In mijn laatste bericht ben ik begonnen met een serie over proactieve gezondheidscontroles die essentieel zijn voor uw SQL Server. We zijn begonnen met schijfruimte en in dit bericht bespreken we onderhoudstaken. Een van de fundamentele verantwoordelijkheden van een DBA is ervoor te zorgen dat de volgende onderhoudstaken regelmatig worden uitgevoerd:
- Back-ups
- Integriteitscontroles
- Indexonderhoud
- Statistische updates
Ik wed dat je al banen hebt om deze taken te beheren. En ik durf te wedden dat je meldingen hebt geconfigureerd om jou en je team te e-mailen als een taak mislukt. Als beide waar zijn, bent u al proactief bezig met onderhoud. En als je niet beide doet, is dat iets om nu op te lossen - zoals in, stop met dit lezen, download de scripts van Ola Hallengren, plan ze in en zorg ervoor dat je meldingen instelt. (Een ander alternatief specifiek voor indexonderhoud, dat we ook aan klanten aanbevelen, is SQL Sentry Fragmentation Manager.)
Als u niet weet of uw vacatures zijn ingesteld om u een e-mail te sturen als ze mislukken, gebruikt u deze vraag:
SELECT [Name], [Description] FROM [dbo].[sysjobs] WHERE [enabled] = 1 AND [notify_level_email] NOT IN (2,3) ORDER BY [Name];
Proactief omgaan met onderhoud gaat echter nog een stap verder. Naast ervoor te zorgen dat uw taken worden uitgevoerd, moet u weten hoe lang ze duren. U kunt de systeemtabellen in msdb gebruiken om dit te controleren:
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
CASE [h].[run_status]
WHEN 0 THEN 'Failed'
WHEN 1 THEN 'Succeeded'
WHEN 2 THEN 'Retry'
WHEN 3 THEN 'Cancelled'
WHEN 4 THEN 'In Progress'
END AS [ExecutionStatus],
[h].[message] AS [MessageGenerated]
FROM [msdb].[dbo].[sysjobhistory] [h]
INNER JOIN [msdb].[dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [j].[name] = 'DatabaseBackup - SYSTEM_DATABASES – FULL'
AND [step_id] = 0
ORDER BY [RunDate]; Of, als je Ola's scripts en loggegevens gebruikt, kun je zijn CommandLog-tabel opvragen:
SELECT [DatabaseName], [CommandType], [StartTime], [EndTime], DATEDIFF(MINUTE, [StartTime], [EndTime]) AS [Duration_Minutes] FROM [master].[dbo].[CommandLog] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'BACKUP DATABASE%' ORDER BY [StartTime];
Het bovenstaande script vermeldt de back-upduur voor elke volledige back-up voor de AdventureWorks2014-database. U kunt verwachten dat de duur van onderhoudstaken in de loop van de tijd langzaam zal toenemen, naarmate databases groter worden. U bent dus op zoek naar grote stijgingen of onverwachte dalingen in duur. Ik had bijvoorbeeld een klant met een gemiddelde back-upduur van minder dan 30 minuten. Plots beginnen back-ups meer dan een uur te duren. De database was niet significant in omvang veranderd, er waren geen instellingen veranderd voor de instance of database, er was niets veranderd met de hardware of schijfconfiguratie. Een paar weken later viel de back-upduur terug tot minder dan een half uur. Een maand later gingen ze weer omhoog. Uiteindelijk hebben we de wijziging in back-upduur gecorreleerd aan failovers tussen clusterknooppunten. Op één node duurden de back-ups minder dan een half uur. Aan de andere kant hebben ze er meer dan een uur over gedaan. Een beetje onderzoek naar de configuratie van de NIC's en SAN-fabric en we konden het probleem lokaliseren.
