Als u tabelpartitionering gebruikt met een of meer partities die zijn opgeslagen in een alleen-lezen bestandsgroep, kunnen SQL-update- en verwijderinstructies mislukken met een fout. Dit is natuurlijk het verwachte gedrag als voor een van de wijzigingen moet worden geschreven naar een alleen-lezen bestandsgroep; het is echter ook mogelijk om deze foutconditie tegen te komen waarbij de wijzigingen beperkt zijn tot bestandsgroepen die zijn gemarkeerd als lezen-schrijven.
Voorbeelddatabase
Om het probleem te demonstreren, zullen we een eenvoudige database maken met een enkele aangepaste bestandsgroep die we later zullen markeren als alleen-lezen. Houd er rekening mee dat u het pad voor de bestandsnaam moet toevoegen aan uw testexemplaar.
USE master;
GO
CREATE DATABASE Test;
GO
-- This filegroup will be marked read-only later
ALTER DATABASE Test
ADD FILEGROUP ReadOnlyFileGroup;
GO
-- Add a file to the new filegroup
ALTER DATABASE Test
ADD FILE
(
NAME = 'Test_RO',
FILENAME = '<...your path...>\MSSQL\DATA\Test_ReadOnly.ndf'
)
TO FILEGROUP ReadOnlyFileGroup; Partitiefunctie en schema
We zullen nu een basispartitioneringsfunctie en -schema maken waarmee rijen met gegevens vóór 1 januari 2000 worden geleid. naar de alleen-lezen partitie. Latere gegevens worden bewaard in de lees-schrijf primaire bestandsgroep:
USE Test;
GO
CREATE PARTITION FUNCTION PF (datetime)
AS RANGE RIGHT
FOR VALUES ({D '2000-01-01'});
GO
CREATE PARTITION SCHEME PS
AS PARTITION PF
TO (ReadOnlyFileGroup, [PRIMARY]); De range right specificatie houdt in dat rijen met de grenswaarde 1 januari 2000 in de read-write partitie komen te staan.
Gepartitioneerde tabel en indexen
We kunnen nu onze testtabel maken:
CREATE TABLE dbo.Test
(
dt datetime NOT NULL,
c1 integer NOT NULL,
c2 integer NOT NULL,
CONSTRAINT PK_dbo_Test__c1_dt
PRIMARY KEY CLUSTERED (dt)
ON PS (dt)
)
ON PS (dt);
GO
CREATE NONCLUSTERED INDEX IX_dbo_Test_c1
ON dbo.Test (c1)
ON PS (dt);
GO
CREATE NONCLUSTERED INDEX IX_dbo_Test_c2
ON dbo.Test (c2)
ON PS (dt); De tabel heeft een geclusterde primaire sleutel in de datetime-kolom en is ook in die kolom gepartitioneerd. Er zijn niet-geclusterde indexen op de andere twee integer-kolommen, die op dezelfde manier zijn gepartitioneerd (de indexen zijn uitgelijnd met de basistabel).
Voorbeeldgegevens
Ten slotte voegen we een aantal rijen met voorbeeldgegevens toe en maken de gegevenspartitie van vóór 2000 alleen-lezen:
INSERT dbo.Test WITH (TABLOCKX)
(dt, c1, c2)
VALUES
({D '1999-12-31'}, 1, 1), -- Read only
({D '2000-01-01'}, 2, 2); -- Writable
GO
ALTER DATABASE Test
MODIFY FILEGROUP
ReadOnlyFileGroup READ_ONLY;
U kunt de volgende testupdate-instructies gebruiken om te bevestigen dat gegevens in de alleen-lezen partitie niet kunnen worden gewijzigd, terwijl gegevens met een dt waarde op of na 1 januari 2000 kan worden geschreven naar:
-- Will fail, as expected
UPDATE dbo.Test
SET c2 = 1
WHERE dt = {D '1999-12-31'};
-- Will succeed, as expected
UPDATE dbo.Test
SET c2 = 999
WHERE dt = {D '2000-01-01'};
-- Reset the value of c2
UPDATE dbo.Test
SET c2 = 2
WHERE dt = {D '2000-01-01'}; Een onverwachte mislukking
We hebben twee rijen:een alleen-lezen (1999-12-31); en één lezen-schrijven (2000-01-01):

Probeer nu de volgende query. Het identificeert dezelfde beschrijfbare rij "2000-01-01" die we zojuist met succes hebben bijgewerkt, maar gebruikt een ander predikaat van de where-clausule:
UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2;
Het geschatte (pre-uitvoerings)plan is:

De vier (!) Compute Scalars zijn niet belangrijk voor deze discussie. Ze worden gebruikt om te bepalen of de niet-geclusterde index moet worden onderhouden voor elke rij die aankomt bij de operator Clustered Index Update.
