Een van de gefilterde gebruiksscenario's die in Books Online worden genoemd, betreft een kolom die voornamelijk NULL . bevat waarden. Het idee is om een gefilterde index te maken die de NULL's uitsluit , wat resulteert in een kleinere niet-geclusterde index die minder onderhoud vereist dan de equivalente ongefilterde index. Een ander populair gebruik van gefilterde indexen is het filteren van NULL's van een UNIEKE index, die het gedrag geeft dat gebruikers van andere database-engines zouden verwachten van een standaard UNIEK index of beperking:uniciteit wordt alleen afgedwongen voor de niet-NULL waarden.
Helaas heeft de query-optimizer beperkingen wat betreft gefilterde indexen. Dit bericht kijkt naar een paar minder bekende voorbeelden.
Voorbeeldtabellen
We zullen twee tabellen (A &B) gebruiken die dezelfde structuur hebben:een surrogaat geclusterde primaire sleutel, een meestal-NULL kolom die uniek is (zonder rekening te houden met NULL's ), en een opvulkolom die de andere kolommen vertegenwoordigt die mogelijk in een echte tabel staan.
De kolom van belang is de meestal-NULL één, die ik heb gedeclareerd als SPARSE . De schaarse optie is niet vereist, ik neem het gewoon op omdat ik niet veel kans krijg om het te gebruiken. In ieder geval SPARSE is waarschijnlijk logisch in veel scenario's waar de kolomgegevens naar verwachting meestal NULL zijn . Voel je vrij om het sparse-attribuut uit de voorbeelden te verwijderen als je wilt.
CREATE TABLE dbo.TableA
(
pk integer IDENTITY PRIMARY KEY,
data bigint SPARSE NULL,
padding binary(250) NOT NULL DEFAULT 0x
);
CREATE TABLE dbo.TableB
(
pk integer IDENTITY PRIMARY KEY,
data bigint SPARSE NULL,
padding binary(250) NOT NULL DEFAULT 0x
);
Elke tabel bevat de getallen van 1 tot 2.000 in de gegevenskolom met nog eens 40.000 rijen waarbij de gegevenskolom NULL is :
-- Numbers 1 - 2,000
INSERT
dbo.TableA WITH (TABLOCKX)
(data)
SELECT TOP (2000)
ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM sys.columns AS c
CROSS JOIN sys.columns AS c2
ORDER BY
ROW_NUMBER() OVER (ORDER BY (SELECT NULL));
-- NULLs
INSERT TOP (40000)
dbo.TableA WITH (TABLOCKX)
(data)
SELECT
CONVERT(bigint, NULL)
FROM sys.columns AS c
CROSS JOIN sys.columns AS c2;
-- Copy into TableB
INSERT dbo.TableB WITH (TABLOCKX)
(data)
SELECT
ta.data
FROM dbo.TableA AS ta;
Beide tabellen krijgen een UNIEK gefilterde index voor de 2000 niet-NULL gegevenswaarden:
CREATE UNIQUE NONCLUSTERED INDEX uqA ON dbo.TableA (data) WHERE data IS NOT NULL; CREATE UNIQUE NONCLUSTERED INDEX uqB ON dbo.TableB (data) WHERE data IS NOT NULL;
De uitvoer van DBCC SHOW_STATISTICS vat de situatie samen:
DBCC SHOW_STATISTICS (TableA, uqA) WITH STAT_HEADER; DBCC SHOW_STATISTICS (TableB, uqB) WITH STAT_HEADER;

Voorbeeldquery
De onderstaande query voert een eenvoudige samenvoeging van de twee tabellen uit – stel je voor dat de tabellen in een soort ouder-kindrelatie staan en dat veel van de refererende sleutels NULL zijn. In ieder geval iets in die richting.
SELECT
ta.data,
tb.data
FROM dbo.TableA AS ta
JOIN dbo.TableB AS tb
ON ta.data = tb.data; Standaard uitvoeringsplan
Met SQL Server in de standaardconfiguratie kiest de optimizer een uitvoeringsplan met een parallelle geneste loops-join:
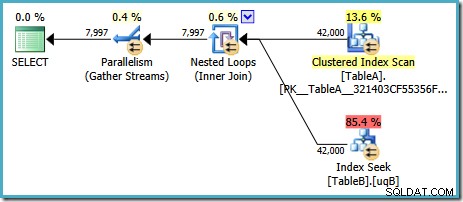
Dit abonnement kost naar schatting 7.7768 magic optimizer units™.