Het is ook belangrijk om de gemiddelde uitvoeringstijd voor CHECKDB-bewerkingen te begrijpen. Dit is iets waar Paul het over heeft in ons Onderdompelingsevenement voor hoge beschikbaarheid en noodherstel:u moet weten hoe lang het normaal duurt voordat CHECKDB wordt uitgevoerd, zodat als u corruptie aantreft en u de hele database controleert, u weet hoe lang het zou moeten duren nemen voordat CHECKDB is voltooid. Als je baas vraagt:"Hoe lang nog voordat we de omvang van het probleem weten?" u kunt een kwantitatief antwoord geven op de minimale tijd die u moet wachten. Als CHECKDB langer duurt dan normaal, dan weet je dat er iets is gevonden (wat niet per se corruptie hoeft te zijn; je moet de controle altijd laten voltooien).
Als u nu honderden databases beheert, wilt u de bovenstaande query niet voor elke database of elke taak uitvoeren. In plaats daarvan wilt u misschien gewoon banen vinden die met een bepaald percentage buiten de gemiddelde duur vallen, wat u kunt krijgen met deze zoekopdracht:
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
[avdur].[Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
INNER JOIN
(
SELECT
[j].[name] AS [JobName],
AVG((([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60))
AS [Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [step_id] = 0
AND CONVERT(DATE, RTRIM(h.run_date)) >= DATEADD(DAY, -60, GETDATE())
GROUP BY [j].[name]
) AS [avdur]
ON [avdur].[JobName] = [j].[name]
WHERE [step_id] = 0
AND (([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
> ([avdur].[Avg_RunDuration_Minutes] + ([avdur].[Avg_RunDuration_Minutes] * .25))
ORDER BY [j].[name], [RunDate]; Deze zoekopdracht geeft een overzicht van taken die 25% langer duurden dan het gemiddelde. De zoekopdracht vereist wat aanpassingen om de specifieke informatie te geven die u wilt - sommige taken met een korte duur (bijvoorbeeld minder dan 5 minuten) zullen verschijnen als ze slechts een paar extra minuten duren - dat is misschien geen probleem. Desalniettemin is deze zoekopdracht een goed begin, en realiseer je dat er veel manieren zijn om afwijkingen te vinden - je kunt ook elke uitvoering vergelijken met de vorige en zoeken naar taken die een bepaald percentage langer duurden dan de vorige.
Het is duidelijk dat de taakduur de meest logische aanduiding is om te gebruiken voor mogelijke problemen - of het nu gaat om een back-uptaak, een integriteitscontrole of de taak die fragmentatie verwijdert en statistieken bijwerkt. Ik heb ontdekt dat de grootste variatie in duur typisch is in de taken om fragmentatie te verwijderen en statistieken bij te werken. Afhankelijk van uw drempels voor reorg versus rebuild, en de vluchtigheid van uw gegevens, kunt u dagenlang met voornamelijk reorgs werken, en dan plotseling een paar indexreconstructies voor grote tabellen, waarbij die rebuilds de gemiddelde duur volledig veranderen. Mogelijk wilt u uw drempelwaarden voor sommige indexen wijzigen of de vulfactor aanpassen, zodat opnieuw opbouwen vaker of minder vaak plaatsvindt, afhankelijk van de index en het niveau van fragmentatie. Om deze aanpassingen te maken, moet u kijken hoe vaak elke index opnieuw wordt opgebouwd of gereorganiseerd, wat u alleen kunt doen als u Ola's scripts gebruikt en inlogt op de CommandLog-tabel, of als u uw eigen oplossing hebt gerolled en logt elke reorganisatie of herbouw. Om dit te bekijken met behulp van de CommandLog-tabel, kunt u beginnen met te controleren welke indexen het vaakst worden gewijzigd:
SELECT [DatabaseName], [ObjectName], [IndexName], COUNT(*) FROM [master].[dbo].[CommandLog] [c] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'ALTER INDEX%' GROUP BY [DatabaseName], [ObjectName], [IndexName] ORDER BY COUNT(*) DESC;
Op basis van deze uitvoer kunt u zien welke tabellen (en dus indexen) de meeste volatiliteit hebben en vervolgens bepalen of de drempel voor reorganisatie versus opnieuw opbouwen moet worden aangepast, of dat de vulfactor moet worden aangepast.
