Inleiding
Sinds hun introductie in SQL Server 2005 werken vensters als ROW_NUMBER en RANK hebben bewezen uiterst nuttig te zijn bij het oplossen van een breed scala aan veelvoorkomende T-SQL-problemen. In een poging om dergelijke oplossingen te veralgemenen, proberen databaseontwerpers ze vaak op te nemen in views om code-inkapseling en hergebruik te bevorderen. Helaas betekent een beperking in de SQL Server-queryoptimalisatie vaak dat weergaven met vensterfuncties niet zo goed presteren als verwacht. Dit bericht behandelt een illustratief voorbeeld van het probleem, beschrijft de redenen en biedt een aantal tijdelijke oplossingen.
Dit probleem kan zich ook voordoen in afgeleide tabellen, algemene tabeluitdrukkingen en in-line functies, maar ik zie het het vaakst bij views omdat ze opzettelijk zijn geschreven om meer generiek te zijn.
Vensterfuncties
Vensterfuncties onderscheiden zich door de aanwezigheid van een OVER() clausule en zijn er in drie varianten:
- Functies van het rangschikkingsvenster
ROW_NUMBERRANKDENSE_RANKNTILE
- Totale vensterfuncties
MIN,MAX,AVG,SUMCOUNT,COUNT_BIGCHECKSUM_AGGSTDEV,STDEVP,VAR,VARP
- Analytische vensterfuncties
LAG,LEADFIRST_VALUE,LAST_VALUEPERCENT_RANK,PERCENTILE_CONT,PERCENTILE_DISC,CUME_DIST
De ranking- en aggregatievensterfuncties zijn geïntroduceerd in SQL Server 2005 en aanzienlijk uitgebreid in SQL Server 2012. De analytische vensterfuncties zijn nieuw voor SQL Server 2012.
Alle bovenstaande vensterfuncties zijn onderhevig aan de optimalisatiebeperking die in dit artikel wordt beschreven.
Voorbeeld
Met behulp van de AdventureWorks-voorbeelddatabase is de taak om een query te schrijven die alle product # 878-transacties retourneert die plaatsvonden op de meest recente beschikbare datum. Er zijn allerlei manieren om deze vereiste in T-SQL tot uitdrukking te brengen, maar we zullen ervoor kiezen om een query te schrijven die een vensterfunctie gebruikt. De eerste stap is om transactierecords voor product #878 te vinden en deze in aflopende volgorde van datum te rangschikken:
SELECTEER th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.Quantity, rnk =RANK() OVER (ORDER BY th.TransactionDate DESC)FROM Production.TransactionHistory AS thWHERE th.ProductID =878ORDER BY rnk;
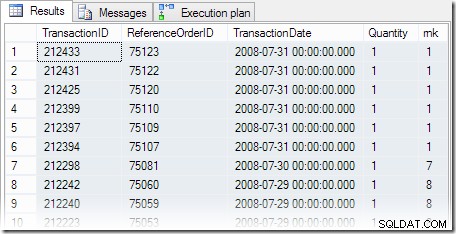

De resultaten van de zoekopdracht zijn zoals verwacht, met zes transacties die plaatsvinden op de meest recente beschikbare datum. Het uitvoeringsplan bevat een gevarendriehoek die ons waarschuwt voor een ontbrekende index:

Zoals gebruikelijk voor ontbrekende indexsuggesties, moeten we onthouden dat de aanbeveling niet het resultaat is van een grondige analyse van de zoekopdracht - het is meer een indicatie dat we een beetje moeten nadenken over hoe deze zoekopdracht toegang krijgt tot de gegevens die het nodig heeft.
De voorgestelde index zou zeker efficiënter zijn dan de tabel volledig te scannen, omdat het een index zou kunnen zoeken naar het specifieke product waarin we geïnteresseerd zijn. De index zou ook alle benodigde kolommen dekken, maar het zou de sortering (op TransactionDate aflopend). De ideale index voor deze zoekopdracht zou een zoekopdracht op ProductID mogelijk maken , retourneer de geselecteerde records in omgekeerde volgorde TransactionDate bestelling, en bedek de andere geretourneerde kolommen:
MAAK NIET-GECLUSTERDE INDEX ixON Production.TransactionHistory (ProductID, TransactionDate DESC)INCLUDE (ReferenceOrderID, Hoeveelheid);
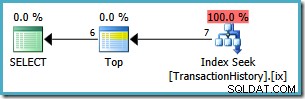
Met die index is het uitvoeringsplan veel efficiënter. De geclusterde index-scan is vervangen door een bereik zoeken en een expliciete sortering is niet langer nodig:

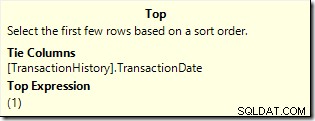
De laatste stap voor deze zoekopdracht is om de resultaten te beperken tot alleen die rijen die op nummer 1 staan. We kunnen niet rechtstreeks filteren in de WHERE clausule van onze query omdat vensterfuncties alleen mogen voorkomen in de SELECT en ORDER BY clausules.
We kunnen deze beperking omzeilen met behulp van een afgeleide tabel, algemene tabeluitdrukking, functie of weergave. Bij deze gelegenheid gebruiken we een algemene tabeluitdrukking (ook wel een in-line weergave genoemd):
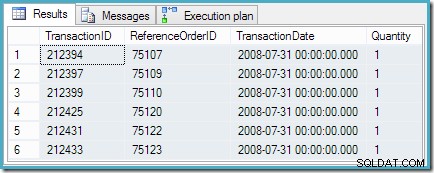
MET RatedTransactions AS( SELECT th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.Quantity, rnk =RANK() OVER ( ORDER BY th.TransactionDate DESC) VANAF Production.TransactionHistory AS TH WHERE th.ProductID =878 )SELECTIE TransactionID, ReferenceOrderID, TransactionDate, QuantityFROM RatedTransactionsWHERE rnk =1;
Het uitvoeringsplan is hetzelfde als voorheen, met een extra filter om alleen rijen op nummer 1 te retourneren:

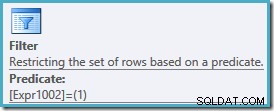
De zoekopdracht retourneert de zes gelijk gerangschikte rijen die we verwachten:
De zoekopdracht generaliseren
Het blijkt dat onze query erg nuttig is, dus wordt besloten om deze te generaliseren en de definitie in een view op te slaan. Om dit voor elk product te laten werken, moeten we twee dingen doen:de ProductID return retourneren uit de weergave, en verdeel de rangschikkingsfunctie op product:
WEERGAVE MAKEN dbo.MostRecentTransactionsPerProductMET SCHEMABINDINGASSELECT sq1.ProductID, sq1.TransactionID, sq1.ReferenceOrderID, sq1.TransactionDate, sq1.QuantityFROM ( SELECT th.ProductID, th.TransactionID, th.ReferenceOrderID, th.thTransactionID rnk =RANK() OVER (VERDELING DOOR th.ProductID ORDER DOOR th.TransactionDate DESC) VAN Production.TransactionHistory AS th) AS sq1WHERE sq1.rnk =1;
Het selecteren van alle rijen uit de weergave resulteert in het volgende uitvoeringsplan en correcte resultaten:

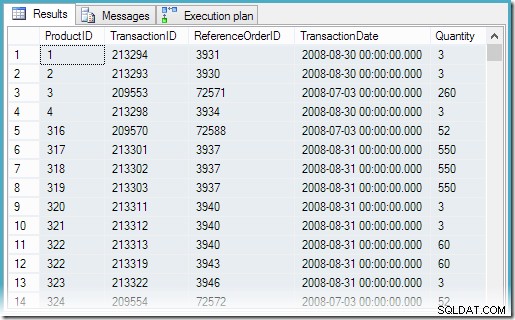
We kunnen nu de meest recente transacties voor product 878 vinden met een veel eenvoudigere zoekopdracht in de weergave:
SELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =878;
Onze verwachting is dat het uitvoeringsplan voor deze nieuwe query precies hetzelfde zal zijn als voordat we de weergave maakten. De query-optimizer moet het filter kunnen pushen dat is gespecificeerd in de WHERE clausule naar beneden in de weergave, wat resulteert in een indexzoekopdracht.
Op dit punt moeten we echter even stilstaan en nadenken. De query-optimizer kan alleen uitvoeringsplannen produceren die gegarandeerd dezelfde resultaten opleveren als de logische queryspecificatie - is het veilig om onze WHERE te pushen clausule in de weergave?
SQL Server 2005 uitvoeringsplan