Er zijn echter enkele vreemde dingen aan dit plan. De Index Seek gebruikt onze gefilterde index op tabel B, maar de query wordt aangestuurd door een Clustered Index Scan van tabel A. Het join-predicaat is een gelijkheidstest op de gegevenskolommen, die NULL's (ongeacht de ANSI_NULLS instelling). We hadden misschien gehoopt dat de optimizer een geavanceerde redenering zou uitvoeren op basis van die observatie, maar nee. Dit plan leest elke rij uit tabel A (inclusief de 40.000 NULL's ), voert voor elk een zoekactie uit in de gefilterde index in tabel B, gebaseerd op het feit dat NULL komt niet overeen met NULL in dat zoeken. Dit is een enorme verspilling van moeite.
Het vreemde is dat de optimizer moet hebben gerealiseerd dat de join NULL's weigert om de gefilterde index voor tabel B te kiezen, maar het heeft er niet aan gedacht om NULL's te filteren eerst uit tabel A – of beter nog, om eenvoudig de NULL . te scannen -vrij gefilterde index op tabel A. Je vraagt je misschien af of dit een op kosten gebaseerde beslissing is, misschien zijn de statistieken niet erg goed? Misschien moeten we het gebruik van de gefilterde index afdwingen met een hint? Een hint naar de gefilterde index op tabel A resulteert in hetzelfde plan met de rollen omgedraaid - het scannen van tabel B en zoeken in tabel A. Het forceren van de gefilterde index voor beide tabellen levert fout 8622 op :de queryprocessor kon geen queryplan produceren.
Een NOT NULL-predikaat toevoegen
Vermoeden dat de oorzaak iets te maken heeft met de impliciete NULL -afwijzing van het join-predikaat, we voegen een expliciete NOT NULL toe predikaat aan de AAN clausule (of de WHERE clausule als je wilt, het komt hier op hetzelfde neer):
SELECT
ta.data,
tb.data
FROM dbo.TableA AS ta
JOIN dbo.TableB AS tb
ON ta.data = tb.data
AND ta.data IS NOT NULL;
We hebben de NIET NULL . toegevoegd controleer de tabel A-kolom omdat het oorspronkelijke plan de geclusterde index van die tabel scande in plaats van onze gefilterde index te gebruiken (het zoeken naar tabel B was prima - het gebruikte de gefilterde index). De nieuwe query is semantisch precies hetzelfde als de vorige, maar het uitvoeringsplan is anders:
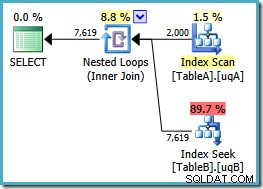
Nu hebben we de gehoopte scan van de gefilterde index op tabel A, wat 2.000 niet-NULL oplevert rijen om de geneste lus te zoeken naar tabel B. Beide tabellen gebruiken onze gefilterde indexen nu blijkbaar optimaal:het nieuwe plan kost slechts 0.362835 eenheden (van 7.7768). We kunnen echter beter doen.
Twee NOT NULL-predikaten toevoegen
De overbodige NIET NULL predikaat voor tabel A deed wonderen; wat gebeurt er als we er ook een toevoegen voor tabel B?
SELECT
ta.data,
tb.data
FROM dbo.TableA AS ta
JOIN dbo.TableB AS tb
ON ta.data = tb.data
AND ta.data IS NOT NULL
AND tb.data IS NOT NULL; Deze zoekopdracht is nog steeds logisch hetzelfde als de twee vorige pogingen, maar het uitvoeringsplan is weer anders:
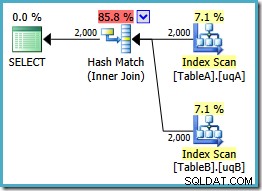
Dit plan bouwt een hash-tabel op voor de 2000 rijen uit tabel A, en zoekt vervolgens naar overeenkomsten met behulp van de 2000 rijen uit tabel B. Het geschatte aantal geretourneerde rijen is veel beter dan de vorige plan (heb je daar de schatting van 7.619 gezien?) en de geschatte uitvoeringskosten zijn weer gedaald, van 0,362835 naar 0,0772056 .
