In dit artikel ga ik verder met het onderzoeken van oplossingen voor het matchen van vraag en aanbod. Met dank aan Luca, Kamil Kosno, Daniel Brown, Brian Walker, Joe Obbish, Rainer Hoffmann, Paul White, Charlie, Ian en Peter Larsson, voor het verzenden van uw oplossingen.
Vorige maand behandelde ik oplossingen op basis van een herziene benadering van intervalkruisingen in vergelijking met de klassieke. De snelste van die oplossingen combineerde ideeën van Kamil, Luca en Daniel. Het verenigde twee query's met onsamenhangende sargable predikaten. Het kostte de oplossing 1,34 seconden om te voltooien tegen een invoer van 400K rijen. Dat is niet zo armoedig, aangezien de oplossing op basis van de klassieke benadering van intervalkruisingen 931 seconden kostte om te voltooien tegen dezelfde invoer. Herinner je ook dat Joe een briljante oplossing bedacht die gebaseerd is op de klassieke benadering van intervallen, maar de matching-logica optimaliseert door intervallen te bucketiseren op basis van de grootste intervallengte. Met dezelfde invoer van 400K rijen kostte Joe's oplossing 0,9 seconden om te voltooien. Het lastige van deze oplossing is dat de prestaties afnemen naarmate de grootste intervallengte toeneemt.
Deze maand verken ik fascinerende oplossingen die sneller zijn dan de Kamil/Luca/Daniel Revised Intersections-oplossing en neutraal zijn voor intervallengte. De oplossingen in dit artikel zijn gemaakt door Brian Walker, Ian, Peter Larsson, Paul White en mij.
Ik heb alle oplossingen in dit artikel vergeleken met de invoertabel Veilingen met rijen van 100K, 200K, 300K en 400K en met de volgende indexen:
-- Index to support solution CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity); -- Enable batch-mode Window Aggregate CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.Auctions(ID) WHERE ID = -1 AND ID = -2;
Bij het beschrijven van de logica achter de oplossingen, ga ik ervan uit dat de tabel Veilingen is gevuld met de volgende kleine set voorbeeldgegevens:
ID Code Quantity ----------- ---- --------- 1 D 5.000000 2 D 3.000000 3 D 8.000000 5 D 2.000000 6 D 8.000000 7 D 4.000000 8 D 2.000000 1000 S 8.000000 2000 S 6.000000 3000 S 2.000000 4000 S 2.000000 5000 S 4.000000 6000 S 3.000000 7000 S 2.000000
Hieronder volgt het gewenste resultaat voor deze voorbeeldgegevens:
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000
Brian Walkers oplossing
Outer joins worden vrij vaak gebruikt in SQL-queryoplossingen, maar wanneer je die gebruikt, gebruik je enkelzijdige. Als ik lesgeef over outer joins, krijg ik vaak vragen om voorbeelden voor praktische toepassingen van volledige outer joins, en dat zijn er niet zo veel. De oplossing van Brian is een mooi voorbeeld van een praktisch gebruik van volledige outer joins.
Hier is de volledige oplossingscode van Brian:
DROP TABLE IF EXISTS #MyPairings;
CREATE TABLE #MyPairings
(
DemandID INT NOT NULL,
SupplyID INT NOT NULL,
TradeQuantity DECIMAL(19,06) NOT NULL
);
WITH D AS
(
SELECT A.ID,
SUM(A.Quantity) OVER (PARTITION BY A.Code
ORDER BY A.ID ROWS UNBOUNDED PRECEDING) AS Running
FROM dbo.Auctions AS A
WHERE A.Code = 'D'
),
S AS
(
SELECT A.ID,
SUM(A.Quantity) OVER (PARTITION BY A.Code
ORDER BY A.ID ROWS UNBOUNDED PRECEDING) AS Running
FROM dbo.Auctions AS A
WHERE A.Code = 'S'
),
W AS
(
SELECT D.ID AS DemandID, S.ID AS SupplyID, ISNULL(D.Running, S.Running) AS Running
FROM D
FULL JOIN S
ON D.Running = S.Running
),
Z AS
(
SELECT
CASE
WHEN W.DemandID IS NOT NULL THEN W.DemandID
ELSE MIN(W.DemandID) OVER (ORDER BY W.Running
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING)
END AS DemandID,
CASE
WHEN W.SupplyID IS NOT NULL THEN W.SupplyID
ELSE MIN(W.SupplyID) OVER (ORDER BY W.Running
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING)
END AS SupplyID,
W.Running
FROM W
)
INSERT #MyPairings( DemandID, SupplyID, TradeQuantity )
SELECT Z.DemandID, Z.SupplyID,
Z.Running - ISNULL(LAG(Z.Running) OVER (ORDER BY Z.Running), 0.0) AS TradeQuantity
FROM Z
WHERE Z.DemandID IS NOT NULL
AND Z.SupplyID IS NOT NULL; Ik heb Brians oorspronkelijke gebruik van afgeleide tabellen met CTE's voor de duidelijkheid herzien.
