We maken allemaal fouten en we kunnen allemaal leren van de fouten van anderen. In dit bericht bekijken we tal van online bronnen om een slecht databaseontwerp te vermijden dat tot veel problemen kan leiden en zowel tijd als geld kost. En in een volgend artikel vertellen we je waar je tips en best practices kunt vinden.
Databaseontwerpfouten en te vermijden fouten
Er zijn talloze online bronnen om databaseontwerpers te helpen veelvoorkomende fouten en vergissingen te voorkomen. Het is duidelijk dat dit artikel geen uitputtende lijst is van elk artikel dat er is. In plaats daarvan hebben we verschillende bronnen bekeken en becommentarieerd, zodat u degene kunt vinden die het beste bij u past.
Onze aanbeveling
Als er slechts één artikel tussen deze bronnen is dat u gaat lezen, zou het moeten zijn:‘Hoe databaseontwerp vreselijk fout te krijgen’ van Robert Sheldon
Laten we beginnen met de DATAVERSITY-blog die een brede reeks redelijk goede bronnen biedt:
Fouten met primaire en externe sleutels die moeten worden vermeden
door Michael Blaha | DATAVERSITY blog | 2 september 2015
Meer database-ontwerpfouten – verwarring met veel-op-veel-relaties
door Michael Blaha | DATAVERSITY blog | 30 september 2015
Diverse database-ontwerpfouten
door Michael Blaha | DATAVERSITY blog | 26 oktober 2015
Michael Blaha heeft een mooie set van drie artikelen bijgedragen. Elk artikel behandelt verschillende valkuilen van databasemodellering en fysiek ontwerp; onderwerpen omvatten sleutels, relaties en algemene fouten. Daarnaast zijn er gesprekken met Michael over een aantal punten. Als je op zoek bent naar valkuilen rond sleutels en relaties, is dit een goede plek om te beginnen.
De heer Blaha stelt dat "ongeveer 20% van de databases de regels voor primaire sleutels overtreedt". Wauw! Dat betekent dat ongeveer 20% van de databaseontwikkelaars de primaire sleutels niet correct heeft gemaakt. Als deze statistiek waar is, toont het echt het belang aan van tools voor gegevensmodellering die modelbouwers sterk "aanmoedigen" of zelfs vereisen dat ze primaire sleutels definiëren.
De heer Blaha deelt ook de heuristiek dat "ongeveer 50% van de databases" buitenlandse sleutelproblemen heeft (volgens zijn ervaring met legacy-databases die hij heeft bestudeerd). Hij herinnert ons eraan om informele koppelingen tussen tabellen te vermijden door de waarde van de ene tabel in de andere in te bedden in plaats van een externe sleutel te gebruiken.
Ik heb dit probleem vaak gezien. Ik geef toe dat informele koppeling kan worden vereist door de te implementeren functionaliteit, maar vaker komt het voor door eenvoudige luiheid. We willen bijvoorbeeld de gebruikers-ID laten zien van iemand die iets heeft gewijzigd, dus we slaan de gebruikers-ID direct op in de tabel. Maar wat als die gebruiker zijn/haar gebruikers-ID verandert? Dan wordt deze informele band verbroken. Dit is vaak te wijten aan een slecht ontwerp en modellering.
Uw database ontwerpen:top 5 fouten die u moet vermijden
door Henrique Netzka | DATAVERSITY blog | 2 november 2015
Ik was een beetje teleurgesteld door dit artikel, omdat het een paar vrij specifieke items bevatte (protocol opslaan in een CLOB) en een paar zeer algemene (denk aan lokalisatie). Over het algemeen is het artikel prima, maar zijn dit echt de top 5 fouten die vermeden moeten worden? Naar mijn mening zijn er verschillende andere veelvoorkomende fouten die op de lijst zouden moeten staan.
Positief is echter dat dit een van de weinige artikelen is waarin globalisering en lokalisatie op een zinvolle manier worden genoemd. Ik werk in een zeer meertalige omgeving en heb verschillende vreselijke implementaties van lokalisatie gezien, dus ik was blij dat dit probleem werd genoemd. Taalkolommen en tijdzonekolommen lijken misschien voor de hand liggend, maar ze komen zelden voor in databasemodellen.
