FILESTREAM is in 2008 door Microsoft geïntroduceerd. Het doel was om ongestructureerde bestanden effectiever op te slaan en te beheren. Voordat FILESTREAM werd geïntroduceerd, werden de volgende benaderingen gebruikt om de gegevens op de SQL-server op te slaan:
- Ongestructureerde bestanden kunnen worden opgeslagen in de VARBINARY- of IMAGE-kolom van een SQL Server-tabel. Deze aanpak is effectief om de transactieconsistentie te behouden en vermindert de complexiteit van bestandsbeheer, maar wanneer de clienttoepassing gegevens uit de SQL-tabel leest, gebruikt deze SQL-geheugen, wat leidt tot slechte prestaties.
- Sla de fysieke locatie van het ongestructureerde bestand op in de SQL-tabel in plaats van het hele bestand op te slaan in de SQL-tabel. Deze aanpak geeft een enorme prestatieverbetering, maar het garandeert niet de transactieconsistentie, bovendien was bestandsbeheer ook moeilijk.
De FILESTREAM-functie is zeer effectief omdat het BLOB-bestanden in het NT-bestandssysteem kan opslaan en de transactieconsistentie handhaaft. Wanneer een clienttoepassing gegevens uit de FILESTREAM-container leest, in plaats van het geheugen van de SQL Server-buffer te gebruiken, gebruikt deze Nthe T-systeemcache die de prestaties verbetert.
FILESTREAM is geen gegevenstype. Het is een attribuut dat kan worden toegewezen aan de kolom VARBINARY(MAX). Wanneer de VARBINARY(MAX)-kolom is toegewezen aan het FILESTREAM-attribuut, wordt dit een FILESTREAM-kolom genoemd. Gegevens die in de FILESTREAM-kolom zijn opgeslagen, worden in het NT-systeem opgeslagen als een schijfbestand en de aanwijzer van het bestand wordt in de tabel opgeslagen. De kolom VARBINARY(max) waaraan het kenmerk FILESTREAM is toegewezen, heeft geen limiet voor de opslag van 2 GB in de tabel. Daarom kunnen we ook enorme bestanden opslaan.
In dit artikel ga ik als volgt demonstreren:
- De FILESTREAM-functie inschakelen.
- Hoe FILESTREAM-bestandsgroepen en FILESTREAM-gegevenscontainer aan te maken en te configureren.
- Hoe u gegevens uit de tabellen met FILESTREAM-functionaliteit opslaat en opent.
Demo:
In deze demo ga ik het volgende gebruiken:
- Databaseserver :SQL Server 2017
- Software :SQL Server Management Studio
- Database :FileStream_Demo
Configureer FILESTREAM-toegang in SQL Server-database
Om FileStream in SQL Server te configureren, brengt u de volgende wijzigingen aan in SQL Server.
- Schakel de FILESTREAM-functie in vanuit SQL Server Configuration Manager.
- Schakel het FILESTREAM-toegangsniveau in op SQL Server-instantie.
- Maak een FILESTREAM-bestandsgroep en een FileStream-container om BLOB-gegevens op te slaan.
