Meer dan drie jaar geleden plaatste ik een driedelige serie over het splitsen van snaren:
- Snaren op de juiste manier splitsen - of op de volgende beste manier
- Snaren splitsen:een vervolg
- Snaren splitsen:nu met minder T-SQL
In januari nam ik een iets uitgebreider probleem aan:
- Het vergelijken van methoden voor het splitsen / samenvoegen van tekenreeksen
Al die tijd was mijn conclusie:STOP DIT TE DOEN IN T-SQL . Gebruik CLR of, beter nog, geef gestructureerde parameters zoals DataTables door van uw toepassing naar tabelwaardeparameters (TVP's) in uw procedures, waarbij u alle stringconstructie en deconstructie helemaal vermijdt - wat echt het deel van de oplossing is dat prestatieproblemen veroorzaakt.
En toen kwam SQL Server 2016 langs…
Toen RC0 werd uitgebracht, werd zonder veel poespas een nieuwe functie gedocumenteerd:STRING_SPLIT . Een snel voorbeeld:
SELECT * FROM STRING_SPLIT('a,b,cd', ',');
/* result:
value
--------
a
b
cd
*/ Het trok de aandacht van een paar collega's, waaronder Dave Ballantyne, die schreef over de belangrijkste kenmerken, maar zo vriendelijk was me het eerste recht van weigering te geven bij een prestatievergelijking.
Dit is meestal een academische oefening, want met een flinke reeks beperkingen in de eerste iteratie van de functie, zal het waarschijnlijk niet haalbaar zijn voor een groot aantal gebruiksscenario's. Hier is de lijst van de observaties die Dave en ik hebben gedaan, waarvan sommige in bepaalde scenario's dealbreakers kunnen zijn:
- de functie vereist dat de database compatibiliteitsniveau 130 heeft;
- het accepteert alleen scheidingstekens van één teken;
- er is geen manier om uitvoerkolommen toe te voegen (zoals een kolom die de ordinale positie binnen de tekenreeks aangeeft);
- gerelateerd, er is geen manier om het sorteren te regelen - de enige opties zijn willekeurig en alfabetisch
ORDER BY value;
- gerelateerd, er is geen manier om het sorteren te regelen - de enige opties zijn willekeurig en alfabetisch
- tot nu toe schat het altijd 50 uitvoerrijen;
- wanneer je het voor DML gebruikt, krijg je in veel gevallen een table spool (ter bescherming tegen Halloween);
NULLinvoer leidt tot een leeg resultaat;- er is geen manier om predikaten naar beneden te duwen, zoals het elimineren van dubbele of lege tekenreeksen vanwege opeenvolgende scheidingstekens;
- er is geen manier om bewerkingen uit te voeren tegen de uitvoerwaarden tot na het feit (veel splitsingsfuncties voeren bijvoorbeeld
LTRIM/RTRIMuit of expliciete conversies voor u –STRING_SPLITspuugt al het lelijke terug, zoals voorloopspaties).
Dus met die beperkingen in de openbaarheid, kunnen we overgaan tot enkele prestatietests. Gezien de staat van dienst van Microsoft met ingebouwde functies die gebruikmaken van CLR onder de dekens (kuch FORMAT() hoesten ), was ik sceptisch of deze nieuwe functie in de buurt zou komen van de snelste methoden die ik tot nu toe had getest.
Laten we stringsplitters gebruiken om door komma's gescheiden reeksen getallen te scheiden, zodat onze nieuwe vriend JSON ook mee kan spelen. En we zullen zeggen dat geen enkele lijst langer kan zijn dan 8.000 tekens, dus geen MAX typen zijn vereist, en aangezien het getallen zijn, hebben we niet te maken met iets exotisch zoals Unicode.
Laten we eerst onze functies maken, waarvan ik er een aantal heb aangepast uit het eerste artikel hierboven. Ik heb een paar weggelaten waarvan ik niet het gevoel had dat ze zouden concurreren; Ik laat het als een oefening aan de lezer over om die te testen.