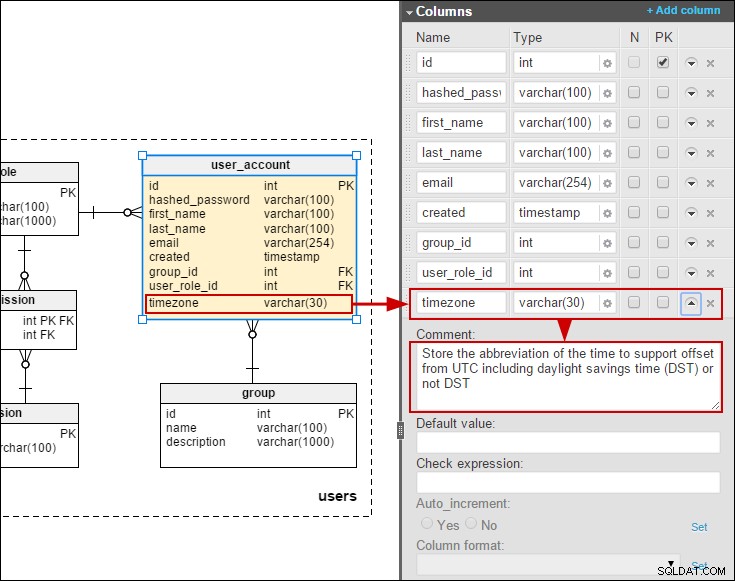
Dat gezegd hebbende, dacht ik dat het interessant zou zijn om een model te maken met vertalingen die door eindgebruikers kunnen worden gewijzigd (in tegenstelling tot het gebruik van bronnenbundels). Enige tijd geleden schreef ik over een model voor een online enquêtedatabase. Hier heb ik een vereenvoudigde vertaling van vragen en antwoordkeuzes gemaakt:
Ervan uitgaande dat we eindgebruikers moeten toestaan om de vertalingen te onderhouden, zou de voorkeursmethode zijn om vertaaltabellen toe te voegen voor vragen en antwoorden:
Ik heb ook een tijdzone toegevoegd aan het user_account tabel zodat we datums/tijden kunnen opslaan in de lokale tijd van de gebruikers:
7 veelvoorkomende fouten bij het ontwerpen van databases
door Grzegorz Kaczor | Verticale blog | 17 juli 2015
Ik zal hier een kleine zelfpromotie maken. We streven ernaar om hier regelmatig interessante en boeiende artikelen te plaatsen.
Dit specifieke artikel wijst op een aantal belangrijke aandachtspunten, zoals naamgeving, indexering, volumeoverwegingen en audittrails. Het artikel gaat zelfs in op problemen met betrekking tot specifieke DBM-systemen, zoals Oracle-beperkingen op tabelnamen. Ik hou echt van mooie duidelijke voorbeelden, ook al illustreren ze hoe ontwerpers fouten maken.
Uiteraard is het niet mogelijk om elke ontwerpfout op te sommen, en de vermelde fouten zijn mogelijk niet uw meest voorkomende fouten. Wanneer we schrijven over veelvoorkomende fouten, zijn het de fouten die we hebben gemaakt of gevonden in het werk van anderen waar we op voortbouwen. Een volledige lijst van fouten, gerangschikt naar frequentie, zou voor één persoon onmogelijk kunnen worden samengesteld. Toch denk ik dat dit artikel een aantal nuttige inzichten geeft over mogelijke valkuilen. Het is over het algemeen een mooie solide bron.
