Het hebben van referentietabellen in uw database is geen probleem, toch? U hoeft alleen maar een code of ID te koppelen aan een beschrijving voor elk referentietype. Maar wat als je letterlijk tientallen en tientallen referentietabellen hebt? Is er een alternatief voor de benadering van één tafel per type? Lees verder om een algemeen en uitbreidbaar . te ontdekken database-ontwerp voor het verwerken van al uw referentiegegevens.
Dit ongebruikelijk ogende diagram is een overzicht in vogelvlucht van een logisch datamodel (LDM) dat alle referentietypen voor een bedrijfssysteem bevat. Het is van een onderwijsinstelling, maar het kan van toepassing zijn op het datamodel van elk soort organisatie. Hoe groter het model, hoe meer referentietypes je waarschijnlijk zult ontdekken.
Met referentietypes bedoel ik referentiegegevens, of opzoekwaarden, of – als je flash wilt zijn – taxonomieën . Meestal worden de hier gedefinieerde waarden gebruikt in vervolgkeuzelijsten in de gebruikersinterface van uw toepassing. Ze kunnen ook als koppen in een rapport worden weergegeven.
Dit specifieke datamodel had ongeveer 100 referentietypes. Laten we inzoomen en er slechts twee bekijken.
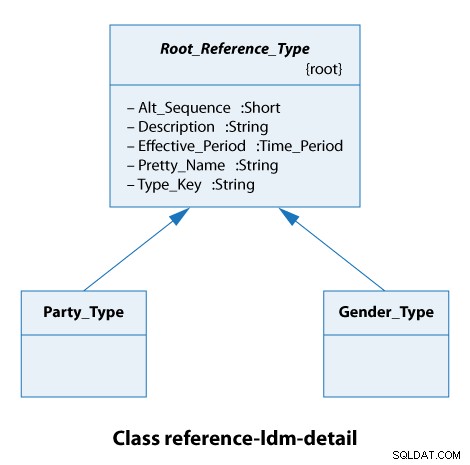
Uit dit klassendiagram zien we dat alle referentietypes het Root_Reference_Type . In de praktijk betekent dit alleen dat al onze referentietypes dezelfde attributen hebben van Alt_Sequence door naar Type_Key inclusief, zoals hieronder weergegeven.
| Kenmerk | Beschrijving |
|---|---|
Alt_Sequence | Gebruikt om een alternatieve volgorde te definiëren wanneer een niet-alfabetische volgorde vereist is. |
Description | De beschrijving van het type. |
Effective_Period | Definieert effectief of de referentie-invoer al dan niet is ingeschakeld. Als een verwijzing eenmaal is gebruikt, kan deze niet worden verwijderd vanwege verwijzingsbeperkingen; het kan alleen worden uitgeschakeld. |
| De mooie naam voor het type. Dit is wat de gebruiker op het scherm ziet. |
Type_Key | De unieke interne SLEUTEL voor het type. Dit is verborgen voor de gebruiker, maar applicatieontwikkelaars kunnen hier uitgebreid gebruik van maken in hun SQL. |
Het type feest is hier een organisatie of een persoon. De soorten geslacht zijn mannelijk en vrouwelijk. Dit zijn dus heel eenvoudige gevallen.
De traditionele oplossing voor referentietabellen
Dus hoe gaan we het logische model implementeren in de fysieke wereld van een echte database?
We zouden van mening kunnen zijn dat elk referentietype naar zijn eigen tabel wordt toegewezen. Je zou dit de meer traditionele één-tafel-per-klasse . kunnen noemen oplossing. Het is eenvoudig genoeg en zou er ongeveer zo uitzien:
De keerzijde hiervan is dat er tientallen en tientallen van deze tabellen kunnen zijn, allemaal met dezelfde kolommen, die allemaal ongeveer hetzelfde doen.
Bovendien mogelijk creëren we nog veel meer ontwikkelingswerk . Als beheerders voor elk type een gebruikersinterface nodig hebben om de waarden te behouden, neemt de hoeveelheid werk snel toe. Hier zijn geen vaste regels voor - het hangt echt af van uw ontwikkelomgeving - dus u zult met uw ontwikkelaars moeten praten om te begrijpen welke impact dit heeft.
Maar gezien het feit dat al onze referentietypen dezelfde attributen of kolommen hebben, is er dan een meer generieke manier om ons logische datamodel te implementeren? Ja dat is er! En het vereist slechts twee tabellen .