De CTE D berekent de lopende totale vraaghoeveelheden in een resultaatkolom genaamd D.Running, en de CTE S berekent de lopende totale leveringshoeveelheden in een resultaatkolom genaamd S.Running. De CTE W voert vervolgens een volledige outer join uit tussen D en S, waarbij D.Running overeenkomt met S.Running, en retourneert de eerste niet-NULL tussen D.Running en S.Running als W.Running. Dit is het resultaat dat u krijgt als u alle rijen van W opvraagt, geordend op Uitvoeren:
DemandID SupplyID Running ----------- ----------- ---------- 1 NULL 5.000000 2 1000 8.000000 NULL 2000 14.000000 3 3000 16.000000 5 4000 18.000000 NULL 5000 22.000000 NULL 6000 25.000000 6 NULL 26.000000 NULL 7000 27.000000 7 NULL 30.000000 8 NULL 32.000000
Het idee om een volledige outer join te gebruiken op basis van een predikaat dat de lopende totalen van vraag en aanbod vergelijkt, is geniaal! De meeste rijen in dit resultaat - de eerste 9 in ons geval - vertegenwoordigen resultaatparen waarbij een beetje extra berekeningen ontbreken. Rijen met NULL-ID's aan het einde van een van de soorten vertegenwoordigen items die niet kunnen worden vergeleken. In ons geval vertegenwoordigen de laatste twee rijen vraagitems die niet kunnen worden gekoppeld aan aanboditems. Wat hier dus overblijft, is het berekenen van de DemandID, SupplyID en TradeQuantity van de resultaatparen en het filteren van de items die niet kunnen worden gematcht.
De logica die het resultaat DemandID en SupplyID berekent, wordt als volgt in de CTE Z gedaan (ervan uitgaande dat de volgorde in W door Running wordt uitgevoerd):
- DemandID:als DemandID niet NULL is, dan DemandID, anders de minimale DemandID die begint met de huidige rij
- SupplyID:als SupplyID niet NULL is, dan SupplyID, anders de minimale SupplyID beginnend met de huidige rij
Dit is het resultaat dat u krijgt als u Z opvraagt en de rijen ordent door Uitvoeren:
DemandID SupplyID Running ----------- ----------- ---------- 1 1000 5.000000 2 1000 8.000000 3 2000 14.000000 3 3000 16.000000 5 4000 18.000000 6 5000 22.000000 6 6000 25.000000 6 7000 26.000000 7 7000 27.000000 7 NULL 30.000000 8 NULL 32.000000
De buitenste query filtert rijen uit Z die vermeldingen van de ene soort vertegenwoordigen die niet kunnen worden vergeleken met vermeldingen van de andere soort door ervoor te zorgen dat zowel DemandID als SupplyID niet NULL zijn. De handelshoeveelheid van de resultaatparen wordt berekend als de huidige Lopende waarde minus de vorige Lopende waarde met behulp van een LAG-functie.
Dit is wat er naar de #MyPairings-tabel wordt geschreven, wat het gewenste resultaat is:
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000
Het plan voor deze oplossing wordt getoond in figuur 1.
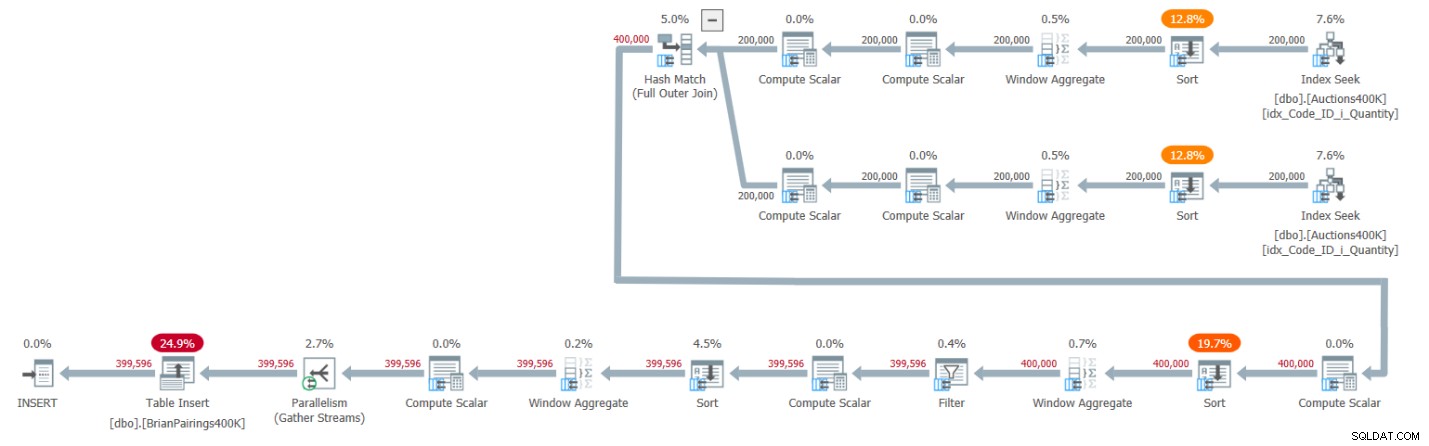 Figuur 1:Queryplan voor Brians oplossing
Figuur 1:Queryplan voor Brians oplossing
De bovenste twee takken van het plan berekenen de lopende totalen van vraag en aanbod met behulp van een batch-modus Window Aggregate-operator, elk na het ophalen van de respectieve invoer uit de ondersteunende index. Zoals ik in eerdere artikelen in de serie heb uitgelegd, zou je denken dat expliciete sorteeroperatoren niet vereist zouden moeten zijn, aangezien de index de rijen al heeft geordend zoals de Window Aggregate-operatoren ze nodig hebben. Maar SQL Server ondersteunt momenteel geen efficiënte combinatie van parallelle indexbewerkingen voor het behouden van de volgorde voorafgaand aan een parallelle batch-modus Window Aggregate-operator, dus als resultaat gaat een expliciete parallelle Sort-operator vooraf aan elk van de parallelle Window Aggregate-operators.