Het leven gemakkelijker maken
Nu is er een eenvoudigere oplossing dan het schrijven van uw eigen query's, zolang u SQL Sentry Event Manager (EM) gebruikt. De tool controleert alle agenttaken die op een instantie zijn ingesteld en met behulp van de kalenderweergave kunt u snel zien welke taken zijn mislukt, zijn geannuleerd of langer duren dan normaal:
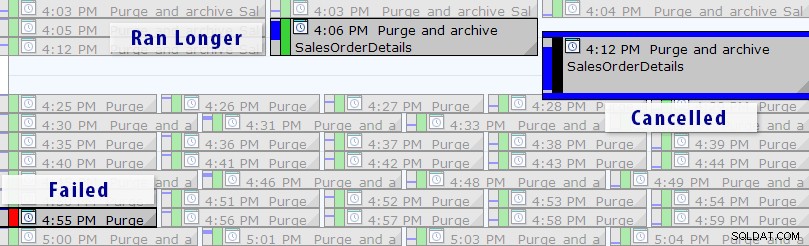 SQL Sentry Event Manager-agendaweergave (met labels toegevoegd in Photoshop)
SQL Sentry Event Manager-agendaweergave (met labels toegevoegd in Photoshop)
U kunt ook inzoomen op afzonderlijke uitvoeringen om te zien hoe lang het duurde om een taak uit te voeren, en er zijn ook handige runtime-grafieken waarmee u snel eventuele patronen in duurafwijkingen of storingsomstandigheden kunt visualiseren. In dit geval zie ik dat de runtime-duur voor deze specifieke taak ongeveer elke 15 minuten met bijna 400% is gestegen:
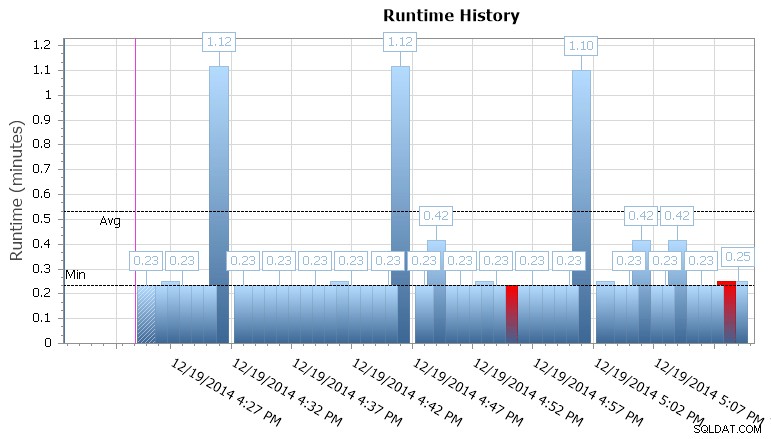 SQL Sentry Event Manager runtime-grafiek
SQL Sentry Event Manager runtime-grafiek
Dit geeft me een idee dat ik naar andere geplande taken moet kijken die hier mogelijk gelijktijdigheidsproblemen veroorzaken. Ik zou weer kunnen uitzoomen op de agenda om te zien welke andere taken rond dezelfde tijd worden uitgevoerd, of ik hoef misschien niet eens te kijken om te herkennen dat dit een rapportage- of back-uptaak is die tegen deze database draait.
Samenvatting
Ik durf te wedden dat de meesten van jullie al de nodige onderhoudstaken hebben en dat je ook meldingen hebt ingesteld voor taakstoringen. Als u niet bekend bent met de gemiddelde duur van uw taken, dan is dat uw volgende stap om proactief te zijn. Opmerking:u moet mogelijk ook controleren hoe lang u de taakgeschiedenis bewaart. Bij het zoeken naar afwijkingen in de duur van een baan, kijk ik liever naar gegevens van een paar maanden in plaats van een paar weken. U hoeft die looptijden niet te onthouden, maar als u eenmaal heeft geverifieerd dat u voldoende gegevens bijhoudt om de geschiedenis te gebruiken voor onderzoek, ga dan regelmatig op zoek naar variaties. In een ideaal scenario kan de langere looptijd u waarschuwen voor een mogelijk probleem, zodat u dit kunt oplossen voordat er zich een probleem voordoet in uw productieomgeving.