Nu 2014 ten einde loopt, start ik een reeks berichten over proactieve SQL Server-gezondheidscontroles, gebaseerd op een bericht dat ik begin dit jaar schreef:prestatieproblemen:de eerste ontmoeting. In dat bericht heb ik besproken waar ik als eerste naar op zoek ben bij het oplossen van een prestatieprobleem in een onbekende omgeving. In deze reeks berichten wil ik het hebben over waar ik naar op zoek ben als ik incheck bij mijn vaste klanten. We bieden een Remote DBA-service en een van onze vaste taken is een maandelijkse "mini"-gezondheidsaudit van hun omgeving. We hebben toezicht en meestal werk ik aan projecten, dus ik ben regelmatig in de omgeving. Maar als een extra stap om ervoor te zorgen dat we niets missen, nemen we eens per maand dezelfde gegevens door die we verzamelen in onze standaard gezondheidsaudit en zoeken we naar iets ongewoons. Dat kunnen veel dingen zijn, toch? Ja! Laten we beginnen met de ruimte.
Hoezo, ruimte? Ja, ruimte. Maak je geen zorgen, ik kom op andere onderwerpen.
Wat te controleren
Waarom zou ik beginnen met de ruimte? Omdat het iets is dat ik vaak verwaarloosd zie, en als je geen schijfruimte meer hebt voor je databasebestanden, wordt je extreem beperkt in wat je in je database kunt doen. Wilt u gegevens toevoegen, maar kunt u het bestand niet laten groeien omdat de schijf vol is? Sorry, gebruikers kunnen nu geen gegevens toevoegen. Maakt u om de een of andere reden geen back-ups van logboeken, zodat het transactielogboek de schijf vult? Sorry, je kunt nu geen gegevens wijzigen. Ruimte is cruciaal. We hebben taken die de vrije ruimte op de schijf en in de bestanden controleren, maar ik verifieer nog steeds het volgende voor elke audit en vergelijk de waarden met die van de vorige maand:
- Grootte van elk logbestand
- Grootte van elk gegevensbestand
- Vrije ruimte in elk gegevensbestand
- Vrije ruimte op elke schijf met databasebestanden
- Vrije ruimte op elke schijf met back-upbestanden
Aangroei logbestand
De meeste problemen die ik zie met betrekking tot schijfruimte, zijn vanwege de groei van logbestanden. De groei vindt meestal plaats om een van de volgende twee redenen:
- De database is in VOLLEDIG herstel en er worden om de een of andere reden geen back-ups van transactielogboeken gemaakt
- Iemand voert een enkele, zeer grote transactie uit die alle bestaande logruimte in beslag neemt, waardoor het bestand moet groeien
Ik heb het logbestand ook zien groeien als onderdeel van indexonderhoud. Voor rebuilds wordt elke toewijzing gelogd en voor grote indexen kan dat een aanzienlijke hoeveelheid logboek genereren. Zelfs met regelmatige back-ups van transactielogboeken kan het logboek nog steeds sneller groeien dan de back-ups kunnen plaatsvinden. Om het logboek te beheren, moet u de back-upfrequentie aanpassen of uw indexonderhoudsmethodologie wijzigen.
U moet bepalen waarom het logbestand is gegroeid, wat lastig kan zijn, tenzij u het bijhoudt. Ik heb een taak die elk uur wordt uitgevoerd om de grootte en het gebruik van het logbestand met snapshots te maken:
USE [Baselines];
GO
IF (NOT EXISTS (SELECT *
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'dbo'
AND TABLE_NAME = 'SQLskills_TrackLogSpace'))
BEGIN
CREATE TABLE [dbo].[SQLskills_TrackLogSpace](
[DatabaseName] [VARCHAR](250) NULL,
[LogSizeMB] [DECIMAL](38, 0) NULL,
[LogSpaceUsed] [DECIMAL](38, 0) NULL,
[LogStatus] [TINYINT] NULL,
[CaptureDate] [DATETIME2](7) NULL
) ON [PRIMARY];
ALTER TABLE [dbo].[SQLskills_TrackLogSpace] ADD DEFAULT (SYSDATETIME()) FOR [CaptureDate];
END
CREATE TABLE #LogSpace_Temp (
DatabaseName VARCHAR(100),
LogSizeMB DECIMAL(10,2),
LogSpaceUsed DECIMAL(10,2),
LogStatus VARCHAR(1)
);
INSERT INTO #LogSpace_Temp EXEC('dbcc sqlperf(logspace)');
INSERT INTO Baselines.dbo.SQLskills_TrackLogSpace
(DatabaseName, LogSizeMB, LogSpaceUsed, LogStatus)
SELECT DatabaseName, LogSizeMB, LogSpaceUsed, LogStatus
FROM #LogSpace_Temp;
DROP TABLE #LogSpace_Temp; Ik gebruik deze informatie om te bepalen wanneer het logbestand begon te groeien, en ik begin door de logs en de taakgeschiedenis te bladeren om te zien welke aanvullende informatie ik kan vinden. Logboekgroei moet statisch zijn - het logbestand moet de juiste grootte hebben en beheerd worden via back-ups (indien uitgevoerd in VOLLEDIG herstel), en als het bestand groter moet zijn, moet ik begrijpen waarom, en het dienovereenkomstig aanpassen.
