Denk je ergens aan als je een nieuwe database aanmaakt? Ik denk dat de meesten van jullie nee zouden zeggen, aangezien we allemaal standaardparameters gebruiken, hoewel ze verre van optimaal zijn. Er zijn echter een heleboel schijfinstellingen en ze helpen echt om de betrouwbaarheid en prestaties van het systeem te vergroten.
We zullen niet spreken over het belang van het NTFS-bestandssysteem voor de betrouwbaarheid van gegevens, hoewel dit bestandssysteem MS SQL Server in staat stelt de schijf op de meest effectieve manier te gebruiken.
Als je te weinig middelen hebt en iets langzaam begint te werken, is upgraden het eerste dat in je opkomt. Maar upgraden is niet in alle gevallen vereist. Je kunt wegkomen met afstemming, hoewel dit niet moet worden gedaan wanneer de server langzaam begint te werken, maar in de fase van ontwerp en installatie.
Optimalisatie is een complex proces en heeft vaak niet alleen betrekking op een bepaald programma (in ons geval een bepaalde database), maar ook op OS en hardware. Hoewel we het vooral over databases zullen hebben, kunnen we de uiterlijke dingen niet negeren.
Gegevensarchitectuur
SQL Server slaat, leest en schrijft gegevens in blokken van elk 8 KB. Deze blokken worden pagina's genoemd. Een database kan 128 pagina's per megabyte bevatten (1 megabyte of 1048576 bytes gedeeld door 8 kilobytes of 8192 bytes). Alle pagina's worden in een mate opgeslagen. Een omvang is de laatste 8 opeenvolgende pagina's of 64 KB. Op 1 megabyte kunnen dus 16 extensies worden opgeslagen.
Pagina's en extensies vormen de basis van de fysieke databasestructuur van SQL Server. MS SQL Server gebruikt verschillende paginatypes, sommige houden de toegewezen ruimte bij, andere bevatten gebruikersgegevens en indexen. Pagina's die de toegewezen ruimte volgen, bevatten de dicht gecomprimeerde gegevens. Hiermee kan MS SQL Server ze effectief in het geheugen opslaan zodat ze gemakkelijk kunnen worden gelezen.
SQL Server gebruikt twee soorten extensies:
- Bereikten die pagina's van twee tot veel objecten opslaan, worden gemengde begrenzingen genoemd. Elke tafel begint als een gemengde omvang. U gebruikt de gemengde omvang voornamelijk voor de pagina's die ruimte in beslag nemen en kleine objecten bevatten.
- Bereikten waarin alle 8 pagina's aan één object zijn toegewezen, worden uniforme begrenzingen genoemd. Ze worden gebruikt wanneer een tabel of index meer dan 64 KB nodig heeft.
De eerste omvang voor elk bestand is een uniforme en bevat pagina's van de bestandskop, de volgende omvang bevatten elk 3 toegewezen pagina's. De server wijst deze gemengde extensies toe wanneer u een basisgegevensbestand aanmaakt en deze pagina's gebruikt voor zijn interne taken. De bestandskoppagina bevat bestandskenmerken, zoals de naam van de database die is opgeslagen in het bestand, bestandsgroep, minimumgrootte, incrementgrootte. Dit is de eerste pagina van elk bestand (pagina 0).
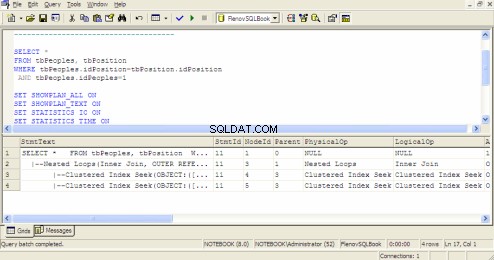
Plan voor query-uitvoering in SQL Query Analyzer
Vrije paginaruimte (PFS ) op een toegewezen pagina die informatie bevat over de beschikbare ruimte in het bestand. Deze informatie wordt opgeslagen op pagina 1. Elke dergelijke pagina kan worden uitgebreid tot 8000 aaneengesloten pagina's, wat ongeveer 64 Mb aan gegevens is.
Het transactielogboek verzamelt alle informatie over de wijzigingen die plaatsvinden op de server om een database te herstellen op het moment van een systeemfout en om de gegevensintegriteit te waarborgen.