Hoewel de heer Kaczor verschillende interessante punten in zijn artikel aanhaalt, vond ik zijn opmerkingen over "geen rekening houden met mogelijk volume of verkeer" behoorlijk interessant. Met name de aanbeveling om veelgebruikte gegevens te scheiden van historische gegevens is bijzonder relevant. Dit is een oplossing die we vaak gebruiken in onze berichtentoepassingen; we moeten een doorzoekbare geschiedenis van alle berichten hebben, maar de berichten die het meest waarschijnlijk worden geopend, zijn de berichten die de afgelopen dagen zijn gepost. Dus het splitsen van "actieve" of recente gegevens die vaak worden geraadpleegd (een veel kleinere hoeveelheid gegevens) van historische gegevens op de lange termijn (de grote hoeveelheid gegevens) is over het algemeen een zeer goede techniek.
Veelvoorkomende fouten bij het ontwerpen van databases
door Troy Blake | Senior DBA-blog | 11 juli 2015
Het artikel van Troy Blake is een andere goede bron, hoewel ik dit artikel misschien heb hernoemd tot "Veelvoorkomende fouten bij het ontwerpen van SQL Server".
We hebben bijvoorbeeld de opmerking:“opgeslagen procedures zijn je beste vriend als het gaat om effectief gebruik van SQL Server”. Dat is prima, maar is dit een veel voorkomende algemene fout, of is het meer specifiek voor SQL Server? Ik zou ervoor moeten kiezen dat dit een beetje SQL Server-specifiek is, omdat er nadelen zijn aan het gebruik van opgeslagen procedures, zoals het eindigen met leverancierspecifieke opgeslagen procedures en dus vendor lock-in. Dus ik ben geen fan van het opnemen van "Geen opgeslagen procedures gebruiken" op deze lijst.
Aan de positieve kant denk ik echter dat de auteur enkele veelvoorkomende fouten identificeerde, zoals slechte planning, slordig systeemontwerp, beperkte documentatie, zwakke naamgevingsnormen en een gebrek aan tests.
Dus ik zou dit classificeren als een zeer nuttige referentie voor SQL Server-beoefenaars en een nuttige referentie voor anderen.
Zeven fouten bij het modelleren van gegevens
door Kurt Cagle | LinkedIn | 12 juni 2015
Ik heb echt genoten van het lezen van Mr. Cagle's lijst met fouten in het modelleren van databases. Deze zijn vanuit de kijk van een database-architect op de dingen; hij identificeert duidelijk modelleringsfouten op een hoger niveau die moeten worden vermeden. Met deze grotere afbeeldingsweergave kun je een mogelijke modellering-puinhoop afbreken.
Sommige van de typen die in het artikel worden genoemd, zijn elders te vinden, maar enkele daarvan zijn uniek:te vroeg abstract worden of conceptuele, logische en fysieke modellen door elkaar halen. Die worden niet vaak genoemd door andere auteurs, waarschijnlijk omdat ze zich richten op het gegevensmodelleringsproces in plaats van op het grotere systeemoverzicht.
Met name het voorbeeld van "Te vroeg abstract worden" beschrijft een interessant denkproces van het creëren van enkele voorbeeld"verhalen" en het testen welke relaties belangrijk zijn in dit domein. Dit richt het denken op de relaties tussen de objecten die worden gemodelleerd. Het resulteert in vragen als wat zijn de belangrijke relaties in dit domein ?
Op basis van dit inzicht creëren we het model rond relaties in plaats van te beginnen bij individuele domeinitems en de relaties daarop te bouwen. Hoewel velen van ons deze benadering zouden kunnen gebruiken, heeft geen enkele andere auteur er commentaar op gegeven. Ik vond deze beschrijving en de voorbeelden best interessant.
Hoe database-ontwerp verschrikkelijk verkeerd te krijgen
door Robert Sheldon | Eenvoudig praten | 6 maart 2015
Als er maar één artikel tussen deze bronnen is dat u gaat lezen, dan zou het dit artikel van Robert Sheldon moeten zijn
Wat ik erg leuk vind aan dit artikel, is dat er voor elk van de genoemde fouten tips zijn om het goed te doen. De meeste van deze zijn gericht op het vermijden van de fout in plaats van deze te corrigeren, maar ik denk nog steeds dat ze erg nuttig zijn. Er is hier heel weinig theorie; meestal directe antwoorden over het vermijden van fouten tijdens het modelleren van gegevens. Er zijn een paar specifieke SQL Server-punten, maar meestal wordt SQL Server gebruikt om voorbeelden te geven van het vermijden van fouten of manieren om fouten te voorkomen.