Tabel met getallen
Deze heeft weer wat opstelling nodig, maar het kan een vrij kleine tafel zijn vanwege de kunstmatige beperkingen die we plaatsen:
SET NOCOUNT ON;
DECLARE @UpperLimit INT = 8000;
;WITH n AS
(
SELECT
x = ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
)
SELECT Number = x
INTO dbo.Numbers
FROM n
WHERE x BETWEEN 1 AND @UpperLimit;
GO
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(Number); Dan de functie:
CREATE FUNCTION dbo.SplitStrings_Numbers
(
@List varchar(8000),
@Delimiter char(1)
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
(
SELECT [Value] = SUBSTRING(@List, [Number],
CHARINDEX(@Delimiter, @List + @Delimiter, [Number]) - [Number])
FROM dbo.Numbers WHERE Number <= LEN(@List)
AND SUBSTRING(@Delimiter + @List, [Number], 1) = @Delimiter
); JSON
Op basis van een aanpak die voor het eerst werd onthuld door het opslagengine-team, heb ik een vergelijkbare wrapper gemaakt rond OPENJSON , houd er rekening mee dat het scheidingsteken in dit geval een komma moet zijn, of dat u een zware tekenreeksvervanging moet uitvoeren voordat u de waarde doorgeeft aan de oorspronkelijke functie:
CREATE FUNCTION dbo.SplitStrings_JSON
(
@List varchar(8000),
@Delimiter char(1) -- ignored but made automated testing easier
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )); De CHAR(91)/CHAR(93) vervangen respectievelijk [ en ] vanwege opmaakproblemen.
XML
CREATE FUNCTION dbo.SplitStrings_XML
(
@List varchar(8000),
@Delimiter char(1)
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] = y.i.value('(./text())[1]', 'varchar(8000)')
FROM (SELECT x = CONVERT(XML, '<i>'
+ REPLACE(@List, @Delimiter, '</i><i>')
+ '</i>').query('.')
) AS a CROSS APPLY x.nodes('i') AS y(i)); CLR
Ik heb opnieuw de vertrouwde splitsingscode van Adam Machanic geleend van bijna zeven jaar geleden, ook al ondersteunt het Unicode, MAX typen en scheidingstekens van meerdere tekens (en eigenlijk, omdat ik helemaal niet met de functiecode wil knoeien, beperkt dit onze invoerreeksen tot 4.000 tekens in plaats van 8.000):
CREATE FUNCTION dbo.SplitStrings_CLR ( @List nvarchar(MAX), @Delimiter nvarchar(255) ) RETURNS TABLE ( value nvarchar(4000) ) EXTERNAL NAME CLRUtilities.UserDefinedFunctions.SplitString_Multi;
STRING_SPLIT
Voor de consistentie heb ik een wikkel rond STRING_SPLIT :
CREATE FUNCTION dbo.SplitStrings_Native
(
@List varchar(8000),
@Delimiter char(1)
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT value FROM STRING_SPLIT(@List, @Delimiter));
Brongegevens &Sanity Check
Ik heb deze tabel gemaakt om te dienen als de bron van invoerreeksen voor de functies:
CREATE TABLE dbo.SourceTable
(
RowNum int IDENTITY(1,1) PRIMARY KEY,
StringValue varchar(8000)
);
;WITH x AS
(
SELECT TOP (60000) x = STUFF((SELECT TOP (ABS(o.[object_id] % 20))
',' + CONVERT(varchar(12), c.[object_id]) FROM sys.all_columns AS c
WHERE c.[object_id] < o.[object_id] ORDER BY NEWID() FOR XML PATH(''),
TYPE).value(N'(./text())[1]', N'varchar(8000)'),1,1,'')
FROM sys.all_objects AS o CROSS JOIN sys.all_objects AS o2
ORDER BY NEWID()
)
INSERT dbo.SourceTable(StringValue)
SELECT TOP (50000) x
FROM x WHERE x IS NOT NULL
ORDER BY NEWID(); Laten we ter referentie valideren dat 50.000 rijen de tabel hebben gehaald en de gemiddelde lengte van de string en het gemiddelde aantal elementen per string controleren:
SELECT
[Values] = COUNT(*),
AvgStringLength = AVG(1.0*LEN(StringValue)),
AvgElementCount = AVG(1.0*LEN(StringValue)-LEN(REPLACE(StringValue, ',','')))
FROM dbo.SourceTable;
/* result:
Values AvgStringLength AbgElementCount
------ --------------- ---------------
50000 108.476380 8.911840
*/
En tot slot, laten we ervoor zorgen dat elke functie de juiste gegevens retourneert voor een gegeven RowNum , dus we kiezen er gewoon een willekeurig en vergelijken de waarden die via elke methode zijn verkregen. Je resultaten zullen natuurlijk variëren.