De oplossing voor twee tafels
De eerste discussie die ik ooit over dit onderwerp had, was halverwege de jaren 90, toen ik voor een verzekeringsmaatschappij in London Market werkte. Destijds gingen we rechtstreeks naar fysiek ontwerp en gebruikten we meestal natuurlijke/zakelijke sleutels, geen ID's. Waar referentiegegevens bestonden, besloten we om één tabel per type te behouden die was samengesteld uit een unieke code (de VARCHAR PK) en een beschrijving. In feite waren er toen veel minder referentietabellen. Vaker wel dan niet, zou een beperkte reeks bedrijfscodes in een kolom worden gebruikt, mogelijk met een gedefinieerde databasecontrolebeperking; er zou helemaal geen referentietabel zijn.
Maar sindsdien is het spel verder gegaan. Dit is wat een oplossing met twee tabellen zou er als volgt uit kunnen zien:
Zoals u kunt zien, is dit fysieke datamodel heel eenvoudig. Maar het is heel anders dan het logische model, en niet omdat er iets helemaal peervormig is geworden. Dat komt omdat er een aantal dingen zijn gedaan als onderdeel van fysiek ontwerp .
Het reference_type tabel vertegenwoordigt elke individuele referentieklasse uit de LDM. Dus als je 20 referentietypes in je LDM hebt, heb je 20 rijen metadata in de tabel. De reference_value tabel bevat de toegestane waarden voor alle de referentietypes.
Ten tijde van dit project waren er behoorlijk levendige discussies tussen ontwikkelaars. Sommigen gaven de voorkeur aan de oplossing met twee tafels en anderen gaven de voorkeur aan één-tafel-per-type methode.
Er zijn voor- en nadelen voor elke oplossing. Zoals je zou kunnen raden, waren de ontwikkelaars vooral bezorgd over de hoeveelheid werk die de gebruikersinterface zou vergen. Sommigen dachten dat het vrij snel zou zijn om voor elke tafel een beheerdersinterface samen te stellen. Anderen dachten dat het bouwen van een enkele gebruikersinterface voor beheerders complexer zou zijn, maar uiteindelijk de moeite waard zou zijn.
Bij dit specifieke project kreeg de tweetafeloplossing de voorkeur. Laten we het in meer detail bekijken.
Het uitbreidbare en flexibele referentiegegevenspatroon
Aangezien uw gegevensmodel in de loop van de tijd evolueert en er nieuwe referentietypen nodig zijn, hoeft u niet steeds wijzigingen in uw database aan te brengen voor elk nieuw referentietype. U hoeft alleen nieuwe configuratiegegevens te definiëren. Om dit te doen, voegt u een nieuwe rij toe aan het reference_type tabel en voeg de gecontroleerde lijst met toegestane waarden toe aan de reference_value tafel.
Een belangrijk concept in deze oplossing is het definiëren van effectieve tijdsperioden voor bepaalde waarden. Uw organisatie moet bijvoorbeeld mogelijk een nieuwe reference_value van 'Bewijs van ID' dat op een toekomstige datum acceptabel zal zijn. Het is een kwestie van die nieuwe reference_value met de effective_period_from datum correct ingesteld. Dit kan vooraf. Tot die datum aanbreekt, zal het nieuwe item niet verschijnen in de vervolgkeuzelijst met waarden die gebruikers van uw toepassing zien. Dit komt omdat uw applicatie alleen waarden weergeeft die actueel of ingeschakeld zijn.
Aan de andere kant moet u mogelijk voorkomen dat gebruikers een bepaalde reference_value . Werk het in dat geval gewoon bij met de effective_period_to datum correct ingesteld. Als die dag voorbij is, verschijnt de waarde niet meer in de vervolgkeuzelijst. Vanaf dat moment wordt het uitgeschakeld. Maar omdat het fysiek nog steeds als een rij in de tabel bestaat, blijft referentie-integriteit behouden voor die tabellen waar er al naar verwezen is.
Nu we aan de oplossing met twee tabellen werkten, werd het duidelijk dat enkele extra kolommen nuttig zouden zijn voor het reference_type tafel. Deze waren voornamelijk gericht op problemen met de gebruikersinterface.
Bijvoorbeeld pretty_name op de reference_type tabel is toegevoegd voor gebruik in de gebruikersinterface. Voor grote taxonomieën is het handig om een venster met zoekfunctie te gebruiken. Dan pretty_name kan worden gebruikt voor de titel van het venster.