Het interessantere is dat deze update-instructie mislukt met een fout vergelijkbaar met:
Msg 652, Level 16, State 1De index "PK_dbo_Test__c1_dt" voor tabel "dbo.Test" (RowsetId 72057594039042048) bevindt zich op een alleen-lezen bestandsgroep ("ReadOnlyFileGroup"), die niet kan worden gewijzigd.
Geen partitie-eliminatie
Als je al eerder met partitionering hebt gewerkt, denk je misschien dat 'partitie-eliminatie' de reden zou kunnen zijn. De logica zou ongeveer als volgt gaan:
In de vorige instructies was er een letterlijke waarde voor de partitioneringskolom in de waar-clausule, zodat SQL Server onmiddellijk zou kunnen bepalen tot welke partitie(s) toegang moet worden verkregen. Door de where-clausule te wijzigen om niet langer naar de partitioneringskolom te verwijzen, hebben we SQL Server gedwongen toegang te krijgen tot elke partitie met behulp van een geclusterde indexscan.
Dat is in het algemeen allemaal waar, maar het is niet de reden waarom de update-instructie hier niet werkt.
Het verwachte gedrag is dat SQL Server moet kunnen lezen van alle partities tijdens het uitvoeren van de query. Een bewerking voor het wijzigen van gegevens mag alleen mislukken als de uitvoeringsengine werkelijk probeert te wijzigen een rij die is opgeslagen in een alleen-lezen bestandsgroep.
Laten we ter illustratie een kleine wijziging aanbrengen in de vorige vraag:
UPDATE dbo.Test
SET c2 = 2,
dt = dt
WHERE c1 = 2; De waar-clausule is precies hetzelfde als voorheen. Het enige verschil is dat we nu (bewust) de partitioneringskolom gelijk aan zichzelf stellen. Dit zal de waarde die in die kolom is opgeslagen niet veranderen, maar het heeft wel invloed op de uitkomst. De update slaagt nu (zij het met een complexer uitvoeringsplan):

De optimizer heeft nieuwe Split-, Sorteer- en Collapse-operators geïntroduceerd en de benodigde machines toegevoegd om elke potentieel aangetaste niet-geclusterde index afzonderlijk te onderhouden (met behulp van een brede of per-indexstrategie).
De eigenschappen van de geclusterde indexscan laten zien dat beide partities van de tabel zijn geopend tijdens het lezen:
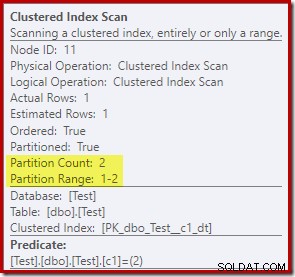
De update van de geclusterde index laat daarentegen zien dat alleen de lees-schrijfpartitie werd gebruikt om te schrijven:
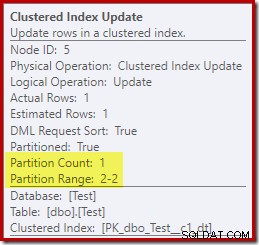
Elk van de niet-geclusterde indexupdate-operators toont vergelijkbare informatie:alleen de beschrijfbare partitie (#2) is tijdens runtime gewijzigd, dus er is geen fout opgetreden.
De reden onthuld
Het nieuwe plan slaagt niet omdat de niet-geclusterde indexen afzonderlijk worden bijgehouden; noch is het (direct) te wijten aan de combinatie Split-Sort-Collapse die nodig is om tijdelijke dubbele sleutelfouten in de unieke index te voorkomen.
De echte reden is iets dat ik kort noemde in mijn vorige artikel, "Optimizing Update Queries" - een interne optimalisatie die bekend staat als Rowset Sharing . Wanneer dit wordt gebruikt, deelt de Clustered Index Update dezelfde onderliggende rijenset voor opslagengines als een Clustered Index Scan, Seek of Key Lookup aan de leeszijde van het plan.