FiLESTREAM-functie inschakelen
Als u FileStream op een database wilt inschakelen, schakelt u eerst de FileStream-functie in op het SQL Server-exemplaar. Open hiervoor SQL Server-configuratiebeheer, klik met de rechtermuisknop op SQL-instantie, selecteer Eigenschappen , zoals weergegeven in de volgende afbeelding:
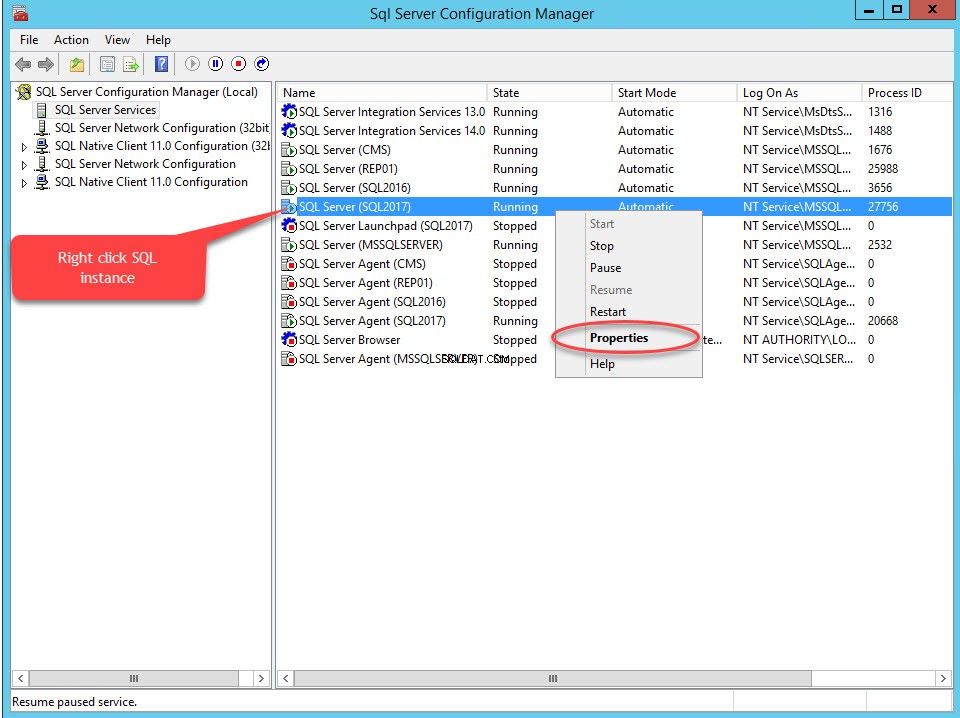
Er wordt een dialoogvenster geopend om servereigenschappen te configureren. Schakel over naar de FILESTREAM tabblad. Selecteer FILESTREAM inschakelen voor T-SQL-toegang . Selecteer FILESTREAM inschakelen voor I/O-toegang en selecteer vervolgens Sta externe clienttoegang toe tot FILESTREAM-gegevens . In de Windows-sharenaam tekstvak, geef een naam op van de map om de bestanden op te slaan. Zie de volgende afbeelding:
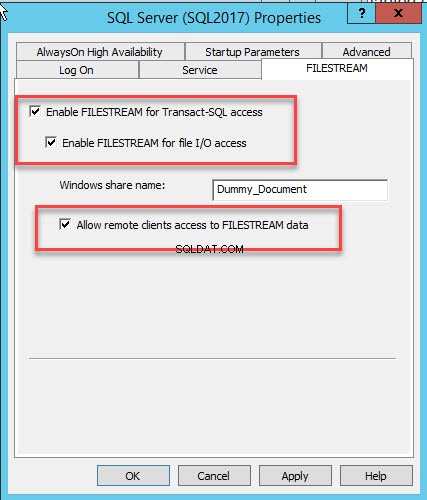
Klik op OK en start de SQL-service opnieuw.
Activeer FILESTREAM-toegangsniveau op SQL Server-instantie
Zodra de FILESTREAM-functie is ingeschakeld, wijzigt u het FILESTREAM-toegangsniveau. Voer de volgende query uit om het toegangsniveau van FileStream te wijzigen:
EXEC sp_configure filestream_access_level, 2 RECONFIGURE
In de bovenstaande query zijn de onderstaande parameters geldige waarden:
0 betekent de FILESTREAM-ondersteuning voor SQL-instantie is uitgeschakeld.
1 betekent de FILESTREAM-ondersteuning voor T-SQL is ingeschakeld.
2 betekent de FILESTREAM-ondersteuning voor T-SQL- en Win32-streamingtoegang is ingeschakeld.