Het plan gebruikt een hash-join in batch-modus om de volledige outer join af te handelen. Het plan gebruikt ook twee extra batch-modus Window Aggregate-operators, voorafgegaan door expliciete Sort-operators om de MIN- en LAG-vensterfuncties te berekenen.
Dat is een behoorlijk efficiënt plan!
Dit zijn de looptijden die ik voor deze oplossing heb gekregen tegen invoergroottes van 100K tot 400K rijen, in seconden:
100K: 0.368 200K: 0.845 300K: 1.255 400K: 1.315
Itziks oplossing
De volgende oplossing voor de uitdaging is een van mijn pogingen om het op te lossen. Hier is de volledige oplossingscode:
DROP TABLE IF EXISTS #MyPairings;
WITH C1 AS
(
SELECT *,
SUM(Quantity)
OVER(PARTITION BY Code
ORDER BY ID
ROWS UNBOUNDED PRECEDING) AS SumQty
FROM dbo.Auctions
),
C2 AS
(
SELECT *,
SUM(Quantity * CASE Code WHEN 'D' THEN -1 WHEN 'S' THEN 1 END)
OVER(ORDER BY SumQty, Code
ROWS UNBOUNDED PRECEDING) AS StockLevel,
LAG(SumQty, 1, 0.0) OVER(ORDER BY SumQty, Code) AS PrevSumQty,
MAX(CASE WHEN Code = 'D' THEN ID END)
OVER(ORDER BY SumQty, Code
ROWS UNBOUNDED PRECEDING) AS PrevDemandID,
MAX(CASE WHEN Code = 'S' THEN ID END)
OVER(ORDER BY SumQty, Code
ROWS UNBOUNDED PRECEDING) AS PrevSupplyID,
MIN(CASE WHEN Code = 'D' THEN ID END)
OVER(ORDER BY SumQty, Code
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS NextDemandID,
MIN(CASE WHEN Code = 'S' THEN ID END)
OVER(ORDER BY SumQty, Code
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS NextSupplyID
FROM C1
),
C3 AS
(
SELECT *,
CASE Code
WHEN 'D' THEN ID
WHEN 'S' THEN
CASE WHEN StockLevel > 0 THEN NextDemandID ELSE PrevDemandID END
END AS DemandID,
CASE Code
WHEN 'S' THEN ID
WHEN 'D' THEN
CASE WHEN StockLevel <= 0 THEN NextSupplyID ELSE PrevSupplyID END
END AS SupplyID,
SumQty - PrevSumQty AS TradeQuantity
FROM C2
)
SELECT DemandID, SupplyID, TradeQuantity
INTO #MyPairings
FROM C3
WHERE TradeQuantity > 0.0
AND DemandID IS NOT NULL
AND SupplyID IS NOT NULL; De CTE C1 doorzoekt de tabel Veilingen en gebruikt een vensterfunctie om de lopende totale vraag- en aanbodhoeveelheden te berekenen, waarbij de resultaatkolom SumQty wordt aangeroepen.
De CTE C2 doorzoekt C1 en berekent een aantal attributen met behulp van vensterfuncties op basis van SumQty en Code-volgorde:
- Voorraadniveau:Het huidige voorraadniveau na verwerking van elke invoer. Dit wordt berekend door een negatief teken toe te kennen aan vraaghoeveelheden en een positief teken aan leveringshoeveelheden en deze hoeveelheden op te tellen tot en met de huidige invoer.
- PrevSumQty:de SumQty-waarde van de vorige rij.
- PrevDemandID:laatste niet-NULL aanvraag-ID.
- PrevSupplyID:laatste niet-NULL leverings-ID.
- NextDemandID:Volgende niet-NULL aanvraag-ID.
- NextSupplyID:volgende niet-NULL leverings-ID.
Hier is de inhoud van C2 geordend op SumQty en Code:
ID Code Quantity SumQty StockLevel PrevSumQty PrevDemandID PrevSupplyID NextDemandID NextSupplyID ----- ---- --------- ---------- ----------- ----------- ------------ ------------ ------------ ------------ 1 D 5.000000 5.000000 -5.000000 0.000000 1 NULL 1 1000 2 D 3.000000 8.000000 -8.000000 5.000000 2 NULL 2 1000 1000 S 8.000000 8.000000 0.000000 8.000000 2 1000 3 1000 2000 S 6.000000 14.000000 6.000000 8.000000 2 2000 3 2000 3 D 8.000000 16.000000 -2.000000 14.000000 3 2000 3 3000 3000 S 2.000000 16.000000 0.000000 16.000000 3 3000 5 3000 5 D 2.000000 18.000000 -2.000000 16.000000 5 3000 5 4000 4000 S 2.000000 18.000000 0.000000 18.000000 5 4000 6 4000 5000 S 4.000000 22.000000 4.000000 18.000000 5 5000 6 5000 6000 S 3.000000 25.000000 7.000000 22.000000 5 6000 6 6000 6 D 8.000000 26.000000 -1.000000 25.000000 6 6000 6 7000 7000 S 2.000000 27.000000 1.000000 26.000000 6 7000 7 7000 7 D 4.000000 30.000000 -3.000000 27.000000 7 7000 7 NULL 8 D 2.000000 32.000000 -5.000000 30.000000 8 7000 8 NULL
De CTE C3 bevraagt C2 en berekent de DemandID, SupplyID en TradeQuantity van de resultaatparen, voordat enkele overbodige rijen worden verwijderd.