SELECT f.value FROM dbo.SourceTable AS s CROSS APPLY dbo.SplitStrings_/* method */(s.StringValue, ',') AS f WHERE s.RowNum = 37219 ORDER BY f.value;
En ja hoor, alle functies werken zoals verwacht (sorteren is niet numeriek; onthoud, de uitvoertekenreeksen van de functies):
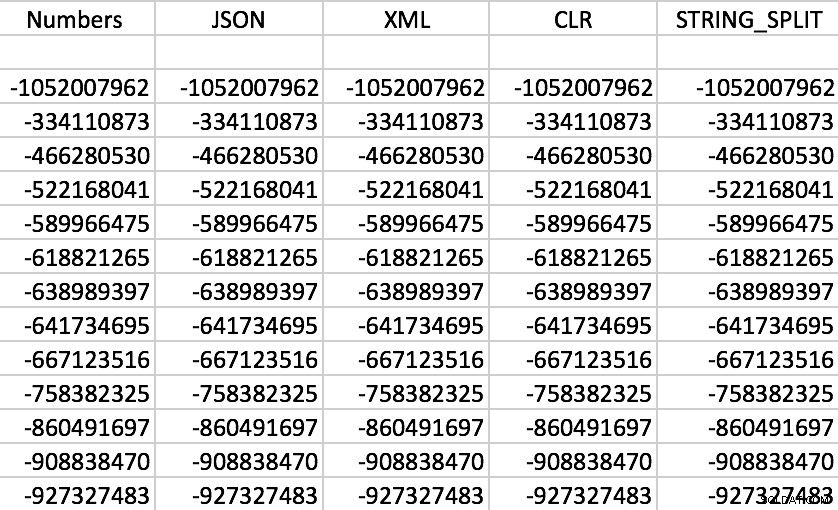 Voorbeeldset van uitvoer van elk van de functies
Voorbeeldset van uitvoer van elk van de functies
Prestatietesten
SELECT SYSDATETIME(); GO DECLARE @x VARCHAR(8000); SELECT @x = f.value FROM dbo.SourceTable AS s CROSS APPLY dbo.SplitStrings_/* method */(s.StringValue,',') AS f; GO 100 SELECT SYSDATETIME();
Ik heb de bovenstaande code 10 keer uitgevoerd voor elke methode en de gemiddelde timing voor elke methode berekend. En hier kwam de verrassing voor mij. Gezien de beperkingen in de native STRING_SPLIT