U kunt het toegangsniveau FILESTREAM wijzigen met SQL Server Management Studio. Klik hiervoor met de rechtermuisknop op een SQL Server-verbinding>> selecteer Eigenschappen>> Selecteer in het dialoogvenster met servereigenschappen FileStream-toegangsniveau uit de vervolgkeuzelijst en selecteer Volledige toegang ingeschakeld , zoals weergegeven in de volgende afbeelding:
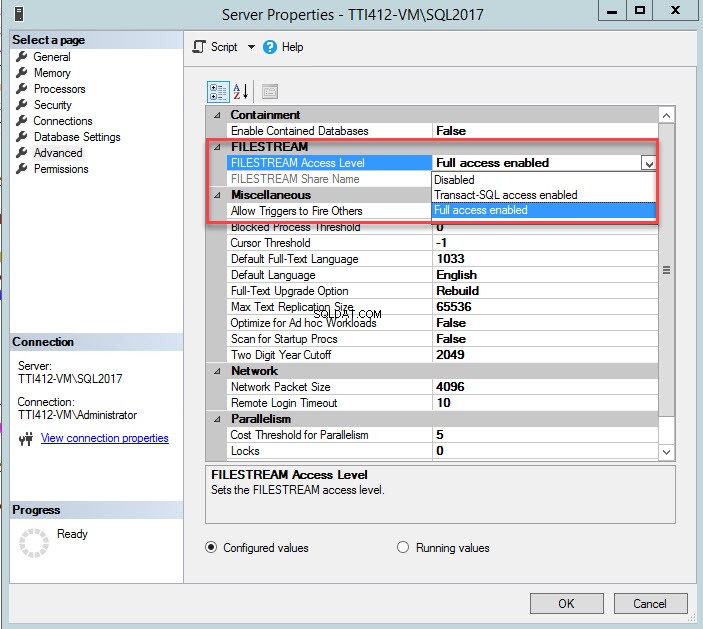
Nadat de parameter is gewijzigd, start u de SQL Server-services opnieuw.
Voeg FILESTREAM-bestandsgroep en gegevensbestanden toe
Zodra FILESTREAM is ingeschakeld, voegt u de FILESTREAM-bestandsgroep en de FILESTREAM-container toe.
Klik hiervoor met de rechtermuisknop op de FileStream-Demo database>> selecteer Eigenschappen>> In een linkerdeelvenster van de Database-eigenschappen dialoogvenster, selecteer Bestandsgroepen>> Klik in het FILESTREAM-raster op Bestandsgroep toevoegen knop> > Noem de bestandsgroep als Dummy Document . Zie de volgende afbeelding:
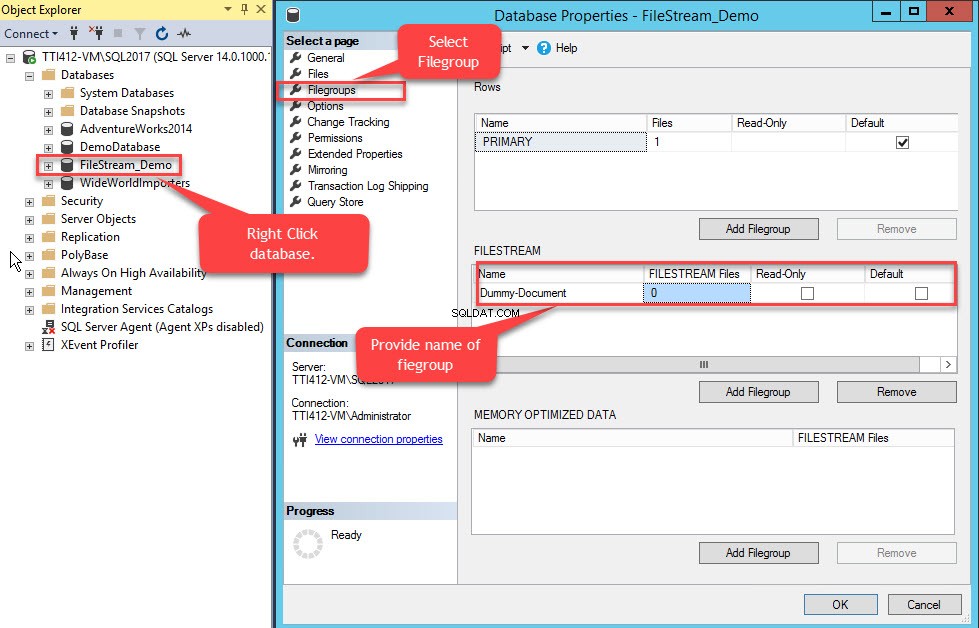