Het resultaat C3.DemandID-kolom wordt als volgt berekend:
- Als de huidige invoer een vraaginvoer is, retourneert u DemandID.
- Als de huidige invoer een leveringsinvoer is en het huidige voorraadniveau positief is, retourneert u NextDemandID.
- Als de huidige invoer een leveringsinvoer is en het huidige voorraadniveau niet positief is, retourneer dan PrevDemandID.
De kolom C3.SupplyID met het resultaat wordt als volgt berekend:
- Als de huidige invoer een voorraadinvoer is, retourneer dan SupplyID.
- Als de huidige invoer een vraaginvoer is en het huidige voorraadniveau niet positief is, retourneer dan NextSupplyID.
- Als de huidige invoer een vraaginvoer is en het huidige voorraadniveau positief is, retourneer dan PrevSupplyID.
Het resultaat TradeQuantity wordt berekend als de SumQty min PrevSumQty van de huidige rij.
Hier is de inhoud van de kolommen die relevant zijn voor het resultaat van C3:
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 2 1000 0.000000 3 2000 6.000000 3 3000 2.000000 3 3000 0.000000 5 4000 2.000000 5 4000 0.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000 7 NULL 3.000000 8 NULL 2.000000
Wat de buitenste query nog moet doen, is overtollige rijen uit C3 filteren. Die omvatten twee gevallen:
- Als de lopende totalen van beide soorten hetzelfde zijn, heeft de invoer een handelshoeveelheid van nul. Onthoud dat de bestelling is gebaseerd op SumQty en Code, dus als de lopende totalen hetzelfde zijn, verschijnt de vraaginvoer vóór de leveringsinvoer.
- Laatste items van de ene soort die niet kunnen worden vergeleken met items van de andere soort. Dergelijke vermeldingen worden weergegeven door rijen in C3 waar ofwel de vraag-ID NULL is of de aanbod-ID NULL is.
Het plan voor deze oplossing wordt getoond in figuur 2.
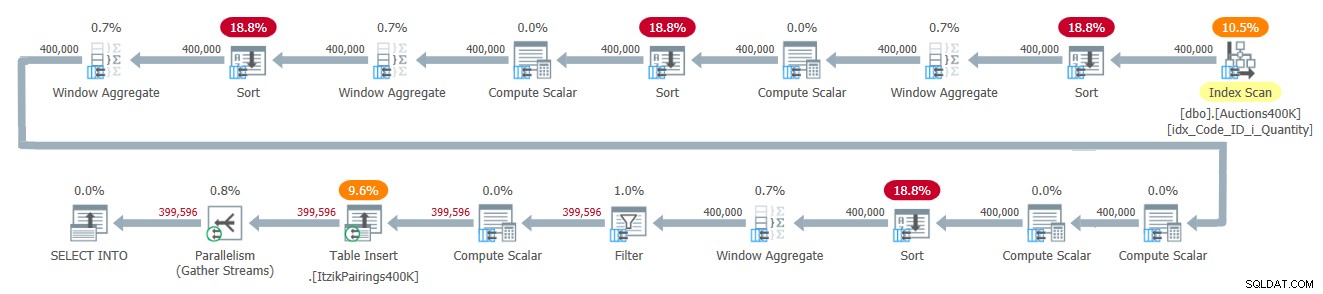 Figuur 2:Queryplan voor de oplossing van Itzik
Figuur 2:Queryplan voor de oplossing van Itzik
Het plan past één keer de invoergegevens toe en gebruikt vier batch-mode Window Aggregate-operators om de verschillende vensterberekeningen af te handelen. Alle Window Aggregate-operatoren worden voorafgegaan door expliciete Sort-operatoren, hoewel er hier slechts twee onvermijdelijk zijn. De andere twee hebben te maken met de huidige implementatie van de parallelle batch-modus Window Aggregate-operator, die niet kan vertrouwen op een parallelle invoer voor het bewaren van orders. Een eenvoudige manier om te zien welke sorteeroperatoren het gevolg zijn van deze reden, is door een serieel plan te forceren en te zien welke sorteeroperatoren verdwijnen. Wanneer ik een serieel plan forceer met deze oplossing, verdwijnen de eerste en derde sorteeroperatoren.
Dit zijn de looptijden in seconden die ik voor deze oplossing heb gekregen:
100K: 0.246 200K: 0.427 300K: 0.616 400K: 0.841>
Ians oplossing
De oplossing van Ian is kort en efficiënt. Hier is de volledige oplossingscode:
DROP TABLE IF EXISTS #MyPairings;
WITH A AS (
SELECT *,
SUM(Quantity) OVER (PARTITION BY Code
ORDER BY ID
ROWS UNBOUNDED PRECEDING) AS CumulativeQuantity
FROM dbo.Auctions
), B AS (
SELECT CumulativeQuantity,
CumulativeQuantity
- LAG(CumulativeQuantity, 1, 0)
OVER (ORDER BY CumulativeQuantity) AS TradeQuantity,
MAX(CASE WHEN Code = 'D' THEN ID END) AS DemandID,
MAX(CASE WHEN Code = 'S' THEN ID END) AS SupplyID
FROM A
GROUP BY CumulativeQuantity, ID/ID -- bogus grouping to improve row estimate
-- (rows count of Auctions instead of 2 rows)
), C AS (
-- fill in NULLs with next supply / demand
-- FIRST_VALUE(ID) IGNORE NULLS OVER ...