functie, was mijn veronderstelling dat het snel in elkaar werd gegooid, en dat de uitvoering daar geloofwaardigheid aan zou verlenen. Jongen was het resultaat anders dan ik had verwacht:
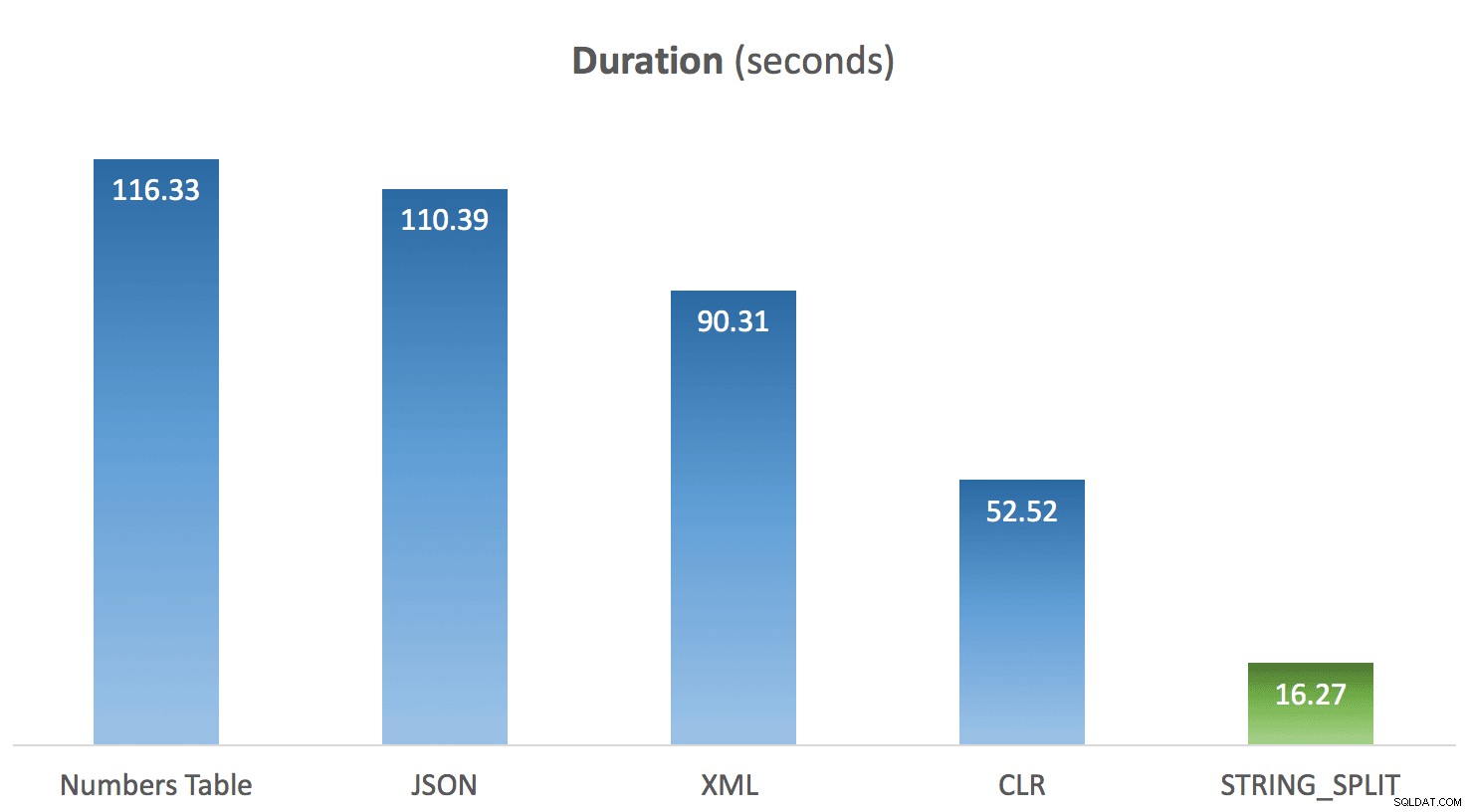 Gemiddelde duur van STRING_SPLIT vergeleken met andere methoden
Gemiddelde duur van STRING_SPLIT vergeleken met andere methoden
Update 20-03-2016
Op basis van de onderstaande vraag van Lars heb ik de tests opnieuw uitgevoerd met een paar wijzigingen:
- Ik heb mijn exemplaar gecontroleerd met SQL Sentry Performance Advisor om het CPU-profiel vast te leggen tijdens de test;
- Ik heb tussen elke batch wachtstatistieken op sessieniveau vastgelegd;
- Ik heb een vertraging tussen batches ingevoegd, zodat de activiteit visueel duidelijk te zien zou zijn op het Performance Advisor-dashboard.