Als je met dit probleem te maken hebt en je hebt nog niet proactief bestandsgroeigebeurtenissen bijgehouden, dan kun je misschien nog steeds achterhalen wat er is gebeurd. Automatische groeigebeurtenissen worden vastgelegd door SQL Server; Aaron Bertrand van SQL Sentry blogde hierover in 2007, waar hij laat zien hoe te ontdekken wanneer deze gebeurtenissen plaatsvonden (zolang ze recent genoeg waren om nog steeds te bestaan in de standaardtracering).
Grootte en vrije ruimte in gegevensbestanden
U hebt waarschijnlijk al gehoord dat uw gegevensbestanden vooraf moeten worden aangepast, zodat ze niet automatisch hoeven te groeien. Als u deze richtlijnen volgt, heeft u waarschijnlijk niet de gebeurtenis meegemaakt waarbij het gegevensbestand onverwachts groeit. Maar als u uw gegevensbestanden niet beheert, is er waarschijnlijk regelmatig groei, of u het zich realiseert of niet (vooral met de standaard groei-instellingen van 10% en 1 MB).
Er is een truc om gegevensbestanden vooraf te dimensioneren - u wilt een database niet te groot maken, want onthoud, als u herstelt naar bijvoorbeeld een dev- of QA-omgeving, hebben de bestanden dezelfde grootte, zelfs als ze' zit niet vol met gegevens. Maar u wilt de groei nog steeds handmatig beheren. Ik vind dat DBA's het het moeilijkst hebben met nieuwe databases. De zakelijke gebruikers hebben geen idee van groeipercentages en hoeveel data er wordt toegevoegd, en die database is een beetje een los kanon in uw omgeving. Je moet goed op deze bestanden letten totdat je grip hebt op de grootte en verwachte groei. Ik gebruik een query die informatie geeft over de grootte en vrije ruimte:
SELECT
[file_id] AS [File ID],
[type] AS [File Type],
substring([physical_name],1,1) AS [Drive],
[name] AS [Logical Name],
[physical_name] AS [Physical Name],
CAST([size] as DECIMAL(38,0))/128. AS [File Size MB],
CAST(FILEPROPERTY([name],'SpaceUsed') AS DECIMAL(38,0))/128. AS [Space Used MB],
(CAST([size] AS DECIMAL(38,0))/128) - (CAST(FILEPROPERTY([name],'SpaceUsed') AS DECIMAL(38,0))/128.) AS [Free Space],
[max_size] AS [Max Size],
[is_percent_growth] AS [Percent Growth Enabled],
[growth] AS [Growth Rate],
SYSDATETIME() AS [Current Date]
FROM sys.database_files; Elke maand controleer ik de grootte van de gegevensbestanden en de gebruikte ruimte en beslis dan of de grootte moet worden vergroot. Ik controleer ook het standaardspoor voor groeigebeurtenissen, omdat dit me precies vertelt wanneer groei plaatsvindt. Met uitzondering van nieuwe databases, kan ik de automatische bestandsgroei altijd voorblijven en handmatig afhandelen. Oké, bijna altijd. Vlak voor de vakantie vorig jaar kreeg ik van de IT-afdeling van een klant een melding dat er weinig vrije ruimte op een schijf was (houd die gedachte vast voor het volgende gedeelte). Nu is de melding gebaseerd op een drempel van minder dan 20% gratis. Deze schijf was meer dan 1 TB, dus er was ongeveer 150 GB vrij toen ik de schijf controleerde. Het was nog geen noodgeval, maar ik moest weten waar de ruimte was gebleven.