-- would be better, but this will work because the IDs are in CumulativeQuantity order
SELECT
MIN(DemandID) OVER (ORDER BY CumulativeQuantity
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS DemandID,
MIN(SupplyID) OVER (ORDER BY CumulativeQuantity
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS SupplyID,
TradeQuantity
FROM B
)
SELECT DemandID, SupplyID, TradeQuantity
INTO #MyPairings
FROM C
WHERE SupplyID IS NOT NULL -- trim unfulfilled demands
AND DemandID IS NOT NULL; -- trim unused supplies De code in de CTE A doorzoekt de tabel Veilingen en berekent de lopende totale vraag- en aanbodhoeveelheden met behulp van een vensterfunctie, waarbij de resultaatkolom CumulativeQuantity wordt genoemd.
De code in CTE B vraagt CTE A op en groepeert de rijen op CumulativeQuantity. Deze groepering bereikt een soortgelijk effect als Brian's outer join op basis van de lopende totalen van vraag en aanbod. Ian heeft ook de dummy-expressie ID/ID toegevoegd aan de groeperingsset om de oorspronkelijke kardinaliteit van de groepering onder schatting te verbeteren. Op mijn machine resulteerde dit ook in het gebruik van een parallel plan in plaats van een serieel plan.
In de SELECT-lijst berekent de code DemandID en SupplyID door de ID van het respectieve itemtype in de groep op te halen met behulp van het MAX-aggregaat en een CASE-expressie. Als de ID niet aanwezig is in de groep, is het resultaat NULL. De code berekent ook een resultaatkolom genaamd TradeQuantity als de huidige cumulatieve hoeveelheid minus de vorige, opgehaald met behulp van de LAG-vensterfunctie.
Hier is de inhoud van B:
CumulativeQuantity TradeQuantity DemandId SupplyId ------------------- -------------- --------- --------- 5.000000 5.000000 1 NULL 8.000000 3.000000 2 1000 14.000000 6.000000 NULL 2000 16.000000 2.000000 3 3000 18.000000 2.000000 5 4000 22.000000 4.000000 NULL 5000 25.000000 3.000000 NULL 6000 26.000000 1.000000 6 NULL 27.000000 1.000000 NULL 7000 30.000000 3.000000 7 NULL 32.000000 2.000000 8 NULL
De code in de CTE C ondervraagt vervolgens de CTE B en vult NULL vraag- en aanbod-ID's in met de volgende niet-NULL vraag- en aanbod-ID's, met behulp van de MIN-vensterfunctie met het frame RIJEN TUSSEN HUIDIGE RIJ EN ONGEBONDEN VOLGENDE.
Hier is de inhoud van C:
DemandID SupplyID TradeQuantity --------- --------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000 7 NULL 3.000000 8 NULL 2.000000
De laatste stap die door de buitenste query tegen C wordt uitgevoerd, is het verwijderen van vermeldingen van de ene soort die niet kunnen worden vergeleken met vermeldingen van de andere soort. Dat wordt gedaan door rijen uit te filteren waarin SupplyID NULL is of DemandID NULL is.
Het plan voor deze oplossing wordt getoond in figuur 3.
 Figuur 3:Queryplan voor Ian's oplossing
Figuur 3:Queryplan voor Ian's oplossing
Dit plan voert één scan uit van de invoergegevens en gebruikt drie parallelle batch-mode vensteraggregaten om de verschillende vensterfuncties te berekenen, allemaal voorafgegaan door parallelle sorteeroperatoren. Twee daarvan zijn onvermijdelijk, zoals u kunt verifiëren door een serieel plan te forceren. Het plan gebruikt ook een Hash Aggregate-operator om de groepering en aggregatie in de CTE B af te handelen.
Dit zijn de looptijden in seconden die ik voor deze oplossing heb gekregen:
100K: 0.214 200K: 0.363 300K: 0.546 400K: 0.701
Peter Larssons oplossing
De oplossing van Peter Larsson is verbazingwekkend kort, krachtig en zeer efficiënt. Hier is de volledige oplossingscode van Peter:
DROP TABLE IF EXISTS #MyPairings;
WITH cteSource(ID, Code, RunningQuantity)
AS
(
SELECT ID, Code,
SUM(Quantity) OVER (PARTITION BY Code ORDER BY ID) AS RunningQuantity
FROM dbo.Auctions
)
SELECT DemandID, SupplyID, TradeQuantity
INTO #MyPairings
FROM (
SELECT
MIN(CASE WHEN Code = 'D' THEN ID ELSE 2147483648 END)
OVER (ORDER BY RunningQuantity, Code
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS DemandID,
MIN(CASE WHEN Code = 'S' THEN ID ELSE 2147483648 END)
OVER (ORDER BY RunningQuantity, Code
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS SupplyID,
RunningQuantity
- COALESCE(LAG(RunningQuantity) OVER (ORDER BY RunningQuantity, Code), 0.0)
AS TradeQuantity
FROM cteSource
) AS d
WHERE DemandID < 2147483648
AND SupplyID < 2147483648
AND TradeQuantity > 0.0; De CTE cteSource doorzoekt de tabel Veilingen en gebruikt een vensterfunctie om de lopende totale vraag- en aanbodhoeveelheden te berekenen, waarbij de resultaatkolom RunningQuantity wordt aangeroepen.