Merk op dat alle getallen veelvouden zijn van 8 of 16. Dit komt omdat de hardeschijfcontroller gegevens van deze grootte gemakkelijker leest. De gegevens worden per pagina van de schijf gelezen, d.w.z. met 8 kilobytes, wat een vrij optimale waarde is.
Paginabeveiliging
Vanaf MS SQL Server 2005 beschikt de databaseserver over een nieuwe optie:de gegevenscontrole op paginaniveau. Als de AGE_VERIFY_CHECKSUM parameter is ingeschakeld (deze is standaard ingeschakeld), controleert de server de controlesommen van pagina's. Als we de handleiding voor deze parameter bekijken, zullen we zien dat de controlesom het mogelijk maakt om de invoer-/uitvoerfouten te volgen die het besturingssysteem niet kan volgen. Wat voor fouten zijn het? Het lijkt erop dat dit de interne problemen zijn van de databaseserver.
De gegevensintegriteitscontrole gaat nooit mis, dus het is beter om deze in te schakelen. Hiervoor moeten we het volgende commando uitvoeren:
ALTER DATABASE имя базы SET PAGE_VERIFY
Als er een fout op de pagina staat, zal de server ons hiervan op de hoogte stellen. Maar hoe kunnen we dit snel oplossen? Hiervoor is er een optie om gegevens op paginaniveau te herstellen.
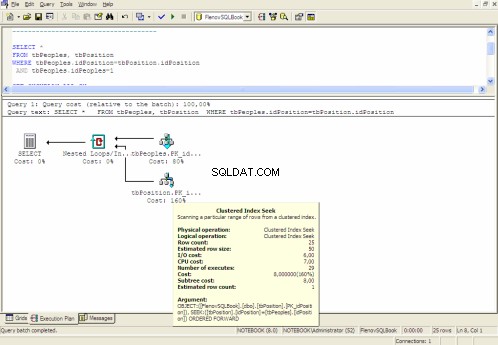
Grafisch uitvoeringsplan
Bestandsgroei
Wanneer we een database maken, worden we gevraagd om de initiële grootte en de increment-methode te selecteren. Als we de huidige ruimte tekort komen, breidt de server deze uit in overeenstemming met de vooraf ingestelde increment-methode.
Er zijn drie ophogingsmethoden voor bestanden:
- Groei in megabytes.
- Groei met procent.
- Handmatige groei.
De eerste twee methoden worden automatisch uitgevoerd, maar ze worden alleen aanbevolen voor testdatabases, aangezien een beheerder geen controle heeft over de bestandsgrootte.
Als een bestand met een bepaald aantal megabytes wordt verhoogd, kan op een bepaald moment de snelheid van het invoegen van gegevens toenemen en kan de bestandsgroei te frequent worden, wat extra kosten met zich meebrengt. Ook bestandsgroei in procenten is onrendabel. Het wordt aanbevolen om een bestandsgroei van 10% te gebruiken en dit is OK voor kleine en middelgrote databases. Maar wanneer het 1000 gigabyte bereikt, zal het bij elke groei 100 gigabyte nodig hebben. Het zal leiden tot zinloze verspilling van schijfruimte.
Beheer altijd wijzigingen in de grootte van bestanden en transactielogboeken. Hiermee kunt u de schijfbronnen op de meest effectieve manier gebruiken.
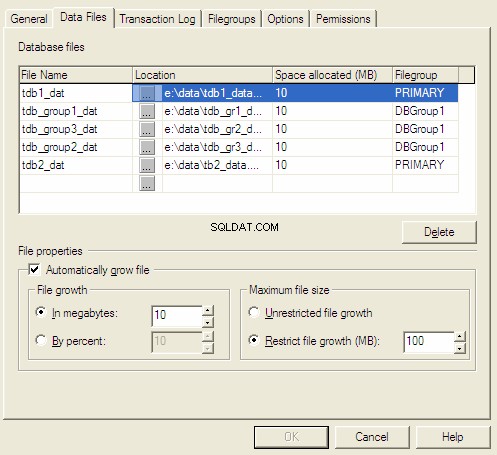
MS SQL Server-database-eigenschappen
Gegevenscompressie
Harde schijf blijft een verstandige plek van een computer. De prestaties van processors groeien enorm, terwijl harde schijven niets nieuws kunnen bieden. Om het aantal invoer-/uitvoerbewerkingen op te slaan en de gegevens die op de harde schijf zijn opgeslagen te verminderen, kunt u schijven met compressie gebruiken. Alleen dergelijke schijven zijn geschikt voor het opslaan van alleen-lezen bestandsgroepen. Misschien is het omdat compressie vereist is voor schrijven, en het vereist extra processorkosten.