Nadat de bestandsgroep is gemaakt, selecteert u in het dialoogvenster Database-eigenschappen bestanden en klik op de knop Toevoegen. Het raster Databasebestanden maakt het mogelijk. Geef in de kolom Logische naam de naam op, – Dummy-Document . Selecteer FILESTREAM-gegevens in het Bestandstype vervolgkeuzelijst. Selecteer Dummy-document in deBestandsgroep kolom. In het Pad kolom, geef de maplocatie op waar bestanden worden opgeslagen (E:\Dummy-Documents). Zie de volgende afbeelding:
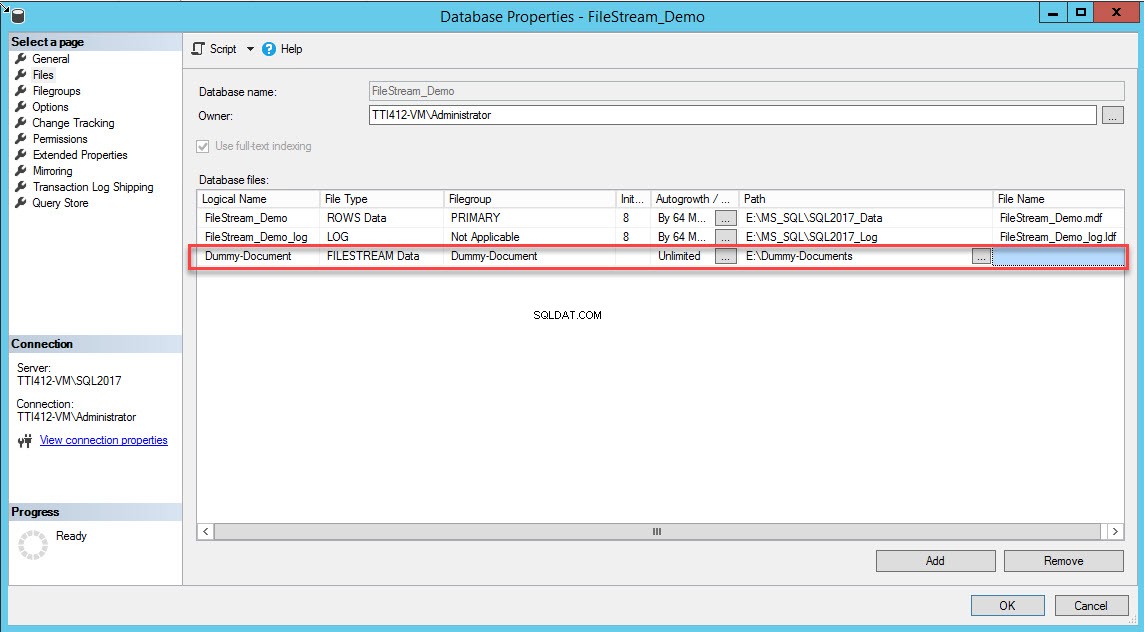
U kunt ook de FILESTREAM-bestandsgroep en containers toevoegen door de volgende T-SQL-query uit te voeren:
USE [master] GO ALTER DATABASE [FileStream_Demo] ADD FILEGROUP [Dummy-Documents] CONTAINS FILESTREAM GO ALTER DATABASE [FileStream_Demo] ADD FILE ( NAME = N'Dummy-Documents', FILENAME = N'E:\Dummy-Documents' ) TO FILEGROUP [Dummy-Documents] GO
Om te controleren of de FileStream-container is gemaakt, opent u Windows Verkenner en navigeert u naar de map "E:\Dummy-Document".