Bij het controleren van de databasebestanden voor één database, kon ik zien dat ze vol waren - en de vorige maand had elk bestand meer dan 50 GB gratis. Ik dook toen in tabelgroottes en ontdekte dat in één tabel meer dan 270 miljoen rijen waren toegevoegd in de afgelopen 16 dagen - in totaal meer dan 100 GB aan gegevens. Het bleek dat er een codewijziging was geweest en dat de nieuwe code meer informatie vastlegde dan de bedoeling was. We hebben snel een taak opgezet om de rijen op te schonen en de vrije ruimte in de bestanden te herstellen (en ze hebben de code gerepareerd). Ik kon echter geen schijfruimte vrijmaken - ik zou de bestanden moeten verkleinen, en dat was geen optie. Ik moest toen bepalen hoeveel ruimte er nog op de schijf was en beslissen of het een hoeveelheid was waar ik me prettig bij voelde of niet. Mijn comfortniveau is afhankelijk van het weten hoeveel gegevens er per maand worden toegevoegd - de typische groeisnelheid. En ik weet alleen hoeveel gegevens er worden toegevoegd omdat ik het bestandsgebruik monitor en kan inschatten hoeveel ruimte er nodig is voor deze maand, voor dit jaar en voor de komende twee jaar.
Schijfruimte
Ik zei eerder dat we taken hebben om de vrije schijfruimte te bewaken. Dit is gebaseerd op een percentage, niet op een vast bedrag. Mijn algemene vuistregel was om meldingen te verzenden wanneer minder dan 10% van de schijf vrij is, maar voor sommige schijven moet u dat mogelijk hoger instellen. Met een schijf van 1 TB krijg ik bijvoorbeeld een melding wanneer er minder dan 100 GB vrij is. Met een schijf van 100 GB krijg ik een melding wanneer er minder dan 10 GB vrij is. Met een schijf van 20 GB ... nou, je begrijpt waar ik hiermee naartoe wil. Die drempel moet u waarschuwen voordat er een probleem is. Als ik slechts 10 GB vrij heb op een schijf die een logbestand host, heb ik misschien niet genoeg tijd om te reageren voordat het als een probleem voor de gebruikers verschijnt - afhankelijk van hoe vaak ik de vrije ruimte controleer en wat het probleem is is.
Het is heel gemakkelijk om xp_fixeddrives te gebruiken om vrije ruimte te controleren, maar ik zou dit niet aanraden omdat het niet gedocumenteerd is en het gebruik van uitgebreide opgeslagen procedures in het algemeen is afgeschaft. Het rapporteert ook niet de totale grootte van elke schijf en rapporteert mogelijk niet over alle schijftypen die uw databases mogelijk gebruiken. Zolang je SQL Server 2008R2 SP1 of hoger gebruikt, kun je de veel handigere sys.dm_os_volume_stats gebruiken om de informatie te krijgen die je nodig hebt, in ieder geval over de stations waar databasebestanden staan:
SELECT DISTINCT vs.volume_mount_point AS [Drive], vs.logical_volume_name AS [Drive Name], vs.total_bytes/1024/1024 AS [Drive Size MB], vs.available_bytes/1024/1024 AS [Drive Free Space MB] FROM sys.master_files AS f CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) AS vs ORDER BY vs.volume_mount_point;
Ik zie vaak een probleem met schijfruimte op volumes die tempdb hosten. Ik ben de tel kwijt van de keren dat ik klanten heb gehad met onverklaarbare tempdb-groei. Soms is het maar een paar GB; meest recent was het 200GB. Tempdb is een lastig beest - er is geen formule om te volgen bij het dimensioneren, en te vaak wordt het op een schijf met weinig vrije ruimte geplaatst die de gekke gebeurtenis veroorzaakt door de beginnende ontwikkelaar of DBA niet aankan. Voor het dimensioneren van de tempdb-gegevensbestanden moet u uw workload uitvoeren voor een "normale" bedrijfscyclus om te bepalen hoeveel het tempdb gebruikt, en vervolgens de grootte dienovereenkomstig aanpassen.
Ik hoorde onlangs een suggestie voor een manier om te voorkomen dat er onvoldoende ruimte op een schijf komt:maak een database zonder gegevens en maak de bestanden zo groot dat ze zoveel ruimte innemen die u 'opzij wilt zetten'. Als je dan een probleem tegenkomt, laat je de database en altviool vallen, je hebt weer vrije ruimte. Persoonlijk denk ik dat dit allerlei andere problemen veroorzaakt en zou het niet aanbevelen. Maar als je opslagbeheerders hebt die het niet leuk vinden om honderden ongebruikte GB's op een schijf te zien, zou dit een manier zijn om een schijf er vol uit te laten zien. Het doet me denken aan iets dat ik een goede vriend van mij heb horen zeggen:"Als ik niet met je kan werken, zal ik om je heen werken."