Met de Rowset Sharing-optimalisatie controleert SQL Server op offline of alleen-lezen bestandsgroepen bij het lezen. In plannen waarbij de Clustered Index Update een aparte rijenset gebruikt, wordt de offline/alleen-lezen controle alleen uitgevoerd voor elke rij bij de update (of verwijder) iterator.
Ongedocumenteerde oplossingen
Laten we eerst de leuke, geeky, maar onpraktische dingen uit de weg ruimen.
De optimalisatie van de gedeelde rijenset kan alleen worden toegepast wanneer de route van de geclusterde indexzoek-, scan- of sleutelzoekopdracht een pijplijn is . Er zijn geen blokkerende of semi-blokkerende operators toegestaan. Anders gezegd, elke rij moet van de leesbron naar de schrijfbestemming kunnen gaan voordat de volgende rij wordt gelezen.
Ter herinnering, hier zijn de voorbeeldgegevens, het statement en het uitvoeringsplan voor de mislukte opnieuw updaten:
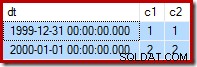
--Change the read-write row UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2;

Halloween-bescherming
Een manier om een blokkerende operator aan het plan te introduceren, is om voor deze update expliciete Halloween Protection (HP) te eisen. Door het lezen van het schrijven te scheiden met een blokkerende operator, wordt voorkomen dat de optimalisatie voor het delen van rijen wordt gebruikt (geen pijplijn). Ongedocumenteerde en niet-ondersteunde (alleen testsysteem!) traceringsvlag 8692 voegt een Eager Table Spool toe voor expliciete HP:
-- Works (explicit HP) UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2 OPTION (QUERYTRACEON 8692);
Het daadwerkelijke uitvoeringsplan (beschikbaar omdat de fout niet langer wordt gegenereerd) is:

De combinatie Sorteren in splitsen sorteren en samenvouwen die in de eerdere succesvolle update werd gezien, biedt de blokkering die nodig is om het delen van rijen in dat geval uit te schakelen.
De Anti-Rowset Sharing Trace Flag
Er is nog een niet-gedocumenteerde traceringsvlag die de optimalisatie van het delen van rijen uitschakelt. Dit heeft het voordeel dat er geen potentieel dure blokkeringsoperator wordt geïntroduceerd. Het kan natuurlijk niet in de praktijk worden gebruikt (tenzij je contact opneemt met Microsoft Support en schriftelijk iets krijgt waarin je wordt aanbevolen het in te schakelen, neem ik aan). Desalniettemin, voor amusementsdoeleinden, is hier traceringsvlag 8746 in actie:
-- Works (no rowset sharing) UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2 OPTION (QUERYTRACEON 8746);
Het daadwerkelijke uitvoeringsplan voor die verklaring is:

Voel je vrij om te experimenteren met verschillende waarden (die de opgeslagen waarden daadwerkelijk veranderen als je wilt) om jezelf hier van het verschil te overtuigen. Zoals vermeld in mijn vorige bericht, kunt u ook ongedocumenteerde traceringsvlag 8666 gebruiken om de eigenschap voor het delen van rijen in het uitvoeringsplan bloot te leggen.
Als u de fout bij het delen van rijen wilt zien met een delete-instructie, vervangt u gewoon de update- en set-clausules door een delete, terwijl u dezelfde where-clausule gebruikt.
Ondersteunde tijdelijke oplossingen
Er zijn een aantal mogelijke manieren om ervoor te zorgen dat het delen van rijensets niet wordt toegepast in real-world query's zonder traceringsvlaggen te gebruiken. Nu u weet dat het kernprobleem een gedeeld en gepijplijnd geclusterd indexlees- en schrijfplan vereist, kunt u waarschijnlijk uw eigen plan bedenken. Toch zijn er een paar voorbeelden die hier bijzonder de moeite waard zijn.