Gegevenscompressie en alleen-lezen status zijn goed voor de archiefgegevens. Boekhoudgegevens van de afgelopen jaren zijn bijvoorbeeld niet nodig om te schrijven en kunnen te veel ruimte in beslag nemen. Door gegevens op het archiefgedeelte van de schijf te plaatsen, bespaart u veel ruimte.
Schijven voor betrouwbaarheid
De volgende methode maakt het mogelijk om tegelijkertijd de betrouwbaarheid en prestaties te vergroten, en nogmaals, het is gerelateerd aan harde schijven. Nou, daar is het, mechanica is niet alleen de langzaamste, maar ook de meest onbetrouwbare. Wat de betrouwbaarheid betreft, ik heb de statistieken niet verzameld, maar zowel thuis als op het werk heb ik voornamelijk te maken met harde schijven.
Om de prestaties en betrouwbaarheid te verhogen, kunt u dus gewoon twee of meer harde schijven gebruiken in plaats van één. Het wordt nog beter als ze worden aangesloten op afzonderlijke controllers. U kunt de database op de ene schijf opslaan en transactielogboeken op een andere. Als er een derde schijf is, kan deze het systeem opslaan.
Door data en een log op aparte schijven op te slaan vergroot je de betrouwbaarheid enorm. Stel dat je alles op één schijf hebt staan en dat het uitvalt. Wat moeten we doen? Je kunt een bedrijf bereiken dat alles zal proberen te herstellen of hetzelfde probeert te doen, maar de kans op herstel is verre van 100%. Bovendien kan het veel tijd kosten om de server weer aan het werk te krijgen. Snel herstel kan alleen worden gedaan tot het moment van de laatste reservekopie. De rest is twijfelachtig.
En stel nu dat u gegevens en een transactielogboek op verschillende schijven hebt staan. Als de schijf met het logboek uitvalt, zijn er nog steeds gegevens. Het enige is dat je geen nieuwe gegevens kunt toevoegen, maar als je een nieuw logboek maakt, kun je doorgaan met werken.
Mocht de schijf met data het begeven, dan kunnen we alsnog het transactielogboek reserveren om het kleinste dataverlies te voorkomen. Daarna herstellen we de gegevens van de volledige back-up (het moet altijd van tevoren worden gedaan, een goede beheerder doet dit minimaal één keer per dag) en voegen we wijzigingen toe vanuit de back-up van de log.
Schijven voor prestaties
Als gegevens en een logboek op afzonderlijke schijven staan, betekent dit niet alleen veiligheid, maar ook prestatiegroei. Het punt is dat de databaseserver tegelijkertijd gegevens in het log- en gegevensbestand kan schrijven.
We kunnen verder gaan en één harde schijf toewijzen aan het transactielogboek en meerdere harde schijven aan gegevens. De server werkt vaker met data, daarom zijn er meerdere storages nodig waarmee je tegelijkertijd kunt werken. En als deze storages zijn aangesloten op verschillende controllers, is het gelijktijdige werk gegarandeerd.
De snelste en meest betrouwbare variant is om RAID . te gebruiken . Niet elke RAID is betrouwbaar en snel tegelijk. Voor de bestandsgroepen wordt aanbevolen om RAID10 . te kiezen , omdat het goed uitgebalanceerde functies bevat, maar afhankelijk van de databasegegevens kunt u een andere variant kiezen.
U kunt een software- of hardwareoplossing gebruiken als RAID . Een software-oplossing is goedkoper, maar vereist extra CPU-bronnen. En een processor heeft geen reservebronnen. Daarom is het beter om hardware-oplossingen te gebruiken waarbij een speciale chip verantwoordelijk is voor RAID .
Indexen
Iedereen weet dat indexen helpen om de zoeksnelheid van gegevens te verhogen. De meesten van ons begrijpen dat indexen een negatief effect hebben op het invoegen en bijwerken van gegevens, dus hoe meer indexen u heeft, hoe moeilijker het voor de server is om ze te onderhouden. Bovendien denken niet veel mensen dat indexen onderhoud nodig hebben. Databasepagina's met indexgegevens kunnen overlopen en uiteindelijk uit balans raken.