Een blik op de filtereigenschappen in dit plan laat zien dat het twee predikaten toepast:
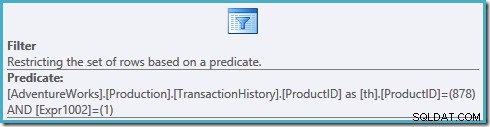
De ProductID = 878 predikaat is niet naar beneden in de weergave geduwd, wat resulteert in een plan dat onze index scant, elke rij in de tabel rangschikt voordat wordt gefilterd op product #878 en rijen gerangschikt op #1.
De query-optimizer van SQL Server 2005 kan geen geschikte predikaten voorbij een vensterfunctie duwen in een lager querybereik (weergave, algemene tabelexpressie, inline-functie of afgeleide tabel). Deze beperking is van toepassing op alle SQL Server 2005-builds.
SQL Server 2008+ uitvoeringsplan
Dit is het uitvoeringsplan voor dezelfde query op SQL Server 2008 of later:

De ProductID predikaat is met succes voorbij de rangschikkingsoperators geduwd, waarbij de indexscan is vervangen door de efficiënte indexzoekfunctie.
De query-optimizer van 2008 bevat een nieuwe vereenvoudigingsregel SelOnSeqPrj (selecteer op sequentieproject) dat in staat is om veilige predikaten van buiten de scope voorbij vensterfuncties te duwen. Om het minder efficiënte plan voor deze query in SQL Server 2008 of later te maken, moeten we deze functie voor het optimaliseren van query's tijdelijk uitschakelen:
SELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =878OPTION (QUERYRULEOFF SelOnSeqPrj);

Helaas is de SelOnSeqPrj vereenvoudigingsregel werkt alleen wanneer het predikaat een vergelijking uitvoert met een constante . Om die reden produceert de volgende query het suboptimale plan op SQL Server 2008 en later:
VERKLAREN @ProductID INT =878; SELECTEER mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WAAR mrt.ProductID =@ProductID;