De reikwijdte van het artikel is ook vrij breed:het heeft betrekking op het nalaten om te plannen, zich niet bezig te houden met documentatie, waardeloze naamgevingsconventies te gebruiken, problemen te hebben met normalisatie (te veel of te weinig), falen op sleutels en beperkingen, niet goed indexeren en presteren onvoldoende testen.
Ik vond vooral het praktische advies met betrekking tot gegevensintegriteit prettig:wanneer moet u controlebeperkingen gebruiken en wanneer u externe sleutels moet definiëren. Daarnaast beschrijft de heer Sheldon ook de situatie waarin teams de aanvraag uitstellen om integriteit af te dwingen. Hij is recht door zee als hij stelt dat een database op meerdere manieren en door tal van toepassingen kan worden benaderd. Hij concludeert dat "gegevens moeten worden beschermd waar ze zich bevinden:in de database". Dit is zo waar dat het kan worden herhaald aan ontwikkelteams en managers om het belang van het implementeren van integriteitscontroles in het datamodel uit te leggen.
Dit is mijn soort artikel, en je kunt zien dat anderen het ermee eens zijn op basis van de vele commentaren die het onderschrijven. Dus toppunten hier; het is een zeer waardevolle hulpbron.
Tien veelvoorkomende fouten bij het ontwerpen van databases
door Louis Davidson | Eenvoudig praten | 26 februari 2007
Ik vond dit artikel best goed, omdat het veel veelvoorkomende ontwerpfouten bevatte. Er waren betekenisvolle analogieën, voorbeelden, modellen en zelfs enkele klassieke citaten van William Shakespeare en J.R.R. Tolkien.
Een paar fouten werden in meer detail uitgelegd dan andere, met lange voorbeelden en SQL-fragmenten die ik een beetje omslachtig vond. Maar dat is een kwestie van smaak.
Nogmaals, we hebben een paar onderwerpen die specifiek zijn voor SQL Server. Het punt van het niet gebruiken van Stored Procedures om toegang te krijgen tot gegevens is bijvoorbeeld goed voor SQL, maar SP's zijn niet altijd een goed idee als het doel is ondersteuning op meerdere DBMS'en. Bovendien worden we gewaarschuwd tegen het proberen om generieke T-SQL-objecten te coderen. Aangezien ik zelden met SQL Server of Sybase werk, vond ik deze tip niet relevant.
De lijst lijkt veel op die van Robert Sheldon, maar als je voornamelijk met SQL Server werkt, zul je een paar extra stukjes informatie vinden.
Vijf eenvoudige database-ontwerpfouten die u moet vermijden
door Anith Sen Larson | Eenvoudig praten | 16 oktober 2009
Dit artikel geeft enkele zinvolle voorbeelden voor elk van de eenvoudige ontwerpfouten die het behandelt. Aan de andere kant is het eerder gericht op vergelijkbare soorten fouten:algemene opzoektabellen, entiteit-attribuut-waardetabellen en attribuutsplitsing.
De observaties zijn prima, en het artikel heeft zelfs verwijzingen, die meestal zeldzaam zijn. Toch zou ik graag meer algemene fouten in het databaseontwerp zien. Deze fouten leken nogal specifiek, maar, zoals ik al heb geschreven, zijn de fouten waar we over schrijven over het algemeen de fouten waarmee we persoonlijke ervaring hebben.
Een item dat ik wel leuk vond, was een specifieke vuistregel om te beslissen wanneer een controlebeperking moet worden gebruikt in plaats van een afzonderlijke tabel met een externe sleutelbeperking. Verschillende auteurs doen soortgelijke aanbevelingen, maar de heer Larson splitst ze op in "moeten", "overwegen" en "sterke argumenten" - met de erkenning dat "design een mix is van kunst en wetenschap en daarom moeten er afwegingen worden gemaakt". Ik vind dit heel waar.
