Wanneer een uitvoeringsplan een scan van een b-tree-indexstructuur bevat, kan de opslagengine mogelijk kunnen kiezen tussen twee fysieke toegangsstrategieën wanneer het plan wordt uitgevoerd:
- Volg de index b-boomstructuur; of,
- vind pagina's met behulp van interne paginatoewijzingsinformatie.
Waar een keuze beschikbaar is, neemt de opslag-engine de runtime-beslissing over elke uitvoering. Een hercompilatie van een plan is niet nodig is om van gedachten te veranderen.
De b-tree-strategie begint bij de wortel van de boom, daalt af naar een uiterste rand van het bladniveau (afhankelijk van of de scan voorwaarts of achterwaarts is), en volgt vervolgens paginalinks op bladniveau totdat het andere uiteinde van de index is bereikt . De toewijzingsstrategie maakt gebruik van Index Allocation Map (IAM)-structuren om databasepagina's te lokaliseren die aan de index zijn toegewezen. Elke IAM-pagina wijst toewijzingen toe aan een interval van 4 GB in een enkel fysiek databasebestand, dus het scannen van de IAM-ketens die aan een index zijn gekoppeld, heeft de neiging om toegang te krijgen tot indexpagina's in fysieke bestandsvolgorde (tenminste voor zover SQL Server kan zien).
De belangrijkste verschillen tussen de twee strategieën zijn:
- Een b-tree-scan kan rijen in indexsleutelvolgorde aan de queryprocessor leveren; een IAM-gestuurde scan kan dat niet;
- een b-tree-scan kan mogelijk geen grote read-ahead I/O-verzoeken afgeven als logisch aaneengesloten indexpagina's niet ook fysiek aaneengesloten zijn (bijvoorbeeld als gevolg van paginasplitsing in de index).
Voor een index is altijd een b-tree scan beschikbaar. De vaak aangehaalde voorwaarden voor het beschikbaar zijn van scans van toewijzingsorders zijn:
- Het zoekplan moet een ongeordende scan van de index mogelijk maken;
- de index moet minimaal 64 pagina's groot zijn; en,
- ofwel een
TABLOCKofNOLOCKhint moet worden opgegeven.
De eerste voorwaarde betekent simpelweg dat de query-optimizer de scan moet hebben gemarkeerd met de Ordered:False eigendom. De scan markeren Ordered:False betekent dat correcte resultaten van het uitvoeringsplan niet vereisen de scan om rijen terug te geven in de volgorde van de indexsleutel (hoewel dit mogelijk is als dit handig of anderszins noodzakelijk is).
De tweede voorwaarde (grootte) is alleen van toepassing op SQL Server 2005 en later. Het weerspiegelt het feit dat er bepaalde opstartkosten zijn voor het uitvoeren van een IAM-gestuurde scan, dus er moet een minimum aantal pagina's zijn om de potentiële besparingen terug te betalen om de initiële investering terug te betalen. De "64 pagina's" verwijst naar de waarde van data_pages voor de IN_ROW_DATA alleen toewijzingseenheid, zoals gerapporteerd in sys.allocation_units.
Natuurlijk kan er alleen een uitbetaling zijn van een scan van een toewijzingsopdracht als de mogelijk grotere read-ahead-overwegingen eigenlijk spelen een rol, maar SQL Server houdt momenteel geen rekening met deze factor. Het houdt met name geen rekening met hoeveel van de index zich momenteel in het geheugen bevindt, en het maakt ook niet uit hoe gefragmenteerd de index is.
De derde voorwaarde is waarschijnlijk de minst volledige beschrijving in de lijst. Hints zijn in feite niet vereist , hoewel ze kunnen worden gebruikt om aan de echte vereisten te voldoen:de gegevens moeten gegarandeerd zijn dat ze niet veranderen tijdens de scan, of (meer controversieel) we moeten aangeven dat het ons niet kan schelen over mogelijk onnauwkeurige resultaten, door de scan uit te voeren op het gelezen niet-vastgelegde isolatieniveau.
Ook met deze verduidelijkingen is de lijst met voorwaarden voor een allocatie-geordende scan nog niet compleet. Er zijn een aantal belangrijke kanttekeningen en uitzonderingen, waar we binnenkort op zullen ingaan.
