4,5 MM rijen worden verwijderd
Dus nogmaals, we zien een significante vermindering van de logbestandsgrootte (meer dan 97% in gevallen met de kleinste chunkgrootte van 100K); op deze schaal zien we echter enkele gevallen waarin we de verwijdering ook in minder tijd uitvoeren, zelfs met alle autogrow-gebeurtenissen die moeten hebben plaatsgevonden. Dat klinkt heel erg als win-win voor mij!
Deze keer met een groter logboek
Nu was ik benieuwd hoe deze verschillende verwijderingen zich zouden verhouden tot een logbestand dat vooraf is aangepast aan dergelijke grote operaties. Ik bleef bij onze grotere database, breidde het logbestand vooraf uit tot 6 GB, maakte er een back-up van en voerde de tests opnieuw uit:
ALTER DATABASE delete_test MODIFY FILE (NAME=delete_test_log, SIZE=6000MB);
Resultaten, duur vergelijken met een vast logbestand met het geval waarin het bestand continu automatisch moest groeien:
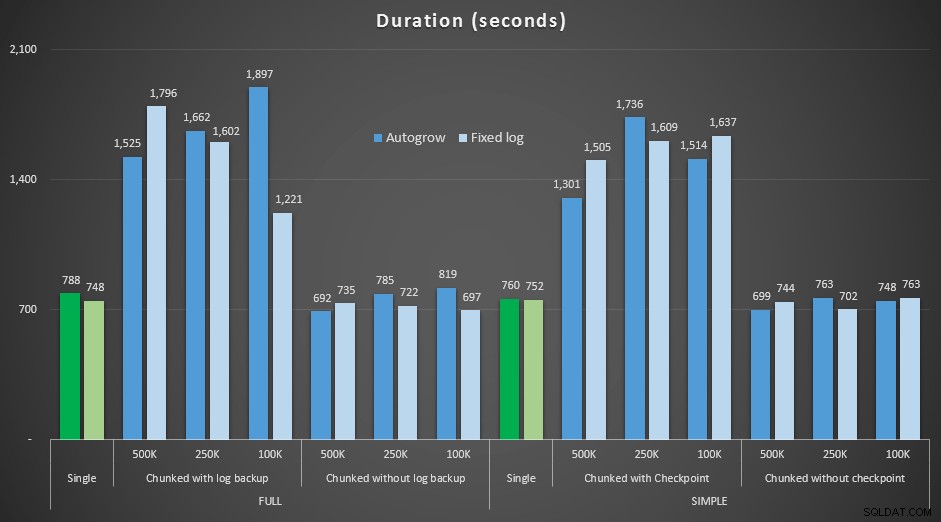
Duur, in seconden, van verschillende wisbewerkingen waarbij rijen van 4,5 mm worden verwijderd , vergelijking van vaste loggrootte en autogrow
Wederom zien we dat de methoden die deletes in batches verdelen en die *geen* een logback-up of een checkpoint uitvoeren na elke stap, qua duur evenaren met de equivalente enkele bewerking. Zie zelfs dat de meeste daadwerkelijk presteren in minder totale tijd, met de toegevoegde bonus dat andere transacties tussen de stappen in en uit kunnen komen. Dat is een goede zaak, tenzij u wilt dat deze verwijderbewerking alle niet-gerelateerde transacties blokkeert.
Conclusie
Het is duidelijk dat er geen enkel, juist antwoord op dit probleem is - er zijn veel inherente "het hangt ervan af"-variabelen. Het kan wat experimenteren vergen om je magische getal te vinden, omdat er een balans zal zijn tussen de overhead die nodig is om een back-up van het logboek te maken en hoeveel werk en tijd je bespaart bij verschillende chunk-groottes. Maar als u van plan bent een groot aantal rijen te verwijderen of te archiveren, is het vrij waarschijnlijk dat u in het algemeen beter af bent door de wijzigingen in delen uit te voeren in plaats van in één grote transactie – ook al lijken de duurcijfers dat een minder aantrekkelijke operatie. Het gaat niet alleen om de duur - als u niet over een voldoende vooraf toegewezen logbestand beschikt en niet over de ruimte beschikt om zo'n enorme transactie op te vangen, is het waarschijnlijk veel beter om de groei van het logbestand te minimaliseren ten koste van de duur, in dat geval wil je de bovenstaande duurgrafieken negeren en aandacht besteden aan de grafieken van de loggrootte.
Als u zich de ruimte kunt veroorloven, wilt u uw transactielogboek nog steeds dienovereenkomstig aanpassen. Afhankelijk van het scenario eindigde het gebruik van de standaard autogrow-instellingen soms iets sneller in mijn tests dan het gebruik van een vast logbestand met voldoende ruimte. Bovendien kan het moeilijk zijn om precies te raden hoeveel u nodig heeft voor een grote transactie die u nog niet heeft uitgevoerd. Als u geen realistisch scenario kunt testen, probeer dan uw best om uw worstcasescenario voor te stellen - en voor de veiligheid, verdubbel het dan. Kimberly Tripp (blog | @KimberlyLTripp) heeft geweldig advies in dit bericht:8 stappen om de transactielogboekdoorvoer te verbeteren – kijk in deze context specifiek naar punt 6. Ongeacht hoe u besluit uw benodigde logruimte te berekenen, als u de ruimte toch nodig zult hebben, kunt u deze beter ruim van tevoren op een gecontroleerde manier innemen dan uw bedrijfsprocessen stil te leggen terwijl ze wachten op een autogrow ( laat staan meerdere!).
Een ander zeer belangrijk facet hiervan dat ik niet expliciet heb gemeten, is de impact op gelijktijdigheid - een aantal kortere transacties zal in theorie minder impact hebben op gelijktijdige operaties. Hoewel een enkele verwijdering iets minder tijd kostte dan de langere, gegroepeerde bewerkingen, hield het alle vergrendelingen voor die hele duur vast, terwijl de gesegmenteerde bewerkingen ervoor zouden zorgen dat andere transacties in de wachtrij tussen elke transactie konden sluipen. In een toekomstige post zal ik proberen deze impact nader te bekijken (en ik heb ook plannen voor andere diepere analyses).