Het probleem kan nog steeds optreden, zelfs als het predikaat een constante waarde gebruikt. SQL Server kan besluiten om triviale zoekopdrachten automatisch te parametreren (een waarvoor een duidelijk beste plan bestaat). Als de automatische parametrering succesvol is, ziet de optimizer een parameter in plaats van een constante, en de SelOnSeqPrj regel wordt niet toegepast.
Voor zoekopdrachten waarbij geen automatische parametrering wordt geprobeerd (of waarvan wordt vastgesteld dat deze onveilig is), kan de optimalisatie nog steeds mislukken als de databaseoptie voor FORCED PARAMETERIZATION staat aan. Onze testquery (met de constante waarde 878) is niet veilig voor automatische parametrering, maar de geforceerde parametrering overschrijft dit, wat resulteert in het inefficiënte plan:
DATABASE WIJZIGEN AdventureWorksSET PARAMETERISATIE GEFOCEERD;GOSELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =878;GOALTER DATABAAMESE AdventureWorks DATABAAMESE;>
SQL Server 2008+ oplossing
Om de optimizer een constante waarde te laten 'zien' voor een query die verwijst naar een lokale variabele of parameter, kunnen we een
OPTION (RECOMPILE)toevoegen vraag hint:VERKLAREN @ProductID INT =878; SELECTEER mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =@ProductIDOPTION (HERCOMPILE);Opmerking: Het pre-execution ('geschatte') uitvoeringsplan toont nog steeds een indexscan omdat de waarde van de variabele nog niet echt is ingesteld. Wanneer de query wordt uitgevoerd , het uitvoeringsplan toont echter het gewenste indexzoekplan:
De
SelOnSeqPrjregel bestaat niet in SQL Server 2005, dusOPTION (RECOMPILE)kan daar niet helpen. Voor het geval je het je afvraagt, deOPTION (RECOMPILE)tijdelijke oplossing resulteert in een zoekactie, zelfs als de databaseoptie voor geforceerde parametrering is ingeschakeld.Alle versies tijdelijke oplossing #1
In sommige gevallen is het mogelijk om de problematische weergave, algemene tabeluitdrukking of afgeleide tabel te vervangen door een geparametriseerde in-line tabelwaardefunctie:
FUNCTIE MAKEN dbo.MostRecentTransactionsForProduct( @ProductID integer) RETURNS TABLEMET SCHEMABINDING ASRETURN SELECT sq1.ProductID, sq1.TransactionID, sq1.ReferenceOrderID, sq1.TransactionDate, sq1.Quantity FROM (SELECT th.TransactionProductID, th. ReferenceOrderID, th.TransactionDate, th.Quantity, rnk =RANK() OVER (VERDELING DOOR th.ProductID ORDER DOOR th.TransactionDate DESC) VAN Production.TransactionHistory AS TH WHERE th.ProductID =@ProductID ) AS sq1 WHERE sq1.rnk =1;Deze functie plaatst expliciet de
ProductIDpredikaat in hetzelfde bereik als de vensterfunctie, waarbij de optimalisatiebeperking wordt vermeden. Geschreven om de in-line functie te gebruiken, wordt onze voorbeeldquery:SELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsForProduct(878) AS mrt;Dit levert het gewenste indexzoekplan op voor alle versies van SQL Server die vensterfuncties ondersteunen. Deze tijdelijke oplossing levert een zoekopdracht op, zelfs als het predikaat verwijst naar een parameter of lokale variabele -
OPTION (RECOMPILE)is niet vereist.PARTITION BY te verwijderen clausule, en om niet langer de ProductID. terug te geven kolom. Ik heb de definitie hetzelfde gelaten als de weergave die het verving om de oorzaak van de verschillen in het uitvoeringsplan duidelijker te illustreren.Alle versies tijdelijke oplossing #2
De tweede oplossing is alleen van toepassing op rangschikkingsvensterfuncties die zijn gefilterd om rijen te retourneren die genummerd of gerangschikt zijn als #1 (met behulp van
ROW_NUMBER,RANK, ofDENSE_RANK). Dit is echter een veel voorkomend gebruik, dus het is het vermelden waard.Een bijkomend voordeel is dat deze tijdelijke oplossing plannen kan opleveren die nog efficiënter zijn dan de index zoekt plannen eerder gezien. Ter herinnering:het vorige beste plan zag er als volgt uit:
Dat uitvoeringsplan scoort 1.918 rijen, ook al retourneert het uiteindelijk slechts 6 . We kunnen dit uitvoeringsplan verbeteren door de vensterfunctie te gebruiken in een