Top tien meest voorkomende fouten bij het ontwerpen van fysieke databases
door Craig Mullins | Gegevens en technologie vandaag | 5 augustus 2013
Zoals de naam al aangeeft, is de "Top tien meest voorkomende fouten bij het ontwerpen van fysieke databases" iets meer gericht op fysiek ontwerp dan op logisch en conceptueel ontwerp. Geen van de fouten die auteur Craig Mullins noemt, valt echt op of is uniek, dus ik zou deze informatie aanraden aan mensen die aan de fysieke DBA-kant werken.
Bovendien zijn de beschrijvingen wat kort, waardoor het soms moeilijk is in te zien waarom een bepaalde fout voor problemen gaat zorgen. Er is op zich niets mis met korte beschrijvingen, maar ze geven je niet veel om over na te denken. En er worden geen voorbeelden gegeven.
Er is een interessant punt naar voren gebracht met betrekking tot het niet delen van gegevens. Dit punt wordt wel eens genoemd in andere artikelen, maar niet als een ontwerpfout. Ik zie dit probleem echter vrij vaak met databases die worden "opnieuw gemaakt" op basis van zeer vergelijkbare vereisten, maar door een nieuw team of voor een nieuw product
.Het komt vaak voor dat het productteam zich later realiseert dat ze graag data hadden willen gebruiken die al aanwezig waren in de “vader” van hun huidige database. In feite hadden ze echter de ouder moeten verbeteren in plaats van een nieuw nageslacht te creëren. Applicaties zijn bedoeld om gegevens te delen; met een goed ontwerp kan een database vaker worden hergebruikt.
Maakt u deze 5 fouten bij het ontwerpen van databases?
door Thomas Larock | Thomas Larock's blog | 2 januari 2012
Misschien kom je een paar interessante punten tegen bij het beantwoorden van de vraag van Thomas Larock:Do You Make This 5 Database Design Mistakes?
Dit artikel is enigszins zwaar gewogen voor sleutels (buitenlandse sleutels, surrogaatsleutels en gegenereerde sleutels). Toch heeft het één belangrijk punt:men moet er niet vanuit gaan dat DBMS-functies op alle systemen hetzelfde zijn. Ik denk dat dit een heel goed punt is. Het is er ook een die niet in de meeste andere artikelen voorkomt, misschien omdat veel auteurs zich concentreren op en voornamelijk werken met een enkel DBMS.
Een database ontwerpen:7 dingen die u niet wilt doen
door Thomas Larock | Thomas Larock's blog | 16 januari 2013
De heer Larock recycleerde een paar van zijn "5 Database Design Mistakes" bij het schrijven van "7 Things You Don't Want To Do", maar er zijn andere goede punten hier.
Interessant is dat sommige van de punten die de heer Larock maakt niet in veel andere bronnen te vinden zijn. Je krijgt wel een paar vrij unieke observaties, zoals "geen prestatieverwachtingen hebben". Dit is een ernstige fout en een die, op basis van mijn ervaring, vrij vaak voorkomt. Zelfs bij het ontwikkelen van de applicatiecode is het vaak nadat het datamodel, de database en de applicatie zelf zijn gemaakt dat mensen gaan nadenken over de niet-functionele vereisten (wanneer niet-functionele tests moeten worden gemaakt) en beginnen met het definiëren van prestatieverwachtingen .
Omgekeerd zijn er een paar punten die ik niet in mijn eigen Top Tien-lijst zou opnemen, zoals "groot worden, voor het geval dat". Ik begrijp het punt, maar het staat niet zo hoog op mijn lijst bij het maken van een datamodel. Er is geen specificiteit voor een bepaald DBM-systeem, dus dat is een bonus.
Tot slot, veel van deze punten kunnen worden samengevat onder het punt:"de vereisten niet begrijpen", wat echt in mijn Top 10 foutenlijst staat.
Hoe 8 veelvoorkomende fouten in databaseontwikkeling te vermijden
door Base36 | 6 december 2012
Ik was erg geïnteresseerd in het lezen van dit artikel. Ik was echter een beetje teleurgesteld. Er is niet veel discussie over vermijding, en het punt van het artikel lijkt echt te zijn "dit zijn veelvoorkomende databasefouten" en "waarom het fouten zijn"; beschrijvingen van hoe de fout te vermijden zijn minder prominent.