De code die de afgeleide tabel d definieert, bevraagt cteSource en berekent de DemandID, SupplyID en TradeQuantity van de resultaatparen, voordat enkele overbodige rijen worden verwijderd. Alle vensterfuncties die in die berekeningen worden gebruikt, zijn gebaseerd op RunningQuantity en Code-volgorde.
De resultaatkolom d.DemandID wordt berekend als de minimale vraag-ID, beginnend met de huidige of 2147483648 als er geen wordt gevonden.
De resultaatkolom d.SupplyID wordt berekend als het minimale aanbod-ID beginnend met de huidige of 2147483648 als er geen wordt gevonden.
Het resultaat TradeQuantity wordt berekend als de RunningQuantity-waarde van de huidige rij minus de RunningQuantity-waarde van de vorige rij.
Hier is de inhoud van d:
DemandID SupplyID TradeQuantity --------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 1000 0.000000 3 2000 6.000000 3 3000 2.000000 5 3000 0.000000 5 4000 2.000000 6 4000 0.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000 7 2147483648 3.000000 8 2147483648 2.000000
Wat de buitenste query nog moet doen, is overtollige rijen uit d filteren. Dat zijn gevallen waarin de handelshoeveelheid nul is, of boekingen van de ene soort die niet kunnen worden gematcht met boekingen van de andere soort (met ID 2147483648).
Het plan voor deze oplossing wordt getoond in figuur 4.
 Figuur 4:Queryplan voor Peters oplossing
Figuur 4:Queryplan voor Peters oplossing
Net als het plan van Ian, is het plan van Peter gebaseerd op één scan van de invoergegevens en gebruikt het drie parallelle batch-modus vensteraggregaten om de verschillende vensterfuncties te berekenen, allemaal voorafgegaan door parallelle sorteeroperatoren. Twee daarvan zijn onvermijdelijk, zoals u kunt verifiëren door een serieel plan te forceren. In het plan van Peter is er geen behoefte aan een gegroepeerde aggregaatoperator zoals in het plan van Ian.
Peter's kritische inzicht dat zo'n korte oplossing mogelijk maakte, was het besef dat voor een relevante invoer van een van de soorten, de overeenkomende ID van de andere soort altijd later zal verschijnen (op basis van RunningQuantity en Code-volgorde). Na het zien van Peters oplossing, voelde het echt alsof ik de mijne te ingewikkeld maakte!
Dit zijn de looptijden in seconden die ik voor deze oplossing heb gekregen:
100K: 0.197 200K: 0.412 300K: 0.558 400K: 0.696
Paul Whites oplossing
Onze laatste oplossing is gemaakt door Paul White. Hier is de volledige oplossingscode:
DROP TABLE IF EXISTS #MyPairings;
CREATE TABLE #MyPairings
(
DemandID integer NOT NULL,
SupplyID integer NOT NULL,
TradeQuantity decimal(19, 6) NOT NULL
);
GO
INSERT #MyPairings
WITH (TABLOCK)
(
DemandID,
SupplyID,
TradeQuantity
)
SELECT
Q3.DemandID,
Q3.SupplyID,
Q3.TradeQuantity
FROM
(
SELECT
Q2.DemandID,
Q2.SupplyID,
TradeQuantity =
-- Interval overlap
CASE
WHEN Q2.Code = 'S' THEN
CASE
WHEN Q2.CumDemand >= Q2.IntEnd THEN Q2.IntLength
WHEN Q2.CumDemand > Q2.IntStart THEN Q2.CumDemand - Q2.IntStart
ELSE 0.0
END
WHEN Q2.Code = 'D' THEN
CASE
WHEN Q2.CumSupply >= Q2.IntEnd THEN Q2.IntLength
WHEN Q2.CumSupply > Q2.IntStart THEN Q2.CumSupply - Q2.IntStart
ELSE 0.0
END
END
FROM
(
SELECT
Q1.Code,
Q1.IntStart,
Q1.IntEnd,
Q1.IntLength,
DemandID = MAX(IIF(Q1.Code = 'D', Q1.ID, 0)) OVER (
ORDER BY Q1.IntStart, Q1.ID
ROWS UNBOUNDED PRECEDING),
SupplyID = MAX(IIF(Q1.Code = 'S', Q1.ID, 0)) OVER (
ORDER BY Q1.IntStart, Q1.ID
ROWS UNBOUNDED PRECEDING),
CumSupply = SUM(IIF(Q1.Code = 'S', Q1.IntLength, 0)) OVER (
ORDER BY Q1.IntStart, Q1.ID
ROWS UNBOUNDED PRECEDING),
CumDemand = SUM(IIF(Q1.Code = 'D', Q1.IntLength, 0)) OVER (