Demo
De volgende query gebruikt de voorbeelddatabase van AdventureWorks:
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P; Merk op dat de tabel Persoon 3.869 pagina's bevat. Het (werkelijke) plan na de uitvoering is als volgt (getoond in SQL Sentry Plan Explorer):
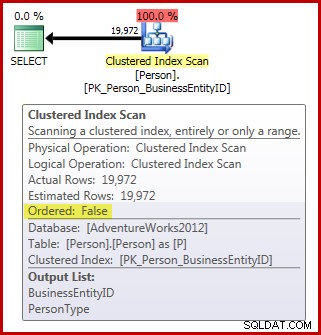
Wat betreft de scanvereisten voor toewijzingsorders die we tot nu toe hebben:
- Het abonnement heeft de vereiste
Ordered:Falseeigendom; en, - de tabel heeft meer dan 64 pagina's; maar,
- we hebben niets gedaan om ervoor te zorgen dat de gegevens tijdens de scan niet kunnen veranderen. Ervan uitgaande dat onze sessie de standaard read commit gebruikt isolatieniveau, de scan wordt niet uitgevoerd op de read uncommitted isolatieniveau ook niet.
Als gevolg hiervan zouden we verwachten dat deze scan wordt uitgevoerd door de b-tree te scannen in plaats van IAM-gestuurd te zijn. De zoekopdrachtresultaten geven aan dat dit waarschijnlijk waar is:
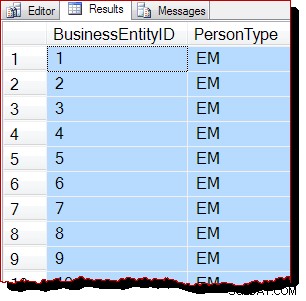
De rijen worden geretourneerd in geclusterde indexsleutelvolgorde (door BusinessEntityID ). Ik moet duidelijk vermelden dat deze resultaatvolgorde absoluut niet gegarandeerd is , en er mag niet op worden vertrouwd. Geordende resultaten worden alleen gegarandeerd door een geschikte ORDER BY op het hoogste niveau clausule.
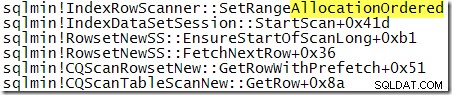
Desalniettemin is de waargenomen uitvoervolgorde het indirecte bewijs dat de scan deze keer is uitgevoerd door de geclusterde index b-boomstructuur te volgen. Als er meer bewijs nodig is, kunnen we een debugger toevoegen en kijken naar het codepad dat SQL Server uitvoert tijdens de scan:

De call-stack toont duidelijk de scan die de b-tree volgt.
Een hint voor tafelvergrendeling toevoegen
We passen de query nu aan om een table-lock hint op te nemen:
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (TABLOCK); Op het standaard vergrendelingsniveau voor leescommittatie, voorkomt de gedeelde vergrendeling op tabelniveau mogelijke gelijktijdige wijzigingen aan de gegevens. Nu aan alle drie de voorwaarden voor IAM-gestuurde scans is voldaan, zouden we nu verwachten dat SQL Server een allocatie-volgorde-scan gebruikt. Het uitvoeringsplan is hetzelfde als voorheen, dus ik zal het niet herhalen, maar de queryresultaten zien er zeker anders uit:
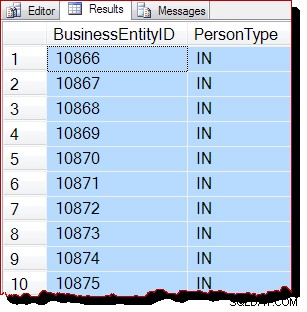
De resultaten zijn blijkbaar nog steeds gerangschikt op BusinessEntityID , maar het uitgangspunt (10866) is anders. Inderdaad, als we door de resultaten scrollen, komen we al snel secties tegen die duidelijk niet op volgorde staan:
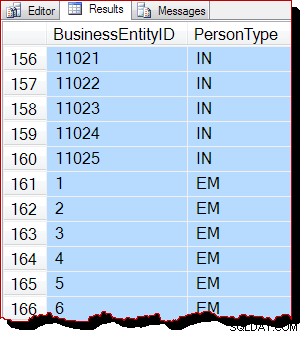
De gedeeltelijke volgorde is te wijten aan het feit dat de scan van de toewijzingsvolgorde een hele indexpagina tegelijk verwerkt. De resultaten binnen een pagina worden geretourneerd in volgorde van de indexsleutel, maar de volgorde van de gescande pagina's is nu anders. Nogmaals, ik moet benadrukken dat de resultaten er voor u anders uit kunnen zien:er is geen garantie voor uitvoervolgorde, zelfs niet binnen een pagina, zonder een ORDER BY op het hoogste niveau op de oorspronkelijke zoekopdracht.