Back-ups
Een van de belangrijkste taken van een DBA is het beschermen van de gegevens. Back-ups zijn een methode die wordt gebruikt om het te beschermen, en als zodanig vormen de schijven die deze back-ups bevatten een integraal onderdeel van het leven van een DBA. Vermoedelijk houdt u een of meer back-ups online, om deze indien nodig direct te herstellen. Uw SLA- en DR-runbook helpen bepalen hoeveel back-ups u online bewaart, en u moet ervoor zorgen dat u over die ruimte beschikt. Ik pleit ervoor dat u ook geen oude back-ups verwijdert totdat de huidige back-up met succes is voltooid. Het is veel te gemakkelijk om in de val te lopen door oude back-ups te verwijderen en vervolgens de huidige back-up uit te voeren. Maar wat gebeurt er als de huidige back-up mislukt? En wat gebeurt er als u compressie gebruikt? Wacht even ... gecomprimeerde back-ups zijn kleiner toch? Ze zijn uiteindelijk kleiner. Maar wist u dat de .bak-bestandsgrootte meestal groter begint dan de eindgrootte? U kunt traceringsvlag 3042 gebruiken om dit gedrag te wijzigen, maar u moet bedenken dat u bij back-ups voldoende ruimte nodig heeft. Als uw back-up 100 GB is en u 3 dagen online houdt, hebt u 300 GB nodig voor de 3 dagen back-ups, en dan waarschijnlijk een gezond bedrag (2X de huidige databasegrootte) vrij voor de volgende back-up. Ja, dit betekent dat je op elk moment meer dan 100 GB vrij hebt op deze schijf. Dat is goed. Het is beter dan de verwijdertaak te laten slagen en de back-uptaak te laten mislukken en er drie dagen later achter te komen dat u helemaal geen back-ups hebt (ik had dat bij een vorige taak met een klant).
De meeste databases worden in de loop van de tijd alleen maar groter, wat betekent dat back-ups ook groter worden. Vergeet niet om regelmatig de grootte van de back-upbestanden te controleren en indien nodig extra ruimte toe te wijzen - het hebben van een "200GB gratis"-beleid voor een database die is gegroeid tot 350GB zal niet erg nuttig zijn. Als de ruimtevereisten veranderen, zorg er dan voor dat u ook de bijbehorende waarschuwingen wijzigt.
Prestatieadviseur gebruiken
Er zijn verschillende vragen in dit bericht die u kunt gebruiken voor het bewaken van de ruimte, als u uw eigen proces moet uitvoeren. Maar als je toevallig SQL Sentry Performance Advisor in je omgeving hebt, wordt dit een stuk makkelijker met Custom Conditions. Er zijn standaard verschillende voorraadvoorwaarden inbegrepen, maar u kunt ook uw eigen voorwaarden maken.
Open in de SQL Sentry-client de Navigator, klik met de rechtermuisknop op Gedeelde groepen (algemeen) en selecteer Aangepaste voorwaarde toevoegen → SQL Sentry. Geef een naam en beschrijving op voor de voorwaarde, voeg vervolgens een numerieke vergelijking toe en wijzig het type in Repository Query. Voer de vraag in:
SELECT MIN(FreeSpace*100.0/Size) FROM SQLSentry.dbo.PerformanceAnalysisDeviceLogicalDisk;
Wijzig Is gelijk aan Is kleiner dan, en stel een expliciete waarde van 10 in. Wijzig ten slotte de standaard evaluatiefrequentie in iets dat minder vaak voorkomt dan elke 10 seconden. Een keer per dag of eens per 12 uur is waarschijnlijk een goede waarde – u hoeft de vrije ruimte niet vaker dan eenmaal per dag te controleren, maar u kunt deze zo vaak controleren als u wilt. De screenshot hieronder toont de uiteindelijke configuratie:
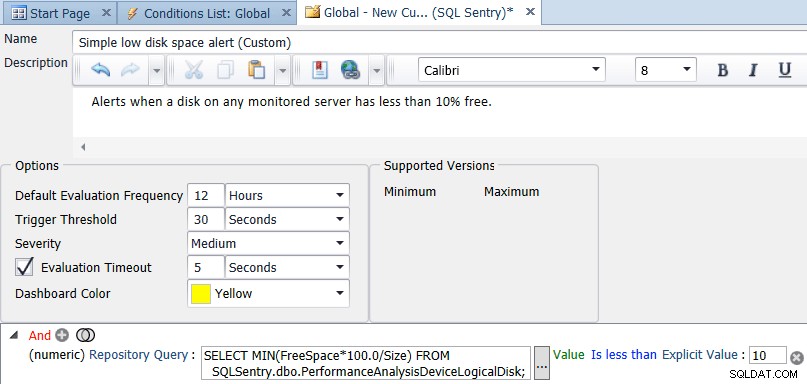
Zodra u op opslaan klikt voor de voorwaarde, wordt u gevraagd of u acties wilt toewijzen voor de aangepaste voorwaarde. De optie Verzenden naar waarschuwingskanalen is standaard geselecteerd, maar misschien wilt u andere taken uitvoeren, zoals een taak uitvoeren, bijvoorbeeld om oude back-ups naar een andere locatie te kopiëren (als dat de schijf met weinig ruimte is).