Bovendien worden sommige van de Top 8-fouten van het artikel betwist. Misbruik van de primaire sleutel is een voorbeeld. Base36 vertelt ons dat ze door het systeem moeten worden gegenereerd en niet op basis van applicatiegegevens in de rij. Hoewel ik het hier tot op zekere hoogte mee eens ben, ben ik er niet van overtuigd dat alle PK's moeten altijd worden gegenereerd; dat is een beetje te categorisch.
Aan de andere kant is de fout van "Hard Deletes" interessant en wordt deze elders niet vaak genoemd. Zachte verwijderingen veroorzaken andere problemen, maar het is waar dat het eenvoudigweg markeren van een rij als inactief zijn voordelen heeft wanneer u probeert te achterhalen waar die gegevens zijn gebleven die zich gisteren in het systeem bevonden. Het doorzoeken van transactielogboeken is niet mijn idee van een plezierige manier om een dag door te brengen.
Zeven hoofdzonden van database-ontwerp
door Jason Tiret | Enterprise Systems Journal | 16 februari 2010
Ik was behoorlijk hoopvol toen ik het artikel van Jason Tiret, "Seven Deadly Sins of Database Design" begon te lezen. Dus ik was blij te ontdekken dat het niet alleen fouten recycleerde die in tal van andere artikelen worden aangetroffen. Integendeel, het bood een "zonde" die ik niet in andere lijsten had gevonden:proberen om al het databaseontwerp "vooraf" uit te voeren en het model niet bij te werken nadat de database in productie is, wanneer er wijzigingen in de database worden aangebracht. (Of, zoals Jason het zegt:"Het datamodel niet behandelen als een levend, ademend organisme").
Ik heb deze fout vele malen gezien. De meeste mensen beseffen hun fout pas wanneer ze updates moeten maken aan een model dat niet langer overeenkomt met de eigenlijke database. Het resultaat is natuurlijk een nutteloos model. Zoals het artikel stelt:"de veranderingen moeten hun weg terug vinden naar het model."
Aan de andere kant zijn de meeste items op de lijst van Jason vrij goed bekend. De beschrijvingen zijn goed, maar er zijn niet veel voorbeelden. Meer voorbeelden en details zouden nuttig zijn.
De meest voorkomende fouten bij het ontwerpen van databases
door Brian Prince | eWeek.com | 19 maart 2008

Het artikel "De meest voorkomende fouten bij het ontwerpen van databases" is eigenlijk een reeks dia's uit een presentatie. Er zijn een paar interessante gedachten, maar sommige van de unieke items zijn misschien een beetje esoterisch. Ik denk aan punten als "Maak kennis met RAID" en betrokkenheid van belanghebbenden.
Over het algemeen zou ik dit niet op je leeslijst zetten, tenzij je gefocust bent op algemene zaken (planning, naamgeving, normalisatie, indexen) en fysieke details.
10 veelvoorkomende ontwerpfouten
door davidm | SQL Server-blogs – SQLTeam.com | 12 september 2005
Sommige punten in "Tien veelvoorkomende ontwerpfouten" zijn interessant en relatief nieuw. Sommige van deze fouten zijn echter nogal controversieel, zoals het "gebruiken van NULL's" en het de-normaliseren.
Ik ben het ermee eens dat het een vergissing is om alle kolommen als nullable te maken, maar het definiëren van een kolom als nullable kan vereist zijn voor een bepaalde bedrijfsfunctie. Kan het daarom worden beschouwd als een algemene fout? Ik denk het niet.
Een ander punt waar ik moeite mee heb, is de-normalisatie. Dit is niet altijd een ontwerpfout. De-normalisatie kan bijvoorbeeld nodig zijn om prestatieredenen.