Ter vergelijking met de eerder getoonde call-stack:dit is een stacktracering die is verkregen terwijl SQL Server de query aan het verwerken was met de TABLOCK hint:
Een beetje verder door de uitvoering stappen:

Het is duidelijk dat SQL Server een scan op basis van toewijzing uitvoert wanneer de tabelvergrendeling is opgegeven. Het is jammer dat er in een post-uitvoeringsplan niet wordt aangegeven welk type scan tijdens runtime is gebruikt. Ter herinnering:het type scan wordt gekozen door de opslagengine en kan tussen uitvoeringen wisselen zonder een hercompilatie van het plan.
Andere manieren om aan de derde voorwaarde te voldoen
Ik zei eerder dat om een IAM-gestuurde scan te krijgen, we ervoor moeten zorgen dat de gegevens onder de scan niet kunnen veranderen terwijl deze aan de gang is, of we moeten de query uitvoeren op het lees-niet-vastgelegde isolatieniveau. We hebben gezien dat een tabelvergrendelingshint voor het vergrendelen van leescommitted-isolatie voldoende is om aan de eerste van deze vereisten te voldoen, en het is gemakkelijk om aan te tonen dat het gebruik van een NOLOCK/READUNCOMMITTED hint maakt ook een scan van de toewijzingsvolgorde mogelijk met de demo-query.
In feite zijn er veel manieren om aan de derde voorwaarde te voldoen, waaronder:
- De index wijzigen om alleen tafelvergrendelingen toe te staan;
- de database alleen-lezen maken (zodat gegevens gegarandeerd niet veranderen); of,
- de sessie wijzigen isolatieniveau tot
READ UNCOMMITTED.
Er zijn echter veel interessantere variaties op dit thema, waardoor we de drie eerder genoemde voorwaarden moeten aanpassen...
Isolatieniveaus voor rijversies
Schakel read Committed snapshot isolation (RCSI) in op de AdventureWorks-database en voer de test uit met de TABLOCK hint nogmaals (bij read commit isolation):
ALTER DATABASE AdventureWorks2012
SET READ_COMMITTED_SNAPSHOT ON
WITH ROLLBACK IMMEDIATE;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
GO
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (TABLOCK);
GO
ALTER DATABASE AdventureWorks2012
SET READ_COMMITTED_SNAPSHOT OFF
WITH ROLLBACK IMMEDIATE;
Met RCSI actief, een geïndexeerd scan wordt gebruikt met TABLOCK , niet de allocatie-order scan die we net eerder zagen. De reden is de TABLOCK hint specificeert een gedeelde vergrendeling op tabelniveau, maar met RCSI ingeschakeld, geen gedeelde vergrendelingen zijn genomen. Zonder de gedeelde tabelvergrendeling hebben we niet voldaan aan de vereiste om gelijktijdige wijzigingen aan de gegevens te voorkomen terwijl de scan wordt uitgevoerd, dus een scan op basis van toewijzing kan niet worden gebruikt.
Het is echter mogelijk om een scan op volgorde van toewijzing te realiseren wanneer RCSI is ingeschakeld. Een manier is om een TABLOCKX . te gebruiken hint (voor een exclusief op tafelniveau lock) in plaats van TABLOCK . We kunnen ook de TABLOCK . behouden hint en voeg er nog een toe, zoals READCOMMITTEDLOCK , of REPEATABLE READ of SERIALIZABLE … enzovoort. Al deze werken door de mogelijkheid van gelijktijdige wijzigingen te voorkomen door een gedeelde tafelvergrendeling te nemen, ten koste van het verliezen van de voordelen van RCSI . We kunnen ook nog steeds een scan van de toewijzingsvolgorde bereiken met een NOLOCK of READUNCOMMITTED hint natuurlijk.