ORDER BY Q1.IntStart, Q1.ID
ROWS UNBOUNDED PRECEDING)
FROM
(
-- Demand intervals
SELECT
A.ID,
A.Code,
IntStart = SUM(A.Quantity) OVER (
ORDER BY A.ID
ROWS UNBOUNDED PRECEDING) - A.Quantity,
IntEnd = SUM(A.Quantity) OVER (
ORDER BY A.ID
ROWS UNBOUNDED PRECEDING),
IntLength = A.Quantity
FROM dbo.Auctions AS A
WHERE
A.Code = 'D'
UNION ALL
-- Supply intervals
SELECT
A.ID,
A.Code,
IntStart = SUM(A.Quantity) OVER (
ORDER BY A.ID
ROWS UNBOUNDED PRECEDING) - A.Quantity,
IntEnd = SUM(A.Quantity) OVER (
ORDER BY A.ID
ROWS UNBOUNDED PRECEDING),
IntLength = A.Quantity
FROM dbo.Auctions AS A
WHERE
A.Code = 'S'
) AS Q1
) AS Q2
) AS Q3
WHERE
Q3.TradeQuantity > 0; De code die de afgeleide tabel Q1 definieert, gebruikt twee afzonderlijke query's om vraag- en aanbodintervallen te berekenen op basis van lopende totalen en verenigt de twee. Voor elk interval berekent de code het begin (IntStart), einde (IntEnd) en lengte (IntLength). Hier is de inhoud van Q1 besteld door IntStart en ID:
ID Code IntStart IntEnd IntLength ----- ---- ---------- ---------- ---------- 1 D 0.000000 5.000000 5.000000 1000 S 0.000000 8.000000 8.000000 2 D 5.000000 8.000000 3.000000 3 D 8.000000 16.000000 8.000000 2000 S 8.000000 14.000000 6.000000 3000 S 14.000000 16.000000 2.000000 5 D 16.000000 18.000000 2.000000 4000 S 16.000000 18.000000 2.000000 6 D 18.000000 26.000000 8.000000 5000 S 18.000000 22.000000 4.000000 6000 S 22.000000 25.000000 3.000000 7000 S 25.000000 27.000000 2.000000 7 D 26.000000 30.000000 4.000000 8 D 30.000000 32.000000 2.000000
De code die de afgeleide tabel Q2 definieert, bevraagt Q1 en berekent resultaatkolommen genaamd DemandID, SupplyID, CumSupply en CumDemand. Alle vensterfuncties die door deze code worden gebruikt, zijn gebaseerd op IntStart- en ID-volgorde en het frame RIJEN ONGEKEND VOORAFGAAND (alle rijen tot aan de huidige).
DemandID is de maximale vraag-ID tot aan de huidige rij, of 0 als er geen bestaat.
SupplyID is het maximale aanbod-ID tot aan de huidige rij, of 0 als er geen bestaat.
CumSupply is de cumulatieve leveringshoeveelheden (leveringsintervallengtes) tot aan de huidige rij.
CumDemand is de cumulatieve vraaghoeveelheden (vraagintervallengtes) tot aan de huidige rij.
Dit is de inhoud van Q2:
Code IntStart IntEnd IntLength DemandID SupplyID CumSupply CumDemand ---- ---------- ---------- ---------- --------- --------- ---------- ---------- D 0.000000 5.000000 5.000000 1 0 0.000000 5.000000 S 0.000000 8.000000 8.000000 1 1000 8.000000 5.000000 D 5.000000 8.000000 3.000000 2 1000 8.000000 8.000000 D 8.000000 16.000000 8.000000 3 1000 8.000000 16.000000 S 8.000000 14.000000 6.000000 3 2000 14.000000 16.000000 S 14.000000 16.000000 2.000000 3 3000 16.000000 16.000000 D 16.000000 18.000000 2.000000 5 3000 16.000000 18.000000 S 16.000000 18.000000 2.000000 5 4000 18.000000 18.000000 D 18.000000 26.000000 8.000000 6 4000 18.000000 26.000000 S 18.000000 22.000000 4.000000 6 5000 22.000000 26.000000 S 22.000000 25.000000 3.000000 6 6000 25.000000 26.000000 S 25.000000 27.000000 2.000000 6 7000 27.000000 26.000000 D 26.000000 30.000000 4.000000 7 7000 27.000000 30.000000 D 30.000000 32.000000 2.000000 8 7000 27.000000 32.000000
Q2 already has the final result pairings’ correct DemandID and SupplyID values. The code defining the derived table Q3 queries Q2 and computes the result pairings’ TradeQuantity values as the overlapping segments of the demand and supply intervals. Finally, the outer query against Q3 filters only the relevant pairings where TradeQuantity is positive.
The plan for this solution is shown in Figure 5.