Dit artikel ontbreekt ook grotendeels aan details en voorbeelden. De gesprekken tussen DBA en programmeur of manager zijn grappig, maar ik had liever concretere voorbeelden en gedetailleerde rechtvaardigingen voor deze veelgemaakte fouten gezien.
OTLT en EAV:de twee grote ontwerpfouten die alle beginners maken
door Tony Andrews | Tony Andrews over Oracle en databases | 21 oktober 2004
Het artikel van de heer Andrews herinnert ons aan de fouten "One True Lookup Table" (OTLT) en Entity-Attribute-Value (EAV) die in andere artikelen worden genoemd. Een leuk punt van deze presentatie is dat deze zich richt op deze twee fouten, dus beschrijvingen en voorbeelden zijn nauwkeurig. Daarnaast wordt een mogelijke verklaring gegeven waarom sommige ontwerpers OTLT en EAV implementeren.
Ter herinnering:de OTLT-tabel ziet er meestal ongeveer zo uit, met vermeldingen van meerdere domeinen in dezelfde tabel:
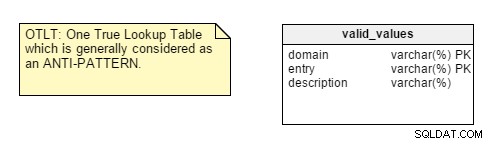
Zoals gebruikelijk is er discussie of OTLT een werkbare oplossing en een goed ontwerppatroon is. Ik moet zeggen dat ik aan de kant sta van de anti-OTLT-groep; deze tabellen introduceren tal van problemen. We zouden de analogie kunnen gebruiken van het gebruik van een enkele enumerator om alle mogelijke waarden van alle mogelijke constanten weer te geven. Dat heb ik tot nu toe nog nooit gezien.
Veelvoorkomende databasefouten
door John Paul Ashenfelter | Dr. Dobb's | 01 januari 2002
Het artikel van de heer Ashenfelter somt maar liefst 15 veelvoorkomende databasefouten op. Er zijn zelfs een paar fouten die niet vaak worden genoemd in andere artikelen. Helaas zijn de beschrijvingen relatief kort en zijn er geen voorbeelden. De verdienste van dit artikel is dat de lijst veel terrein beslaat en kan worden gebruikt als een "checklist" van fouten die moeten worden vermeden. Hoewel ik deze misschien niet als de belangrijkste databasefouten classificeer, behoren ze zeker tot de meest voorkomende.
Positief is dat dit een van de weinige artikelen is die de noodzaak noemt om de internationalisering van formaten voor gegevens zoals datum, valuta en adres aan te pakken. Een voorbeeld zou hier leuk zijn. Het zou zo simpel kunnen zijn als "zorg ervoor dat de staat een kolom is met een nulwaarde; in veel landen is er geen staat gekoppeld aan een adres”.
Eerder in dit artikel noemde ik andere zorgen en enkele benaderingen om voor te bereiden op globalisering van uw database, zoals tijdzones en vertalingen (lokalisatie). Het feit dat geen enkel ander artikel de bezorgdheid over valuta- en datumnotaties vermeldt, is verontrustend. Zijn onze databases voorbereid op het wereldwijde gebruik van onze applicaties?
Eervolle vermeldingen
Uiteraard zijn er andere artikelen die veelvoorkomende fouten en fouten bij het ontwerpen van databases beschrijven, maar we wilden u een breed overzicht geven van verschillende bronnen. U kunt aanvullende informatie vinden in artikelen zoals:
10 veelvoorkomende fouten bij het ontwerpen van databases | MIS Klas Blog | 29 januari 2012
10 veelvoorkomende fouten bij het ontwerpen van databases | IDG.se | 24 juni 2010
Online bronnen:waar te beginnen? Waar te gaan?
Zoals eerder vermeld, is deze lijst zeker niet bedoeld als een uitputtend onderzoek van elk online artikel waarin fouten en fouten in het databaseontwerp worden beschreven. In plaats daarvan hebben we verschillende bronnen geïdentificeerd die bijzonder nuttig zijn of een specifieke focus hebben die u misschien nuttig vindt.
Voel je vrij om aanvullende artikelen aan te bevelen.