Je zou kunnen proberen een hash-join te forceren met behulp van een hint op het origineel of enkele-NOT NULL vragen, maar u krijgt niet het bovenstaande goedkope abonnement. De optimizer heeft gewoon niet de mogelijkheid om volledig te redeneren over de NULL -het weigeren van het gedrag van de join zoals deze van toepassing is op onze gefilterde indexen zonder beide redundante predikaten.
Je mag hierdoor verrast worden – al is het alleen maar het idee dat één redundant predikaat niet genoeg was (zeker als ta.data is NIET NULL en ta.data =tb.data , volgt hieruit dat tb.data is ook NIET NULL , toch?)
Nog steeds niet perfect
Het is een beetje verrassend om daar een hash te zien verschijnen. Als u bekend bent met de belangrijkste verschillen tussen de drie fysieke join-operators, weet u waarschijnlijk dat hash-join een topkandidaat is waar:
- Voorgesorteerde invoer is niet beschikbaar
- De hash build-invoer is kleiner dan de probe-invoer
- De sonde-invoer is vrij groot
Geen van deze dingen is hier waar. Onze verwachting zou zijn dat het beste plan voor deze query en dataset een merge-join zou zijn, waarbij gebruik wordt gemaakt van de geordende invoer die beschikbaar is uit onze twee gefilterde indexen. We kunnen proberen een merge-join te suggereren, met behoud van de twee extra ON clausule predikaten:
SELECT
ta.data,
tb.data
FROM dbo.TableA AS ta
JOIN dbo.TableB AS tb
ON ta.data = tb.data
AND ta.data IS NOT NULL
AND tb.data IS NOT NULL
OPTION (MERGE JOIN); De vorm van het plan is zoals we hadden gehoopt:
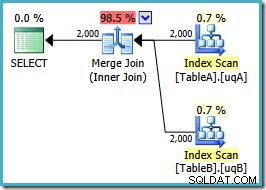
Een geordende scan van beide gefilterde indexen, geweldige kardinaliteitsschattingen, fantastisch. Slechts één klein probleempje:dit uitvoeringsplan is veel erger; de geschatte kosten zijn gestegen van 0,0772056 naar 0,741527 . De reden voor de sprong in geschatte kosten wordt onthuld door de eigenschappen van de samenvoegingsoperator te controleren:
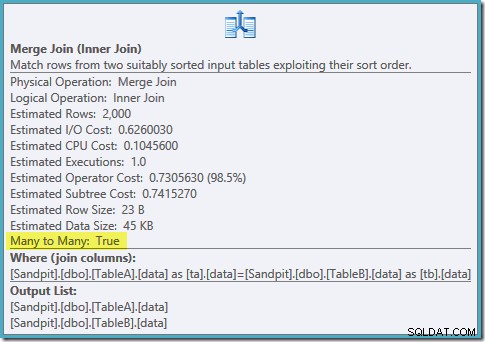
Dit is een dure veel-op-veel-join, waarbij de uitvoeringsengine duplicaten van de buitenste invoer in een werktabel moet bijhouden en indien nodig moet terugspoelen. Duplicaten? We scannen een unieke index! Het blijkt dat de optimizer niet weet dat een gefilterde unieke index unieke waarden oplevert (verbind het item hier). In feite is dit een één-op-één join, maar de optimizer kost het alsof het veel-op-veel is, wat verklaart waarom het de voorkeur geeft aan het hash-joinplan.
Een alternatieve strategie
Het lijkt erop dat we steeds tegen optimalisatiebeperkingen aanlopen als we hier gefilterde indexen gebruiken (ondanks dat het een uitgelichte use case is in Books Online). Wat gebeurt er als we in plaats daarvan weergaven proberen te gebruiken?