Aan de andere kant, als een vervolgkeuzelijst met waarden voldoende is, pretty_name kan worden gebruikt voor de LOV-prompt. Op een vergelijkbare manier zou een beschrijving in de gebruikersinterface kunnen worden gebruikt om roll-over-help in te vullen.
Als u kijkt naar het type configuratie of metagegevens dat in deze tabellen wordt opgenomen, zal dit de zaken een beetje verduidelijken.
Hoe je dat allemaal beheert
Hoewel het hier gebruikte voorbeeld heel eenvoudig is, kunnen de referentiewaarden voor een groot project snel behoorlijk complex worden. Het kan dus raadzaam zijn om dit allemaal in een spreadsheet bij te houden. Als dat het geval is, kunt u de spreadsheet zelf gebruiken om de SQL te genereren met behulp van tekenreeksaaneenschakeling. Dit wordt in scripts geplakt, die worden uitgevoerd tegen de doeldatabases die de ontwikkelingslevenscyclus en de productie (live) database ondersteunen. Dit geeft de database alle benodigde referentiegegevens.
Hier zijn de configuratiegegevens voor de twee LDM-typen, Gender_Type en Party_Type :
PROMPT Gender_TypeINSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Gender Type', 'GENDER_TYPE', ' Identificeert het geslacht van een persoon.', 13000000, 13999999); INSERT INTO reference_value (id, mooie_naam, beschrijving, effectieve_periode_van, alt_sequence, reference_type_id) VALUES (13000010,'Female', 'Female', TRUNC(SYSDATE), 10, rety_seq.currval);INSERT INTO reference_value (id, mooie_naam, beschrijving, effectieve_period_from, alt_sequence, reference_type_id) VALUES (13000020,'Male', 'Male', TRUNC(SYSDATE), 20, rety_seq.currval);PROMPT Party_TypeINSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_to, id_range_from, id_range_from) .nextval, 'Party Type', 'PARTY_TYPE', Een gecontroleerde lijst met referentiewaarden die het type party identificeert.', 23000000, 23999999);INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUE S (23000010,'Organisatie', 'Organisatie', TRUNC(SYSDATE), 10, rety_seq.currval);INSERT INTO reference_value (id, mooie_naam, beschrijving, effectieve_periode_from, alt_sequence, reference_type_id) VALUES (23000020,'Persoon', 'Persoon ', TRUNC(SYSDATE), 20, rety_seq.currval);
Er staat een rij in reference_type voor elk LDM-subtype van Root_Reference_Type . De beschrijving in reference_type is overgenomen uit de LDM-klassebeschrijving. Voor Gender_Type , zou dit lezen "Identificeert het geslacht van een persoon". De DML-fragmenten tonen de verschillen in beschrijvingen tussen type en waarde, die kunnen worden gebruikt in de gebruikersinterface of in rapporten.
Je zult zien dat reference_type genaamd Gender_Type heeft een bereik van 13000000 tot 13999999 toegewezen gekregen voor de bijbehorende reference_value.ids . In dit model wordt elk reference_type krijgt een unieke, niet-overlappende reeks ID's toegewezen. Dit is niet strikt noodzakelijk, maar het stelt ons in staat om gerelateerde waarde-ID's te groeperen. Het bootst een beetje na wat je zou krijgen als je aparte tafels had. Het is leuk om te hebben, maar als je denkt dat dit geen voordeel heeft, kun je het achterwege laten.
Een andere kolom die aan de PDM is toegevoegd, is admin_role . Dit is waarom.
Wie zijn de beheerders
Bij sommige taxonomieën kunnen waarden worden toegevoegd of verwijderd met weinig of geen impact. Dit gebeurt wanneer geen programma's gebruik maken van de waarden in hun logica, of wanneer het type niet is gekoppeld aan andere systemen. In dergelijke gevallen is het veilig voor gebruikersbeheerders om deze up-to-date te houden.
Maar in andere gevallen is veel meer zorg nodig. Een nieuwe referentiewaarde kan onbedoelde gevolgen hebben voor de programmalogica of voor downstream-systemen.