De situatie onder snapshot-isolatie (SI) lijkt erg op RCSI en wordt om ruimteredenen niet in detail onderzocht.
TABELSAMPLE altijd* voert een scan van de toewijzingsvolgorde uit
De TABLESAMPLE clausule is een interessante uitzondering op veel van de dingen die we tot nu toe hebben besproken.
Specificeren van een TABLESAMPLE clausule altijd* resulteert in een scan van de toewijzingsvolgorde, zelfs onder RCSI of SI, en zelfs zonder hints. Voor alle duidelijkheid:de scan van de toewijzingsvolgorde die het resultaat is van het gebruik van TABLESAMPLE behoudt RCSI/SI-semantiek – de scan gebruikt rijversies en lezen blokkeert schrijven niet (en vice versa).
Een tweede verrassing is dat TABLESAMPLE altijd* voert een IAM-gestuurde scan uit zelfs als de tabel minder dan 64 pagina's heeft . Dit is logisch omdat de documentatie op zijn minst aangeeft dat het SYSTEM steekproefmethode maakt gebruik van de IAM-structuur (er zit dus niets anders op dan een scan van de toewijzingsvolgorde te doen):
SYSTEEM Is een implementatie-afhankelijke steekproefmethode gespecificeerd door ISO-normen. In SQL Server is dit de enige beschikbare steekproefmethode en wordt deze standaard toegepast. SYSTEM past een op pagina's gebaseerde steekproefmethode toe waarbij een willekeurige set pagina's uit de tabel wordt gekozen voor de steekproef, en alle rijen op die pagina's worden geretourneerd als de voorbeeldsubset.
* Er treedt een uitzondering op als de ROWS of PERCENT specificatie in de TABLESAMPLE clausule werkt om 100% van de tabel te betekenen. Meer ROWS specificeren dan de metadata aangeeft die momenteel in de tabel staan, werken ook niet. Gebruik TABLESAMPLE SYSTEM (100 PERCENT) of equivalent zal niet forceer een toewijzingsvolgorde-scan.
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
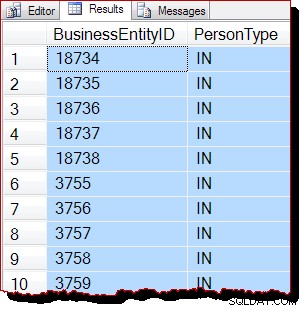
TABLESAMPLE SYSTEM (50 ROWS)
REPEATABLE (12345678)
--WITH (TABLOCK); Resultaten:
Het effect van TOP en SET ROWCOUNT
Kortom, geen van beide heeft invloed op de beslissing om al dan niet gebruik te maken van een verdeelvolgordescan. Dit lijkt misschien verrassend in gevallen waarin het "duidelijk" is dat er minder dan 64 pagina's worden gescand.
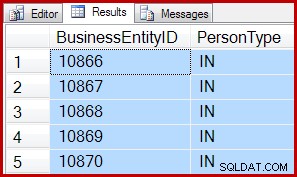
De volgende zoekopdrachten gebruiken bijvoorbeeld allebei een IAM-gestuurde scan om 5 rijen van een scan te retourneren:
SELECT TOP (5)
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P WITH (TABLOCK)
SET ROWCOUNT 5;
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P WITH (TABLOCK)
SET ROWCOUNT 0; De resultaten zijn voor beide hetzelfde:
Dit betekent dat TOP en SET ROWCOUNT zoekopdrachten misschien de overheadkosten van het opzetten van een scan voor toewijzingsvolgorde, zelfs als er minder dan 64 pagina's worden gescand. Ter beperking kunnen complexere TOP-query's met selectieve predikaten die in de scan worden geduwd, nog steeds profiteren van een scan met toewijzingsvolgorde. Als de scan 10.000 pagina's moet verwerken om de eerste 5 rijen te vinden die overeenkomen, kan een scan met toewijzingsvolgorde nog steeds een overwinning zijn.