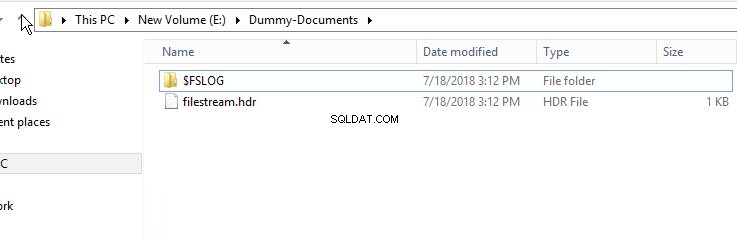
Zoals getoond in de bovenstaande afbeelding, de $FSLOG directory en de filestream.hdr bestand zijn gemaakt. $FSLOG is als SQL server T-Log, en filestream.hdr bevat metadata van FILESTREAM. Zorg ervoor dat u die bestanden niet wijzigt of bewerkt.
Bestanden opslaan in SQL-tabel
In deze demo zullen we een tabel maken om verschillende bestanden van de computer op te slaan. De tabel heeft de volgende kolommen:
- De “RootDirectory ” kolom om de bestandslocatie op te slaan.
- De “Bestandsnaam ” kolom om de naam van het bestand op te slaan.
- Het “Bestandskenmerk ” kolom om Bestandsattribuut op te slaan (Raw/Directory.
- De "FileCreateDate ” kolom om de aanmaaktijd van het bestand op te slaan.
- De "Bestandsgrootte ” kolom om de Grootte van het bestand op te slaan.
- De “FileStreamCol ” kolom om de inhoud van het bestand in het binaire formaat op te slaan.
Maak een SQL-tabel met een FILESTREAM-kolom
Nadat FILESTREAM is geconfigureerd, maakt u een SQL-tabel met de FILESTREAM-kolommen om verschillende bestanden in de SQL-servertabel op te slaan. Zoals ik hierboven al zei, is FILESTREAM geen gegevenstype. Het is een attribuut dat we toevoegen aan de varbinary(max) kolom in de FILESTREAM-enabled tabel. Zorg ervoor dat u een UNIQUEIDENTIFIER toevoegt wanneer u een tabel met FILESTREAM maakt. kolom met de ROWGUIDCOL en UNIEK attributen.
Voer het volgende script uit om een FILESTREAM-tabel te maken:
Use [FileStream_Demo]
go
Create Table [DummyDocuments]
(
ID uniqueidentifier ROWGUIDCOL unique NOT NULL,
RootDirectory varchar(max),
FileName varchar(max),
FileAttribute varchar(150),
FileCreateDate datetime,
FileSize numeric(10,5),
FileStreamCol varbinary (max) FILESTREAM
) Gegevens in tabel invoegen
Ik heb de WorldWide_Importors.xls document dat op de computer is opgeslagen op de locatie "E:\Documents". Gebruik OPENROWSET(Bulk) om de inhoud van de schijf naar de VARBINARY(max) . te laden variabel. Sla de variabele vervolgens op in de FileStreamCol (VARBINARY(max)) kolom van de DummyDocumen tafel. Voer hiervoor het volgende script uit:
Use [FileStream-Demo]
Go
DECLARE @Document AS VARBINARY(MAX)
-- Load the image data
SELECT @Document = CAST(bulkcolumn AS VARBINARY(MAX))
FROM OPENROWSET(
BULK
'E:\Documents\WorldWide_Importors.xls',
SINGLE_BLOB ) AS Doc
-- Insert the data to the table
INSERT INTO [DummyDocuments] (ID, RootDirectory,FileName, FileAttribute, FileCreateDate,FileSize,FileStreamCol)
SELECT NEWID(), 'E:\Documents','WorldWide_Importors.xls','Raw',getdate(),10, @Document Toegang tot FILESTREAM-gegevens
De FILESTREAM-gegevens zijn toegankelijk via T-SQL en Managed API. Wanneer de FILESTREAM-kolom wordt geopend met behulp van een T-SQL-query, gebruikt deze SQL-geheugen om de inhoud van het gegevensbestand te lezen en de gegevens naar de clienttoepassing te verzenden. Wanneer de FILESTREAM-kolom wordt geopend met behulp van Win32 Managed API, gebruikt deze geen SQL Server-geheugen. Het maakt gebruik van de streamingmogelijkheden van het NT-bestandssysteem, wat prestatievoordelen oplevert.