Geforceerde index / dekkingsindex
Een natuurlijk idee is om de leeskant van het plan te dwingen een niet-geclusterde index te gebruiken in plaats van de geclusterde index. We kunnen geen indexhint direct toevoegen aan de testquery zoals deze is geschreven, maar door de tabel te aliassen is dit mogelijk:
UPDATE T SET c2 = 2 FROM dbo.Test AS T WITH (INDEX(IX_dbo_Test_c1)) WHERE c1 = 2;
Dit lijkt misschien de oplossing die de query-optimizer in de eerste plaats had moeten kiezen, aangezien we een niet-geclusterde index hebben op de where-clausule predikaat kolom c1. Het uitvoeringsplan laat zien waarom de optimizer koos zoals het deed:
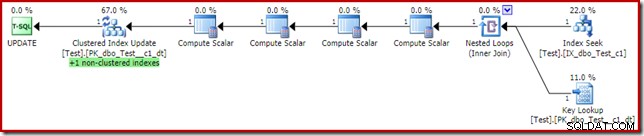
De kosten van de Key Lookup zijn voldoende om de optimizer te overtuigen om de geclusterde index te gebruiken voor het lezen. Het opzoeken is nodig om de huidige waarde van kolom c2 op te halen, zodat de Compute Scalars kunnen beslissen of de niet-geclusterde index moet worden onderhouden.
Het toevoegen van kolom c2 aan de niet-geclusterde index (sleutel of include) zou het probleem voorkomen. De optimizer zou de nu dekkende index kiezen in plaats van de geclusterde index.
Dat gezegd hebbende, is het niet altijd mogelijk om te anticiperen welke kolommen nodig zullen zijn, of om ze allemaal op te nemen, zelfs als de set bekend is. Onthoud dat de kolom nodig is omdat c2 in de set-clausule staat van de updateverklaring. Als de zoekopdrachten ad-hoc zijn (bijvoorbeeld ingediend door gebruikers of gegenereerd door een tool), zou elke niet-geclusterde index alle kolommen moeten bevatten om dit een robuuste optie te maken.
Een interessant ding over het plan met de Key Lookup hierboven is dat het niet . doet een fout genereren. Dit is ondanks de Key Lookup en Clustered Index Update met behulp van een gedeelde rijenset. De reden is dat de niet-geclusterde Index Seek de rij lokaliseert met c1 =2 voor de Key Lookup raakt de geclusterde index. De controle op gedeelde rijen voor offline / alleen-lezen bestandsgroepen wordt nog steeds uitgevoerd bij het opzoeken, maar raakt de alleen-lezen partitie niet aan, dus er wordt geen fout gegenereerd. Als laatste (gerelateerd) aandachtspunt:de Index Seek raakt beide partities, maar de Key Lookup raakt er slechts één.
Exclusief de alleen-lezen partitie
Een triviale oplossing is om te vertrouwen op partitie-eliminatie, zodat de leeszijde van het plan nooit de alleen-lezen partitie raakt. Dit kan met een expliciet predikaat, bijvoorbeeld een van deze:
UPDATE dbo.Test
SET c2 = 2
WHERE c1 = 2
AND dt >= {D '2000-01-01'};
UPDATE dbo.Test
SET c2 = 2
WHERE c1 = 2
AND $PARTITION.PF(dt) > 1; -- Not partition #1 Waar het onmogelijk of onhandig is om elke query te wijzigen om een predikaat voor het verwijderen van partities toe te voegen, kunnen andere oplossingen, zoals bijwerken via een weergave, geschikt zijn. Bijvoorbeeld:
CREATE VIEW dbo.TestWritablePartitions
WITH SCHEMABINDING
AS
-- Only the writable portion of the table
SELECT
T.dt,
T.c1,
T.c2
FROM dbo.Test AS T
WHERE
$PARTITION.PF(dt) > 1;
GO
-- Succeeds
UPDATE dbo.TestWritablePartitions
SET c2 = 2
WHERE c1 = 2; Een nadeel van het gebruik van een weergave is dat een update of verwijdering die gericht is op het alleen-lezen deel van de basistabel, slaagt zonder dat de rijen worden beïnvloed, in plaats van dat er een fout optreedt. Een in plaats van trigger op de tafel of view kan in sommige situaties een oplossing zijn, maar kan ook meer problemen veroorzaken... maar ik dwaal af.
Zoals eerder vermeld, zijn er veel mogelijke ondersteunde oplossingen. Het doel van dit artikel is om te laten zien hoe het delen van rijen de onverwachte updatefout veroorzaakte.