Ja, we kunnen verschillende parameters negeren en eenvoudig één keer per maand indexen opnieuw maken, wat vergelijkbaar is met onderhoud. SQL Server bevat twee parameters die voorkomen dat indexen binnen een half uur na het maken ervan verouderd zijn:FILLFACTOR en PAD_INDEX .
U kunt de optie FILLFACTOR gebruiken om de prestaties te optimaliseren van de invoeg- en updatebewerkingen die een geclusterde of niet-geclusterde index bevatten. Indexgegevens kunnen op veel gegevenspagina's worden opgeslagen. Zoals ik hierboven al zei, bestaat elke pagina uit 8 KB. Wanneer een indexpagina vol is, maakt de server een nieuwe pagina aan en verdeelt de pagina voor het invoegen van gegevens in tweeën.
De server heeft tijd nodig voor het opdelen van de pagina's en het maken van een nieuwe pagina. Gebruik de FILLFACTOR . om de pagina-indeling te optimaliseren optie om het percentage vrije ruimte op alle bladen van de indexpagina te bepalen. Hoe meer schijfruimte de pagina's op bladniveau hebben, hoe minder vaak u indexpagina's hoeft te splitsen. De indexboom zal dan te groot zijn en het omzeilen ervan kost extra tijd.
De PAD_INDEX optie geeft het vulpercentage van de niet-bladpagina's aan. U kunt PAD_INDEX . gebruiken alleen wanneer de FILLFACTOR optie is opgegeven sinds de procentuele waarde van PAD_INDEX hangt af van het percentage gespecificeerd in FILLFACTOR .
Statistieken
Statistieken stellen de server in staat om de juiste beslissing te nemen tussen indexgebruik en het scannen van volledige tabellen. Stel, u heeft een lijst met medewerkers van een gieterij. Zo'n lijst wordt gemaakt van ongeveer 90% van de mannen.
Stel nu dat we alle vrouwen moeten vinden. Aangezien er niet veel van zijn, is de meest effectieve optie om de index te gebruiken. Maar als we alle mannen moeten vinden, neemt de efficiëntie van de index af. Het aantal geselecteerde records is te groot en het omzeilen van de indexstructuur voor elk van hen zal een overhead zijn. Het is veel eenvoudiger om de hele tabel te scannen - de uitvoering zal veel sneller zijn, omdat de server alle bladen van de index op laag niveau één keer moet lezen zonder de noodzaak van meerdere leesbewerkingen van alle niveaus.
SQL Server verzamelt statistieken door alle veldwaarden te lezen of met een sjabloon voor het maken van de uniform verdeelde en gesorteerde waardenlijst. SQL Server detecteert dynamisch het percentage rijen dat getest moet worden op basis van het aantal rijen in de tabel. Bij het verzamelen van statistieken zal de query-optimizer een volledige scan of rijsjablonen uitvoeren.
Om statistieken te laten werken, moet deze worden gemaakt. In het geval van massale gegevensupdates, kunnen de statistieken onjuiste gegevens bevatten en zal de server een verkeerde beslissing nemen. Maar alles kan worden rechtgezet, - u moet statistieken bijhouden. Raadpleeg de boeken over Transact-SQL of MS SQL Server voor meer gedetailleerde informatie.
Samenvatting
De standaardinstellingen laten niet toe om alle mogelijkheden van hardware te gebruiken en werken met alle verschillende servers. De verantwoordelijkheid voor de instellingen ligt bij de beheerders. Het feit dat de Microsoft-producten eenvoudige installatieprogramma's, grafische beheerprogramma's en de mogelijkheid om offline te werken hebben, betekent niet dat dit een optimale variant is.
We beschouwen dergelijke opties voor het afstemmen van databases niet als hardwareversnelling. Als alle afstemmingsopties zijn uitgeput, is het beter om na te denken over de upgrade, omdat hardwareversnelling de betrouwbaarheid van het systeem negatief beïnvloedt.
Het belangrijkste is dat elke optimalisatie van de databaseserver of elke upgrade niet helpt als query's niet worden geoptimaliseerd.