Ik heb een nieuwe tabel gemaakt om wachtstatistieken vast te leggen:
CREATE TABLE dbo.Timings ( dt datetime, test varchar(64), point varchar(64), session_id smallint, wait_type nvarchar(60), wait_time_ms bigint, );
Daarna veranderde de code voor elke test in dit:
WAITFOR DELAY '00:00:30'; DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, test = /* 'method' */, point = 'Start', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; GO DECLARE @x VARCHAR(8000); SELECT @x = f.value FROM dbo.SourceTable AS s CROSS APPLY dbo.SplitStrings_/* method */(s.StringValue, ',') AS f GO 100 DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, /* 'method' */, 'End', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID;
Ik heb de test uitgevoerd en vervolgens de volgende vragen uitgevoerd:
-- validate that timings were in same ballpark as previous tests
SELECT test, DATEDIFF(SECOND, MIN(dt), MAX(dt))
FROM dbo.Timings WITH (NOLOCK)
GROUP BY test ORDER BY 2 DESC;
-- determine window to apply to Performance Advisor dashboard
SELECT MIN(dt), MAX(dt) FROM dbo.Timings;
-- get wait stats registered for each session
SELECT test, wait_type, delta FROM
(
SELECT f.test, rn = RANK() OVER (PARTITION BY f.point ORDER BY f.dt),
f.wait_type, delta = f.wait_time_ms - COALESCE(s.wait_time_ms, 0)
FROM dbo.Timings AS f
LEFT OUTER JOIN dbo.Timings AS s
ON s.test = f.test
AND s.wait_type = f.wait_type
AND s.point = 'Start'
WHERE f.point = 'End'
) AS x
WHERE delta > 0
ORDER BY rn, delta DESC; Vanaf de eerste zoekopdracht bleven de timings consistent met eerdere tests (ik zou ze opnieuw in kaart brengen, maar dat zou niets nieuws onthullen).
Vanaf de tweede vraag kon ik dit bereik op het Performance Advisor-dashboard markeren en van daaruit was het gemakkelijk om elke batch te identificeren:
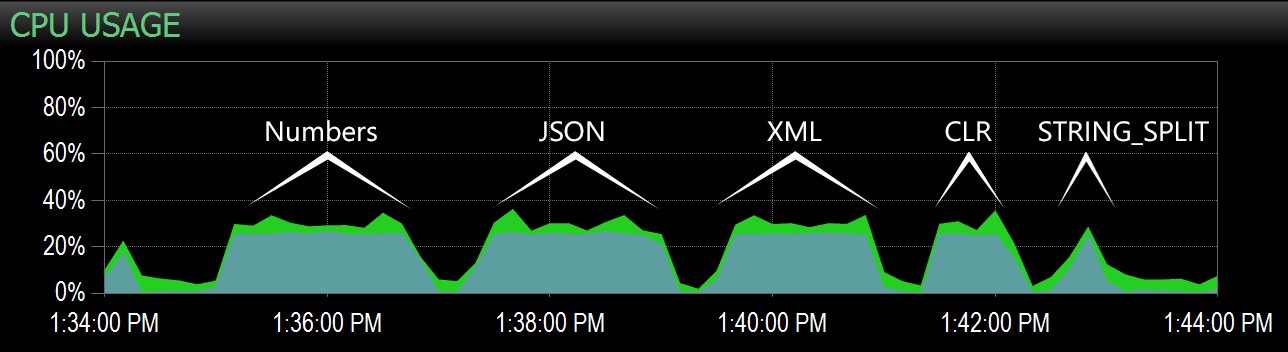 Batches vastgelegd in het CPU-diagram op het Performance Advisor-dashboard
Batches vastgelegd in het CPU-diagram op het Performance Advisor-dashboard
Het is duidelijk dat alle methoden *behalve* STRING_SPLIT gekoppeld aan een enkele kern voor de duur van de test (dit is een quad-core machine en de CPU bleef constant op 25%). Het is waarschijnlijk dat Lars insinueerde onder die STRING_SPLIT is sneller ten koste van de CPU, maar het lijkt erop dat dit niet het geval is.