Toegang tot FILESTREAM-gegevens met T-SQL
Zoals ik aan het begin van het artikel al zei, is FILESTREAM een attribuut dat is toegewezen aan een tabelkolom met het gegevenstype varbinary(max) en daarom toegankelijk is zoals elke andere kolom van de tabel. Voer onderstaande query uit om FILESTREAM-gegevens samen met alle informatie van de tabel op te halen
Use [FileStream-Demo] go select RootDirectory,FileName,FileAttribute,FileCreateDate,FileSize,FileStreamCol from DummyDocuments
Hieronder staat de uitvoer van de vraag:

Zoals te zien is in de bovenstaande afbeelding, is het document "WorldWide_Importors.xls" geconverteerd naar een BLOB die is opgeslagen in de kolom "FileStreamCol".
Toegang tot FILESTREAM-gegevens met beheerde API
Hoewel toegang tot FILESTREAM met behulp van Win32 API een prestatie en andere voordelen biedt, maar het heeft andere en moeilijke syntaxis dan T-SQL-syntaxis, waardoor het moeilijk is om toegang te krijgen tot gegevens. Ten eerste moeten we, om het bestand in het FILESTREAM-gegevensarchief te lokaliseren, het logische pad identificeren om het bestand in het FILESTREAM-gegevensarchief op unieke wijze te identificeren. We kunnen dit doen door de Padnaam() . te gebruiken methode van de FILESTREAM-kolom. Het is hoofdlettergevoelig.
Nadat we het pad van Bestand hebben opgehaald om toegang te krijgen, moeten we de transactiecontext verkrijgen met behulp van de Transactie starten methode. Zodra de transactiecontext is verkregen, kunnen we deze openen met behulp van de SQLFileStream klasse.
De onderstaande code verkrijgt het lokale pad naar de WorldWide_Importors.xls document in de FILESTREAM-gegevensopslag.
SELECT
RootDirectory,
FileName,
FileAttribute,
FileCreateDate,
FileSize,
FileStreamCol.PathName() AS FilePath
FROM DummyDocuments Uitvoer van zoekopdracht:

Bestanden verwijderen uit FILESTREAM-container
Het verwijderen van bestanden is eenvoudig. U moet de verwijderquery uitvoeren om het bestand uit de FILESTREAM ingeschakelde SQL-tabel te verwijderen. Ook al is het record uit tabellen verwijderd, het bestand zal fysiek beschikbaar zijn in de FILSTREAM-gegevensopslag. Het wordt verwijderd door Garbage Collector. Garbage Collector-proces wordt uitgevoerd wanneer de checkpoint-gebeurtenis plaatsvindt. Door een expliciet ijkpunt op te geven, kun je het onmiddellijk verwijderen nadat je het uit de tabel hebt verwijderd.
Query om bestanden uit SQL-tabel te verwijderen:
Use [FileStream_Demo] go delete from DummyDocuments where ID='0D640ABC-8CF1-41E0-9FA8-28171047129F'
Samenvatting
In dit artikel heb ik het volgende behandeld:
- Introductie van FILESTREAM en wat zijn de voordelen.
- Hoe de FILESTREAM-functie op de SQL-serverinstantie in te schakelen.
- Maak en configureer de FILESTREAM-gegevensopslag en bestandsgroepen.
- Voer bestanden in en verwijder bestanden uit de FILESTREAM-gegevensopslag.
In toekomstige artikelen ga ik uitleggen:
- Hoe een FILESTREAM-database te back-uppen en te herstellen.
- Replicatie en tabelportionering instellen in FILESTREAM-tabellen.
Blijf op de hoogte!