Weergaven gebruiken
De volgende twee weergaven filteren alleen de basistabellen om de rijen weer te geven waar de gegevenskolom NIET NULL is :
CREATE VIEW dbo.VA
WITH SCHEMABINDING AS
SELECT
pk,
data,
padding
FROM dbo.TableA
WHERE data IS NOT NULL;
GO
CREATE VIEW dbo.VB
WITH SCHEMABINDING AS
SELECT
pk,
data,
padding
FROM dbo.TableB
WHERE data IS NOT NULL; Het herschrijven van de originele query om de views te gebruiken is triviaal:
SELECT
v.data,
v2.data
FROM dbo.VA AS v
JOIN dbo.VB AS v2
ON v.data = v2.data; Onthoud dat deze zoekopdracht oorspronkelijk een plan voor parallelle geneste lussen opleverde voor 7,7768 eenheden. Met de weergavereferenties krijgen we dit uitvoeringsplan:
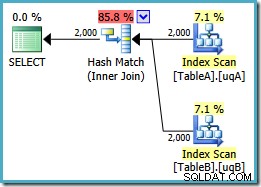
Dit is precies hetzelfde hash-joinplan dat we hadden om redundant toe te voegen NIET NULL predikaten te krijgen met de gefilterde indexen (de kosten zijn 0.0772056 eenheden als voorheen). Dit wordt verwacht, omdat het enige dat we hier in wezen hebben gedaan is om de extra NOT NULL . te pushen predikaten van de zoekopdracht naar een weergave.
De weergaven indexeren
We kunnen ook proberen de weergaven te materialiseren door een unieke geclusterde index op de pk-kolom te maken:
CREATE UNIQUE CLUSTERED INDEX cuq ON dbo.VA (pk); CREATE UNIQUE CLUSTERED INDEX cuq ON dbo.VB (pk);
Nu kunnen we unieke niet-geclusterde indexen toevoegen aan de gefilterde gegevenskolom in de geïndexeerde weergave:
CREATE UNIQUE NONCLUSTERED INDEX ix ON dbo.VA (data); CREATE UNIQUE NONCLUSTERED INDEX ix ON dbo.VB (data);
Merk op dat de filtering wordt uitgevoerd in de weergave, deze niet-geclusterde indexen worden zelf niet gefilterd.
Het perfecte plan
We zijn nu klaar om onze query uit te voeren tegen de weergave, met behulp van de NOEXPAND tafel hint:
SELECT
v.data,
v2.data
FROM dbo.VA AS v WITH (NOEXPAND)
JOIN dbo.VB AS v2 WITH (NOEXPAND)
ON v.data = v2.data; Het uitvoeringsplan is:
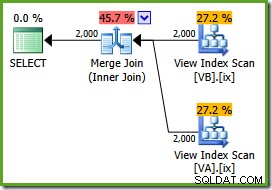
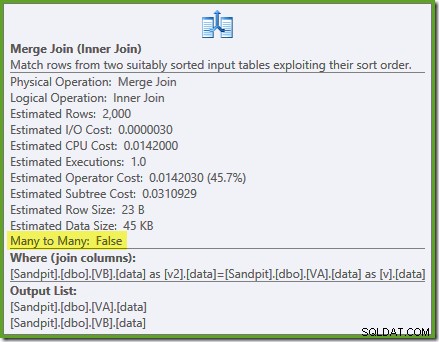
De optimizer kan de ongefilterde niet-geclusterde weergave-indexen zijn uniek, dus een veel-op-veel merge-join is niet nodig. Dit definitieve uitvoeringsplan heeft een geschatte kostprijs van 0,0310929 eenheden - zelfs lager dan het hash-joinplan (0.0772056 eenheden). Dit bevestigt onze verwachting dat een merge-join de laagste geschatte kosten zou moeten hebben voor deze query en voorbeelddataset.
De NOEXPAND zelfs in Enterprise Edition zijn hints nodig om ervoor te zorgen dat de uniekheidsgarantie die wordt geboden door de weergave-indexen door de optimizer wordt gebruikt.
Samenvatting
Dit bericht belicht twee belangrijke optimalisatiebeperkingen met gefilterde indexen:
- Overbodige join-predikaten kunnen nodig zijn om overeen te komen met gefilterde indexen
- Gefilterde unieke indexen bieden geen uniciteitsinformatie aan de optimizer
In sommige gevallen kan het praktisch zijn om eenvoudigweg de overbodige predikaten aan elke zoekopdracht toe te voegen. Het alternatief is om de gewenste impliciete predikaten in te kapselen in een niet-geïndexeerde weergave. Het hash-overeenkomstplan in dit bericht was veel beter dan het standaardplan, hoewel de optimizer het iets betere samenvoegingsplan zou moeten kunnen vinden. Soms moet u de weergave indexeren en NOEXPAND . gebruiken hints (hoe dan ook vereist voor Standard Edition-instanties). In nog andere omstandigheden zal geen van deze benaderingen geschikt zijn. Sorry daarvoor :)