Ten slotte kon ik bij de derde query de volgende wachtstatistieken zien die na elke batch werden gegenereerd:
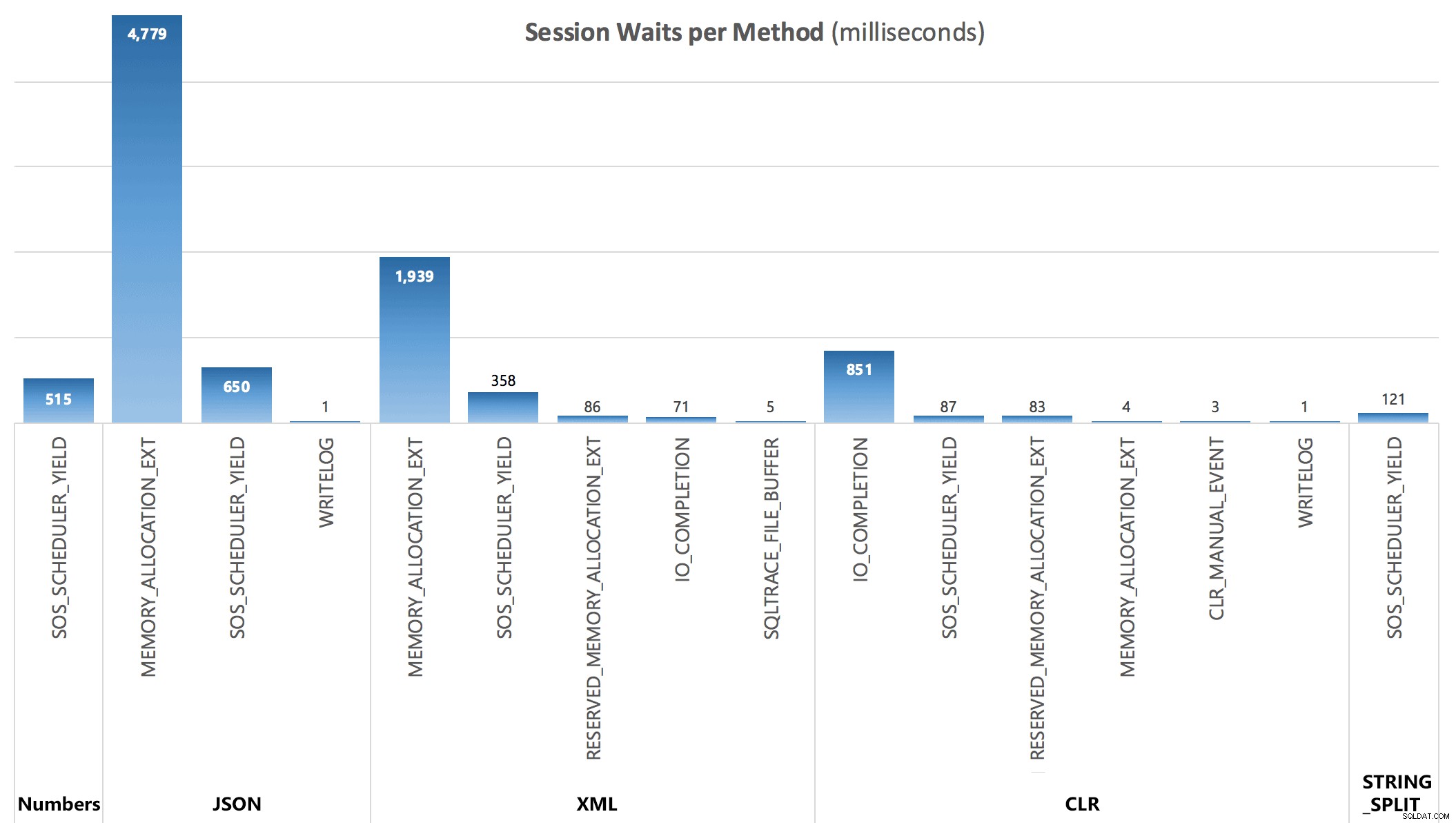 Wacht per sessie, in milliseconden
Wacht per sessie, in milliseconden
De wachttijden die door de DMV zijn vastgelegd, verklaren niet volledig de duur van de zoekopdrachten, maar ze dienen wel om te laten zien waar aanvullende wachttijden worden gemaakt.
Conclusie
Hoewel aangepaste CLR nog steeds een enorm voordeel biedt ten opzichte van traditionele T-SQL-benaderingen, en het gebruik van JSON voor deze functionaliteit niets meer dan een noviteit lijkt, STRING_SPLIT was de duidelijke winnaar - met een mijl. Dus, als je gewoon een string moet splitsen en alle beperkingen aankan, lijkt het erop dat dit een veel meer haalbare optie is dan ik had verwacht. Hopelijk zullen we in toekomstige builds extra functionaliteit zien, zoals een uitvoerkolom die de ordinale positie van elk element aangeeft, de mogelijkheid om duplicaten en lege tekenreeksen uit te filteren, en scheidingstekens voor meerdere tekens.
Ik behandel meerdere opmerkingen hieronder in twee vervolgberichten:
- STRING_SPLIT() in SQL Server 2016:follow-up #1
- STRING_SPLIT() in SQL Server 2016:vervolg #2