ORDER BYclausule in plaats van rijen rangschikken en vervolgens filteren op rang #1:SELECTEER TOP (1) MET BANDEN th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.QuantityFROM Production.TransactionHistory AS THWHERE th.ProductID =878ORDER BY RANK() OVER (ORDER BY th.TransactionDate DESC);
Die query illustreert mooi het gebruik van een vensterfunctie in de
ORDER BYclausule, maar we kunnen het nog beter doen door de vensterfunctie volledig te elimineren:SELECTEER TOP (1) MET BANDEN th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.QuantityFROM Production.TransactionHistory ALS THWHERE th.ProductID =878ORDER BY th.TransactionDate DESC;
Dit plan leest slechts 7 rijen uit de tabel om dezelfde resultatenset van 6 rijen te retourneren. Waarom 7 rijen? De Top-operator draait in
WITH TIESmodus:
Het blijft één rij tegelijk opvragen uit zijn substructuur totdat de TransactionDate verandert. De zevende rij is vereist voor de Top om er zeker van te zijn dat er geen rijen met gelijke waarde meer in aanmerking komen.
We kunnen de logica van de bovenstaande query uitbreiden om de problematische weergavedefinitie te vervangen:
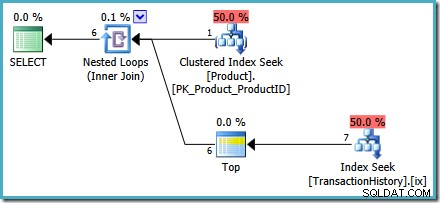
WEERGAVE WIJZIGEN dbo.MostRecentTransactionsPerProductMET SCHEMABINDINGASSELECTEER p.ProductID, gerangschikt1.TransactionID, gerangschikt1.ReferentieOrderID, gerangschikt1.TransactionDate, gerangschikt1.QuantityFROM -- Lijst met product-ID's (SELECT ProductID FROM Production.Product) ALS pCROSS APPLY( -- Returns Rank #1 resultaten voor elk product ID SELECTEER TOP (1) MET BANDEN th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.Quantity FROM Production.TransactionHistory AS THERE th.ProductID =p.ProductID ORDER BY th.TransactionDate BESCHRIJVING) AS gerangschikt1;De weergave gebruikt nu een
CROSS APPLYom de resultaten van onze geoptimaliseerdeORDER BY. te combineren vraag voor elk product. Onze testquery is ongewijzigd:DECLARE @ProductID integer;SET @ProductID =878; SELECTEER mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WAAR mrt.ProductID =@ProductID;Zowel pre- als post-uitvoeringsplannen tonen een indexzoekopdracht zonder dat een
OPTION (RECOMPILE)nodig is vraag hint. Het volgende is een plan voor na de uitvoering ('werkelijk'):
Als de weergave
ROW_NUMBER. had gebruikt in plaats vanRANK, zou de vervangende weergave gewoon deWITH TIES. hebben weggelaten clausule op deTOP (1). De nieuwe weergave kan natuurlijk ook worden geschreven als een geparametriseerde in-line tabelwaardefunctie.Men zou kunnen stellen dat het oorspronkelijke zoekplan voor de index met de
rnk = 1predikaat kan ook worden geoptimaliseerd om slechts 7 rijen te testen. De optimizer moet immers weten dat ranglijsten worden geproduceerd door de Sequence Project-operator in strikt oplopende volgorde, dus de uitvoering kan eindigen zodra een rij met een rangorde groter dan één wordt gezien. De optimizer bevat deze logica vandaag echter niet.Laatste gedachten
Mensen zijn vaak teleurgesteld over de prestaties van weergaven die vensterfuncties bevatten. De reden is vaak terug te voeren op de optimalisatiebeperking die in dit bericht wordt beschreven (of misschien omdat de weergaveontwerper niet op prijs stelde dat predikaten die op de weergave worden toegepast, moeten verschijnen in de
PARTITION BYclausule om veilig naar beneden te worden geduwd).Ik wil wel benadrukken dat deze beperking niet alleen van toepassing is op weergaven, en ook niet beperkt is tot
ROW_NUMBER,RANK, enDENSE_RANK. U dient zich bewust te zijn van deze beperking wanneer u een functie gebruikt met eenOVERclausule in een weergave, algemene tabeluitdrukking, afgeleide tabel of in-line tabelwaardefunctie.Gebruikers van SQL Server 2005 die dit probleem tegenkomen, worden geconfronteerd met de keuze om de weergave te herschrijven als een geparametriseerde in-line tabelwaardefunctie, of de
APPLYte gebruiken techniek (indien van toepassing).Gebruikers van SQL Server 2008 hebben de extra optie om een
OPTION (RECOMPILE). te gebruiken vraag hint als het probleem kan worden opgelost door de optimizer een constante te laten zien in plaats van een variabele of parameterverwijzing. Vergeet echter niet om de plannen na de uitvoering te controleren wanneer u deze hint gebruikt:het plan voor de uitvoering kan over het algemeen niet het optimale plan weergeven.