Voorkomen van alle* scans van de toewijzingsvolgorde voor de hele instantie
Dit is waarschijnlijk niet iets dat u met opzet zou doen, maar er is een serverinstelling die scans op de toewijzingsvolgorde voor alle* gebruikersquery's in alle databases verhindert.
Hoe onwaarschijnlijk het ook lijkt, de instelling in kwestie is de configuratieoptie voor de cursordrempelserver, die de volgende beschrijving heeft in Books Online:
De optie cursordrempel specificeert het aantal rijen in de cursorset waarop cursortoetsensets asynchroon worden gegenereerd. Wanneer cursors een keyset voor een resultatenset genereren, schat de query-optimizer het aantal rijen dat voor die resultatenset wordt geretourneerd. Als de query-optimizer schat dat het aantal geretourneerde rijen groter is dan deze drempel, wordt de cursor asynchroon gegenereerd, zodat de gebruiker rijen van de cursor kan ophalen terwijl de cursor gevuld blijft. Anders wordt de cursor synchroon gegenereerd en wacht de query totdat alle rijen zijn geretourneerd.
Als de cursor threshold optie is ingesteld op iets anders dan –1 (de standaard), zullen er geen scans op de toewijzingsvolgorde plaatsvinden voor gebruikersquery's in een database op de SQL Server-instantie.
Met andere woorden, als asynchrone cursorpopulatie is ingeschakeld, zijn er geen IAM-gestuurde scans voor u.
* De uitzondering is (niet-100%) TABLESAMPLE vragen. De interne zoekopdrachten die door het systeem worden gegenereerd voor het maken van statistieken en het bijwerken van statistieken, blijven ook gebruikmaken van scans op basis van toewijzing.
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
-- WARNING! Disables allocation-order scans instance-wide
EXECUTE sys.sp_configure
@configname = 'cursor threshold',
@configvalue = 5000;
RECONFIGURE WITH OVERRIDE;
GO
-- Would normally result in an allocation-order scan
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (READUNCOMMITTED);
GO
-- Reset to default allocation-order scans
EXECUTE sys.sp_configure
@configname = 'cursor threshold',
@configvalue = -1;
RECONFIGURE WITH OVERRIDE; Resultaten (geen scan van toewijzingsvolgorde):
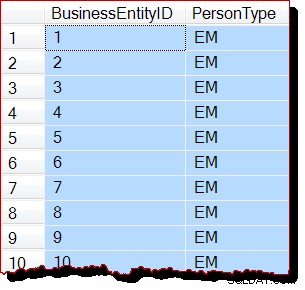
Men kan alleen maar raden dat asynchrone cursorpopulatie om de een of andere reden niet goed werkt met scans op toewijzingsvolgorde. Het is volkomen onverwacht dat deze beperking van invloed zou zijn op alle zoekopdrachten van gebruikers zonder cursor ook wel. Misschien is het voor SQL Server te moeilijk om te detecteren of een query wordt uitgevoerd als onderdeel van een extern uitgegeven API-cursor? Wie weet.
Het zou leuk zijn als deze bijwerking ergens officieel werd gedocumenteerd, hoewel het moeilijk is om precies te weten waar het in Books Online naartoe moet. Ik vraag me af hoeveel productiesystemen er zijn die hierdoor geen allocatie-order scans gebruiken? Misschien niet veel, maar je weet maar nooit.
Om alles af te ronden, volgt hier een samenvatting. Een scan op volgorde van toewijzing is beschikbaar als:
- De serveroptie
cursor thresholdis ingesteld op –1 (de standaard); en, - de scanoperator van het queryplan heeft de
Ordered:Falseeigendom; en, - het totaal data_pages van de
IN_ROW_DATAtoewijzingseenheden is minimaal 64; en, - ofwel:
- SQL Server heeft een acceptabele garantie dat gelijktijdige wijzigingen onmogelijk zijn; of,
- de scan wordt uitgevoerd op het lees-niet-vastgelegde isolatieniveau.
Ongeacht al het bovenstaande, een scan met een TABLESAMPLE clausule maakt altijd gebruik van op toewijzing geordende scans (met de enige technische uitzondering die in de hoofdtekst wordt vermeld).