Zoals ik eerder al zei, is een standaard van 10% vrije ruimte voor alle schijven waarschijnlijk niet geschikt voor elke schijf in uw omgeving. U kunt de query aanpassen voor verschillende instanties en stations, bijvoorbeeld:
SELECT Alert = MAX(CASE WHEN Name = N'C:' AND [FreeSpace%] < 10 THEN 1 WHEN Name = N'S:' AND [FreeSpace%] < 25 THEN 1 WHEN Name = N'T:' AND [FreeSpace%] < 20 THEN 1 ELSE 0 END) FROM ( SELECT d.Name, d.FreeSpace * 100.0/d.Size AS [FreeSpace%] FROM SQLSentry.dbo.PerformanceAnalysisDeviceLogicalDisk AS d INNER JOIN SQLSentry.dbo.EventSourceConnection AS c ON d.DeviceID = c.DeviceID WHERE c.ObjectName = N'HANK\SQL2012' -- replace with your server/instance ) AS s;
U kunt deze query naar behoefte wijzigen en uitbreiden voor uw omgeving, en vervolgens de vergelijking in de voorwaarde dienovereenkomstig wijzigen (in feite evalueren naar waar als de uitkomst ooit is 1):
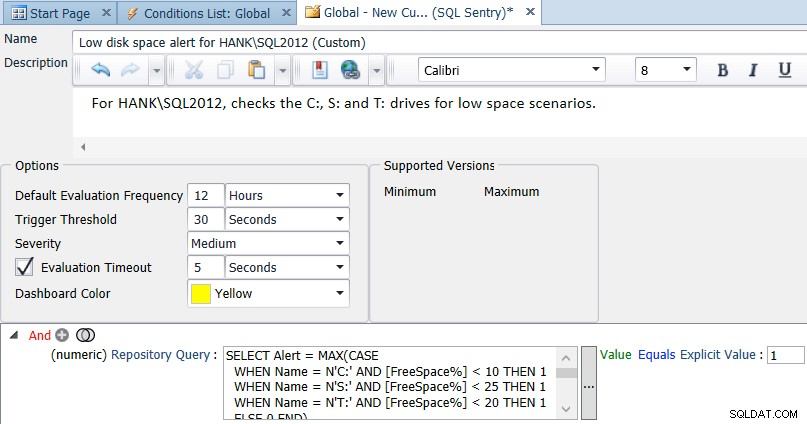
Als u Performance Advisor in actie wilt zien, kunt u een proefversie downloaden.
Houd er rekening mee dat u voor beide voorwaarden slechts één keer wordt gewaarschuwd, zelfs als meerdere schijven onder uw drempelwaarde vallen. In complexe omgevingen wilt u misschien een groter aantal specifiekere voorwaarden hanteren om flexibelere en aangepaste waarschuwingen te bieden, in plaats van minder 'catch-all'-voorwaarden.
Samenvatting
Er zijn veel kritieke componenten in een SQL Server-omgeving en schijfruimte moet proactief worden bewaakt en onderhouden. Met slechts een klein beetje planning is dit eenvoudig te doen, en het vermindert veel onbekenden en reactieve probleemoplossing. Of u nu uw eigen scripts of een tool van derden gebruikt, ervoor zorgen dat er voldoende vrije ruimte is voor databasebestanden en back-ups is een probleem dat gemakkelijk op te lossen is en de moeite meer dan waard is.