Stel dat we bijvoorbeeld het volgende toevoegen aan de geslachtstype-taxonomie:
INSERT INTO reference_value (id, pretty_name, description, Effective_period_from, alt_sequence, reference_type_id) VALUES (13000040,'Niet bekend', 'Geslacht is niet vastgelegd. Omvat het geslacht van het ongeboren kind, wanneer iemand heeft geweigerd de vraag te beantwoorden of wanneer de vraag niet is gesteld.', TRUNC(SYSDATE), 30, (SELECT id FROM reference_type WHERE ref_type_key ='GENDER_TYPE'));
Dit wordt al snel een probleem als we ergens de volgende logica hebben ingebouwd:
IF ref_key ='MALE' THEN RETURN 'M';ELSE RETURN 'F';END IF;
Het is duidelijk dat de logica "als je niet man bent, moet je vrouw zijn" niet langer van toepassing is in de uitgebreide taxonomie.
Dit is waar de admin_role kolom in het spel komt. Het is ontstaan uit discussies met de ontwikkelaars over het fysieke ontwerp en het werkte in combinatie met hun UI-oplossing. Maar als de één-tabel-per-klasse-oplossing was gekozen, dan zou reference_type niet zou hebben bestaan. De metagegevens die het bevatte zouden hard gecodeerd zijn in de applicatie Gender_Type table – , die niet flexibel of uitbreidbaar is.
Alleen gebruikers met de juiste rechten kunnen de taxonomie beheren. Dit is waarschijnlijk gebaseerd op inhoudelijke expertise (MKB ). Aan de andere kant moeten sommige taxonomieën mogelijk door IT worden beheerd om impactanalyse en grondige tests mogelijk te maken en om eventuele codewijzigingen harmonieus op tijd voor de nieuwe configuratie vrij te geven. (Of dit gebeurt door wijzigingsverzoeken of op een andere manier is aan uw organisatie.)
Je hebt misschien opgemerkt dat de controlekolommen created_by , created_date , updated_by , en updated_date er wordt in het bovenstaande script helemaal niet naar verwezen. Nogmaals, als u hier niet in geïnteresseerd bent, hoeft u ze niet te gebruiken. Deze specifieke organisatie had een standaard die verplichtte om op elke tafel controlekolommen te hebben.
Triggers:dingen consistent houden
Triggers zorgen ervoor dat deze controlekolommen consistent worden bijgewerkt, ongeacht de bron van de SQL (scripts, uw toepassing, geplande batchupdates, ad-hocupdates, enz.).
Mijn achtergrond is voornamelijk Oracle en helaas beperkt Oracle identifiers tot 30 bytes. Om overschrijding hiervan te voorkomen, krijgt elke tabel een korte alias van drie tot vijf tekens en gebruiken andere tabelgerelateerde artefacten die alias in hun naam. Dus, reference_value ’s alias is reva – de eerste twee tekens van elk woord. Vóór rij invoegen en voordat rij-update wordt afgekort tot bri en bru respectievelijk. De reeksnaam reva_seq , enzovoort.
Handmatige coderingstriggers zoals deze, tafel na tafel, vereisen veel demoraliserend ketelplaatwerk voor ontwikkelaars. Gelukkig kunnen deze triggers worden aangemaakt via codegeneratie , maar dat is het onderwerp van een ander artikel!
Het belang van sleutels
De ref_type_key en type_key kolommen zijn beide beperkt tot 30 bytes. Hierdoor kunnen ze worden gebruikt in SQL-query's van het PIVOT-type (in Oracle. Andere databases hebben mogelijk niet dezelfde id-lengtebeperking).
Omdat de uniekheid van de sleutel wordt gegarandeerd door de database en de trigger ervoor zorgt dat de waarde ervan voor altijd hetzelfde blijft, kunnen en moeten deze sleutels worden gebruikt in query's en code om ze leesbaarder te maken . Wat bedoel ik hiermee? Nou, in plaats van:
SELECTEER … VAN …INNER JOIN …WAAR reference_value.id =13000020
Je schrijft:
SELECTEER … VAN …INNER JOIN …WAAR reference_value.type_key ='MANNET'
Kortom, de sleutel geeft duidelijk weer wat de zoekopdracht doet .
Van LDM naar PDM, met Room to Grow
De reis van LDM naar PDM is niet per se een rechte weg. Het is ook geen directe transformatie van de een naar de ander. Het is een afzonderlijk proces dat zijn eigen overwegingen en zijn eigen zorgen introduceert.
Hoe modelleer je de referentiegegevens in je database?