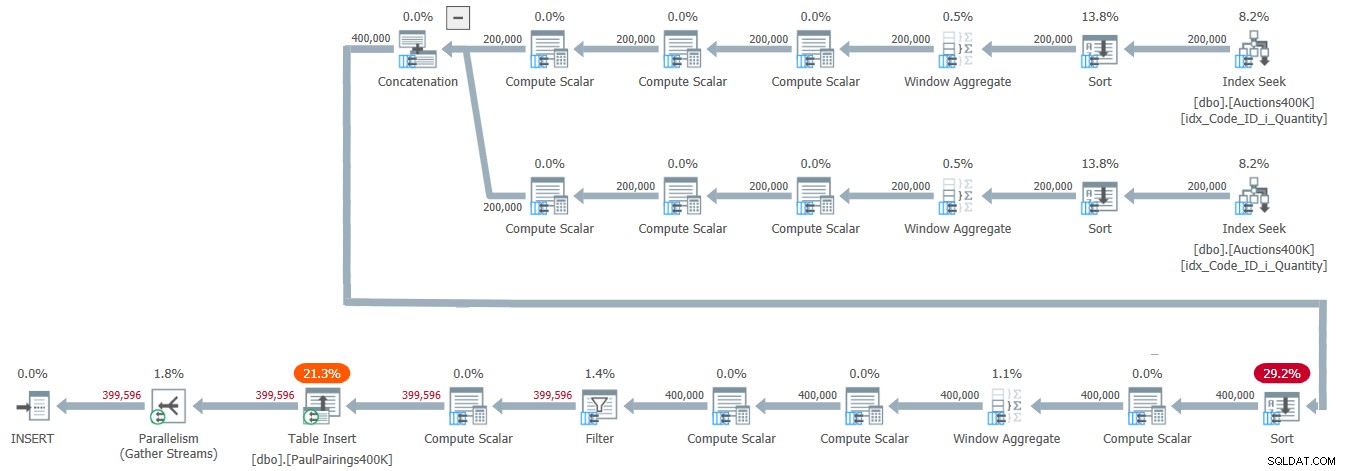 Figure 5:Query plan for Paul’s solution
Figure 5:Query plan for Paul’s solution
The top two branches of the plan are responsible for computing the demand and supply intervals. Both rely on Index Seek operators to get the relevant rows based on index order, and then use parallel batch-mode Window Aggregate operators, preceded by Sort operators that theoretically could have been avoided. The plan concatenates the two inputs, sorts the rows by IntStart and ID to support the subsequent remaining Window Aggregate operator. Only this Sort operator is unavoidable in this plan. The rest of the plan handles the needed scalar computations and the final filter. That’s a very efficient plan!
Here are the run times in seconds I got for this solution:
100K: 0.187 200K: 0.331 300K: 0.369 400K: 0.425
These numbers are pretty impressive!
Performance Comparison
Figure 6 has a performance comparison between all solutions covered in this article.
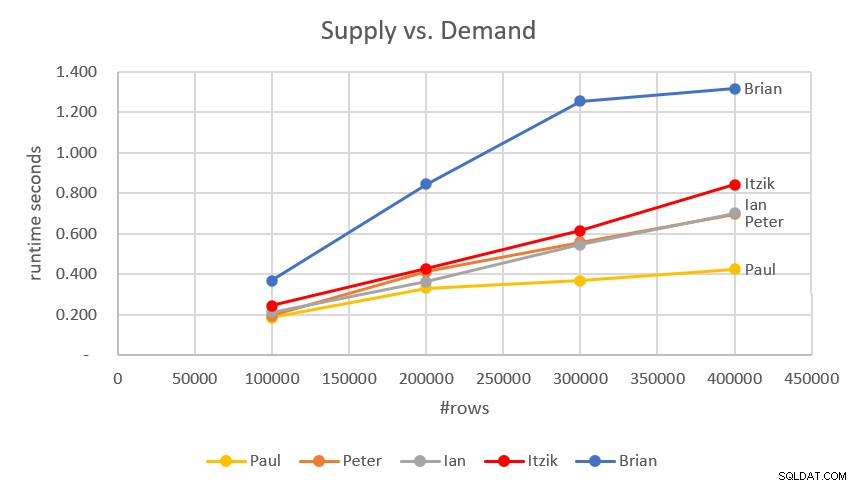 Figure 6:Performance comparison
Figure 6:Performance comparison
At this point, we can add the fastest solutions I covered in previous articles. Those are Joe’s and Kamil/Luca/Daniel’s solutions. The complete comparison is shown in Figure 7.
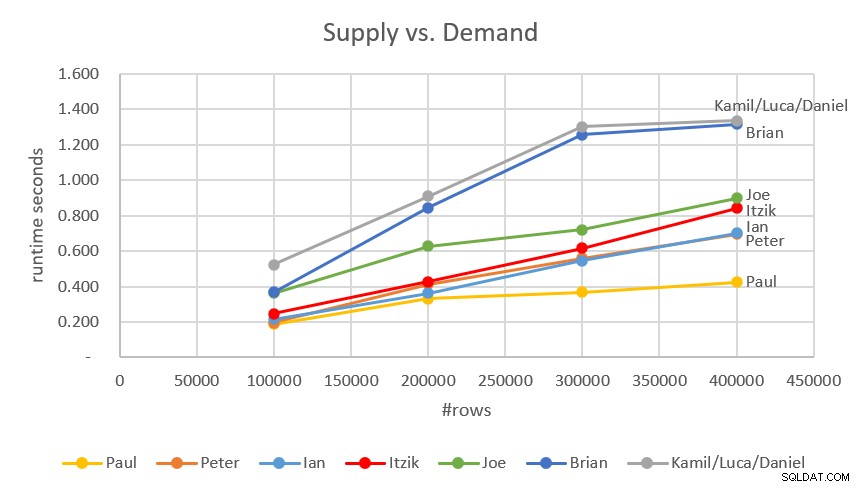 Figure 7:Performance comparison including earlier solutions
Figure 7:Performance comparison including earlier solutions
These are all impressively fast solutions, with the fastest being Paul’s and Peter’s.
Conclusie
When I originally introduced Peter’s puzzle, I showed a straightforward cursor-based solution that took 11.81 seconds to complete against a 400K-row input. The challenge was to come up with an efficient set-based solution. It’s so inspiring to see all the solutions people sent. I always learn so much from such puzzles both from my own attempts and by analyzing others’ solutions. It’s impressive to see several sub-second solutions, with Paul’s being less than half a second!
It's great to have multiple efficient techniques to handle such a classic need of matching supply with demand. Well done everyone!
[ Jump to:Original challenge | Solutions:Part 1 | Part 2 | Part 3 ]